
Document Operation (33)

PDF is one of the most popular formats for distributing, archiving, and presenting digital documents. However, when PDFs include high-resolution images, scanned pages, or embedded fonts, their file sizes can grow considerably. Large PDF files can slow down upload and download speeds, take up unnecessary storage space, and even cause issues with email attachments and website performance.
This complete guide shows you how to compress PDF documents in C# using the Spire.PDF for .NET library. It covers multiple compression strategies—image compression, font optimization, and content compression—with practical, ready-to-use C# code examples to help you streamline PDF size effectively in your .NET applications.
Table of Contents
- Why Compress PDF Files
- Install the Library for PDF Compression in .NET
- How to Optimize PDF File Size in C# (Methods and Code Examples)
- Conclusion
- FAQs
Why Compress PDF Files?
Compressing PDF files can bring significant benefits, especially in professional and enterprise environments:
- Faster upload and download speeds
- Reduced storage consumption
- Easier email sharing with smaller attachments
- Improved performance in web-based PDF viewers
- Better experience on mobile and low-bandwidth environments
Whether you're working with reports, invoices, or scanned documents, PDF compression ensures efficient document handling and delivery.
Install the Library for PDF Compression in .NET
Spire.PDF for .NET is a robust and developer-friendly library that enables developers to create, edit, convert, and compress PDF documents without relying on Adobe Acrobat. It supports various compression options to minimize PDF file sizes effectively.
Installation Steps
You can easily install Spire.PDF for .NET via NuGet using one of the following methods:
Option 1: Using NuGet Package Manager
- Open your project in Visual Studio.
- Right-click on the project → Manage NuGet Packages.
- Search for Spire.PDF.
- Click Install.
Option 2: Using the Package Manager Console
Install-Package Spire.PDF
Once installed, you can start using the built-in compression APIs to optimize PDF file size.
How to Optimize PDF File Size in C# (Methods and Code Examples)
Spire.PDF provides multiple techniques to reduce PDF size. In this section, you'll learn how to implement three key methods: compressing images, optimizing fonts, and compressing overall document content.
Method 1. Compressing Images
High-resolution images embedded in PDF files often consume the most space. Spire.PDF offers flexible image compression options that allow you to reduce file size by compressing either all images or individual images in the document.
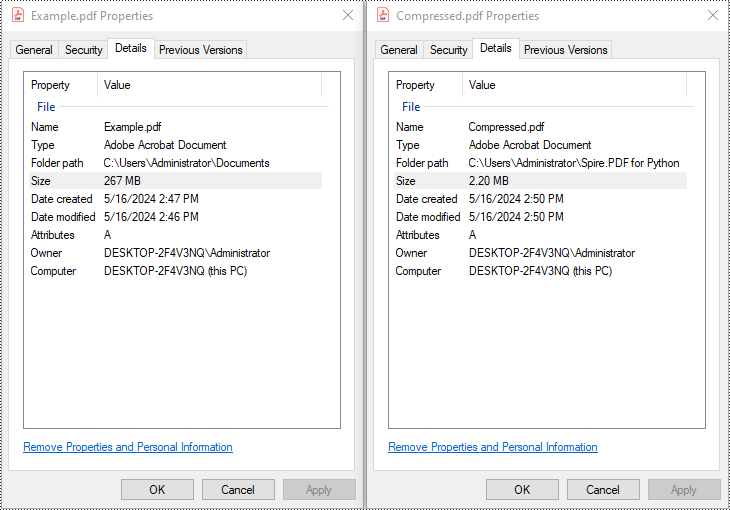
Example 1: Compress All Images with PdfCompressor
You can compress the images in a PDF document by creating a PdfCompressor object, enabling CompressImage and ResizeImages properties, and setting the ImageQuality to a predefined level such as Low, Medium, or High.
using Spire.Pdf.Conversion.Compression;
namespace CompressImages
{
class Program
{
static void Main(string[] args)
{
// Create a PdfCompressor object and load the PDF file
PdfCompressor compressor = new PdfCompressor("C:\\Users\\Administrator\\Documents\\Example.pdf");
// Get the image compression options
ImageCompressionOptions imageCompression = compressor.Options.ImageCompressionOptions;
// Enable Image resizing
imageCompression.ResizeImages = true;
// Enable image compression
imageCompression.CompressImage = true;
// Set the image quality to Medium (available options: Low, Medium, High)
imageCompression.ImageQuality = ImageQuality.Medium;
// Compress the PDF file according to the compression options and save it to a new file
compressor.CompressToFile("Compressed.pdf");
}
}
}
Example 2: Compress Images Individually Using TryCompressImage()
If you need more precise control over image compression, you can use the PdfImageHelper class to access the images on each page and compress them individually using the TryCompressImage() method.
using Spire.Pdf;
using Spire.Pdf.Utilities;
namespace CompressImagesIndividually
{
internal class Program
{
static void Main(string[] args)
{
// Create a PdfDocument object
PdfDocument pdf = new PdfDocument();
// Load the PDF file
pdf.LoadFromFile("C:\\Users\\Administrator\\Documents\\Example.pdf");
// Disable the incremental update
pdf.FileInfo.IncrementalUpdate = false;
// Create an instance of PdfImageHelper to work with images
PdfImageHelper imageHelper = new PdfImageHelper();
// Iterate through each page in the document
foreach (PdfPageBase page in pdf.Pages)
{
// Retrieve information about the images on the page
foreach (PdfImageInfo info in imageHelper.GetImagesInfo(page))
{
// Attempt to compress the image
info.TryCompressImage();
}
}
// Save the updated file
pdf.SaveToFile("Compressed.pdf");
pdf.Close();
}
}
}
Method 2. Optimize Fonts
Fonts embedded in a PDF file can contribute significantly to its size, especially when multiple fonts or large font sets are used. You can compress or unembed fonts that aren't essential for document rendering through the TextCompressionOptions property.
