Java: Create PDF Portfolios
A PDF portfolio allows multiple files to be assembled into a single interactive PDF container. The files in a PDF portfolio can be text documents, spreadsheets, presentations, images, videos, audio files, and more. By creating PDF portfolios, you can consolidate all of the relevant materials for a project into one unified package, making it easier to manage and distribute files. This article will demonstrate how to programmatically create a PDF portfolio and add files and folders to it using Spire.PDF for Java.
Install Spire.PDF for Java
First of all, you're required to add the Spire.Pdf.jar file as a dependency in your Java program. The JAR file can be downloaded from this link. If you use Maven, you can easily import the JAR file in your application by adding the following code to your project's pom.xml file.
<repositories>
<repository>
<id>com.e-iceblue</id>
<name>e-iceblue</name>
<url>https://repo.e-iceblue.com/nexus/content/groups/public/</url>
</repository>
</repositories>
<dependencies>
<dependency>
<groupId>e-iceblue</groupId>
<artifactId>spire.pdf</artifactId>
<version>12.7.0</version>
</dependency>
</dependencies>
Create a PDF Portfolio and Add Files to It in Java
As a PDF portfolio is a collection of files, Spire.PDF for Java allows you to create it easily using the PdfDocument.getCollection() method. Then you can add files to the PDF portfolio using the PdfCollection.addFile() method. The detailed steps are as follows:
- Specify the files that need to be added to the PDF portfolio.
- Create a PdfDocument instance.
- Create a PDF portfolio and add files to it using PdfDocument.getCollection().addFile() method.
- Save the result file using PdfDocument.saveToFile() method.
- Java
import com.spire.pdf.FileFormat;
import com.spire.pdf.PdfDocument;
public class CreatePortfolioWithFiles {
public static void main(String []args){
// Specify the files
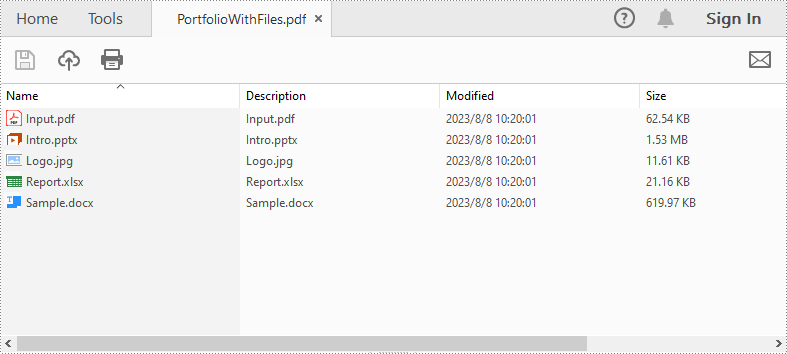
String[] files = new String[] { "Input.pdf", "Sample.docx", "Report.xlsx","Intro.pptx","Logo.jpg" };
//Create a PdfDocument instance
PdfDocument pdf = new PdfDocument();
//Create a PDF Portfolio and add files to it
for (int i = 0; i < files.length; i++)
{
pdf.getCollection().addFile(files[i]);
}
//Save the result file
pdf.saveToFile("PortfolioWithFiles.pdf", FileFormat.PDF);
pdf.dispose();
}
}
Create a PDF Portfolio and Add Folders to It in Java
After creating a PDF portfolio, Spire.PDF for Java also allows you to create folders within the PDF portfolio to further manage the files. The detailed steps are as follows:
- Specify the files that need to be added to the PDF portfolio.
- Create PdfDocument instance.
- Create a PDF portfolio using PdfDocument.getCollection() method.
- Add folders to the PDF portfolio using PdfCollection.getFolders().createSubfolder() method, and then add files to the folders using PdfFolder.addFile() method.
- Save the result file using PdfDocument.saveToFile() method.
- Java
import com.spire.pdf.FileFormat;
import com.spire.pdf.PdfDocument;
import com.spire.pdf.collections.PdfFolder;
public class CreatePortfolioWithFolders {
public static void main(String []args){
// Specify the files
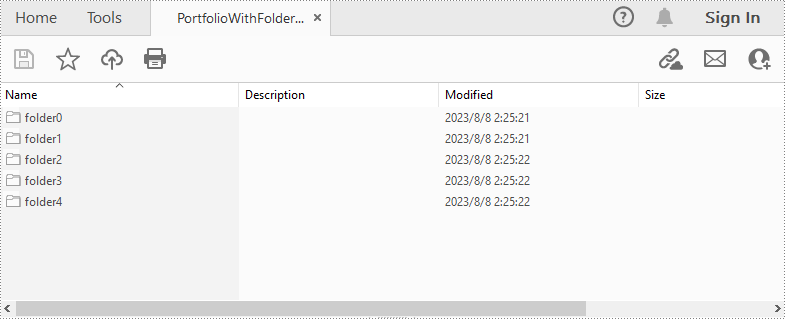
String[] files = new String[] { "Input.pdf", "Sample.docx", "Report.xlsx","Intro.pptx","Logo.jpg" };
//Create a PdfDocument instance
PdfDocument pdf = new PdfDocument();
//Create a portfolio and add folders to it
for (int i = 0; i < files.length; i++)
{
PdfFolder folder = pdf.getCollection().getFolders().createSubfolder("folder" + i);
//Add files to the folders
folder.addFile(files[i]);
}
//Save the result file
pdf.saveToFile("PortfolioWithFolders.pdf", FileFormat.PDF);
pdf.dispose();
}
}
Apply for a Temporary License
If you'd like to remove the evaluation message from the generated documents, or to get rid of the function limitations, please request a 30-day trial license for yourself.
Hide or display layers in PDF in Java
This article will demonstrate how to hide and display Layers in a PDF document using Spire.PDF for Java.
