
Conversion (24)
How to Convert PDF to CSV in Java (Easily Extract PDF Tables)
2025-08-28 05:43:27 Written by zaki zou
When working with reports, invoices, or datasets stored in PDF format, developers often need a way to reuse the tabular data in spreadsheets, databases, or analytical tools. A common solution is to convert PDF to CSV using Java, since CSV is lightweight, structured, and compatible with almost every platform.
Unlike text or image export, a PDF-to-CSV conversion is mainly about extracting tables from PDF and saving them as CSV. With the help of Spire.PDF for Java, you can detect table structures in PDFs and export them programmatically with just a few lines of code.
In this article, you’ll learn step by step how to perform a PDF to CSV conversion in Java—from setting up the environment, to extracting tables, and even handling more complex scenarios like multi-page documents or multiple tables per page.
Overview of This Tutorial
Environment Setup for PDF to CSV Conversion in Java
Before extracting tables and converting PDF to CSV using Java, you need to set up the development environment. This involves choosing a suitable library and adding it to your project.
Why Choose Spire.PDF for Java
Since PDF files do not provide a built-in export to CSV, extracting tables programmatically is the practical approach. Spire.PDF for Java offers APIs to detect table structures in PDF documents and save them directly as CSV files, making the conversion process simple and efficient.
Install Spire.PDF for Java
Add Spire.PDF for Java to your project using Maven:
<repositories>
<repository>
<id>com.e-iceblue</id>
<name>e-iceblue</name>
<url>https://repo.e-iceblue.com/nexus/content/groups/public/</url>
</repository>
</repositories>
<dependencies>
<dependency>
<groupId>e-iceblue</groupId>
<artifactId>spire.pdf</artifactId>
<version>11.10.3</version>
</dependency>
</dependencies>
If you are not using Maven, you can download the Spire.PDF for Java package and add the JAR files to your project’s classpath.
Extract Tables from PDF and Save as CSV
The most practical way to perform PDF to CSV conversion is by extracting tables. With Spire.PDF for Java, this can be done with just a few steps:
- Load the PDF document.
- Use PdfTableExtractor to find tables on each page.
- Collect cell values row by row.
- Write the output into a CSV file.
Here is a Java example that shows the process from start to finish:
Java Code Example for PDF to CSV Conversion
import com.spire.pdf.*;
import com.spire.pdf.utilities.*;
import java.io.*;
public class PdfToCsvExample {
public static void main(String[] args) throws Exception {
// Load the PDF document
PdfDocument pdf = new PdfDocument();
pdf.loadFromFile("Sample.pdf");
// Create a StringBuilder to store extracted text
StringBuilder sb = new StringBuilder();
// Iterate through each page
for (int i = 0; i < pdf.getPages().getCount(); i++) {
PdfTableExtractor extractor = new PdfTableExtractor(pdf);
PdfTable[] tableLists = extractor.extractTable(i);
if (tableLists != null) {
for (PdfTable table : tableLists) {
for (int row = 0; row < table.getRowCount(); row++) {
for (int col = 0; col < table.getColumnCount(); col++) {
// Escape the cell text safely
String cellText = escapeCsvField(table.getText(row, col));
sb.append(cellText);
if (col < table.getColumnCount() - 1) {
sb.append(",");
}
}
sb.append("\n");
}
}
}
}
// Write the output to a CSV file
FileWriter writer = new FileWriter("output/PDFTable.csv");
writer.write(sb.toString());
writer.close();
pdf.close();
System.out.println("PDF tables successfully exported to CSV.");
}
// Utility method to escape CSV fields
private static String escapeCsvField(String text) {
if (text == null) return "";
// Remove line breaks
text = text.replaceAll("[\\n\\r]", "");
// Escape if contains special characters
if (text.contains(",") || text.contains(";") || text.contains("\"") || text.contains("\n")) {
text = text.replace("\"", "\"\""); // Escape double quotes
text = "\"" + text + "\""; // Wrap with quotes
}
return text;
}
}
Code Walkthrough
- PdfDocument loads the PDF file into memory.
- PdfTableExtractor checks each page for tables.
- PdfTable provides access to rows and columns.
- escapeCsvField() removes line breaks and safely quotes/escapes text if needed.
- StringBuilder accumulates cell text, separated by commas.
- The result is written into Output.csv, which you can open in Excel or any editor.
CSV file generated from a PDF table after running the Java code.
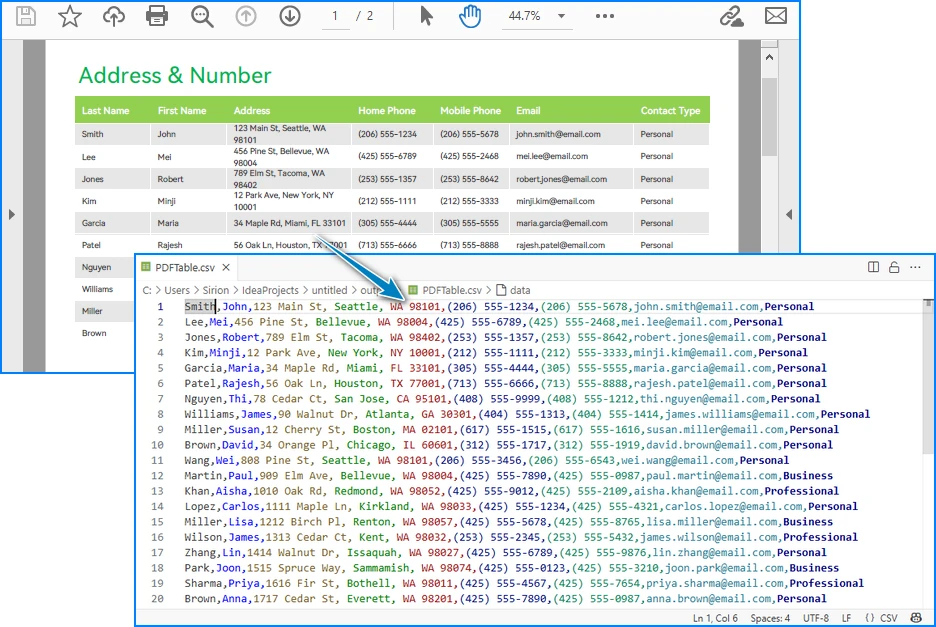
Handling Complex PDF-to-CSV Conversion Cases
In practice, PDFs often contain multiple tables, span multiple pages, or have irregular structures. Let’s see how to extend the solution to handle these scenarios.
