

HTML parsing is a critical task in Java development, enabling developers to extract structured data, analyze content, and interact with web-based information. Whether you’re building a web scraper, validating HTML content, or extracting text and attributes from web pages, having a reliable tool simplifies the process. In this guide, we’ll explore how to parse HTML in Java using Spire.Doc for Java - a powerful library that combines robust HTML parsing with seamless document processing capabilities.
- Why Use Spire.Doc for Java for HTML Parsing
- Environment Setup & Installation
- Core Guide: Parsing HTML to Extract Elements in Java
- Advanced Scenarios: Parse HTML Files & URLs in Java
- FAQ About Parsing HTML
Why Use Spire.Doc for Java for HTML Parsing
While there are multiple Java libraries for HTML parsing (e.g., Jsoup), Spire.Doc stands out for its seamless integration with document processing and low-code workflow, which is critical for developers prioritizing efficiency. Here’s why it’s ideal for Java HTML parsing tasks:
- Intuitive Object Model: Converts HTML into a navigable document structure (e.g., Section, Paragraph, Table), eliminating the need to manually parse raw HTML tags.
- Comprehensive Data Extraction: Easily retrieve text, attributes, table rows/cells, and even styles (e.g., headings) without extra dependencies.
- Low-Code Workflow: Minimal code is required to load HTML content and process it—reducing development time for common tasks.
- Lightweight Integration: Simple to add to Java projects via Maven/Gradle, with minimal dependencies.
Environment Setup & Installation
To start reading HTML in Java, ensure your environment meets these requirements:
- Java Development Kit (JDK): Version 8 or higher (JDK 11+ recommended for HttpClient support in URL parsing).
- Spire.Doc for Java Library: Latest version (integrated via Maven or manual download).
- HTML Source: A sample HTML string, local file, or URL (for testing extraction).
Install Spire.Doc for Java
Maven Setup: Add the Spire.Doc repository and dependency to your project’s pom.xml file. This automatically downloads the library and its dependencies:
<repositories>
<repository>
<id>com.e-iceblue</id>
<name>e-iceblue</name>
<url>https://repo.e-iceblue.com/nexus/content/groups/public/</url>
</repository>
</repositories>
<dependencies>
<dependency>
<groupId>e-iceblue</groupId>
<artifactId>spire.doc</artifactId>
<version>14.6.0</version>
</dependency>
</dependencies>
For manual installation, download the JAR from the official website and add it to your project.
Get a Temporary License (Optional)
By default, Spire.Doc adds an evaluation watermark to output. To remove it and unlock full features, you can request a free 30-day trial license.
Core Guide: Parsing HTML to Extract Elements in Java
Spire.Doc parses HTML into a structured object model, where elements like paragraphs, tables, and fields are accessible as Java objects. Below are practical examples to extract key HTML components.
1. Extract Text from HTML in Java
Extracting text (without HTML tags or formatting) is essential for scenarios like content indexing or data analysis. This example parses an HTML string and extracts text from all paragraphs.