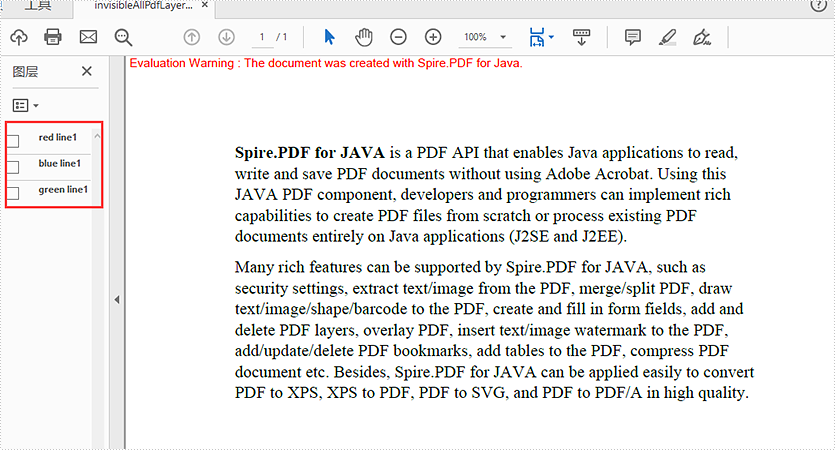
Hide all layers:
import com.spire.pdf.*;
import com.spire.pdf.graphics.layer.*;
public class invisibleAllPdfLayers {
public static void main(String[] args) {
//Load the sample document
PdfDocument doc = new PdfDocument();
doc.loadFromFile("layerSample.pdf");
for (int i = 0; i < doc.getLayers().getCount(); i++)
{
//Show all the Pdf layers
//doc.getLayers().get(i).setVisibility(PdfVisibility.On);
//Set all the Pdf layers invisible
doc.getLayers().get(i).setVisibility(PdfVisibility.Off);
}
//Save to document to file
doc.saveToFile("output/invisibleAllPdfLayers.pdf", FileFormat.PDF);
}
}
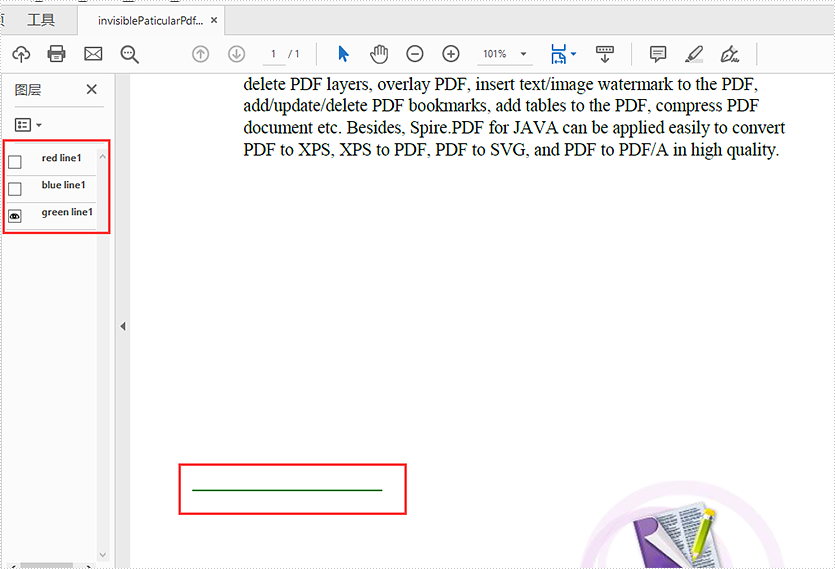
Hide some of the PDF layers:
import com.spire.pdf.*;
import com.spire.pdf.graphics.layer.*;
public class invisibleParticularPdfLayers {
public static void main(String[] args) {
//Load the sample document
PdfDocument doc = new PdfDocument();
doc.loadFromFile("layerSample.pdf");
//Hide the first layer by index
doc.getLayers().get(0).setVisibility(PdfVisibility.Off);
//Hide the layer by name with blue line1
for (int i = 0; i < doc.getLayers().getCount(); i++)
{
if("blue line1".equals(doc.getLayers().get(i).getName())){
doc.getLayers().get(i).setVisibility(PdfVisibility.Off);
}
}
//Save to document to file
doc.saveToFile("output/invisiblePaticularPdfLayers.pdf", FileFormat.PDF);
}
}
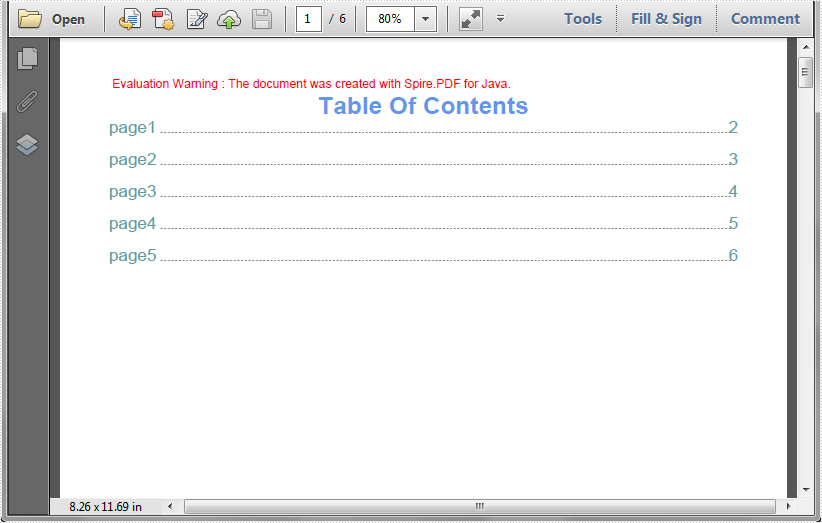
Create Table of Contents (TOC) in PDF in Java
Table of contents (TOC) makes the PDF documents more accessible and easier to navigate, especially for large files. This article demonstrates how to create table of contents (TOC) for a PDF document using Spire.PDF for Java.
import com.spire.pdf.*;
import com.spire.pdf.actions.PdfGoToAction;
import com.spire.pdf.annotations.*;
import com.spire.pdf.general.PdfDestination;
import com.spire.pdf.graphics.*;
import java.awt.*;
import java.awt.geom.*;
public class TableOfContent {
public static void main(String[] args) throws Exception
{
//load PDF file
PdfDocument doc = new PdfDocument("sample.pdf");
int pageCount = doc.getPages().getCount();
//Insert a new page as the first page to draw table of content
PdfPageBase tocPage = doc.getPages().insert(0);
//set title
String title = "Table Of Contents";
PdfTrueTypeFont titleFont = new PdfTrueTypeFont(new Font("Arial", Font.BOLD,20));
PdfStringFormat centerAlignment = new PdfStringFormat(PdfTextAlignment.Center, PdfVerticalAlignment.Middle);
Point2D location = new Point2D.Float((float) tocPage.getCanvas().getClientSize().getWidth() / 2, (float) titleFont.measureString(title).getHeight());
tocPage.getCanvas().drawString(title, titleFont, PdfBrushes.getCornflowerBlue(), location, centerAlignment);
//draw TOC text
PdfTrueTypeFont titlesFont = new PdfTrueTypeFont(new Font("Arial", Font.PLAIN,14));
String[] titles = new String[pageCount];
for (int i = 0; i < titles.length; i++) {
titles[i] = String.format("page%1$s", i + 1);
}
float y = (float)titleFont.measureString(title).getHeight() + 10;
float x = 0;
for (int i = 1; i <= pageCount; i++) {
String text = titles[i - 1];
Dimension2D titleSize = titlesFont.measureString(text);
PdfPageBase navigatedPage = doc.getPages().get(i);
String pageNumText = (String.valueOf(i+1));
Dimension2D pageNumTextSize = titlesFont.measureString(pageNumText);
tocPage.getCanvas().drawString(text, titlesFont, PdfBrushes.getCadetBlue(), 0, y);
float dotLocation = (float)titleSize.getWidth() + 2 + x;
float pageNumlocation = (float)(tocPage.getCanvas().getClientSize().getWidth() - pageNumTextSize.getWidth());
for (float j = dotLocation; j < pageNumlocation; j++) {
if (dotLocation >= pageNumlocation) {
break;
}
tocPage.getCanvas().drawString(".", titlesFont, PdfBrushes.getGray(), dotLocation, y);
dotLocation += 3;
}
tocPage.getCanvas().drawString(pageNumText, titlesFont, PdfBrushes.getCadetBlue(), pageNumlocation, y);
//add TOC action
Rectangle2D titleBounds = new Rectangle2D.Float(0,y,(float)tocPage.getCanvas().getClientSize().getWidth(),(float)titleSize.getHeight());
PdfDestination Dest = new PdfDestination(navigatedPage, new Point2D.Float(-doc.getPageSettings().getMargins().getTop(), -doc.getPageSettings().getMargins().getLeft()));
PdfActionAnnotation action = new PdfActionAnnotation(titleBounds, new PdfGoToAction(Dest));
action.setBorder(new PdfAnnotationBorder(0));
((PdfNewPage) ((tocPage instanceof PdfNewPage) ? tocPage : null)).getAnnotations().add(action);
y += titleSize.getHeight() + 10;
}
//save the resultant file
doc.saveToFile("addTableOfContent.pdf");
doc.close();
}
}
Output:
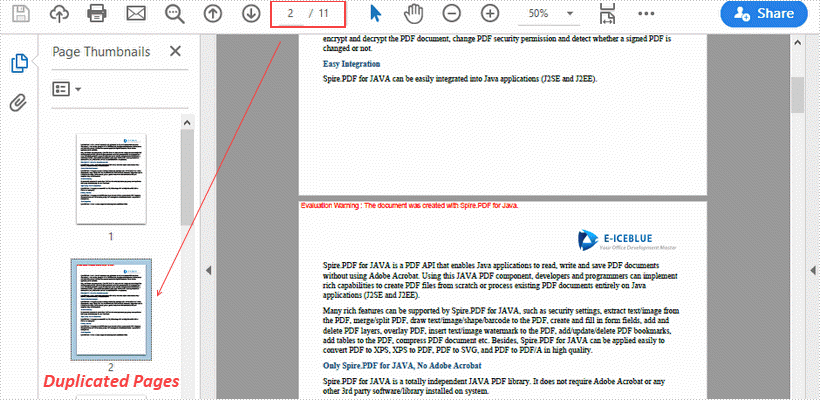
Duplicate a Page in PDF in Java
This article demonstrates how to duplicate a page within a PDF document using Spire.PDF for Java.
