

PDFs are ubiquitous in digital document management, but their rigid formatting often makes them less than ideal for content that needs to be easily edited, updated, or integrated into modern workflows. Markdown (.md), on the other hand, offers a lightweight, human-readable syntax perfect for web publishing, documentation, and version control. In this guide, we'll explore how to leverage the Spire.PDF for Python library to perform single or batch conversions from PDF to Markdown in Python efficiently.
- Why Convert PDFs to Markdown?
- Python PDF Converter Library – Installation
- Convert PDF to Markdown in Python
- Batch Convert Multiple PDFs to Markdown in Python
- Frequently Asked Questions
- Conclusion
Why Convert PDFs to Markdown?
Markdown offers several advantages over PDF for content creation and management:
- Version control friendly: Easily track changes in Git
- Lightweight and readable: Plain text format with simple syntax
- Editability: Simple to modify without specialized software
- Web integration: Natively supported by platforms like GitHub, GitLab, and static site generators (e.g., Jekyll, Hugo).
Spire.PDF for Python provides a robust solution for extracting text and structure from PDFs while preserving essential formatting elements like tables, lists, and basic styling.
Python PDF Converter Library - Installation
To use Spire.PDF for Python in your projects, you need to install the library via PyPI (Python Package Index) using pip. Open your terminal/command prompt and run:
pip install Spire.PDF
To upgrade an existing installation to the latest version:
pip install --upgrade spire.pdf
Convert PDF to Markdown in Python
Here’s a basic example demonstrates how to use Python to convert a PDF file to a Markdown (.md) file.
from spire.pdf.common import *
from spire.pdf import *
# Create an instance of PdfDocument class
pdf = PdfDocument()
# Load a PDF document
pdf.LoadFromFile("TestFile.pdf")
# Convert the PDF to a Markdown file
pdf.SaveToFile("PDFToMarkdown.md", FileFormat.Markdown)
pdf.Close()
This Python script loads a PDF file and then uses the SaveToFile() method to convert it to Markdown format. The FileFormat.Markdown parameter specifies the output format.
How Conversion Works
The library extracts text, images, tables, and basic formatting from the PDF and converts them into Markdown syntax.
- Text: Preserved with paragraphs/line breaks.
- Images: Images in the PDF are converted to base64-encoded PNG format and embedded directly in the Markdown.
- Tables: Tabular data is converted to Markdown table syntax (rows/columns with pipes |).
- Styling: Basic formatting (bold, italic) is retained using Markdown syntax.
Output: 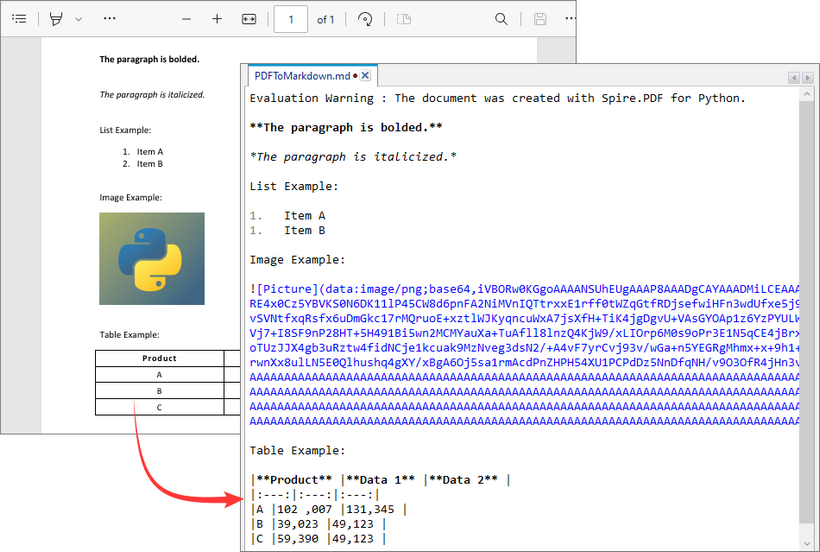
Batch Convert Multiple PDFs to Markdown in Python
This Python script uses a loop to convert all PDF files in a specified directory to Markdown format.
import os
from spire.pdf import *
# Configure paths
input_folder = "pdf_folder/"
output_folder = "markdown_output/"
# Create output directory
os.makedirs(output_folder, exist_ok=True)
# Process all PDFs in folder
for file_name in os.listdir(input_folder):
if file_name.endswith(".pdf"):
# Initialize document
pdf = PdfDocument()
pdf.LoadFromFile(os.path.join(input_folder, file_name))
# Generate output path
md_name = os.path.splitext(file_name)[0] + ".md"
output_path = os.path.join(output_folder, md_name)
# Convert to Markdown
pdf.SaveToFile(output_path, FileFormat.Markdown)
pdf.Close()
Key Characteristics
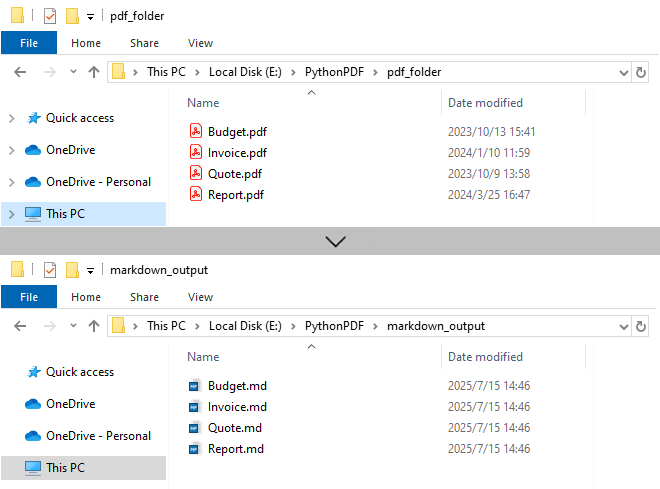
- Batch Processing: Automatically processes all PDFs in input folder, improving efficiency for bulk operations.
- 1:1 Conversion: Each PDF generates corresponding Markdown file.
- Sequential Execution: Files processed in alphabetical order.
- Resource Management: Each PDF is closed immediately after conversion.
Output:
Need to convert Markdown to PDF? Refer to: Convert Markdown to PDF in Python
Frequently Asked Questions (FAQs)
Q1: Is Spire.PDF for Python free?
A: Spire.PDF offers a free version with limitations (e.g., maximum 3 pages per conversion). For unlimited use, request a 30-day free trial for evaluation.
Q2: Can I convert password-protected PDFs to Markdown?
A: Yes. Use the LoadFromFile method with the password as a second parameter:
pdf.LoadFromFile("ProtectedFile.pdf", "your_password")
Q3: Can Spire.PDF convert scanned/image-based PDFs to Markdown?
A: No. The library extracts text-based content only. For scanned PDFs, use OCR tools (like Spire.OCR for Python) to create searchable PDFs first.
Conclusion
Spire.PDF for Python simplifies PDF to Markdown conversion for both single file and batch processing.
Its advantages include:
- Simple API with minimal code
- Preservation of document structure
- Batch processing capabilities
- Cross-platform compatibility
Whether you're migrating documentation, processing research papers, or building content pipelines, by following the examples in this guide, you can efficiently transform static PDF documents into flexible, editable Markdown content, streamlining workflows and improving collaboration.