Java Code: Extract Text from an HTML String
import com.spire.doc.*;
import com.spire.doc.documents.*;
public class ExtractTextFromHtml {
public static void main(String[] args) {
// Define HTML content to parse
String htmlContent = "<html>" +
"<body>" +
"<h1>Introduction to HTML Parsing</h1>" +
"<p>Spire.Doc for Java simplifies extracting text from HTML.</p>" +
"<ul>" +
"<li>Extract headings</li>" +
"<li>Extract paragraphs</li>" +
"<li>Extract list items</li>" +
"</ul>" +
"</body>" +
"</html>";
// Create a Document object to hold parsed HTML
Document doc = new Document();
// Parse the HTML string into the document
doc.addSection().addParagraph().appendHTML(htmlContent);
// Extract text from all paragraphs
StringBuilder extractedText = new StringBuilder();
for (Section section : (Iterable<Section>) doc.getSections()) {
for (Paragraph paragraph : (Iterable<Paragraph>) section.getParagraphs()) {
extractedText.append(paragraph.getText()).append("\n");
}
}
// Print or process the extracted text
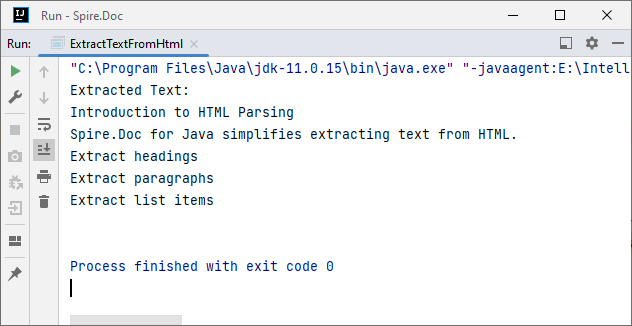
System.out.println("Extracted Text:\n" + extractedText);
}
}
Output:
2. Extract Table Data from HTML in Java
HTML tables store structured data (e.g., product lists, reports). Spire.Doc parses <table> tags into Table objects, making it easy to extract rows and columns.
Java Code: Extract HTML Table Rows & Cells
import com.spire.doc.*;
import com.spire.doc.documents.*;
public class ExtractTableFromHtml {
public static void main(String[] args) {
// HTML content with a table
String htmlWithTable = "<html>" +
"<body>" +
"<table border='1'>" +
"<tr><th>ID</th><th>Name</th><th>Price</th></tr>" +
"<tr><td>001</td><td>Laptop</td><td>$999</td></tr>" +
"<tr><td>002</td><td>Phone</td><td>$699</td></tr>" +
"</table>" +
"</body>" +
"</html>";
// Parse HTML into Document
Document doc = new Document();
doc.addSection().addParagraph().appendHTML(htmlWithTable);
// Extract table data
for (Section section : (Iterable<Section>) doc.getSections()) {
// Iterate through all objects in the section's body
for (Object obj : section.getBody().getChildObjects()) {
if (obj instanceof Table) { // Check if the object is a table
Table table = (Table) obj;
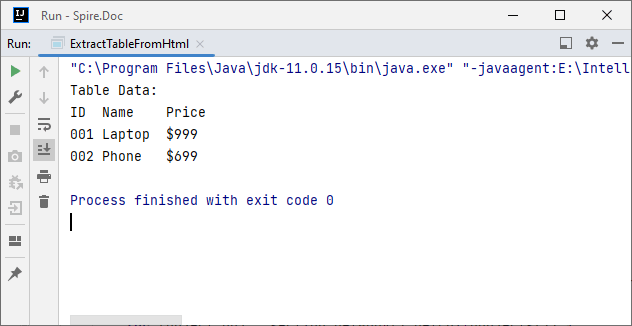
System.out.println("Table Data:");
// Loop through rows
for (TableRow row : (Iterable<TableRow>) table.getRows()) {
// Loop through cells in the row
for (TableCell cell : (Iterable<TableCell>) row.getCells()) {
// Extract text from each cell's paragraphs
for (Paragraph para : (Iterable<Paragraph>) cell.getParagraphs()) {
System.out.print(para.getText() + "\t");
}
}
System.out.println(); // New line after each row
}
}
}
}
}
}
Output:
After parsing the HTML string into a Word document via the appendHTML() method, you can leverage Spire.Doc’s APIs to extract hyperlinks as well.
Advanced Scenarios: Parse HTML Files & URLs in Java
Spire.Doc for Java also offers flexibility to parse local HTML files and web URLs, making it versatile for real-world applications.
1. Read an HTML File in Java
To parse a local HTML file using Spire.Doc for Java, simply load it via the loadFromFile(String filename, FileFormat.Html) method for processing.