using Spire.Pdf.Conversion.Compression;
namespace OptimizeFonts
{
internal class Program
{
static void Main(string[] args)
{
// Create a PdfCompressor object and load the PDF file
PdfCompressor compressor = new PdfCompressor("C:\\Users\\Administrator\\Documents\\Example.pdf");
// Get the text compression options
TextCompressionOptions textCompression = compressor.Options.TextCompressionOptions;
// Compress the fonts
textCompression.CompressFonts = true;
// Unembed the fonts
// textCompression.UnembedFonts = true;
// Compress the PDF file according to the compression options and save it to a new file
compressor.CompressToFile("CompressFonts.pdf");
}
}
}
Method 3. Optimizing Document Content
Beyond images and fonts, overall document content can be optimized by setting the CompressionLevel property of the document to PdfCompressionLevel.Best.
using Spire.Pdf;
using Spire.Pdf.Conversion.Compression;
namespace OptimizeDocumentContent
{
internal class Program
{
static void Main(string[] args)
{
// Create a PdfDocument object
PdfDocument pdf = new PdfDocument();
// Load the PDF file
pdf.LoadFromFile("C:\\Users\\Administrator\\Documents\\Example.pdf");
// Disable the incremental update
pdf.FileInfo.IncrementalUpdate = false;
// Set the compression level to best
pdf.CompressionLevel = PdfCompressionLevel.Best;
// Save the updated file
pdf.SaveToFile("OptimizeDocumentContent.pdf");
pdf.Close();
}
}
}
Conclusion
Compressing PDF files in C# using Spire.PDF for .NET is straightforward, efficient, and highly customizable. Whether your goal is to reduce file size for web uploads, email attachments, or storage management, this library offers flexible solutions such as:
- Compressing images
- Optimizing fonts
- Minimizing document content
By applying one or a combination of these techniques, you can significantly reduce PDF file sizes while preserving readability and document structure—making your files easier to share, store, and distribute.
FAQs
Q1: Is it possible to compress PDF files in bulk?
A1: Yes. You can loop through multiple PDF files in a directory and apply compression using the same logic programmatically.
Q2: Can I compress a PDF and then convert it to PDF/A or other formats?
A2: Absolutely. You can compress the PDF first, then convert it to PDF/A, ensuring long-term archival with optimized size.
Q3: Can I preserve hyperlinks, bookmarks, and metadata during compression?
A3: Yes. Compression will not remove document structure like links, bookmarks, or metadata. Spire.PDF preserves document integrity.
Q4: Does Spire.PDF support other PDF operations besides compression?
A4: Yes. Besides compression, Spire.PDF offers a wide range of PDF features, such as:
- Merging/Splitting PDFs
- Extracting text, images and tables
- Adding watermarks
- Digitally signing and encrypting PDFs
For detailed tutorials and sample projects, you can visit the Spire.PDF tutorial page and explore the GitHub demo repository to see practical code examples.
Get a Free License
To fully experience the capabilities of Spire.PDF for .NET without any evaluation limitations, you can request a free 30-day trial license.
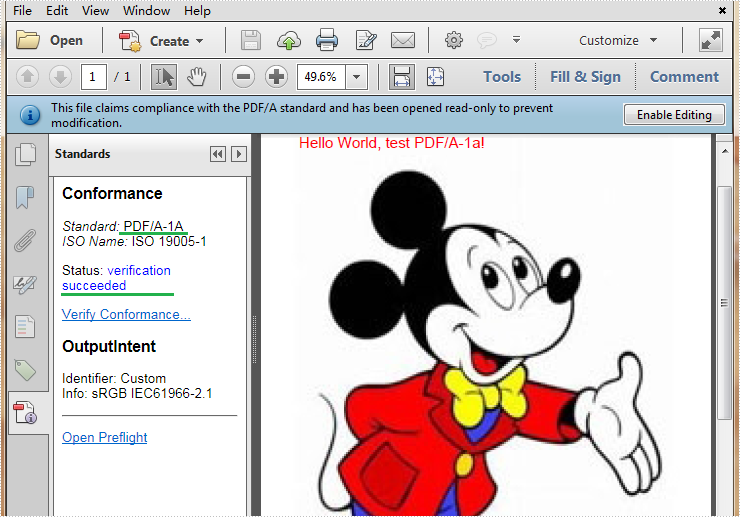
The PDF/A-1 standard specifies two levels of conformance for PDF files: PDF/A-1a (Level A conformance) and PDF/A-1b (Level B conformance). With Spire.PDF, you can create both PDF/A-1a and PDF/A-1b files easily. This article demonstrates the detail steps of how to create a PDF/A-1a file by using Spire.PDF.
Below is the PDF/A-1a file we created:
Detail steps:
Step 1: Create a new PDF file and specify its conformance level as PDF/A-1a.
PdfDocument pdf = new PdfDocument(PdfConformanceLevel.Pdf_A1A);
Step 2: Add a new page to the file, then add an image and some text to the page.
PdfPageBase page = pdf.Pages.Add(PdfPageSize.A4);
page.Canvas.DrawImage(PdfImage.FromFile("Background.jpg"), PointF.Empty, page.GetClientSize());
page.Canvas.DrawString("Hello World, test PDF/A-1a!", new PdfTrueTypeFont(new Font("Arial", 20f), true), PdfBrushes.Red, new Point(10, 15));
Step 3: Save the file.
pdf.SaveToFile("A-1a.pdf");
Full code:
using System.Drawing;
using Spire.Pdf;
using Spire.Pdf.Graphics;
namespace Create_PDF_A_1a
{
class Program
{
static void Main(string[] args)
{
PdfDocument pdf = new PdfDocument(PdfConformanceLevel.Pdf_A1A);
PdfPageBase page = pdf.Pages.Add(PdfPageSize.A4);
page.Canvas.DrawImage(PdfImage.FromFile("Background.jpg"), PointF.Empty, page.GetClientSize());
page.Canvas.DrawString("Hello World, test PDF/A-1a!", new PdfTrueTypeFont(new Font("Arial", 20f), true), PdfBrushes.Red, new Point(10, 15));
pdf.SaveToFile("A-1a.pdf");
}
}
}
Open a PDF file at a specific zoom factor/percentage in C#/VB.NET
2016-07-08 02:46:34 Written by KoohjiSometimes, we may need to change the zoom factor when displaying a PDF file to fulfil our requirements. In this article, we will demonstrate how to open a PDF file at a specific zoom factor/percentage (such as default, 100 percent or any other zoom factors as required) by using Spire.PDF for .NET.
