

Working with PDFs as byte arrays is common in C# development. Developers often need to store PDF documents in a database, transfer them through an API, or process them entirely in memory without touching the file system. In such cases, converting between PDF and bytes using C# becomes essential.
This tutorial explains how to perform these operations step by step using Spire.PDF for .NET. You will learn how to convert a byte array to PDF, convert a PDF back into a byte array, and even edit a PDF directly from memory with C# code.
Jump right where you need
- Why Work with Byte Arrays and PDFs in C#?
- Convert Byte Array to PDF in C#
- Convert PDF to Byte Array in C#
- Create and Edit PDF Directly from a Byte Array
- Advantages of Using Spire.PDF for .NET
- Conclusion
- FAQ
Why Work with Byte Arrays and PDFs in C#?
Using byte[] as the transport format lets you avoid temporary files and makes your code friendlier to cloud and container environments.
- Database storage (BLOB): Persist PDFs as raw bytes; hydrate only when needed.
- Web APIs: Send/receive PDFs over HTTP without touching disk.
- In-memory processing: Transform or watermark PDFs entirely in streams.
- Security & isolation: Limit file I/O, reduce temp-file risks.
Getting set up: before running the examples, add the NuGet package of Spire.PDF for .NET so the API surface is available in your project.
Install-Package Spire.PDF
Once installed, you can load from byte[] or Stream, edit pages, and write outputs back to memory or disk—no extra converters required.
Convert Byte Array to PDF in C#
When an upstream service (e.g., an API or message queue) hands you a byte[] that represents a PDF, you often need to materialize it as a document for further processing or for a one-time save to disk. With Spire.PDF for .NET, this is a direct load operation—no intermediate temp file.
Scenario & approach: we’ll accept a byte[] (from DB/API), construct a PdfDocument in memory, optionally validate basic metadata, and then save the document.
using Spire.Pdf;
using System.IO;
class Program
{
static void Main()
{
// Example source: byte[] retrieved from DB/API
byte[] pdfBytes = File.ReadAllBytes("Sample.pdf"); // substitute with your source
// 1) Load PDF from raw bytes (in memory)
PdfDocument doc = new PdfDocument();
doc.LoadFromBytes(pdfBytes);
// 2) (Optional) inspect basic info before saving or further processing
// int pageCount = doc.Pages.Count;
// 3) Save to a file
doc.SaveToFile("Output.pdf");
doc.Close();
}
}
The diagram below illustrates the byte[] to PDF conversion workflow:
What the code is doing & why it matters:
- LoadFromBytes(byte[]) initializes the PDF entirely in memory—perfect for services without write access.
- You can branch after loading: validate pages, redact, stamp, or route elsewhere.
- SaveToFile(string) saves the document to disk for downstream processing or storing.
Convert PDF to Byte Array in C#
In the reverse direction, converting a PDF to a byte[] enables database writes, caching, or streaming the file through an HTTP response. Spire.PDF for .NET writes directly to a MemoryStream, which you can convert to a byte array with ToArray().
Scenario & approach: load an existing PDF, push the document into a MemoryStream, then extract the byte[]. This pattern is especially useful when returning PDFs from APIs or persisting them to databases.
using Spire.Pdf;
using System.IO;
class Program
{
static void Main()
{
// 1) Load a PDF from disk, network share, or embedded resource
PdfDocument doc = new PdfDocument();
doc.LoadFromFile("Input.pdf");
// 2) Save to a MemoryStream for fileless output
byte[] pdfBytes;
using (var ms = new MemoryStream())
{
doc.SaveToStream(ms);
pdfBytes = ms.ToArray();
}
doc.Close();
// pdfBytes now contains the full document (ready for DB/API)
// e.g., return File(pdfBytes, "application/pdf");
}
}
The diagram below shows the PDF to byte[] conversion workflow:
Key takeaways after the code:
- SaveToStream → ToArray is the standard way to obtain a PDF as bytes in C# without creating temp files.
- This approach scales for large PDFs; the only limit is available memory.
- Great for ASP.NET: return the byte array directly in your controller or minimal API endpoint.
If you want to learn more about working with streams, check out our guide on loading and saving PDF documents via streams in C#.
Create and Edit PDF Directly from a Byte Array
The real power comes from editing PDFs fully in memory. You can load from byte[], add text or images, stamp a watermark, fill form fields, and save the edited result back into a new byte[]. This enables fileless pipelines and is well-suited for microservices.