Java Code: Read & Parse Local HTML Files
import com.spire.doc.*;
import com.spire.doc.documents.*;
public class ParseHtmlFile {
public static void main(String[] args) {
// Create a Document object
Document doc = new Document();
// Load an HTML file
doc.loadFromFile("input.html", FileFormat.Html);
// Extract and print text
StringBuilder text = new StringBuilder();
for (Section section : (Iterable<Section>) doc.getSections()) {
for (Paragraph para : (Iterable<Paragraph>) section.getParagraphs()) {
text.append(para.getText()).append("\n");
}
}
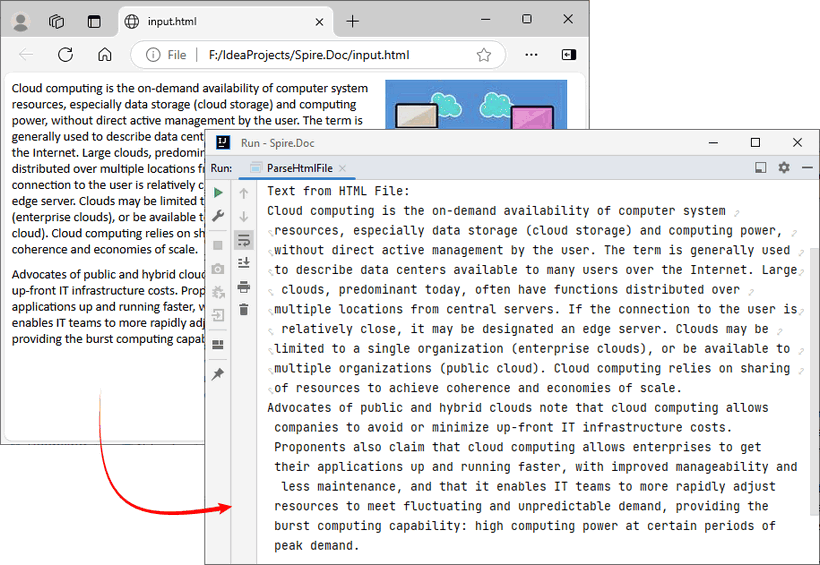
System.out.println("Text from HTML File:\n" + text);
}
}
The example extracts text content from the loaded HTML file. If you need to extract the paragraph style (e.g., "Heading1", "Normal") simultaneously, use the Paragraph.getStyleName() method.
Output:
You may also need: Convert HTML to Word in Java
2. Parse a URL in Java
For real-world web scraping, you'll need to parse HTML from live web pages. Spire.Doc can work with Java’s built-in HttpClient (JDK 11+) to fetch HTML content from URLs, then parse it.
Java Code: Fetch & Parse a Web URL
import com.spire.doc.*;
import com.spire.doc.documents.*;
import java.net.URI;
import java.net.http.HttpClient;
import java.net.http.HttpRequest;
import java.net.http.HttpResponse;
import java.time.Duration;
public class ParseHtmlFromUrl {
// Reusable HttpClient (configures timeout to avoid hanging)
private static final HttpClient httpClient = HttpClient.newBuilder()
.connectTimeout(Duration.ofSeconds(10))
.build();
public static void main(String[] args) {
String url = "https://www.e-iceblue.com/privacypolicy.html";
try {
// Fetch HTML content from the URL
System.out.println("Fetching from: " + url);
String html = fetchHtml(url);
// Parse HTML with Spire.Doc
Document doc = new Document();
Section section = doc.addSection();
section.addParagraph().appendHTML(html);
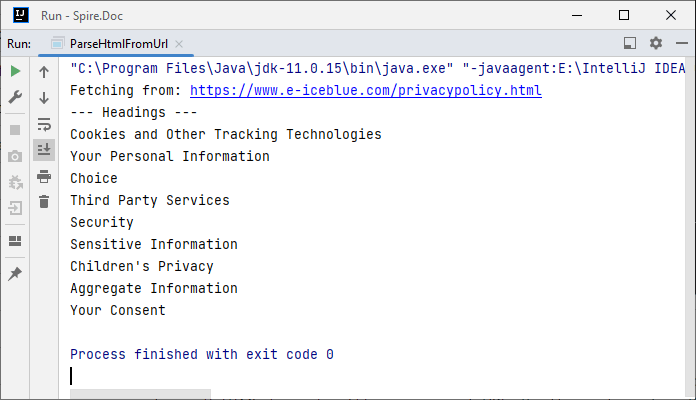
System.out.println("--- Headings ---");
// Extract headings
for (Paragraph para : (Iterable<Paragraph>) section.getParagraphs()) {
// Check if the paragraph style is a heading (e.g., "Heading1", "Heading2")
if (para.getStyleName() != null && para.getStyleName().startsWith("Heading")) {
System.out.println(para.getText());
}
}
} catch (Exception e) {
System.err.println("Error: " + e.getMessage());
}
}
// Helper method: Fetches HTML content from a given URL
private static String fetchHtml(String url) throws Exception {
// Create HTTP request with User-Agent header (to avoid blocks)
HttpRequest request = HttpRequest.newBuilder()
.uri(URI.create(url))
.header("User-Agent", "Mozilla/5.0")
.timeout(Duration.ofSeconds(10))
.GET()
.build();
// Send request and get response
HttpResponse<String> response = httpClient.send(request, HttpResponse.BodyHandlers.ofString());
// Check if the request succeeded (HTTP 200 = OK)