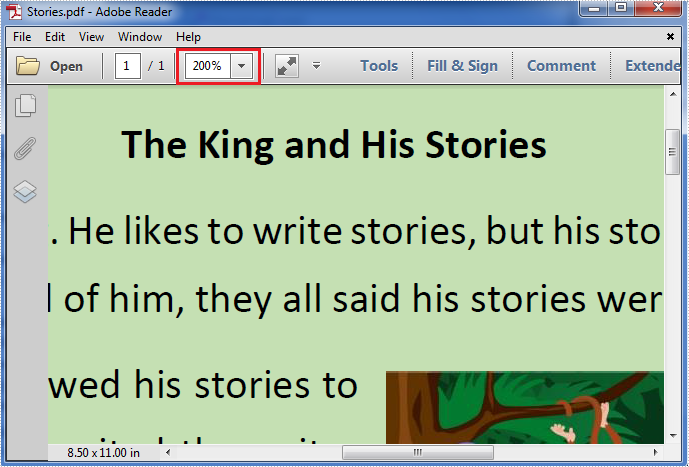
Now, please check the original zoom factor of the PDF file as below picture:
Then refer to the following detail steps:
Step 1: Create a new instance of PdfDocument class, load the original PDF file and get its first page.
PdfDocument pdf = new PdfDocument("Stories.pdf");
PdfPageBase page = pdf.Pages[0];
Step 2: Create a new PdfDestination object using the PdfDestination(PdfPageBase page, PointF location) class which has two parameters: the page and the page display location. Then set the value of its zoom property to the specific zoom factor/percentage.
PdfDestination dest = new PdfDestination(page, new PointF(-40f, -40f)); // Here we set its zoom factor to 100%. If you want to set the zoom factor to default, please set the value of zoom property to 0f. dest.Zoom = 1f;
Step 3: Create a new instance of PdfGoToAction class and enable the zoom factor resetting action to be executed when the PDF file is opened.
PdfGoToAction gotoaction = new PdfGoToAction(dest); pdf.AfterOpenAction = gotoaction;
Step 4: Save the PDF file.
pdf.SaveToFile("result.pdf");
The result zoom factor of the PDF file:
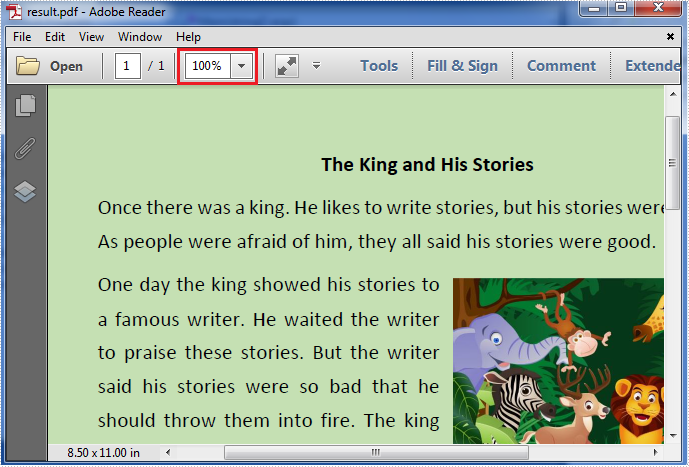
Full codes:
using Spire.Pdf;
using Spire.Pdf.Actions;
using Spire.Pdf.General;
using System.Drawing;
namespace Set_the_zoom_factor
{
class Program
{
static void Main(string[] args)
{
PdfDocument pdf = new PdfDocument("Stories.pdf");
PdfPageBase page = pdf.Pages[0];
PdfDestination dest = new PdfDestination(page, new PointF(-40f, -40f));
dest.Zoom = 1f;
PdfGoToAction gotoaction = new PdfGoToAction(dest);
pdf.AfterOpenAction = gotoaction;
pdf.SaveToFile("result.pdf");
}
}
}
Imports Spire.Pdf
Imports Spire.Pdf.Actions
Imports Spire.Pdf.General
Imports System.Drawing
Namespace Set_the_zoom_factor
Class Program
Private Shared Sub Main(args As String())
Dim pdf As New PdfDocument("Stories.pdf")
Dim page As PdfPageBase = pdf.Pages(0)
Dim dest As New PdfDestination(page, New PointF(-40F, -40F))
dest.Zoom = 1F
Dim gotoaction As New PdfGoToAction(dest)
pdf.AfterOpenAction = gotoaction
pdf.SaveToFile("result.pdf")
End Sub
End Class
End Namespace
The table of contents plays a critical role in enhancing the readability and navigability of a document. It provides readers with a clear overview of the document's structure and enables them to quickly locate and access specific sections or information they are interested in. This can be especially valuable for longer documents, such as reports, books, or academic papers, where readers may need to refer back to specific sections or chapters multiple times. In this article, we'll explore how to create a table of contents in a PDF document in C# and VB.NET using Spire.PDF for .NET.
Install Spire.PDF for .NET
To begin with, you need to add the DLL files included in the Spire.PDF for.NET package as references in your .NET project. The DLL files can be either downloaded from this link or installed via NuGet.
PM> Install-Package Spire.PDF
Create a Table of Contents in PDF in C# and VB.NET
A table of contents mainly includes the TOC title (e.g. Table of Contents), TOC content, page numbers, and actions that will take you to the target pages when clicked on. To create a table of contents in PDF using Spire.PDF for .NET, you can follow these steps:
- Initialize an instance of the PdfDocument class.
- Load a PDF document using PdfDocument.LoadFromFile() method.
- Get the page count of the document using PdfDocument.Pages.Count property.