import com.spire.pdf.PdfDocument;
import com.spire.pdf.PdfPageBase;
import com.spire.pdf.graphics.PdfMargins;
import com.spire.pdf.graphics.PdfTemplate;
import java.awt.geom.Dimension2D;
import java.awt.geom.Point2D;
public class DuplicatePage {
public static void main(String[] args) {
//Load a sample PDF document
PdfDocument pdf = new PdfDocument("C:\\Users\\Administrator\\Desktop\\original.pdf");
//Get the first page
PdfPageBase page = pdf.getPages().get(0);
//Get the page size
Dimension2D size = page.getActualSize();
//Create a template based on the page
PdfTemplate template = page.createTemplate();
for (int i = 0; i < 10; i++) {
//Add a new page to the document
page = pdf.getPages().add(size, new PdfMargins(0));
//Draw template on the new page
page.getCanvas().drawTemplate(template, new Point2D.Float(0, 0));
}
//Save the file
pdf.saveToFile("output/DuplicatePage.pdf");
}
}
Java: Add, Hide or Delete Layers in PDF
PDF layers are supported through the usage of Optional Content Group (OCG) objects. As its name implies, optional content refers to the content in a PDF document that can be made visible or invisible dynamically by the user of PDF viewer applications. In this article, you will learn how to programmatically add, hide or delete layers in a PDF file using Spire.PDF for Java.
- Add Layers to a PDF Document in Java
- Set Visibility of Layers in a PDF Document in Java
- Delete Layers in a PDF Document in Java
Install Spire.PDF for Java
First of all, you're required to add the Spire.Pdf.jar file as a dependency in your Java program. The JAR file can be downloaded from this link. If you use Maven, you can easily import the JAR file in your application by adding the following code to your project's pom.xml file.
<repositories>
<repository>
<id>com.e-iceblue</id>
<name>e-iceblue</name>
<url>https://repo.e-iceblue.com/nexus/content/groups/public/</url>
</repository>
</repositories>
<dependencies>
<dependency>
<groupId>e-iceblue</groupId>
<artifactId>spire.pdf</artifactId>
<version>12.7.0</version>
</dependency>
</dependencies>
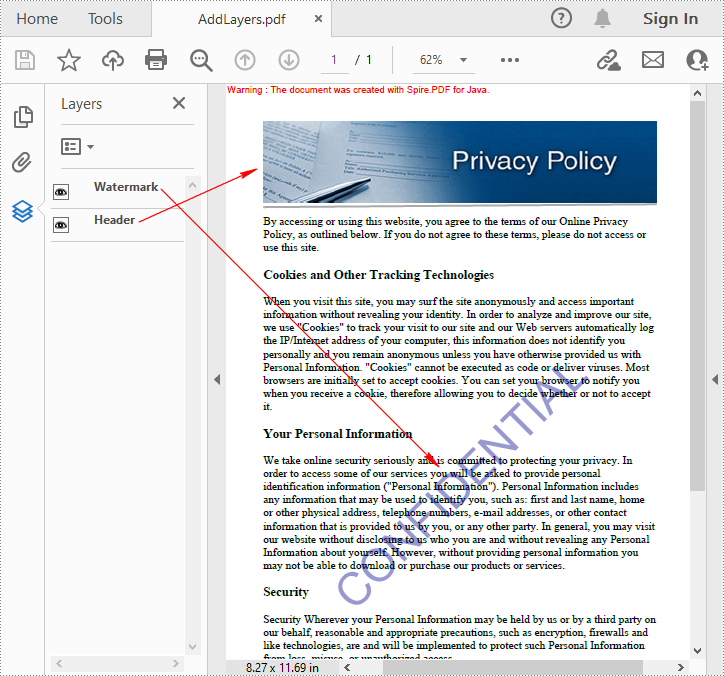
Add Layers to a PDF Document in Java
Spire.PDF for Java provides PdfDocument.getLayers().addLayer() method to add a layer in a PDF document, and you can then draw text, lines, images or shapes on the PDF layer. The detailed steps are as follows.
- Create a PdfDocument instance.
- Load a sample PDF file using PdfDocument.loadFromFile() method.
- Add a layer with specified name in the PDF using PdfDocument.getLayers().addLayer(java.lang.String name) method. Or you can also set the visibility of the layer while adding it using PdfDocument. getLayers().addLayer(java.lang.String name, PdfVisibility state) method.
- Create a canvas for the layer using PdfLayer.createGraphics() method.
- Draw text, image or other elements on the canvas.
- Save the result document using PdfDocument.saveToFile() method.
