
When it comes to working with web content and documents, the ability to parse HTML in Python is an essential skill for developers across various domains. HTML parsing involves extracting meaningful information from HTML documents, manipulating content, and processing web data efficiently. Whether you're working on web scraping projects, data extraction tasks, content analysis, or document processing, mastering HTML parsing techniques in Python can significantly enhance your productivity and capabilities.
In this guide, we'll explore how to effectively read HTML in Python using Spire.Doc for Python. You'll learn practical techniques for processing HTML content from strings, local files, and URLs, and implementing best practices for HTML parsing in your projects.
- Why Parse HTML in Python?
- Getting Started: Install HTML Parser in Python
- How Spire.Doc Parses HTML: Core Concepts
- Best Practices for Effective HTML Parsing
- Conclusion
Why Parse HTML in Python?
HTML (HyperText Markup Language) is the backbone of the web, used to structure and present content on websites. Parsing HTML enables you to:
- Extract specific data (text, images, tables, hyperlinks) from web pages or local files.
- Analyze content structure for trends, keywords, or patterns.
- Automate data collection for research, reporting, or content management.
- Clean and process messy HTML into structured data.
While libraries like BeautifulSoup excel at lightweight parsing, Spire.Doc for Python shines when you need to integrate HTML parsing with document creation or conversion. It offers a robust framework to parse and interact with HTML content as a structured document object model (DOM).
Getting Started: Install HTML Parser in Python
Before diving into parsing, you’ll need to install Spire.Doc for Python. The library is available via PyPI, making installation straightforward:
pip install Spire.Doc
This command installs the latest version of the library, along with its dependencies. Once installed, you’re ready to start parsing HTML.
How Spire.Doc Parses HTML: Core Concepts
At its core, Spire.Doc parses HTML by translating HTML’s tag-based structure into a hierarchical document model. This model is composed of objects that represent sections, paragraphs, and other elements, mirroring the original HTML’s organization. Let’s explore how this works in practice.
1. Parsing HTML Strings in Python
If you have a small HTML snippet (e.g., from an API response or user input), parse it directly from a string. This is great for testing or working with short, static HTML.
from spire.doc import *
from spire.doc.common import *
# Define HTML content as a string
html_string = """
<html>
<head>
<title>Sample HTML</title>
</head>
<body>
<h1>Main Heading</h1>
<p>This is a paragraph with <strong>bold text</strong>.</p>
<div>
<p>A nested paragraph inside a div.</p>
</div>
<ul>
<li>List item 1</li>
<li>List item 2</li>
<li>List item 3</li>
</ul>
</body>
</html>
"""
# Initialize a new Document object
doc = Document()
# Add a section and paragraph to the document
section = doc.AddSection()
paragraph = section.AddParagraph()
# Load HTML content from the string
paragraph.AppendHTML(html_string)
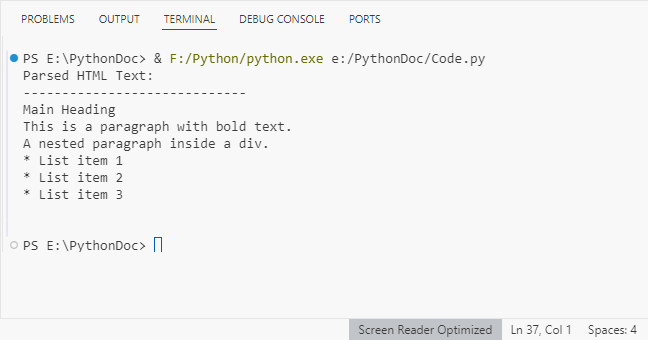
print("Parsed HTML Text:")
print("-----------------------------")
# Extract text content from the parsed HTML
parsed_text = doc.GetText()
# Print the result
print(parsed_text)
# Close the document
doc.Close()
How It Works:
- HTML String: We define a sample HTML snippet with common elements (headings, paragraphs, lists).
- Document Setup: Spire.Doc uses a Word-like structure (sections → paragraphs) to organize parsed HTML.