- Insert a new page into the PDF document as the first page using PdfDocument.Pages.Insert(0) method.
- Draw the TOC title, TOC content, and page numbers on the page using PdfPageBase.Canvas.DrawString() method.
- Create actions using PdfActionAnnotation class and add the actions to the page using PdfNewPage.Annotations.Add() method.
- Save the result document using PdfDocument.SaveToFile() method.
- C#
- VB.NET
using Spire.Pdf;
using Spire.Pdf.Actions;
using Spire.Pdf.Annotations;
using Spire.Pdf.General;
using Spire.Pdf.Graphics;
using System;
using System.Drawing;
namespace TableOfContents
{
internal class Program
{
static void Main(string[] args)
{
//Initialize an instance of the PdfDocument class
PdfDocument doc = new PdfDocument();
//Load a PDF document
doc.LoadFromFile("Sample.PDF");
//Get the page count of the document
int pageCount = doc.Pages.Count;
//Insert a new page into the pdf document as the first page
PdfPageBase tocPage = doc.Pages.Insert(0);
//Draw TOC title on the new page
string title = "Table of Contents";
PdfTrueTypeFont titleFont = new PdfTrueTypeFont(new Font("Arial", 20, FontStyle.Bold));
PdfStringFormat centerAlignment = new PdfStringFormat(PdfTextAlignment.Center, PdfVerticalAlignment.Middle);
PointF location = new PointF(tocPage.Canvas.ClientSize.Width / 2, titleFont.MeasureString(title).Height + 10);
tocPage.Canvas.DrawString(title, titleFont, PdfBrushes.CornflowerBlue, location, centerAlignment);
//Draw TOC content on the new page
PdfTrueTypeFont titlesFont = new PdfTrueTypeFont(new Font("Arial", 14));
String[] titles = new String[pageCount];
for (int i = 0; i < titles.Length; i++)
{
titles[i] = string.Format("This is page {0}", i + 1);
}
float y = titleFont.MeasureString(title).Height + 10;
float x = 0;
//Draw page numbers of the target pages on the new page
for (int i = 1; i <= pageCount; i++)
{
string text = titles[i - 1];
SizeF titleSize = titlesFont.MeasureString(text);
PdfPageBase navigatedPage = doc.Pages[i];
string pageNumText = (i + 1).ToString();
SizeF pageNumTextSize = titlesFont.MeasureString(pageNumText);
tocPage.Canvas.DrawString(text, titlesFont, PdfBrushes.CadetBlue, 0, y);
float dotLocation = titleSize.Width + 2 + x;
float pageNumlocation = tocPage.Canvas.ClientSize.Width - pageNumTextSize.Width;
for (float j = dotLocation; j < pageNumlocation; j++)
{
if (dotLocation >= pageNumlocation)
{
break;
}
tocPage.Canvas.DrawString(".", titlesFont, PdfBrushes.Gray, dotLocation, y);
dotLocation += 3;
}
tocPage.Canvas.DrawString(pageNumText, titlesFont, PdfBrushes.CadetBlue, pageNumlocation, y);
//Add actions that will take you to the target pages when clicked on to the new page
location = new PointF(0, y);
RectangleF titleBounds = new RectangleF(location, new SizeF(tocPage.Canvas.ClientSize.Width, titleSize.Height));
PdfDestination Dest = new PdfDestination(navigatedPage, new PointF(-doc.PageSettings.Margins.Top, -doc.PageSettings.Margins.Left));
PdfActionAnnotation action = new PdfActionAnnotation(titleBounds, new PdfGoToAction(Dest));
action.Border = new PdfAnnotationBorder(0);
(tocPage as PdfNewPage).Annotations.Add(action);
y += titleSize.Height + 10;
}
//Save the result pdf document
doc.SaveToFile("AddTableOfContents.pdf");
doc.Close();
}
}
}
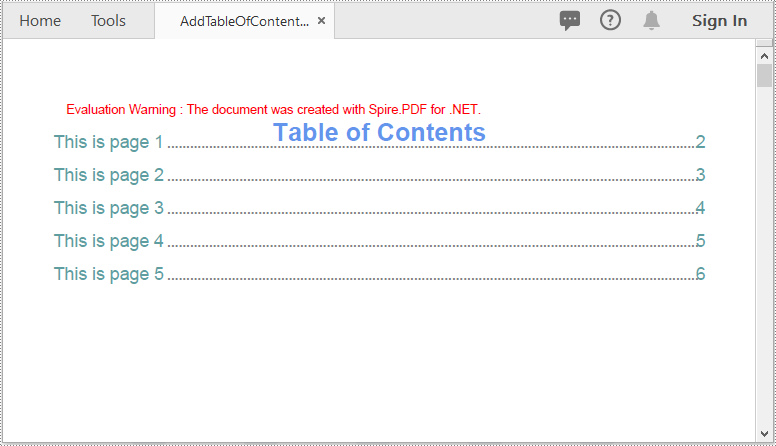
Apply for a Temporary License
If you'd like to remove the evaluation message from the generated documents, or to get rid of the function limitations, please request a 30-day trial license for yourself.
XMP is a file labeling technology that lets you embed metadata into files themselves during the content creation process. With an XMP enabled application, your workgroup can capture meaningful information about a project (such as titles and descriptions, searchable keywords, and up-to-date author and copyright information) in a format that is easily understood by your team as well as by software applications, hardware devices, and even file formats.
In the Spire.PDF Version 3.6.135 and above, we add a new feature to read, set and load an existing XMP data from XML documents. This article presents how to set XMP Metadata while creating a PDF document.
Code Snippet:
Step 1: Initialize a new instance of PdfDocument class.
PdfDocument doc = new PdfDocument();
Step 2: Get XMP metadata from PDF document.