1. Multiple Tables per Page
The PdfTable[] returned by extractTable(i) contains all tables detected on a page. You can process each one separately. For example, to save each table as a different CSV file:
for (int i = 0; i < pdf.getPages().getCount(); i++) {
PdfTableExtractor extractor = new PdfTableExtractor(pdf);
PdfTable[] tableLists = extractor.extractTable(i);
if (tableLists != null) {
for (int t = 0; t < tableLists.length; t++) {
PdfTable table = tableLists[t];
StringBuilder tableContent = new StringBuilder();
for (int row = 0; row < table.getRowCount(); row++) {
for (int col = 0; col < table.getColumnCount(); col++) {
tableContent.append(escapeCsvField(table.getText(row, col)));
if (col < table.getColumnCount() - 1) {
tableContent.append(",");
}
}
tableContent.append("\n");
}
FileWriter writer = new FileWriter("Table_Page" + i + "_Index" + t + ".csv");
writer.write(tableContent.toString());
writer.close();
}
}
}
Example of multiple tables in one PDF page exported into separate CSV files.
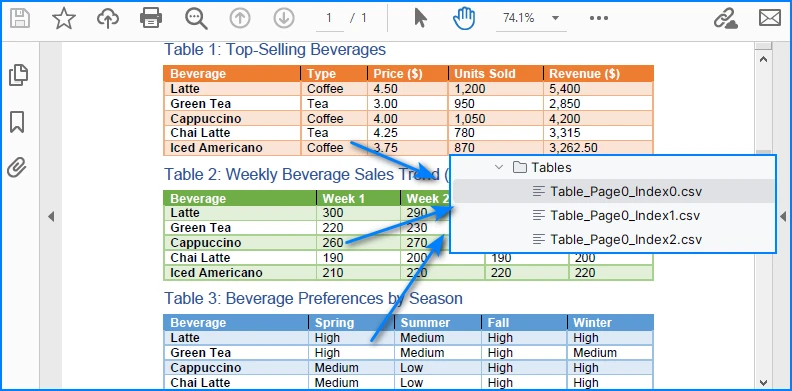
This way, every table is saved as an independent CSV file for better organization.
2. Multi-page or Large Tables
If a table spans across multiple pages, iterating page by page ensures that all data is collected. The key is to append data instead of overwriting:
StringBuilder sb = new StringBuilder();
for (int i = 0; i < pdf.getPages().getCount(); i++) {
PdfTableExtractor extractor = new PdfTableExtractor(pdf);
PdfTable[] tables = extractor.extractTable(i);
if (tables != null) {
for (PdfTable table : tables) {
for (int row = 0; row < table.getRowCount(); row++) {
for (int col = 0; col < table.getColumnCount(); col++) {
sb.append(escapeCsvField(table.getText(row, col)));
if (col < table.getColumnCount() - 1) sb.append(",");
}
sb.append("\n");
}
}
}
}
FileWriter writer = new FileWriter("MergedTables.csv");
writer.write(sb.toString());
writer.close();
Example of a large table across multiple PDF pages merged into one CSV file.
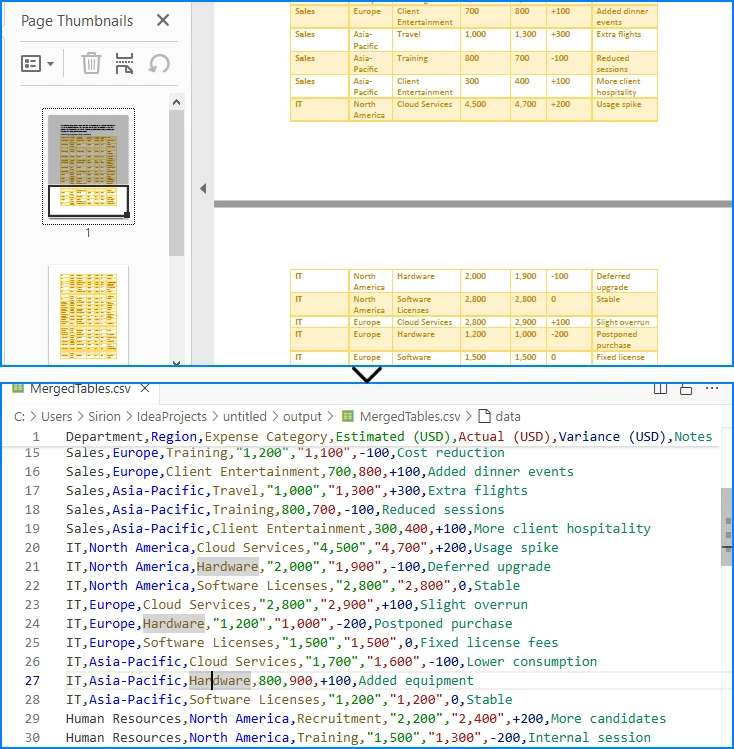
Here, all tables across pages are merged into one CSV file, useful when dealing with continuous reports.
3. Limitations with Formatting
CSV only stores plain text values. Elements like merged cells, fonts, or images are discarded. If preserving styling is critical, exporting to Excel (.xlsx) is a better alternative, which the same library also supports. See How to Export PDF Table to Excel in Java for more details.
4. CSV Special Characters Handling
When writing tables to CSV, certain characters like commas, semicolons, double quotes, or line breaks can break the file structure if not handled properly.
In the Java examples above, the escapeCsvField method removes line breaks and safely quotes or escapes text when needed.
For more advanced scenarios, you can also use Spire.XLS for Java to write data into worksheets and then save as CSV, which automatically handles special characters and ensures correct CSV formatting without manual processing.
Alternatively, for open-source options, libraries like OpenCSV or Apache Commons CSV also automatically handle special characters and CSV formatting, reducing potential issues and simplifying code.
Conclusion
Converting PDF to CSV in Java essentially means extracting tables and saving them in a structured format. CSV is widely supported, lightweight, and ideal for storing and analyzing tabular data. By setting up Spire.PDF for Java and following the code example, you can automate this process, saving time and reducing manual effort.