- Java
import com.spire.pdf.PdfDocument;
import com.spire.pdf.PdfPageBase;
import com.spire.pdf.graphics.*;
import com.spire.pdf.graphics.layer.PdfLayer;
import java.awt.*;
import java.awt.geom.Dimension2D;
import java.io.IOException;
public class AddLayersToPdf {
public static void main(String[] args) throws IOException {
//Create a PdfDocument instance and load the sample PDF file
PdfDocument pdf = new PdfDocument();
pdf.loadFromFile("C:\\Users\\Administrator\\Desktop\\Sample.pdf");
//Invoke AddLayerWatermark method to add a watermark layer
AddLayerWatermark(pdf);
//Invoke AddLayerHeader method to add a header layer
AddLayerHeader(pdf);
//Save to file
pdf.saveToFile("AddLayers.pdf");
pdf.close();
}
private static void AddLayerWatermark(PdfDocument doc) throws IOException {
//Create a layer named "watermark"
PdfLayer layer = doc.getLayers().addLayer("Watermark");
//Create a font
PdfTrueTypeFont font = new PdfTrueTypeFont(new Font("Arial", Font.PLAIN,48),true);
//Specify watermark text
String watermarkText = "CONFIDENTIAL";
//Get text size
Dimension2D fontSize = font.measureString(watermarkText);
//Calculate two offsets
float offset1 = (float)(fontSize.getWidth() * Math.sqrt(2) / 4);
float offset2 = (float)(fontSize.getHeight() * Math.sqrt(2) / 4);
//Get page count
int pageCount = doc.getPages().getCount();
//Declare two variables
PdfPageBase page;
PdfCanvas canvas;
//Loop through the pages
for (int i = 0; i < pageCount; i++) {
page = doc.getPages().get(i);
//Create a canvas from layer
canvas = layer.createGraphics(page.getCanvas());
canvas.translateTransform(canvas.getSize().getWidth() / 2 - offset1 - offset2, canvas.getSize().getHeight() / 2 + offset1 - offset2);
canvas.setTransparency(0.4f);
canvas.rotateTransform(-45);
//Draw sting on the canvas of layer
canvas.drawString(watermarkText, font, PdfBrushes.getDarkBlue(), 0, 0);
}
}
private static void AddLayerHeader(PdfDocument doc) {
//Create a layer named "header"
PdfLayer layer = doc.getLayers().addLayer("Header");
//Get page size
Dimension2D size = doc.getPages().get(0).getSize();
//Specify the initial values of X and y
float x = 90;
float y = 40;
//Get page count
int pageCount = doc.getPages().getCount();
//Declare two variables
PdfPageBase page;
PdfCanvas canvas;
//Loop through the pages
for (int i = 0; i < pageCount; i++) {
//Draw an image on the layer
PdfImage pdfImage = PdfImage.fromFile("C:\\Users\\Administrator\\Desktop\\img.jpg");
float width = pdfImage.getWidth();
float height = pdfImage.getHeight();
page = doc.getPages().get(i);
canvas = layer.createGraphics(page.getCanvas());
canvas.drawImage(pdfImage, x, y, width, height);
//Draw a line on the layer
PdfPen pen = new PdfPen(PdfBrushes.getDarkGray(), 2f);
canvas.drawLine(pen, x, y + height + 5, size.getWidth() - x, y + height + 2);
}
}
}
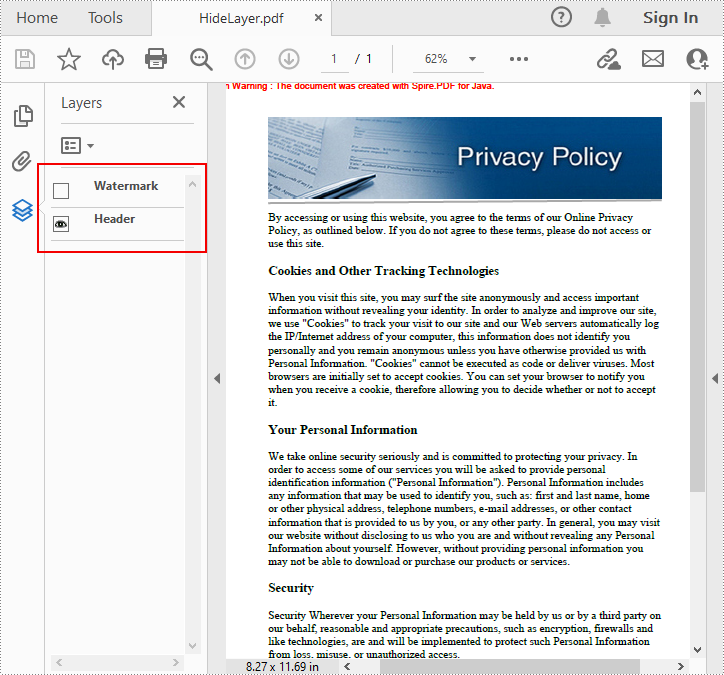
Set Visibility of Layers in a PDF Document in Java
To set the visibility of an existing layer, you'll need to get a specified layer by its index or name using PdfDocument.getLayers().get() method, and then show or hide the layer using PdfLayer.setVisibility(PdfVisibility value) method. The detailed steps are as follows.
- Create a PdfDocument instance.
- Load a sample PDF document using PdfDocument.loadFromFile() method.
- Set the visibility of a specified layer using PdfDocument.getLayers().get().setVisibility() method.
- Save the result document using PdfDocument.saveToFile() method.
- Java
import com.spire.pdf.FileFormat;
import com.spire.pdf.PdfDocument;
import com.spire.pdf.graphics.layer.PdfVisibility;
public class SetLayerVisibility {
public static void main(String[] args) {
//Create a PdfDocument instance
PdfDocument pdf = new PdfDocument();
//Load a sample PDF file
pdf.loadFromFile("AddLayers.pdf");
//Set the visibility of the first layer to off
pdf.getLayers().get(0).setVisibility(PdfVisibility.Off);
//Save to file
pdf.saveToFile("HideLayer.pdf", FileFormat.PDF);
pdf.dispose();
}
}
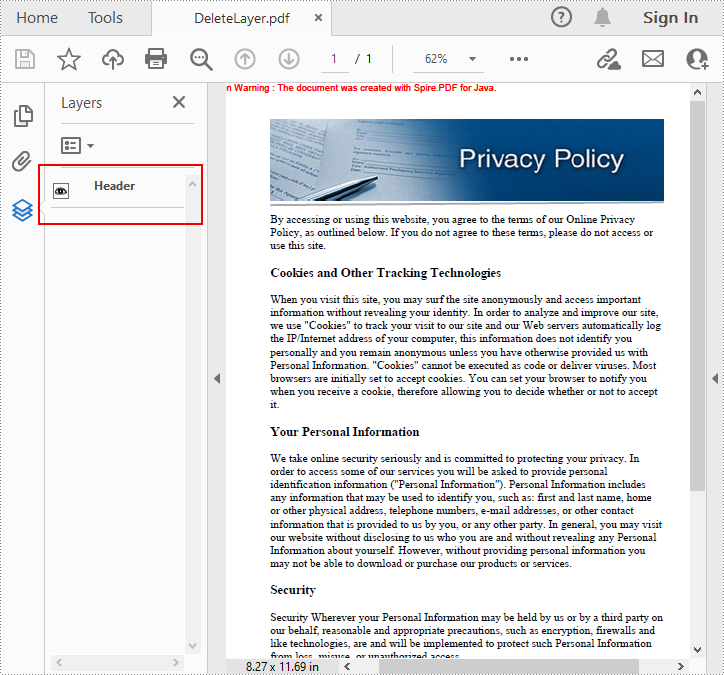
Delete Layers in a PDF Document in Java
Spire.PDF for Java also allows you to remove an existing layer by its name using PdfDocument.getLayers().removeLayer(java.lang.String name) method. But kindly note that the names of PDF layers may not be unique and this method will remove all PDF layers with the same name. The detailed steps are as follows.
- Create a PdfDocument instance.
- Load a sample PDF document using PdfDocument.LoadFromFile() method.
- Delete a specified layer by its name using PdfDocument.getLayers().removeLayer() method.
- Save the result document using PdfDocument.saveToFile() method.
- Java
import com.spire.pdf.PdfDocument;
public class DeleteLayers {
public static void main(String[] args) {
//Create a PdfDocument object and load the sample PDF file
PdfDocument pdf = new PdfDocument();
pdf.loadFromFile("AddLayers.pdf");
//Delete the specific layer by its name
pdf.getLayers().removeLayer("Watermark");
//Save to file
pdf.saveToFile("DeleteLayer.pdf");
pdf.close();
}
}
Apply for a Temporary License
If you'd like to remove the evaluation message from the generated documents, or to get rid of the function limitations, please request a 30-day trial license for yourself.