XmpMetadata meta = doc.XmpMetaData;
Step 3: Set author, create data, creator, keywords and etc. to metadata.
meta.SetAuthor("E-iceblue");
meta.SetCreateDate(DateTime.Now);
meta.SetCreator("Spire.PDF");
meta.SetCustomProperty("Field", "NewValue");
meta.SetKeywords("XMP");
meta.SetProducer("E-icenlue Co,.Ltd");
meta.SetSubject("XMP Metadata");
meta.SetTitle("Set XMP Metadata in PDF");
Step 4: Save the file.
doc.SaveToFile("XMP.pdf", FileFormat.PDF);
Output:
To view metadata in a PDF document, open it with Acrobat or Acrobat Reader and select ‘Document Properties’ in the File menu.
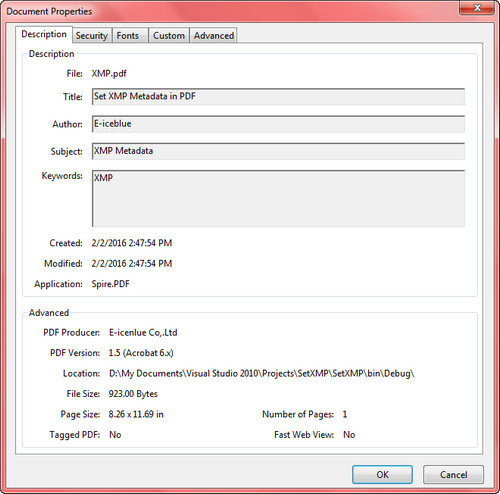
Full Code:
using Spire.Pdf;
using Spire.Pdf.Xmp;
using System;
namespace SetXMPMetadata
{
class Program
{
static void Main(string[] args)
{
PdfDocument doc = new PdfDocument();
XmpMetadata meta = doc.XmpMetaData;
meta.SetAuthor("E-iceblue");
meta.SetCreateDate(DateTime.Now);
meta.SetCreator("Spire.PDF");
meta.SetCustomProperty("Field", "NewValue");
meta.SetKeywords("XMP");
meta.SetProducer("E-icenlue Co,.Ltd");
meta.SetSubject("XMP Metadata");
meta.SetTitle("Set XMP Metadata in PDF");
doc.SaveToFile("XMP.pdf", FileFormat.PDF);
}
}
}
Imports Spire.Pdf
Imports Spire.Pdf.Xmp
Namespace SetXMPMetadata
Class Program
Private Shared Sub Main(args As String())
Dim doc As New PdfDocument()
Dim meta As XmpMetadata = doc.XmpMetaData
meta.SetAuthor("E-iceblue")
meta.SetCreateDate(DateTime.Now)
meta.SetCreator("Spire.PDF")
meta.SetCustomProperty("Field", "NewValue")
meta.SetKeywords("XMP")
meta.SetProducer("E-icenlue Co,.Ltd")
meta.SetSubject("XMP Metadata")
meta.SetTitle("Set XMP Metadata in PDF")
doc.SaveToFile("XMP.pdf", FileFormat.PDF)
End Sub
End Class
End Namespace
With the help of Spire.PDF, we can add several kinds of layers such as line, image, string, ellipse, rectangle and pie to any page of a new or an existing pdf document. At the same time, it also supports us to delete specific layer from a pdf document.
In this section, we're going to demonstrate how to delete layer in PDF using Spire.PDF for .NET. To add layer to PDF, please check this article: How to add layers to PDF file in C#.
Below is the screenshot of the original PDF document which contains three layers: a red line layer and two image layers.
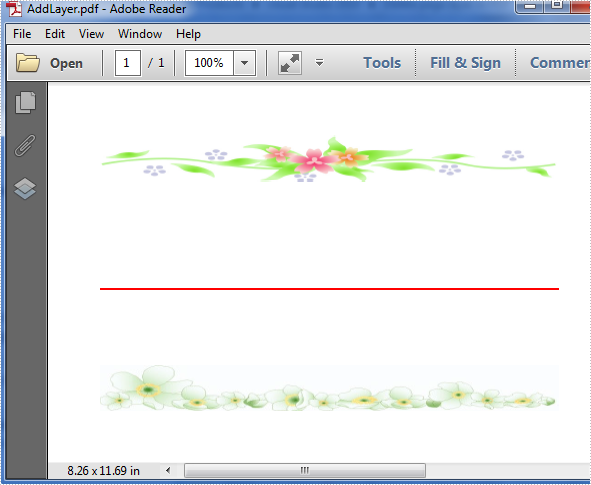
Before start, download Spire.PDF and install it correctly, next add the corresponding dll file from the installation folder as reference of your project.
Detail steps:
Step 1: Initialize a new instance of PdfDocument class and load the sample document from file.
PdfDocument doc = new PdfDocument();
doc.LoadFromFile("AddLayer.pdf");
Step 2: Get its first page and delete the specific layer by name from page one.
PdfPageBase page = doc.Pages[0];
page.PageLayers.DeleteOldLayer("red line");
Step 3: Save and launch the file.
doc.SaveToFile("delete.pdf");
System.Diagnostics.Process.Start("delete.pdf");
Effective screenshot after deleting:
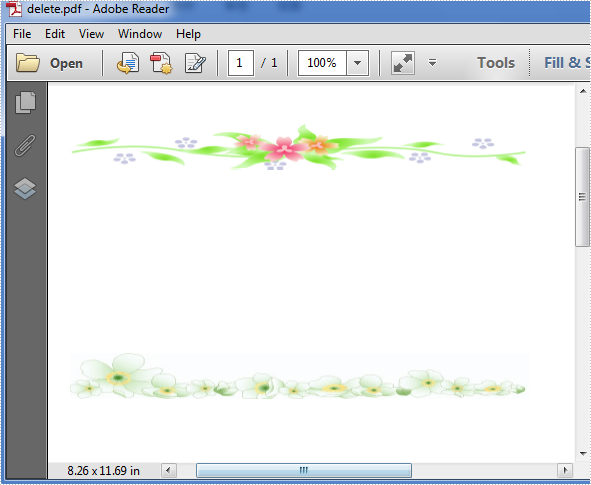
Full codes:
using Spire.Pdf;
namespace Delete_page_layer_in_PDF
{
class Program
{
static void Main(string[] args)
{
PdfDocument doc = new PdfDocument();
doc.LoadFromFile("AddLayer.pdf");
PdfPageBase page = doc.Pages[0];
page.PageLayers.DeleteOldLayer("red line");
doc.SaveToFile("delete.pdf");
System.Diagnostics.Process.Start("delete.pdf");
}
}
}
Spire.PDF offers a method of PdfDocument.MergeFiles(); to enable developers to merge PDF files easily and conveniently. This article will show you how to insert a new page from the first PDF into the second PDF file at a specified index by using the method of Pages.Insert(); offered by Spire.PDF.