- Parse HTML:
AppendHTML()converts the string into structured Word elements (e.g.,<h1>becomes a "Heading 1" style,<ul>becomes a list). - Extract Text:
GetText()pulls clean, plain text from the parsed document (no HTML tags).
Output:
Spire.Doc supports exporting parsed HTML content to multiple formats such as TXT, Word via the SaveToFile() method.
2. Parsing HTML Files in Python
For local HTML files, Spire.Doc can load and parse them with a single method. This is useful for offline content (e.g., downloaded web pages, static reports).
from spire.doc import *
from spire.doc.common import *
# Define the path to your local HTML file
html_file_path = "example.html"
# Create a Document instance
doc = Document()
# Load and parse the HTML file
doc.LoadFromFile(html_file_path, FileFormat.Html)
# Analyze document structure
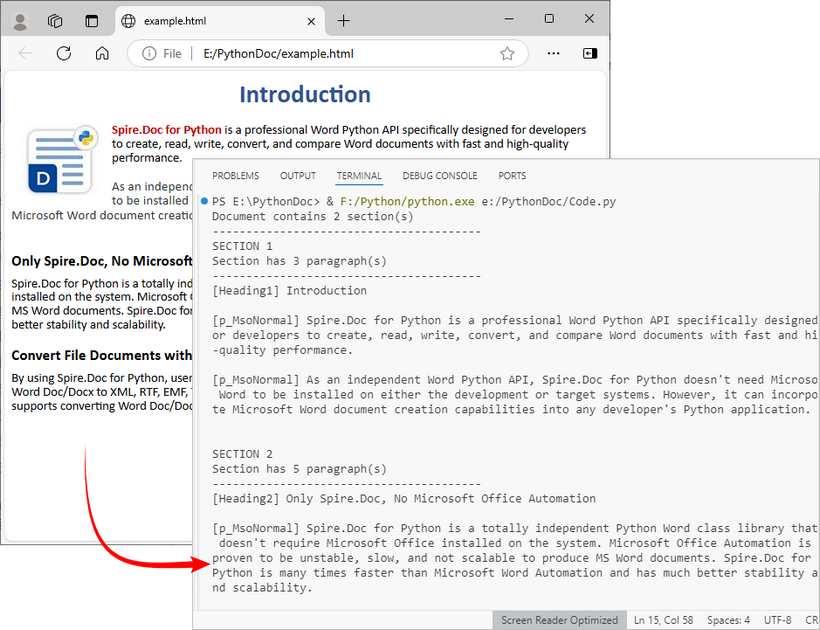
print(f"Document contains {doc.Sections.Count} section(s)")
print("-"*40)
# Process each section
for section_idx in range(doc.Sections.Count):
section = doc.Sections.get_Item(section_idx)
print(f"SECTION {section_idx + 1}")
print(f"Section has {section.Body.Paragraphs.Count} paragraph(s)")
print("-"*40)
# Traverse through paragraphs in the current section
for para_idx in range(section.Paragraphs.Count):
para = section.Paragraphs.get_Item(para_idx)
# Get paragraph style name and text content
style_name = para.StyleName
para_text = para.Text
# Print paragraph information if content exists
if para_text.strip():
print(f"[{style_name}] {para_text}\n")
# Add spacing between sections
print()
# Close the document
doc.Close()
Key Features:
- Load Local Files:
LoadFromFile()reads the HTML file and auto-parses it into a Word structure. - Structure Analysis: Check the number of sections/paragraphs and their styles (critical for auditing content).
- Style Filtering: Identify headings (e.g., "Heading 1") or lists (e.g., "List Paragraph") to organize content.
Output:
After loading the HTML file into the Document object, you can use Spire.Doc to extract specific elements like tables, hyperlinks from HTML.
3. Parsing a URL in Python
To parse HTML directly from a live web page, first fetch the HTML content from the URL using a library like requests, then pass the content to Spire.Doc for parsing. This is core for web scraping and real-time data extraction.