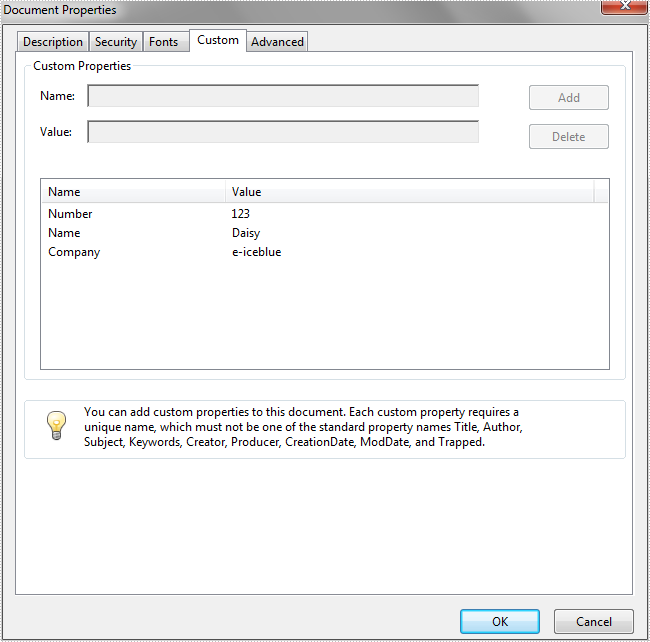
Set custom properties for PDF files in Java
We have already demonstrated how to set PDF Document Properties in Java. This article we will show you how to set custom properties for PDF files in Java.
import com.spire.pdf.*;
public class PDFCustomProperties {
public static void main(String[] args) throws Exception {
String inputPath = "Sample.pdf";
PdfDocument doc = new PdfDocument(inputPath);
doc.loadFromFile(inputPath);
//Set the custom properties
doc.getDocumentInformation().setCustomProperty("Number", "123");
doc.getDocumentInformation().setCustomProperty("Name", "Daisy");
doc.getDocumentInformation().setCustomProperty("Company", "e-iceblue");"
//Save the document to file
doc.saveToFile("Output/result.pdf");
doc.close();
}
}
Effective screenshot after adding custom properties to PDF document:
Master PDF Compression in Java: Reduce PDF File Size Efficiently

Handling large PDF files is a common challenge for Java developers. PDFs with high-resolution images, embedded fonts, and multimedia content can quickly become heavy, slowing down applications, increasing storage costs, and creating a poor user experience—especially on mobile devices.
Mastering PDF compression in Java is essential to reduce file size efficiently while maintaining document quality. This step-by-step guide demonstrates how to compress and optimize PDF files in Java. You’ll learn how to compress document content, optimize images, fonts, and metadata, ensuring faster file transfers, improved performance, and a smoother user experience in your Java applications.
What You Will Learn
- Setting Up Your Development Environment
- Reduce PDF File Size by Compressing Document Content in Java
- Reduce PDF File Size by Optimizing Specific Elements in Java
- Full Java Example that Combines All PDF Compressing Techniques
- Best Practices for PDF Compression
- Conclusion
- FAQs
1. Setting Up Your Development Environment
Before implementing PDF compression in Java, ensure your development environment is properly configured.
1.1. Prerequisites
- Java Development Kit (JDK): Ensure you have JDK 1.8 or later installed.
- Build Tool: Maven or Gradle is recommended for dependency management.
- Integrated Development Environment (IDE): IntelliJ IDEA or Eclipse is suitable.
1.2. Adding Dependencies
To programmatically compress PDF files, you need a PDF library that supports compression features. Spire.PDF for Java provides APIs for loading, reading, editing, and compressing PDF documents. You can include it via Maven or Gradle.
Maven (pom.xml):
Add the following repository and dependency to your project's pom.xml file within the <repositories> and <dependencies> tags, respectively:
<repositories>
<repository>
<id>com.e-iceblue</id>
<name>e-iceblue</name>
<url>https://repo.e-iceblue.com/nexus/content/groups/public/</url>
</repository>
</repositories>
<dependencies>
<dependency>
<groupId>e-iceblue</groupId>
<artifactId>spire.pdf</artifactId>
<version>12.7.0</version>
</dependency>
</dependencies>
Gradle (build.gradle):
For Gradle users, add the repository and dependency as follows:
repositories {
mavenCentral()
maven {
url "https://repo.e-iceblue.com/nexus/content/groups/public/"
}
}
dependencies {
implementation 'e-iceblue:spire.pdf:11.8.0'
}
After adding the dependency, refresh your Maven or Gradle project to download the necessary JAR files.
2. Reduce PDF File Size by Compressing Document Content in Java
One of the most straightforward techniques for reducing PDF file size is to apply document content compression. This approach automatically compresses the internal content streams of the PDF, such as text and graphics data, without requiring any manual fine-tuning. It is especially useful when you want a quick and effective solution that minimizes file size while maintaining document integrity.
The following example demonstrates how to enable and apply content compression in a PDF file using Java.
import com.spire.pdf.conversion.compression.PdfCompressor;
public class CompressContent {
public static void main(String[] args){
// Create a compressor
PdfCompressor compressor = new PdfCompressor("test.pdf");
// Enable document content compression
compressor.getOptions().setCompressContents(true);
// Compress and save
compressor.compressToFile("ContentCompression.pdf");
}
}
Key Points:
- setCompressContents(true) enables document content compression.
- Original PDFs remain unchanged; compressed files are saved separately.
3. Reduce PDF File Size by Optimizing Specific Elements in Java
Beyond compressing content streams, developers can also optimize individual elements of the PDF, such as images, fonts, and metadata. This allows for granular control over file size optimization.
3.1. Image Compression
Images are frequently the primary reason for large files. By lowering the image quality, you can significantly minimize the size of image-heavy PDF files.
import com.spire.pdf.conversion.compression.ImageCompressionOptions;
import com.spire.pdf.conversion.compression.ImageQuality;
import com.spire.pdf.conversion.compression.PdfCompressor;
public class CompressImages {
public static void main(String[] args){
// Load the PDF document
PdfCompressor compressor = new PdfCompressor("test.pdf");
// Get image compression options
ImageCompressionOptions imageCompression = compressor.getOptions().getImageCompressionOptions();
// Compress images and set quality
imageCompression.setCompressImage(true); // Enable image compression
imageCompression.setImageQuality(ImageQuality.Low); // Set image quality (Low, Medium, High)
imageCompression.setResizeImages(true); // Resize images to reduce size
// Save the compressed PDF
compressor.compressToFile("ImageCompression.pdf");
}
}
Key Points:
- setCompressImage(true) enables image compression.
- setImageQuality(...) adjusts the output image quality; the lower the quality, the smaller the image size.
- setResizeImages(true) enables image resizing.
3.2. Font Compression or Unembedding
When a PDF uses custom fonts, the entire font file might be embedded, even if only a few characters are used. Font compression or unembedding is a technique that reduces the size of embedded fonts by compressing them or removing them entirely from the PDF.
import com.spire.pdf.conversion.compression.PdfCompressor;
import com.spire.pdf.conversion.compression.TextCompressionOptions;
public class CompressPDFWithOptions {
public static void main(String[] args){
// Load the PDF document
PdfCompressor compressor = new PdfCompressor("test.pdf");
// Get text compression options
TextCompressionOptions textCompression = compressor.getOptions().getTextCompressionOptions();
// Compress fonts
textCompression.setCompressFonts(true);
// Optional: unembed fonts to reduce size
// textCompression.setUnembedFonts(true);
// Save the compressed PDF
compressor.compressToFile("FontOptimization.pdf");
}
}
Key Points:
- setCompressFonts(true) compresses embedded fonts while preserving document appearance.
- setUnembedFonts(true) removes embedded fonts entirely, which may reduce file size but could affect text rendering if the fonts are not available on the system.