Note: Before Start, please download the latest version of Spire.PDF and add Spire.PDF.dll in the bin folder as the reference of Visual Studio.
Here comes to the steps of how to insert the page from the first PDF (sample.pdf) into the second PDF (test.pdf) at a specified index:
Step 1: Create the first PDF document and load file.
PdfDocument doc1 = new PdfDocument();
doc1.LoadFromFile("sample.pdf");
Step 2: Create the second PDF document and load file.
PdfDocument doc2 = new PdfDocument();
doc2.LoadFromFile("test.pdf");
Step 3: Get the first page and its size from the first PDF document.
PdfPageBase page = doc1.Pages[0]; SizeF size = page.Size;
Step 4: Inserts a new blank page with the specified size at the specified index into the second PDF.
PdfPageBase newPage = doc2.Pages.Insert(1, size);
Step 5: Copy the contents on the page into the second PDF.
newPage.Canvas.DrawTemplate(page.CreateTemplate(), new PointF(0, 0));
Step 6: Save the document to file.
doc2.SaveToFile("result.pdf");
Effective screenshot of insert a new PDF page to an existing PDF at a specified index:
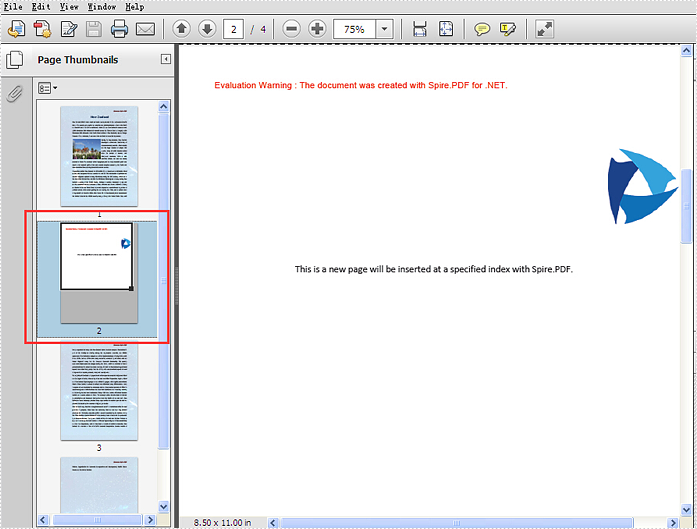
Full codes:
using Spire.Pdf;
using System.Drawing;
namespace InsertNewPage
{
class Program
{
static void Main(string[] args)
{
PdfDocument doc1 = new PdfDocument();
doc1.LoadFromFile("sample.pdf");
PdfDocument doc2 = new PdfDocument();
doc2.LoadFromFile("test.pdf");
PdfPageBase page = doc1.Pages[0];
SizeF size = page.Size;
PdfPageBase newPage = doc2.Pages.Insert(1, size);
newPage.Canvas.DrawTemplate(page.CreateTemplate(), new PointF(0, 0));
doc2.SaveToFile("result.pdf");
}
}
}
Developers can use PDF layer to set some content to be visible and others to be invisible in the same PDF file. It makes the PDF Layer widely be used to deal with related contents within the same PDF. Now developers can easily add page layers by using class PdfPageLayer offered by Spire.PDF. This article will focus on showing how to add layers to a PDF file in C# with the help of Spire.PDF.
Note: Before Start, please download the latest version of Spire.PDF and add Spire.PDF.dll in the bin folder as the reference of Visual Studio.
Here comes to the details:
Step 1: Create a new PDF document
PdfDocument pdfdoc = new PdfDocument();
Step 2: Add a new page to the PDF document.
PdfPageBase page = pdfdoc.Pages.Add();
Step 3: Add a layer named "red line" to the PDF page.
PdfPageLayer layer = page.PageLayers.Add("red line");
Step 4: Draw a red line to the added layer.
layer.Graphics.DrawLine(new PdfPen(PdfBrushes.Red, 1), new PointF(0, 100), new PointF(300, 100));
Step 5: Use the same method above to add the other two layers to the PDF page.
layer = page.PageLayers.Add("blue line");
layer.Graphics.DrawLine(new PdfPen(PdfBrushes.Blue, 1), new PointF(0, 200), new PointF(300, 200));
layer = page.PageLayers.Add("green line");
layer.Graphics.DrawLine(new PdfPen(PdfBrushes.Green, 1), new PointF(0, 300), new PointF(300, 300));
Step 6: Save the document to file.