If you want to explore more advanced features of Spire.PDF for Java, please apply for a free trial license. You can also use Free Spire.PDF for Java for small projects.
FAQ
Q: Can I turn a PDF into a CSV file? A: Yes. While images and styled text cannot be exported, you can extract tables and save them as CSV files using Java.
Q: How to extract data from a PDF file in Java? A: Use a PDF library like Spire.PDF for Java to parse the document, detect tables, and export them to CSV or Excel.
Q: What is the best PDF to CSV converter? A: For Java developers, programmatic solutions such as Spire.PDF for Java offer more flexibility and automation than manual converters.
Q: How to convert PDF to Excel using Java code? A: The process is similar to CSV export. Instead of writing data as comma-separated text, you can export tables into Excel format for richer features.
Java Convert Byte Array to PDF: Load & Create with Spire.PDF
2025-08-21 06:31:19 Written by zaki zou
In modern Java applications, PDF data is not always stored as files on disk. Instead, it may be transmitted over a network, returned by a REST API, or stored as a byte array in a database. In such cases, you’ll often need to convert a byte array back into a PDF file or even generate a new PDF from plain text bytes.
This tutorial will walk you through both scenarios using Spire.PDF for Java, a powerful library for working with PDF documents.
Table of Contents:
- Getting Started with Spire.PDF for Java
- Understanding PDF Bytes vs. Text Bytes
- Loading PDF from Byte Array
- Creating PDF from Text Bytes
- Common Pitfalls to Avoid
- Frequently Asked Questions
- Conclusion
Getting Started with Spire.PDF for Java
Spire.PDF is a powerful and feature-rich API that allows Java developers to create, read, edit, convert, and print PDF documents without any dependencies on Adobe Acrobat.
Key Features:
- Create PDFs with text, images, tables, and shapes.
- Edit existing PDFs and extract text and images.
- Convert PDFs to formats like HTML, Word, Excel, and images.
- Encrypt PDFs with password protection.
- Add watermarks, annotations, and digital signatures.
To get started, download Spire.PDF for Java from our website and add the JAR files to your project's build path. If you’re using Maven, include the following dependency in your pom.xml.
<repositories>
<repository>
<id>com.e-iceblue</id>
<name>e-iceblue</name>
<url>https://repo.e-iceblue.com/nexus/content/groups/public/</url>
</repository>
</repositories>
<dependencies>
<dependency>
<groupId>e-iceblue</groupId>
<artifactId>spire.pdf</artifactId>
<version>11.10.3</version>
</dependency>
</dependencies>
Once set up, you can now proceed to convert byte arrays to PDFs and perform other PDF-related operations.
Understanding PDF Bytes vs. Text Bytes
Before coding, it’s important to distinguish between two very different kinds of byte arrays :
- PDF File Bytes : These represent the actual binary structure of a valid PDF document. They always start with %PDF-1.x and contain objects, cross-reference tables, and streams. Such byte arrays can be loaded directly into a PdfDocument.
- Text Bytes : These are simply ASCII or UTF-8 encodings of characters. For example,
byte[] bytes = {84, 104, 105, 115};
System.out.println(new String(bytes)); // Output: "This"
Such arrays are not valid PDFs, but you can create a new PDF and write the text into it.
Loading PDF from Byte Array in Java
Suppose you want to download a PDF from a URL and work with it in memory as a byte array. With Spire.PDF for Java, you can easily load and save it back as a PDF document.
import com.spire.pdf.PdfDocument;
import java.io.ByteArrayInputStream;
import java.io.ByteArrayOutputStream;
import java.io.InputStream;
import java.net.HttpURLConnection;
import java.net.URL;
public class LoadPdfFromByteArray throws Exception{
public static void main(String[] args) {
// The PDF URL
String fileUrl = "https://www.e-iceblue.com/resource/sample.pdf";
// Download PDF into a byte array
byte[] pdfBytes = downloadPdfAsBytes(fileUrl);
// Create a PdfDocument object
PdfDocument doc = new PdfDocument();
// Load PDF from byte array
doc.loadFromStream(new ByteArrayInputStream(pdfBytes));
// Save the document locally
doc.saveToFile("downloaded.pdf");
doc.close();
}
// Helper method: download file as byte[]
private static byte[] downloadPdfAsBytes(String fileUrl) throws Exception {
URL url = new URL(fileUrl);
HttpURLConnection conn = (HttpURLConnection) url.openConnection();
conn.setRequestMethod("GET");
InputStream inputStream = conn.getInputStream();
ByteArrayOutputStream buffer = new ByteArrayOutputStream();
byte[] data = new byte[4096];
int nRead;
while ((nRead = inputStream.read(data, 0, data.length)) != -1) {
buffer.write(data, 0, nRead);
}
buffer.flush();
inputStream.close();
conn.disconnect();
return buffer.toByteArray();
}
}
How this works
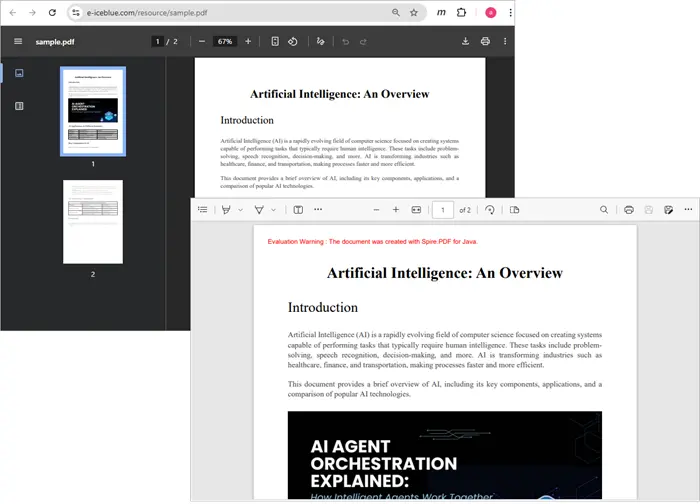
- Make an HTTP request to fetch the PDF file.
- Convert the InputStream into a byte array using ByteArrayOutputStream .
- Pass the byte array into Spire.PDF via loadFromStream .
- Save or manipulate the document as needed.