3.3 Metadata Removal
PDFs often store metadata such as author details, timestamps, and editing history that aren’t needed for viewing. Removing metadata reduces file size and protects sensitive information.
import com.spire.pdf.conversion.compression.PdfCompressor;
public class CompressPDFWithOptions {
public static void main(String[] args){
// Load the PDF document
PdfCompressor compressor = new PdfCompressor("test.pdf");
// Remove metadata
compressor.getOptions().setRemoveMetadata(true);
// Save the compressed PDF
compressor.compressToFile("MetadataRemoval.pdf");
}
}
4. Full Java Example that Combines All PDF Compressing Techniques
After exploring both document content compression and element-specific optimizations (images, fonts, and metadata), let’s explore how to apply all these techniques together in one workflow.
import com.spire.pdf.conversion.compression.ImageQuality;
import com.spire.pdf.conversion.compression.OptimizationOptions;
import com.spire.pdf.conversion.compression.PdfCompressor;
public class CompressPDFWithAllTechniques {
public static void main(String[] args){
// Initialize compressor
PdfCompressor compressor = new PdfCompressor("test.pdf");
// Enable document content compression
OptimizationOptions options = compressor.getOptions();
options.setCompressContents(true);
// Optimize images (downsampling and compression)
options.getImageCompressionOptions().setCompressImage(true);
options.getImageCompressionOptions().setImageQuality(ImageQuality.Low);
options.getImageCompressionOptions().setResizeImages(true);
// Optimize fonts (compression or unembedding)
// Compress fonts
options.getTextCompressionOptions().setCompressFonts(true);
// Optional: unembed fonts to reduce size
// options.getTextCompressionOptions().setUnembedFonts(true);
// Remove unnecessary metadata
options.setRemoveMetadata(true);
// Save the compressed PDF
compressor.compressToFile("CompressPDFWithAllTechniques.pdf");
}
}
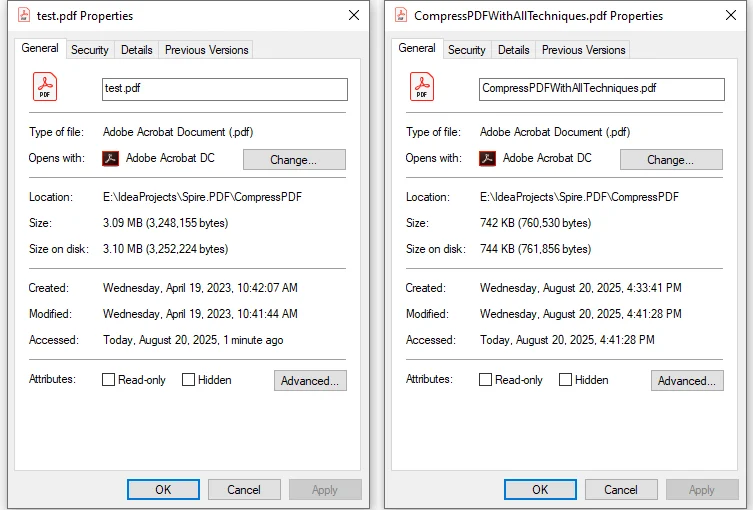
Reviewing the Compression Effect:
After running the code, the original sample PDF of 3.09 MB was reduced to 742 KB. The compression ratio is approximately 76%.
5. Best Practices for PDF Compression
When applying PDF compression in Java, it’s important to follow some practical guidelines to ensure the file size is reduced effectively without sacrificing usability or compatibility.
- Choose methods based on content: PDF compression depends heavily on the type of content. Text-based files may only require content and font optimization, while image-heavy documents benefit more from image compression. In many cases, combining multiple techniques yields the best results.
- Balance quality with file size: Over-compression may influence the document's readability, so it’s important to maintain a balance.
- Test across PDF readers: Ensure compatibility with Adobe Acrobat, browser viewers, and mobile apps.
6. Conclusion
Compressing PDF in Java is not just about saving disk space—it directly impacts performance, user experience, and system efficiency. Using Libraries like Spire.PDF for Java, developers can implement fine-grained compression techniques, from compressing content, optimizing images and fonts, to cleaning up unused metadata.
By applying the right strategies, you can minimize PDF size in Java significantly without sacrificing quality. This leads to faster file transfers, lower storage costs, and smoother rendering across platforms. Mastering these compression methods ensures your Java applications remain responsive and efficient, even when handling complex, resource-heavy PDFs.
7. FAQs
Q1: Can I reduce PDF file size in Java without losing quality?
A1: Yes. Spire.PDF allows selective compression of images, fonts, and other objects while maintaining readability and layout.
Q2: Will compressed PDFs remain compatible with popular PDF readers?
A2: Yes. Compressed PDFs remain compatible with Adobe Acrobat, browser viewers, mobile apps, and other standard PDF readers.
Q3: What’s the difference between image compression and font compression?
A3: Image compression reduces the size of embedded images, while font compression reduces embedded font data or removes unused fonts. Both techniques together optimize file size effectively.
Q4: How do I choose the best compression strategy?
A4: Consider the PDF content. Use image compression for image-heavy PDFs and font compression for text-heavy PDFs. Often, combining both techniques yields the best results without affecting readability.
Q5: Can I automate PDF compression for multiple files in Java?
A5: Yes. You can write Java scripts to batch compress multiple PDFs by applying the same compression settings consistently across all files.
Java: Add or Delete Pages in PDF Documents
When you edit a PDF document, it is sometimes necessary to delete redundant pages of the document or add new pages to the document. This article will show you how to add or delete pages in a PDF document using Spire.PDF for Java.
Install Spire.PDF for Java
First of all, you're required to add the Spire.Pdf.jar file as a dependency in your Java program. The JAR file can be downloaded from this link. If you use Maven, you can easily import the JAR file in your application by adding the following code to your project's pom.xml file.
<repositories>
<repository>
<id>com.e-iceblue</id>
<name>e-iceblue</name>
<url>https://repo.e-iceblue.com/nexus/content/groups/public/</url>
</repository>
</repositories>
<dependencies>
<dependency>
<groupId>e-iceblue</groupId>
<artifactId>spire.pdf</artifactId>
<version>12.7.0</version>
</dependency>
</dependencies>
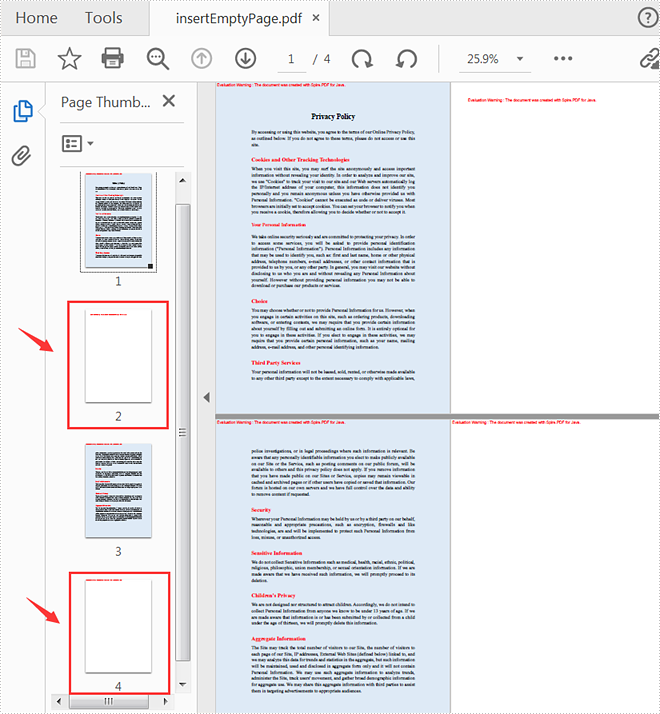
Add Empty Pages to a PDF Document
The following steps show you how to add empty pages to a specific position of a PDF document and its end.