pdfdoc.SaveToFile("AddLayers.pdf", FileFormat.PDF);
Effective screenshot:
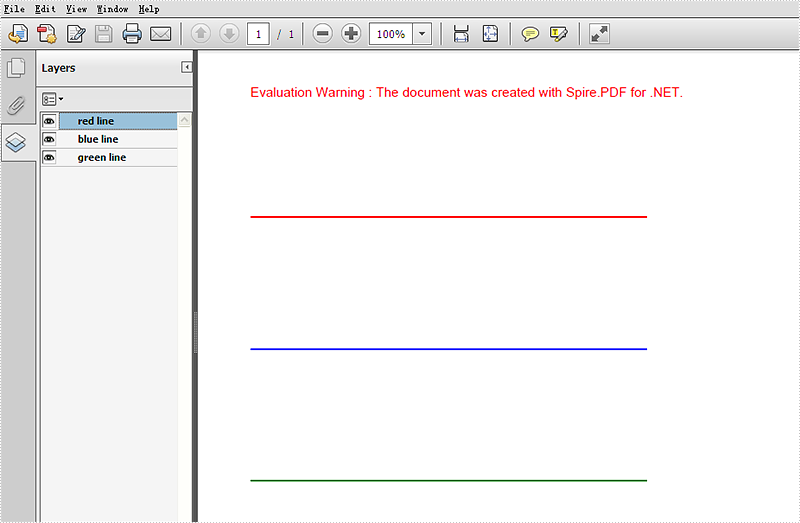
Full codes:
using Spire.Pdf;
using Spire.Pdf.Graphics;
using System.Drawing;
namespace AddLayer
{
class Program
{
static void Main(string[] args)
{
PdfDocument pdfdoc = new PdfDocument();
PdfPageBase page = pdfdoc.Pages.Add();
PdfPageLayer layer = page.PageLayers.Add("red line");
layer.Graphics.DrawLine(new PdfPen(PdfBrushes.Red, 1), new PointF(0, 100), new PointF(300, 100));
layer = page.PageLayers.Add("blue line");
layer.Graphics.DrawLine(new PdfPen(PdfBrushes.Blue, 1), new PointF(0, 200), new PointF(300, 200));
layer = page.PageLayers.Add("green line");
layer.Graphics.DrawLine(new PdfPen(PdfBrushes.Green, 1), new PointF(0, 300), new PointF(300, 300));
pdfdoc.SaveToFile("AddLayers.pdf", FileFormat.PDF);
}
}
}
Split PDF into Multiple PDFs using a Range of Pages in C#/VB.NET
2015-05-08 02:59:51 Written by KoohjiSplitting a multi-page PDF into single pages is perfectly supported by Spire.PDF. However, it's more common that you may want to extract selected range of pages and save as a new PDF document. In this post, you'll learn how to split a PDF file based on a range of pages via Spire.PDF in C#, VB.NET.
Here come the detailed steps:
Step 1: Initialize a new instance of PdfDocument class and load the test file.
PdfDocument pdf = new PdfDocument();
pdf.LoadFromFile("Sample.pdf");
Step 2: Create a new PDF document named as pdf1, initialize a new instance of PdfPageBase class.
PdfDocument pdf1 = new PdfDocument(); PdfPageBase page;
Step 3: Add new page to pdf1 based on the original page size and the specified margins, draw the original page element to the new page using Draw() method. Use for loop to select pages that you want them to be divided.
for (int i = 0; i < 5; i++)
{
page = pdf1.Pages.Add(pdf.Pages[i].Size, new Spire.Pdf.Graphics.PdfMargins(0));
pdf.Pages[i].CreateTemplate().Draw(page, new System.Drawing.PointF(0, 0));
}
Step 4: Save the file.
pdf1.SaveToFile("DOC_1.pdf");
Step 5: Repeat step 2 to step 4 to extract another range of pages to a new PDF file. Change the parameter i to choose the pages.
PdfDocument pdf2 = new PdfDocument();
for (int i = 5; i < 8; i++)
{
page = pdf2.Pages.Add(pdf.Pages[i].Size, new Spire.Pdf.Graphics.PdfMargins(0));
pdf.Pages[i].CreateTemplate().Draw(page, new System.Drawing.PointF(0, 0));
}
pdf2.SaveToFile("DOC_2.pdf");
Result:
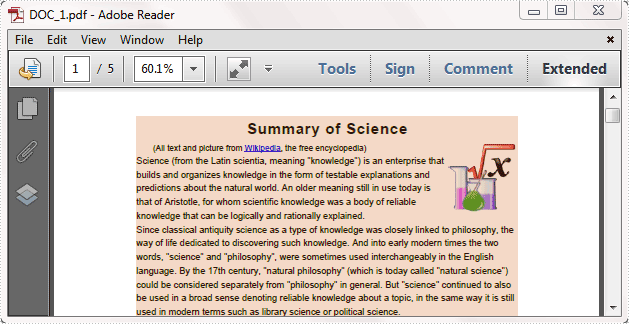

Full code:
using Spire.Pdf;
namespace SplitPDFFile
{
class Program
{
static void Main(string[] args)
{
PdfDocument pdf = new PdfDocument();
pdf.LoadFromFile("Sample.pdf");
PdfDocument pdf1 = new PdfDocument();
PdfPageBase page;
for (int i = 0; i < 5; i++)
{
page = pdf1.Pages.Add(pdf.Pages[i].Size, new Spire.Pdf.Graphics.PdfMargins(0));
pdf.Pages[i].CreateTemplate().Draw(page, new System.Drawing.PointF(0, 0));
}
pdf1.SaveToFile("DOC_1.pdf");
PdfDocument pdf2 = new PdfDocument();
for (int i = 5; i < 8; i++)
{
page = pdf2.Pages.Add(pdf.Pages[i].Size, new Spire.Pdf.Graphics.PdfMargins(0));
pdf.Pages[i].CreateTemplate().Draw(page, new System.Drawing.PointF(0, 0));
}
pdf2.SaveToFile("DOC_2.pdf");
}
}
}
Imports Spire.Pdf
Namespace SplitPDFFile
Class Program
Private Shared Sub Main(args As String())
Dim pdf As New PdfDocument()
pdf.LoadFromFile("Sample.pdf")
Dim pdf1 As New PdfDocument()
Dim page As PdfPageBase
For i As Integer = 0 To 4
page = pdf1.Pages.Add(pdf.Pages(i).Size, New Spire.Pdf.Graphics.PdfMargins(0))
pdf.Pages(i).CreateTemplate().Draw(page, New System.Drawing.PointF(0, 0))
Next
pdf1.SaveToFile("DOC_1.pdf")
Dim pdf2 As New PdfDocument()
For i As Integer = 5 To 7
page = pdf2.Pages.Add(pdf.Pages(i).Size, New Spire.Pdf.Graphics.PdfMargins(0))
pdf.Pages(i).CreateTemplate().Draw(page, New System.Drawing.PointF(0, 0))
Next
pdf2.SaveToFile("DOC_2.pdf")
End Sub
End Class
End Namespace
Maybe you have met this case in your work: You receive a lot of files that are in different file types, some are Word, some are PowerPoint slides, or some are Excel, etc, and you need to combine these files to one PDF for easy sharing. In this article, I’ll introduce you how to convert each file type into an Adobe PDF and then simultaneously merge them into a single PDF document using Spire.Office.