Output:
Creating PDF from Text Bytes in Java
If you only have plain text bytes (e.g., This document is created from text bytes.), you can decode them into a string and then draw the text onto a new PDF document.
import com.spire.pdf.*;
import com.spire.pdf.graphics.*;
import java.awt.*;
public class TextFromBytesToPdf {
public static void main(String[] args) {
// Your text bytes
byte[] byteArray = {
84, 104, 105, 115, 32,
100, 111, 99, 117, 109, 101, 110, 116, 32,
105, 115, 32,
99, 114, 101, 97, 116, 101, 100, 32,
102, 114, 111, 109, 32,
116, 101, 120, 116, 32,
98, 121, 116, 101, 115, 46
};
String text = new String(byteArray);
// Create a PDF document
PdfDocument doc = new PdfDocument();
// Configure the page settings
doc.getPageSettings().setSize(PdfPageSize.A4);
doc.getPageSettings().setMargins(40f);
// Add a page
PdfPageBase page = doc.getPages().add();
// Draw the string onto PDF
PdfFont font = new PdfFont(PdfFontFamily.Helvetica, 20f);
PdfSolidBrush brush = new PdfSolidBrush(new PdfRGBColor(Color.black));
page.getCanvas().drawString(text, font, brush, 20, 40);
// Save the document to a PDF file
doc.saveToFile("TextBytes.pdf");
doc.close();
}
}
This will produce a new PDF named TextBytes.pdf (shown below) containing the sentence represented by your byte array.

You might be interested in: How to Generate PDF Documents in Java
Common Pitfalls to Avoid
When converting byte arrays to PDFs, watch out for these issues:
- Confusing plain text with PDF bytes
Not every byte array is a valid PDF. Unless the array starts with %PDF-1.x and contains the proper structure, you can’t load it directly with PdfDocument.loadFromStream .
- Incorrect encoding
If your text bytes are in UTF-16, ISO-8859-1, or another encoding, you need to specify the charset when creating a string:
String text = new String(byteArray, StandardCharsets.UTF_8);
- Large byte arrays
When dealing with large PDFs, consider streaming instead of holding everything in memory to avoid OutOfMemoryError .
- Forgetting to close documents
Always call doc.close() to release resources after saving or processing a PDF.
Frequently Asked Questions
Q1. Can I store a PDF as a byte array in a database?
Yes. You can store a PDF as a BLOB in a relational database. Later, you can retrieve it, load it into a PdfDocument , and save or manipulate it.
Q2. How do I check if a byte array is a valid PDF?
Check if the array begins with the %PDF- header. You can do:
String header = new String(Arrays.copyOfRange(bytes, 0, 5));
if (header.startsWith("%PDF-")) {
// valid PDF
}
Q3. Can Spire.PDF load a PDF directly from an InputStream?
Yes. Instead of converting to a byte array, you can pass the InputStream directly to loadFromStream() .
Q4. Can I convert a PdfDocument back into a byte array?
You can save the document into a ByteArrayOutputStream instead of a file:
ByteArrayOutputStream baos = new ByteArrayOutputStream();
doc.saveToStream(baos);
byte[] pdfBytes = baos.toByteArray();
Q5. What if my byte array contains images instead of text or PDF?
In that case, you’ll need to create a new PDF and insert the image using Spire.PDF’s drawing APIs.
Conclusion
In this article, we explored how to efficiently convert byte arrays to PDF documents using Spire.PDF for Java. Whether you're loading existing PDF files from byte arrays retrieved via APIs or creating new PDFs from plain text bytes, Spire.PDF provides a robust solution to meet your needs.
We covered essential concepts, including the distinction between PDF file bytes and text bytes, and highlighted common pitfalls to avoid during the conversion process. With the right understanding and tools, you can seamlessly integrate PDF functionalities into your Java applications, enhancing your ability to manage and manipulate document data.
For further exploration, consider experimenting with additional features of Spire.PDF, such as editing, encrypting, and converting PDFs to other formats. The possibilities are extensive, and mastering these techniques will undoubtedly improve your development skills and project outcomes.
Combining multiple images into a single PDF document is an efficient method for those who want to store or distribute their images in a more organized way. Converting these images into a single PDF file not only saves storage space but also ensures that all images are kept together in one place, making it easier and more convenient to share or transfer them. In this article, you will learn how to merge several images into a single PDF document in Java using Spire.PDF for Java.
Install Spire.PDF for Java
First of all, you're required to add the Spire.Pdf.jar file as a dependency in your Java program. The JAR file can be downloaded from this link. If you use Maven, you can easily import the JAR file in your application by adding the following code to your project's pom.xml file.
<repositories>
<repository>
<id>com.e-iceblue</id>
<name>e-iceblue</name>
<url>https://repo.e-iceblue.com/nexus/content/groups/public/</url>
</repository>
</repositories>
<dependencies>
<dependency>
<groupId>e-iceblue</groupId>
<artifactId>spire.pdf</artifactId>
<version>11.10.3</version>
</dependency>
</dependencies>
Convert Multiple Images into a Single PDF Document in Java
In order to convert all the images in a folder to a PDF, we iterate through each image, add a new page to the PDF with the same size as the image, and then draw the image onto the new page. The following are the detailed steps.
- Create a PdfDocument object.
- Set the page margins to zero using PdfDocument.getPageSettings().setMargins() method.
- Get the folder where the images are stored.
- Iterate through each image file in the folder, and get the width and height of a specific image.
- Add a new page that has the same width and height as the image to the PDF document using PdfDocument.getPages().add() method.
- Draw the image on the page using PdfPageBase.getCanvas().drawImage() method.
- Save the document using PdfDocument.saveToFile() method.
- Java
import com.spire.pdf.PdfDocument;
import com.spire.pdf.PdfPageBase;
import com.spire.pdf.graphics.PdfImage;
import java.awt.*;
import java.io.File;
public class ConvertMultipleImagesIntoPdf {
public static void main(String[] args) {
//Create a PdfDocument object
PdfDocument doc = new PdfDocument();
//Set the page margins to 0
doc.getPageSettings().setMargins(0);
//Get the folder where the images are stored
File folder = new File("C:/Users/Administrator/Desktop/Images");
//Iterate through the files in the folder
for (File file : folder.listFiles())
{
//Load a particular image
PdfImage pdfImage = PdfImage.fromFile(file.getPath());
//Get the image width and height
int width = pdfImage.getWidth();
int height = pdfImage.getHeight();
//Add a page that has the same size as the image
PdfPageBase page = doc.getPages().add(new Dimension(width, height));
//Draw image at (0, 0) of the page
page.getCanvas().drawImage(pdfImage, 0, 0, width, height);
}
//Save to file
doc.saveToFile("CombineImagesToPdf.pdf");
doc.dispose();
}
}
Apply for a Temporary License
If you'd like to remove the evaluation message from the generated documents, or to get rid of the function limitations, please request a 30-day trial license for yourself.