- Create a PdfDocument instance.
- Load a sample PDF document using PdfDocument.loadFromFile() method.
- Create a new blank page and insert it into a specific position of the document using PdfDocument.getPages().insert(int index) method.
- Create another new blank page with the specified size and margins and then append it to the end of the document using PdfDocument.getPages().add(java.awt.geom.Dimension2D size, PdfMargins margins) method.
- Save the document to another file using PdfDocument.saveToFile() method.
- Java
import com.spire.pdf.*;
import com.spire.pdf.graphics.PdfMargins;
public class InsertEmptyPage {
public static void main(String[] args) {
//Create a PdfDocument instance
PdfDocument pdf = new PdfDocument();
//Load a sample PDF document
pdf.loadFromFile("C:\\Users\\Test1\\Desktop\\sample.pdf");
//Insert a blank page to the document as the second page
pdf.getPages().insert(1);
//Add an empty page to the end of the document
pdf.getPages().add(PdfPageSize.A4, new PdfMargins(0, 0));
//Save the document to another file
pdf.saveToFile("output/insertEmptyPage.pdf");
pdf.close();
}
}
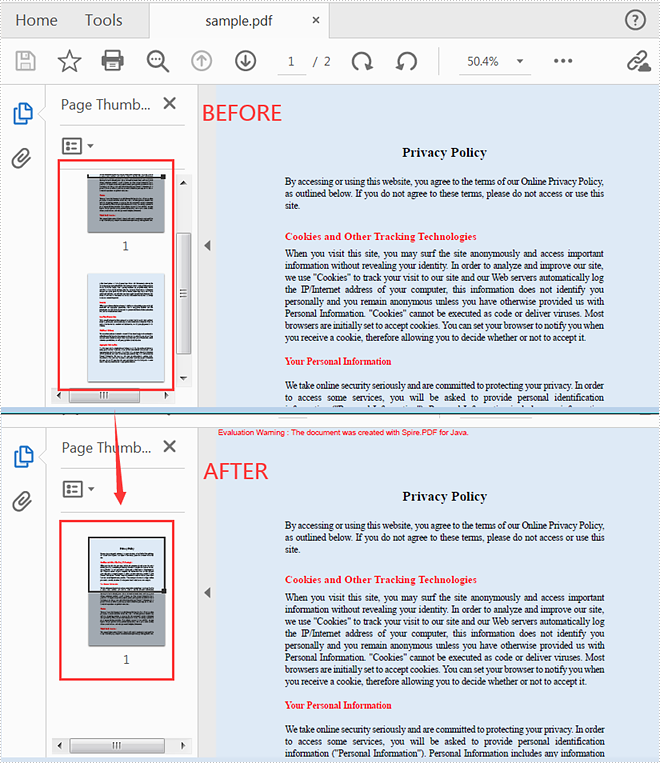
Delete an Existing Page in a PDF Document
The following steps are to delete a specific page of a PDF document.
- Create a PdfDocument instance.
- Load a sample PDF document using PdfDocument.loadFromFile() method.
- Remove a specific page of the document using PdfDocument.getPages().removeAt(int index) method.
- Save the document to another file using PdfDocument.saveToFile() method.
- Java
import com.spire.pdf.*;
public class DeletePage {
public static void main(String[] args) {
//Create a PdfDocument instance
PdfDocument pdf = new PdfDocument();
//Load a sample PDF document
pdf.loadFromFile("C:\\Users\\Test1\\Desktop\\sample.pdf");
//Delete the second page of the document
pdf.getPages().removeAt(1);
//Save the document to another file
pdf.saveToFile("output/deletePage.pdf");
pdf.close();
}
}
Apply for a Temporary License
If you'd like to remove the evaluation message from the generated documents, or to get rid of the function limitations, please request a 30-day trial license for yourself.
Java: Set PDF Viewer Preferences
Preserving and displaying documents precisely is a primary function of PDF. However, the viewing preference settings of different devices and users would still affect the display of PDF documents. To solve this problem, PDF provides the viewer preference entry in a document to control the way the PDF document presents on screen. Without it, PDF documents will display according to the current user’s preference setting. This article will show how to set PDF viewer preferences by programming using Spire.PDF for Java.
Install Spire.PDF for Java
First of all, you're required to add the Spire.Pdf.jar file as a dependency in your Java program. The JAR file can be downloaded from this link. If you use Maven, you can easily import the JAR file in your application by adding the following code to your project's pom.xml file.
<repositories>
<repository>
<id>com.e-iceblue</id>
<name>e-iceblue</name>
<url>https://repo.e-iceblue.com/nexus/content/groups/public/</url>
</repository>
</repositories>
<dependencies>
<dependency>
<groupId>e-iceblue</groupId>
<artifactId>spire.pdf</artifactId>
<version>12.7.0</version>
</dependency>
</dependencies>
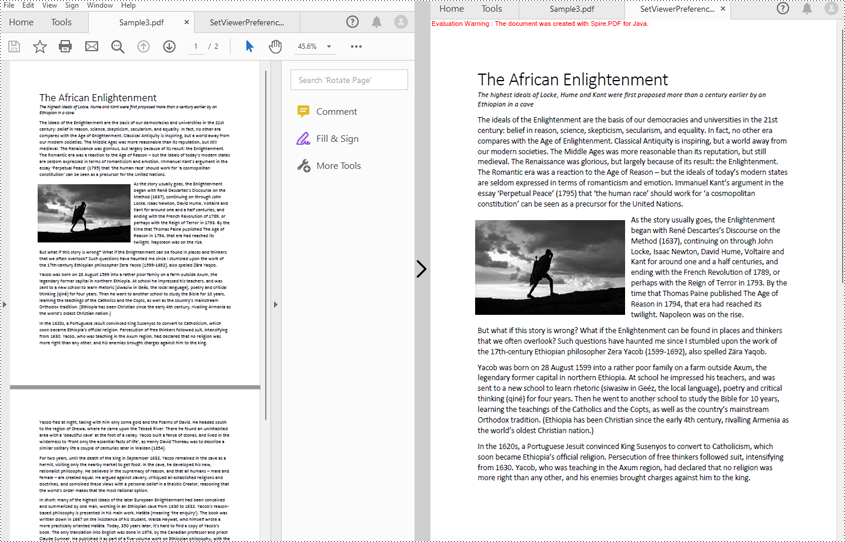
Set Viewer Preferences of a PDF Document
Spire.PDF for Java includes several methods under PdfViewerPreferences class, which can decide whether to center the window, display title, fit the window, and hide menu bar as well as tool bar and set page layout, page mode, and scaling mode. The detailed steps of setting viewer preferences are as follows.
- Create an object of PdfDocument class.
- Load a PDF file using PdfDocument.loadFromFile() method.
- Get viewer preferences of the document using PdfDocument.getViewerPreferences() method.
- Set the viewer preferences using the methods under PdfViewerPreferences object.
- Save the file using PdfDocument.saveToFile() method.