if (response.statusCode() != 200) {
throw new Exception("HTTP error: " + response.statusCode());
}
return response.body(); // Return the raw HTML content
}
}
Key Steps:
- HTTP Fetching: Uses HttpClient to fetch HTML from the URL, with a User-Agent header to mimic a browser (avoids being blocked).
- HTML Parsing: Creates a Document, adds a Section and Paragraph, then uses appendHTML() to load the fetched HTML.
- Content Extraction: Extracts headings by checking if paragraph styles start with "Heading".
Output:
Conclusion
Parsing HTML in Java is simplified with the Spire.Doc for Java library. Using it, you can extract text, tables, and data from HTML strings, local files, or URLs with minimal code—no need to manually handle raw HTML tags or manage heavy dependencies.
Whether you’re building a web scraper, analyzing web content, or converting HTML to other formats (e.g., HTML to PDF), Spire.Doc streamlines the workflow. By following the step-by-step examples in this guide, you’ll be able to integrate robust HTML parsing into your Java projects to unlock actionable insights from HTML content.
FAQs About Parsing HTML
Q1: Which library is best for parsing HTML in Java?
A: It depends on your needs:
- Use Spire.Doc if you need to extract text/tables and integrate with document processing (e.g., convert HTML to PDF).
- Use Jsoup if you only need basic HTML parsing (but it requires more code for table/text extraction).
Q2: How does Spire.Doc handle malformed or poorly structured HTML?
A: Spire.Doc for Java provides a dedicated approach using the loadFromFile method with XHTMLValidationType.None parameter. This configuration disables strict XHTML validation, allowing the parser to handle non-compliant HTML structures gracefully.
// Load and parse the malformed HTML file
// Parameters: file path, file format (HTML), validation type (None)
doc.loadFromFile("input.html", FileFormat.Html, XHTMLValidationType.None);
However, severely malformed HTML may still cause parsing issues.
Q3: Can I modify parsed HTML content and save it back as HTML?
A: Yes. Spire.Doc lets you manipulate parsed content (e.g., edit paragraph text, delete table rows, or add new elements) and then save the modified document back as HTML:
// After parsing HTML into a Document object:
Section section = doc.getSections().get(0);
Paragraph firstPara = section.getParagraphs().get(0);
firstPara.setText("Updated heading!"); // Modify text
// Save back as HTML
doc.saveToFile("modified.html", FileFormat.Html);
Q4: Is an internet connection required to parse HTML with Spire.Doc?
A: No, unless you’re loading HTML directly from a URL. Spire.Doc can parse HTML from local files or strings without an internet connection. If fetching HTML from a URL, you’ll need an internet connection to retrieve the content first, but parsing itself works offline.