Converting a PDF document to an image format like JPEG or PNG can be useful for a variety of reasons, such as making it easier to share the content on social media, embedding it into a website, or including it in a presentation. Converting PDF to images can also avoid printing issues caused by the printers that do not support PDF format well enough. In this article, you will learn how to convert PDF to JPEG or PNG in Java using Spire.PDF for Java.
Install Spire.PDF for Java
First, you're required to add the Spire.Pdf.jar file as a dependency in your Java program. The JAR file can be downloaded from this link. If you use Maven, you can easily import the JAR file in your application by adding the following code to your project's pom.xml file.
<repositories>
<repository>
<id>com.e-iceblue</id>
<name>e-iceblue</name>
<url>https://repo.e-iceblue.com/nexus/content/groups/public/</url>
</repository>
</repositories>
<dependencies>
<dependency>
<groupId>e-iceblue</groupId>
<artifactId>spire.pdf</artifactId>
<version>11.10.3</version>
</dependency>
</dependencies>
Convert PDF to JPEG in Java
The PdfDocument.saveAsImage() method provided by Spire.PDF for Java enables the conversion of a particular page from a PDF document into a BufferedImage object, which can be saved as a file in .jpg or .png format. The following are the steps to convert each page of a PDF document to a JPEG image file.
- Create a PdfDocument object.
- Load a PDF file using PdfDocument.loadFromFile() method.
- Iterate through each page of the PDF document.
- Convert a specific page into a BufferedImage object using PdfDocument.saveAsImage() method.
- Re-create a BufferedImage in RGB type with the same width and height as the converted image.
- Write the image data as a .jpg file using ImageIO.write() method.
- Java
import com.spire.pdf.PdfDocument;
import com.spire.pdf.graphics.PdfImageType;
import javax.imageio.ImageIO;
import java.awt.image.BufferedImage;
import java.io.File;
import java.io.IOException;
public class ConvertPdfToJpeg {
public static void main(String[] args) throws IOException {
//Create a PdfDocument instance
PdfDocument pdf = new PdfDocument();
//Load a sample PDF document
pdf.loadFromFile("C:\\Users\\Administrator\\Desktop\\Input.pdf");
//Loop through the pages
for (int i = 0; i < pdf.getPages().getCount(); i++) {
//Save the current page as a buffered image
BufferedImage image = pdf.saveAsImage(i, PdfImageType.Bitmap, 300, 300);
//Re-create a buffered image in RGB type
BufferedImage newImg = new BufferedImage(image.getWidth(), image.getHeight(), BufferedImage.TYPE_INT_RGB);
newImg.getGraphics().drawImage(image, 0, 0, null);
//Write the image data as a .jpg file
File file = new File("C:\\Users\\Administrator\\Desktop\\Output\\" + String.format(("ToImage-%d.jpg"), i));
ImageIO.write(newImg, "JPEG", file);
}
pdf.close();
}
}
Convert PDF to PNG in Java
The steps to convert PDF to PNG using Spire.PDF for Java are as follows.
- Create a PdfDocument object.
- Load a PDF file using PdfDocument.loadFromFile() method.
- Iterate through each page of the PDF document.
- Convert a specific page into a BufferedImage object using PdfDocument.saveAsImage() method.
- Write the image data as a .png file using ImageIO.write() method.
- Java
import com.spire.pdf.*;
import javax.imageio.ImageIO;
import java.awt.image.BufferedImage;
import java.io.File;
import java.io.IOException;
public class ConvertPdfToPng {
public static void main(String[] args) throws IOException {
//Create a PdfDocument object
PdfDocument doc = new PdfDocument();
//Load a sample PDF document
doc.loadFromFile("C:\\Users\\Administrator\\Desktop\\Input.pdf");
//Make the background of the generated PNG files transparent
//doc.getConvertOptions().setPdfToImageOptions(0);
//Loop through the pages
for (int i = 0; i < doc.getPages().getCount(); i++) {
//Save the current page as a buffered image
BufferedImage image = doc.saveAsImage(i);
//Write the image data as a .png file
File file = new File("C:\\Users\\Administrator\\Desktop\\Output\\" + String.format("ToImage-%d.png", i));
ImageIO.write(image, "png", file);
}
doc.close();
}
}
If the background of the PDF document is white and you want to make it transparent when converted to PNG, you can add following line of code before you save each page to a BufferedImage object.
- Java
doc.getConvertOptions().setPdfToImageOptions(0);
Apply for a Temporary License
If you'd like to remove the evaluation message from the generated documents, or to get rid of the function limitations, please request a 30-day trial license for yourself.
PDF is a popular and widely used file format, but when it comes to giving presentations to others in meetings, classes or other scenarios, PowerPoint is always preferred over PDF files because it contains rich presentation effects that can better capture the attention of your audience. In this article, you will learn how to convert an existing PDF file to a PowerPoint presentation using Spire.PDF for Java.
Install Spire.PDF for Java
First of all, you're required to add the Spire.Pdf.jar file as a dependency in your Java program. The JAR file can be downloaded from this link. If you use Maven, you can easily import the JAR file in your application by adding the following code to your project's pom.xml file.
<repositories>
<repository>
<id>com.e-iceblue</id>
<name>e-iceblue</name>
<url>https://repo.e-iceblue.com/nexus/content/groups/public/</url>
</repository>
</repositories>
<dependencies>
<dependency>
<groupId>e-iceblue</groupId>
<artifactId>spire.pdf</artifactId>
<version>11.10.3</version>
</dependency>
</dependencies>
Convert PDF to PowerPoint Presentation in Java
From Version 9.2.1, Spire.PDF for Java supports converting PDF to PPTX using PdfDocument.saveToFile() method. With this method, each page of your PDF file will be converted to a single slide in PowerPoint. Below are the steps to convert a PDF file to an editable PowerPoint document.
- Create a PdfDocument instance.