In this sample, I get four types of file (.doc, .docx, .xls, .pdf) prepared at first. Within the Spire.Office, it provides SaveToStream() method which allows us to save Word and Excel documents into stream, then these streams can be converted to PDF documents by calling the method of PdfDocument(Stream stream). At last, we could merge these PDF files to one file with the method PdfDocument.AppendPage(). More details would be as follows:
Code Snippet for Merge Multiple File Types to One PDF
Step 1: Create four new PDF documents.
PdfDocument[] documents = new PdfDocument[4];
Step 2: Load the .doc file, save it into stream and generate new PDF document from the stream.
using (MemoryStream ms1 = new MemoryStream())
{
Document doc = new Document("01.doc", Spire.Doc.FileFormat.Doc);
doc.SaveToStream(ms1, Spire.Doc.FileFormat.PDF);
documents[0] = new PdfDocument(ms1);
}
Step 3: Repeat Step 2 to generate two PDF documents from .docx file and .xls file.
using (MemoryStream ms2 = new MemoryStream())
{
Document docx = new Document("02.docx", Spire.Doc.FileFormat.Docx2010);
docx.SaveToStream(ms2, Spire.Doc.FileFormat.PDF);
documents[1] = new PdfDocument(ms2);
}
using (MemoryStream ms3 = new MemoryStream())
{
Workbook workbook = new Workbook();
workbook.LoadFromFile("03.xls", ExcelVersion.Version97to2003);
workbook.SaveToStream(ms3, Spire.Xls.FileFormat.PDF);
documents[2] = new PdfDocument(ms3);
}
Step 4: Load .pdf file and save it to documents[3].
documents[3] = new PdfDocument("04.pdf");
Step 5: Append the documents[0],[1],[2] to documents[3] and save as a new PDF document.
for (int i = 2; i > -1; i--)
{
documents[3].AppendPage(documents[i]);
}
documents[3].SaveToFile("Result.pdf");
Screenshot of the Effect:
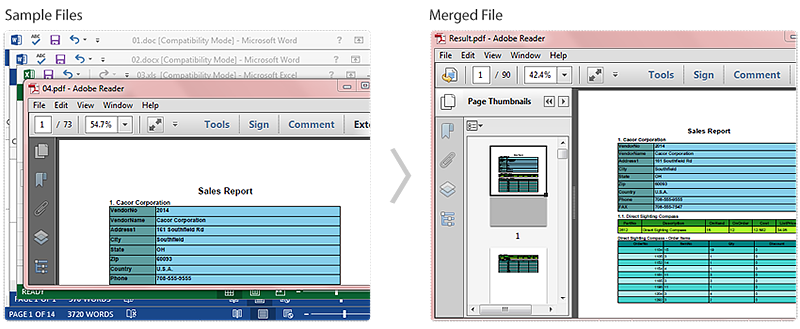
Full Code:
using Spire.Doc;
using Spire.Xls;
using Spire.Pdf;
namespace MergeMultiTypestoOnePDF
{
class Program
{
static void Main(string[] args)
{
PdfDocument[] documents = new PdfDocument[4];
using (MemoryStream ms1 = new MemoryStream())
{
Document doc = new Document("01.doc", Spire.Doc.FileFormat.Doc);
doc.SaveToStream(ms1, Spire.Doc.FileFormat.PDF);
documents[0] = new PdfDocument(ms1);
}
using (MemoryStream ms2 = new MemoryStream())
{
Document docx = new Document("02.docx", Spire.Doc.FileFormat.Docx2010);
docx.SaveToStream(ms2, Spire.Doc.FileFormat.PDF);
documents[1] = new PdfDocument(ms2);
}
using (MemoryStream ms3 = new MemoryStream())
{
Workbook workbook = new Workbook();
workbook.LoadFromFile("03.xls", ExcelVersion.Version97to2003);
workbook.SaveToStream(ms3, Spire.Xls.FileFormat.PDF);
documents[2] = new PdfDocument(ms3);
}
documents[3] = new PdfDocument("04.pdf");
for (int i = 2; i > -1; i--)
{
documents[3].AppendPage(documents[i]);
}
documents[3].SaveToFile("Result.pdf");
}
}
}
Imports Spire.Doc
Imports Spire.Xls
Imports Spire.Pdf
Namespace MergeMultiTypestoOnePDF
Class Program
Private Shared Sub Main(args As String())
Dim documents As PdfDocument() = New PdfDocument(3) {}
Using ms1 As New MemoryStream()
Dim doc As New Document("01.doc", Spire.Doc.FileFormat.Doc)
doc.SaveToStream(ms1, Spire.Doc.FileFormat.PDF)
documents(0) = New PdfDocument(ms1)
End Using
Using ms2 As New MemoryStream()
Dim docx As New Document("02.docx", Spire.Doc.FileFormat.Docx2010)
docx.SaveToStream(ms2, Spire.Doc.FileFormat.PDF)
documents(1) = New PdfDocument(ms2)
End Using
Using ms3 As New MemoryStream()
Dim workbook As New Workbook()
workbook.LoadFromFile("03.xls", ExcelVersion.Version97to2003)
workbook.SaveToStream(ms3, Spire.Xls.FileFormat.PDF)
documents(2) = New PdfDocument(ms3)
End Using
documents(3) = New PdfDocument("04.pdf")
For i As Integer = 2 To -1 + 1 Step -1
documents(3).AppendPage(documents(i))
Next
documents(3).SaveToFile("Result.pdf")
End Sub
End Class
End Namespace