Install the Requests library via pip:
pip install requests
Python code to parse web page:
from spire.doc import *
from spire.doc.common import *
import requests
# Fetch html content from a URL
def fetch_html_from_url(url):
"""Fetch HTML from a URL and handle errors (e.g., 404, network issues)"""
# Mimic a browser with User-Agent (avoids being blocked by websites)
headers = {
"User-Agent": "Mozilla/5.0 (Windows NT 10.0; Win64; x64)"
}
try:
response = requests.get(url, headers=headers)
response.raise_for_status() # Raise exception for HTTP errors
return response.text # Return raw HTML content
except requests.exceptions.RequestException as e:
raise Exception(f"Error fetching HTML: {str(e)}")
# Specify the target URL
url = "https://www.e-iceblue.com/privacypolicy.html"
print(f"Fetching HTML from: {url}")
# Get HTML content
html_content = fetch_html_from_url(url)
# Create document and insert HTML content into it
doc = Document()
section = doc.AddSection()
paragraph = section.AddParagraph()
paragraph.AppendHTML(html_content)
# Extract and display summary information
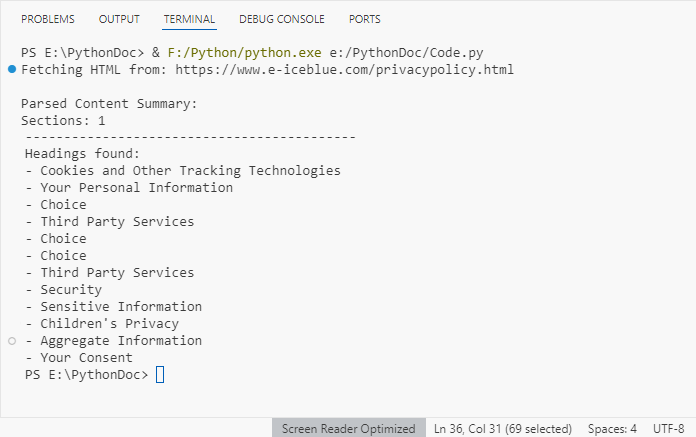
print("\nParsed Content Summary:")
print(f"Sections: {doc.Sections.Count}")
print("-------------------------------------------")
# Extract and display headings
print("Headings found:")
for para_idx in range(section.Paragraphs.Count):
para = section.Paragraphs.get_Item(para_idx)
if isinstance(para, Paragraph) and para.StyleName.startswith("Heading"):
print(f"- {para.Text.strip()}")
# Close the document
doc.Close()
Steps Explained:
- Use requests.get() to fetch the HTML content from the URL.
- Pass the raw HTML text to Spire.Doc for parsing.
- Extract specific content (e.g., headings) from live pages for SEO audits or content aggregation.
Output:
Best Practices for Effective HTML Parsing
To optimize your HTML parsing workflow with Spire.Doc, follow these best practices:
- Validate Input Sources: Before parsing, check that HTML content (strings or files) is accessible and not corrupted. This reduces parsing errors:
import os
html_file = "data.html"
if os.path.exists(html_file):
doc.LoadFromFile(html_file, FileFormat.Html)
else:
print(f"Error: File '{html_file}' not found.")
- Handle Exceptions: Wrap parsing operations in try-except blocks to catch catch errors (e.g., missing files, invalid HTML):
try:
doc.LoadFromFile("sample.html", FileFormat.Html)
except Exception as e:
print(f"Error loading HTML: {e}")
- Optimize for Large Files: For large HTML files, consider loading content in chunks or disabling non-essential parsing features to improve performance.
- Clean Extracted Data: Use Python’s string methods (e.g., strip(), replace()) to remove extra whitespace or unwanted characters from extracted text.
- Keep the Library Updated: Regularly update Spire.Doc with
pip install --upgrade Spire.Docto benefit from improved parsing logic and bug fixes.
Conclusion
Python makes HTML parsing accessible for all skill levels. Whether you’re working with HTML strings, local files, or remote URLs, the combination of Requests (for fetching) and Spire.Doc (for structuring) simplifies complex tasks like web scraping and content extraction.
By following the examples and best practices in this guide, you’ll turn unstructured HTML into actionable, organized data in minutes. To unlock the full potential of Spire.Doc for Python, you can request a 30-day trial license here.