- Load a sample PDF document using PdfDocument.loadFromFile() method.
- Save the document as a PowerPoint document using PdfDocument.saveToFile(String filename, FileFormat.PPTX) method.
- Java
import com.spire.pdf.FileFormat;
import com.spire.pdf.PdfDocument;
public class PDFtoPowerPoint {
public static void main(String[] args) {
//Create a PdfDocument instance
PdfDocument pdfDocument = new PdfDocument();
//Load a sample PDF document
pdfDocument.loadFromFile("sample.pdf");
//Convert PDF to PPTX document
pdfDocument.saveToFile("PDFtoPowerPoint.pptx", FileFormat.PPTX);
}
}
Apply for a Temporary License
If you'd like to remove the evaluation message from the generated documents, or to get rid of the function limitations, please request a 30-day trial license for yourself.
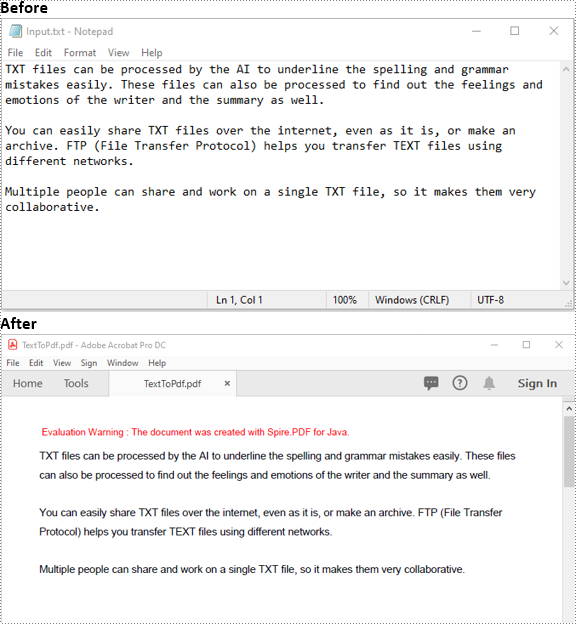
Text files can be easily edited by any text editing program. If you want to prevent changes when others view the files, you can convert them to PDF. In this article, we will demonstrate how to convert text files to PDF in Java using Spire.PDF for Java.
Install Spire.PDF for Java
First of all, you're required to add the Spire.Pdf.jar file as a dependency in your Java program. The JAR file can be downloaded from this link. If you use Maven, you can easily import the JAR file in your application by adding the following code to your project's pom.xml file.
<repositories>
<repository>
<id>com.e-iceblue</id>
<name>e-iceblue</name>
<url>https://repo.e-iceblue.com/nexus/content/groups/public/</url>
</repository>
</repositories>
<dependencies>
<dependency>
<groupId>e-iceblue</groupId>
<artifactId>spire.pdf</artifactId>
<version>11.10.3</version>
</dependency>
</dependencies>
Convert Text Files to PDF in Java
The following are the main steps to convert a text file to PDF using Spire.PDF for Java:
- Read the text in the text file into a String object.
- Create a PdfDocument instance and add a page to the PDF file using PdfDocument.getPages().add() method.
- Create a PdfTextWidget instance from the text.
- Draw the text onto the PDF page using PdfTextWidget.draw() method.
- Save the result file using PdfDocument.saveToFile() method.
- Java
import com.spire.pdf.FileFormat;
import com.spire.pdf.PdfDocument;
import com.spire.pdf.PdfPageBase;
import com.spire.pdf.graphics.*;
import java.awt.geom.Rectangle2D;
import java.io.BufferedReader;
import java.io.FileReader;
import java.io.IOException;
public class ConvertTextToPdf {
public static void main(String[] args) throws Exception {
//Read the text from the text file
String text = readTextFromFile("Input.txt");
//Create a PdfDocument instance
PdfDocument pdf = new PdfDocument();
//Add a page
PdfPageBase page = pdf.getPages().add();
//Create a PdfFont instance
PdfFont font = new PdfFont(PdfFontFamily.Helvetica, 11);
//Create a PdfTextLayout instance
PdfTextLayout textLayout = new PdfTextLayout();
textLayout.setBreak(PdfLayoutBreakType.Fit_Page);
textLayout.setLayout(PdfLayoutType.Paginate);
//Create a PdfStringFormat instance
PdfStringFormat format = new PdfStringFormat();
format.setLineSpacing(20f);
//Create a PdfTextWidget instance from the text
PdfTextWidget textWidget = new PdfTextWidget(text, font, PdfBrushes.getBlack());
//Set string format
textWidget.setStringFormat(format);
//Draw the text at the specified location of the page
Rectangle2D.Float bounds = new Rectangle2D.Float();
bounds.setRect(0,25,page.getCanvas().getClientSize().getWidth(),page.getCanvas().getClientSize().getHeight());
textWidget.draw(page, bounds, textLayout);
//Save the result file
pdf.saveToFile("TextToPdf.pdf", FileFormat.PDF);
}
public static String readTextFromFile(String fileName) throws IOException {
StringBuffer sb = new StringBuffer();
BufferedReader br = new BufferedReader(new FileReader(fileName));
String content = null;
while ((content = br.readLine()) != null) {
sb.append(content);
sb.append("\n");
}
return sb.toString();
}
}
Apply for a Temporary License
If you'd like to remove the evaluation message from the generated documents, or to get rid of the function limitations, please request a 30-day trial license for yourself.
The Tagged Image File Format (TIFF) is a relatively flexible image format which has the advantages of not requiring specific hardware, as well as being portable. Spire.PDF for Java supports converting TIFF to PDF and vice versa. This article will show you how to programmatically convert PDF to TIFF using it from the two aspects below.
Install Spire.PDF for Java
First of all, you're required to add the Spire.Pdf.jar file as a dependency in your Java program. The JAR file can be downloaded from this link. If you use Maven, you can easily import the JAR file in your application by adding the following code to your project's pom.xml file.