- Java
import com.spire.pdf.*;
public class setViewerPreference {
public static void main(String[] args) {
//Create an object of PdfDocument class
PdfDocument pdf = new PdfDocument();
//Load a PDF file
pdf.loadFromFile("C:/Sample3.pdf");
//Get viewer preferences of the document
PdfViewerPreferences preferences = pdf.getViewerPreferences();
//Set viewer preferences
preferences.setCenterWindow(true);
preferences.setDisplayTitle(false);
preferences.setFitWindow(true);
preferences.setHideMenubar(true);
preferences.setHideToolbar(true);
preferences.setPageLayout(PdfPageLayout.Single_Page);
//preferences.setPageMode(PdfPageMode.Full_Screen);
//preferences.setPrintScaling(PrintScalingMode.App_Default);
//Save the file
pdf.saveToFile("SetViewerPreference.pdf");
pdf.close();
}
}
Apply for a Temporary License
If you'd like to remove the evaluation message from the generated documents, or to get rid of the function limitations, please request a 30-day trial license for yourself.
Java: Set or Retrieve PDF Properties
PDF properties, as a part of a PDF document, are not shown on a page. Those properties contain information on documents, including title, author, subject, keywords, creation date, and creator. Some of the property values will not be produced automatically, and we have to set them by ourselves. This article will show you how to set or retrieve PDF properties programmatically using Spire.PDF for Java.
Install Spire.PDF for Java
First of all, you're required to add the Spire.Pdf.jar file as a dependency in your Java program. The JAR file can be downloaded from this link. If you use Maven, you can easily import the JAR file in your application by adding the following code to your project's pom.xml file.
<repositories>
<repository>
<id>com.e-iceblue</id>
<name>e-iceblue</name>
<url>https://repo.e-iceblue.com/nexus/content/groups/public/</url>
</repository>
</repositories>
<dependencies>
<dependency>
<groupId>e-iceblue</groupId>
<artifactId>spire.pdf</artifactId>
<version>12.7.0</version>
</dependency>
</dependencies>
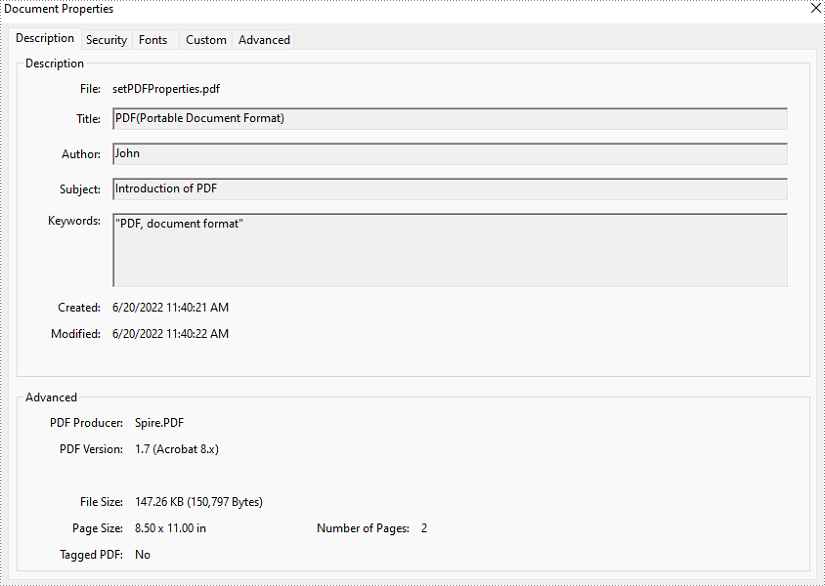
Set Properties of a PDF Document in Java
The detailed steps of setting PDF properties are as follows.
- Create an object of PdfDocument class.
- Load a PDF document from disk using PdfDocument.loadFromFile() method.
- Set document properties including title, author, subject, keywords, creation date, modification date, creator, and producer using the methods under DocumentInformation object returned by PdfDocument.getDocumentInformation() method.
- Save the document using PdfDocument.saveToFile() method.
- Java
import com.spire.pdf.*;
import java.util.Date;
public class setPDFProperties {
public static void main(String[] args) {
//Create an object of PdfDocument
PdfDocument pdfDocument = new PdfDocument();
//Load a PDF document from disk
pdfDocument.loadFromFile("D:/Samples/Sample.pdf");
//Set the title
pdfDocument.getDocumentInformation().setTitle("PDF(Portable Document Format)");
//Set the author
pdfDocument.getDocumentInformation().setAuthor("John");
//Set the subject
pdfDocument.getDocumentInformation().setSubject("Introduction of PDF");
//Set the keywords
pdfDocument.getDocumentInformation().setKeywords("PDF, document format");
//Set the creation time
pdfDocument.getDocumentInformation().setCreationDate(new Date());
//Set the creator name
pdfDocument.getDocumentInformation().setCreator("John");
//Set the modification time
pdfDocument.getDocumentInformation().setModificationDate(new Date());
//Set the producer name
pdfDocument.getDocumentInformation().setProducer("Spire.PDF for Java");
//Save the document
pdfDocument.saveToFile("output/setPDFProperties.pdf");
}
}
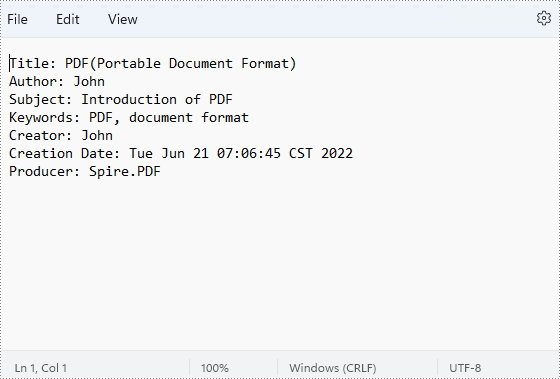
Get Properties of a PDF Document in Java
The detailed steps of retrieving PDF properties are as follows.
- Create an object of PdfDocument class.
- Load a PDF document from disk using PdfDocument.loadFromFile() method.
- Create a StringBuilder instance to store the values of document properties.
- Get properties using the methods under DocumentInformation object returned by PdfDocument.getDocumentInformation() method and put them in the StringBuilder.
- Create a new TXT file using File.createNewFile() method.
- Write the StringBuilder to the TXT file using BufferedWriter.write() method.
- Java
import com.spire.pdf.*;
import java.io.*;
public class getPDFProperties {
public static void main(String[] args) throws IOException {
//Create an object of PdfDocument class
PdfDocument pdf = new PdfDocument();
//Load a PDF document from disk
pdf.loadFromFile("D:/Samples/Sample.pdf");
//Create a StringBuilder instance to store the values of document properties
StringBuilder stringBuilder = new StringBuilder();
//Retrieve property values and put them in the StringBuilder
stringBuilder.append("Title: " + pdf.getDocumentInformation().getTitle() + "\r\n");
stringBuilder.append("Author: " + pdf.getDocumentInformation().getAuthor() + "\r\n");
stringBuilder.append("Subject: " + pdf.getDocumentInformation().getSubject() + "\r\n");
stringBuilder.append("Keywords: " + pdf.getDocumentInformation().getKeywords() + "\r\n");
stringBuilder.append("Creator: " + pdf.getDocumentInformation().getCreator() + "\r\n");
stringBuilder.append("Creation Date: " + pdf.getDocumentInformation().getCreationDate() + "\r\n");
stringBuilder.append("Producer: " + pdf.getDocumentInformation().getProducer() + "\r\n");
//Create a new TXT file
File file = new File("D:/output/getPDFProperties.txt");
file.createNewFile();
//Write the StringBuilder to the TXT file
FileWriter fileWriter = new FileWriter(file, true);
BufferedWriter bufferedWriter = new BufferedWriter(fileWriter);
bufferedWriter.write(stringBuilder.toString());
bufferedWriter.flush();
}
}
Apply for a Temporary License
If you'd like to remove the evaluation message from the generated documents, or to get rid of the function limitations, please request a 30-day trial license for yourself.