Scenario & approach: we’ll load a PDF from bytes, draw a small text annotation on page 1 (stand-in for any edit operation), and emit the edited document as a fresh byte array.
using Spire.Pdf;
using Spire.Pdf.Graphics;
using System.Drawing;
using System.IO;
class Program
{
static void Main()
{
// Source could be DB, API, or file — represented as byte[]
byte[] inputBytes = File.ReadAllBytes("Input.pdf");
// 1) Load in memory
var doc = new PdfDocument();
doc.LoadFromBytes(inputBytes);
// 2) Edit: write a small marker on the first page
PdfPageBase page = doc.Pages[0];
page.Canvas.DrawString(
"Edited in memory",
new PdfFont(PdfFontFamily.Helvetica, 12f),
PdfBrushes.DarkBlue,
new PointF(100, page.Size.Height - 100)
);
// 3) Save the edited PDF back to byte[]
byte[] editedBytes;
using (var ms = new MemoryStream())
{
doc.SaveToStream(ms);
editedBytes = ms.ToArray();
}
doc.Close();
// editedBytes can now be persisted or returned by an API
}
}
The image below shows the edited PDF page:
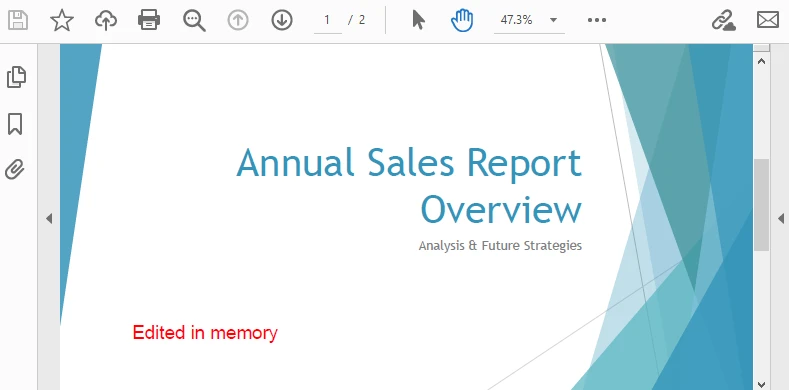
After-code insights:
- The same pattern works for text, images, watermarks, annotations, and form fields.
- Keep edits idempotent (e.g., check if you already stamped a page) for safe reprocessing.
- For ASP.NET, this is ideal for on-the-fly stamping or conditional redaction before returning the response.
For a step-by-step tutorial on building a PDF from scratch, see our article on creating PDF documents in C#.
Advantages of Using Spire.PDF for .NET
A concise view of why this API pairs well with byte-array workflows:
| Concern | What you get with Spire.PDF for .NET |
|---|---|
| I/O flexibility | Load/save from file path, Stream, or byte[] with the same PdfDocument API. |
| In-memory editing | Draw text/images, manage annotations/forms, watermark, and more—no temp files. |
| Service-friendly | Clean integration with ASP.NET endpoints and background workers. |
| Scales to real docs | Handles multi-page PDFs; you control memory via streams. |
| Straightforward code | Minimal boilerplate; avoids manual byte fiddling and fragile interop. |
Conclusion
You’ve seen how to convert byte array to PDF in C#, how to convert PDF to byte array, and how to edit a PDF directly from memory—all with concise code. Keeping everything in streams and byte[] simplifies API design, accelerates response times, and plays nicely with databases and cloud hosting. Spire.PDF for .NET gives you a consistent, fileless workflow that’s easy to extend from quick conversions to full in-memory document processing.
If you want to try these features without limitations, you can request a free 30-day temporary license. Alternatively, you can explore Free Spire.PDF for .NET for lightweight PDF tasks.
FAQ
Can I create a PDF from a byte array in C# without saving to disk?
Yes. Load from byte[] with LoadFromBytes, then either save to a MemoryStream or return it directly from an API—no disk required.
How do I convert PDF to byte array in C# for database storage?
Use SaveToStream on PdfDocument and call ToArray() on the MemoryStream. Store that byte[] as a BLOB (or forward it to another service).
Can I edit a PDF that only exists as a byte array?
Absolutely. Load from bytes, apply edits (text, images, watermarks, annotations, form fill), then save the result back to a new byte[].
Any tips for performance and reliability?
Dispose streams promptly, reuse buffers when appropriate, and create a new PdfDocument per operation/thread. For large files, stream I/O keeps memory usage predictable.