<repositories>
<repository>
<id>com.e-iceblue</id>
<name>e-iceblue</name>
<url>https://repo.e-iceblue.com/nexus/content/groups/public/</url>
</repository>
</repositories>
<dependencies>
<dependency>
<groupId>e-iceblue</groupId>
<artifactId>spire.pdf</artifactId>
<version>11.10.3</version>
</dependency>
</dependencies>
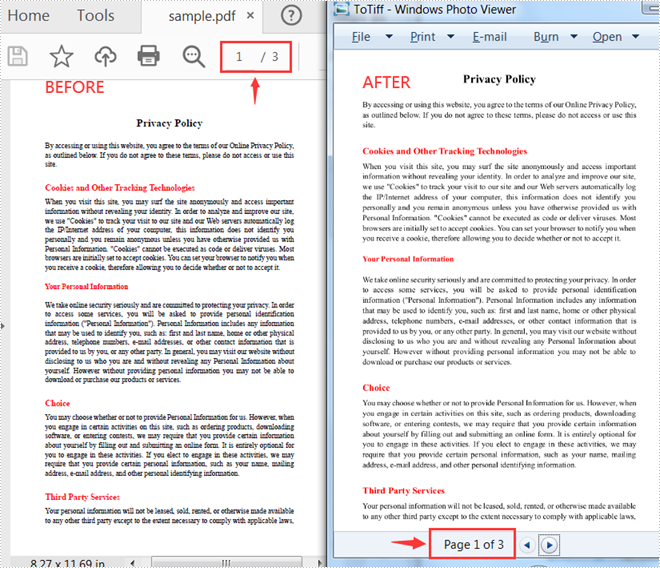
Convert All Pages of a PDF File to TIFF
The following steps show you how to convert all pages of a PDF file to a TIFF file.
- Create a PdfDocument instance.
- Load a PDF sample document using PdfDocument.loadFromFile() method.
- Save all pages of the document to a TIFF file using PdfDocument.saveToTiff(String tiffFilename) method.
- Java
import com.spire.compression.TiffCompressionTypes;
import com.spire.pdf.PdfDocument;
public class PDFToTIFF {
public static void main(String[] args) {
//Create a PdfDocument instance
PdfDocument pdf = new PdfDocument();
//Load a PDF sample document
pdf.loadFromFile("sample.pdf");
//Save all pages of the document to Tiff
pdf.saveToTiff("output/PDFtoTiff.tiff");
}
}
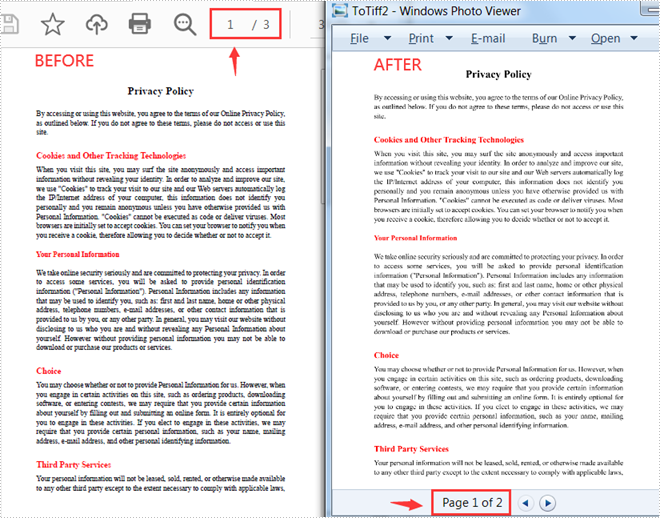
Convert Some Specified Pages of a PDF File to TIFF
The following steps are to convert specified pages of a PDF document to a TIFF file.
- Create a PdfDocument instance.
- Load a PDF sample document using PdfDocument.loadFromFile() method.
- Save specified pages of the document to a TIFF file using PdfDocument.saveToTiff(String tiffFilename, int startPage, int endPage, int dpix, int dpiy) method.
- Java
import com.spire.pdf.PdfDocument;
public class PDFToTIFF {
public static void main(String[] args) {
//Create a PdfDocument instance
PdfDocument pdf = new PdfDocument();
//Load a PDF sample document
pdf.loadFromFile("sample.pdf");
//Save specified pages of the document to TIFF and set horizontal and vertical resolution
pdf.saveToTiff("output/ToTiff2.tiff",0,1,400,600);
}
}
Apply for a Temporary License
If you'd like to remove the evaluation message from the generated documents, or to get rid of the function limitations, please request a 30-day trial license for yourself.
TIFF or TIF files are image files saved in the tagged image file format. They are often used for storing high-quality color images. Sometimes, you may wish to convert TIFF files to PDF so you can share them more easily. In this article, you will learn how to achieve this task programmatically in Java using Spire.PDF for Java library.
Install Spire.PDF for Java
First of all, you're required to add the Spire.Pdf.jar file as a dependency in your Java program. The JAR file can be downloaded from this link. If you use Maven, you can easily import the JAR file in your application by adding the following code to your project's pom.xml file.
<repositories>
<repository>
<id>com.e-iceblue</id>
<name>e-iceblue</name>
<url>https://repo.e-iceblue.com/nexus/content/groups/public/</url>
</repository>
</repositories>
<dependencies>
<dependency>
<groupId>e-iceblue</groupId>
<artifactId>spire.pdf</artifactId>
<version>11.10.3</version>
</dependency>
</dependencies>
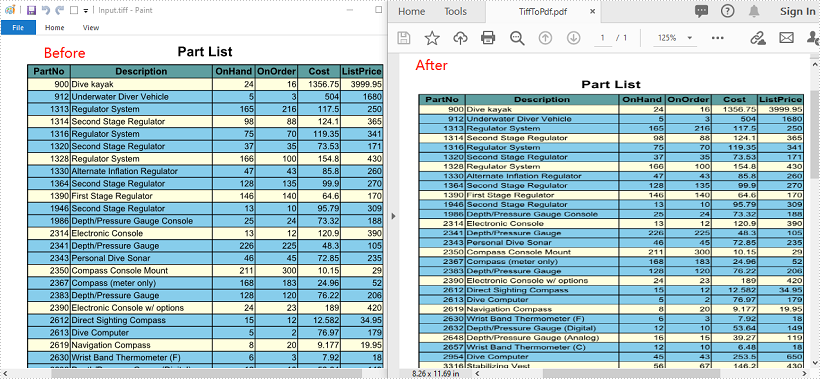
Convert TIFF to PDF in Java
The following are the steps to convert a TIFF file to PDF:
- Create an instance of PdfDocument class.
- Add a page to the PDF using PdfDocument.getPages().add() method.
- Create a PdfImage object from the TIFF image using PdfImage.fromFile() method.
- Draw the image onto the page using PdfPageBase.getCanvas().drawImage() method.
- Save the result file using PdfDocument.saveToFile() method.
- Java
import com.spire.pdf.FileFormat;
import com.spire.pdf.PdfDocument;
import com.spire.pdf.PdfPageBase;
import com.spire.pdf.graphics.PdfImage;
public class ConvertTiffToPdf {
public static void main(String[] args){
//Create a PdfDocument instance
PdfDocument doc = new PdfDocument();
//Add a page
PdfPageBase page = doc.getPages().add();
//Create a PdfImage object from the TIFF image
PdfImage tiff = PdfImage.fromFile("Input.tiff");
//Draw the image to the page
page.getCanvas().drawImage(tiff, 20, 0, 450, 450);
//Save the result file
doc.saveToFile("TiffToPdf.pdf", FileFormat.PDF);
}
}
Apply for a Temporary License
If you'd like to remove the evaluation message from the generated documents, or to get rid of the function limitations, please request a 30-day trial license for yourself.
Spire.PDF for Java offers the PdfDocument.saveToFile() method to convert PDF to other file formats such as Word, Excel, HTML, SVG and XPS. When converting PDF to Excel, it allows you to convert each PDF page to a single Excel worksheet or convert multiple PDF pages to one Excel worksheet. This article will demonstrate how to convert a PDF file containing 3 pages to one Excel worksheet.
Install Spire.PDF for Java
First of all, you're required to add the Spire.PDF.jar file as a dependency in your Java program. The JAR file can be downloaded from this link. If you use Maven, you can easily import the JAR file in your application by adding the following code to your project's pom.xml file.
<repositories>
<repository>
<id>com.e-iceblue</id>
<name>e-iceblue</name>
<url>https://repo.e-iceblue.com/nexus/content/groups/public/</url>
</repository>
</repositories>
<dependencies>
<dependency>
<groupId>e-iceblue</groupId>
<artifactId>spire.pdf</artifactId>
<version>11.10.3</version>
</dependency>
</dependencies>
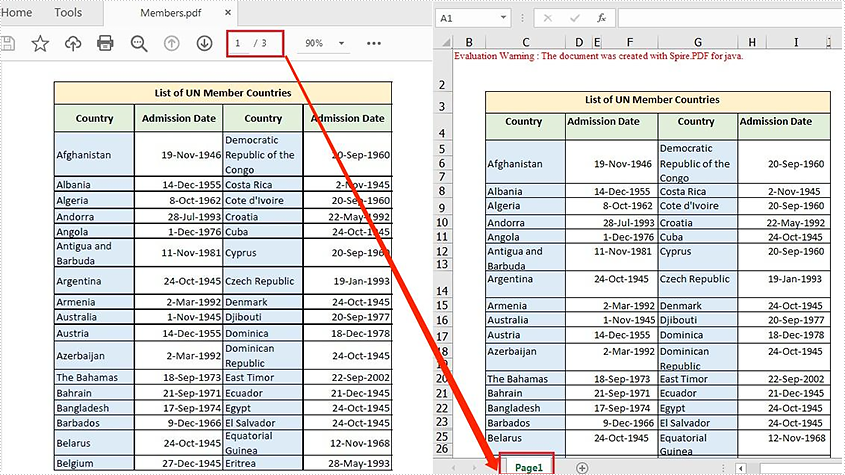
Convert a Multi-page PDF to One Excel Worksheet
The detailed steps are as follows:
- Create a PdfDocument object.
- Load a sample PDF file using PdfDocument.loadFromFile() method.
- Set the PDF to XLSX conversion options to render multiple PDF pages on a single worksheet using PdfDocument.getConvertOptions().setPdfToXlsxOptions() method.
- Save the PDF file to Excel using PdfDocument.saveToFile() method.
- Java
import com.spire.pdf.*;
import com.spire.pdf.conversion.XlsxLineLayoutOptions;
public class ManyPagesToOneSheet {
public static void main(String[] args) {
//Create a PdfDocument object
PdfDocument pdf = new PdfDocument();
//Load a sample PDF file
pdf.loadFromFile("C:\\Users\\Administrator\\Desktop\\Members.pdf");
//Set the PDF to XLSX conversion options: rendering multiple pages on a single worksheet
pdf.getConvertOptions().setPdfToXlsxOptions(new XlsxLineLayoutOptions(false,true,true));
//Save to Excel
pdf.saveToFile("out/ToOneSheet.xlsx", FileFormat.XLSX);
}
}
Apply for a Temporary License
If you'd like to remove the evaluation message from the generated documents, or to get rid of the function limitations, please request a 30-day trial license for yourself.
Postscript, also known as PS, is a dynamically typed, concatenative programming language that describes the appearance of a printed page. Owing to its faster printing and improved quality, sometime you may need to convert a PDF document to Postscript. In this article, you will learn how to achieve this function using Spire.PDF for Java.
Install Spire.PDF for Java
First of all, you're required to add the Spire.PDF.jar file as a dependency in your Java program. The JAR file can be downloaded from this link. If you use Maven, you can easily import the JAR file in your application by adding the following code to your project's pom.xml file.
<repositories>
<repository>
<id>com.e-iceblue</id>
<name>e-iceblue</name>
<url>https://repo.e-iceblue.com/nexus/content/groups/public/</url>
</repository>
</repositories>
<dependencies>
<dependency>
<groupId>e-iceblue</groupId>
<artifactId>spire.pdf</artifactId>
<version>11.10.3</version>
</dependency>
</dependencies>
Convert PDF to PostScript
The following are the steps to convert PDF to PostScript.
- Create a PdfDocument object.
- Load a sample PDF file using PdfDocument.loadFromFile() method.
- Save the document as PostScript using PdfDocument.saveToFile() method
- Java
import com.spire.pdf.*;
public class PDFToPS {
public static void main(String[] args) {
//Load a pdf document
PdfDocument doc = new PdfDocument();
doc.loadFromFile("sample.pdf");
//Convert to PostScript file
doc.saveToFile("output.ps", FileFormat.POSTSCRIPT);
}
}
Apply for a Temporary License
If you'd like to remove the evaluation message from the generated documents, or to get rid of the function limitations, please request a 30-day trial license for yourself.
