
Document Operation (33)
When uploading or submitting PDF files on certain platforms, you are sometimes faced with the dilemma that the platforms require a specific version of PDF file. If your PDF files fail to meet the requirements, it is necessary to convert them to a different version for compatibility purposes. This article will demonstrate how to programmatically convert PDF between different versions using Spire.PDF for .NET.
Install Spire.PDF for .NET
To begin with, you need to add the DLL files included in the Spire.PDF for.NET package as references in your .NET project. The DLL files can be either downloaded from this link or installed via NuGet.
PM> Install-Package Spire.PDF
Change PDF Version in C# and VB.NET
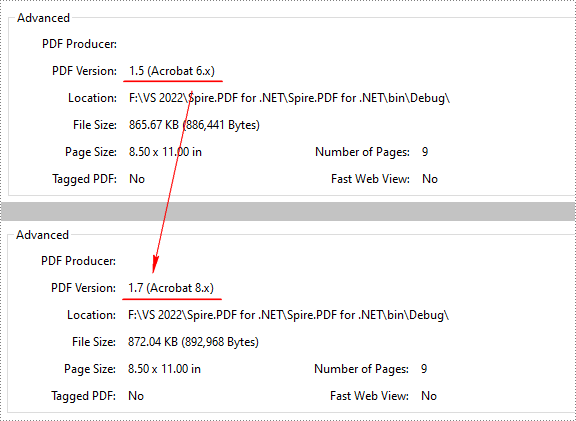
Spire.PDF for .NET supports PDF versions from 1.0 to 1.7. To convert a PDF file to a newer or older version, you can use the PdfDocument.FileInfo.Version property. The following are the detailed steps.
- Create a PdfDocument object.
- Load a sample PDF file using PdfDocument.LoadFromFile() method.
- Change the PDF version to a newer or older version using PdfDocument.FileInfo.Version property.
- Save the result document using PdfDocument.SaveToFile() method.
- C#
- VB.NET
using Spire.Pdf;
namespace ConvertPDFVersion
{
class Program
{
static void Main(string[] args)
{
//Create a PdfDocument object
PdfDocument pdf = new PdfDocument();
//Load a sample PDF file
pdf.LoadFromFile("sample.pdf");
//Change the PDF to version 1.7
pdf.FileInfo.Version = PdfVersion.Version1_7;
//Save the result file
pdf.SaveToFile("PDFVersion.pdf");
}
}
}
Apply for a Temporary License
If you'd like to remove the evaluation message from the generated documents, or to get rid of the function limitations, please request a 30-day trial license for yourself.
In document-centric workflows, combining multiple PDF files into a single document is a critical functionality in many .NET applications, ranging from enterprise document management systems to customer-facing invoicing platforms. While many tools exist for this PDF merging task, Spire.PDF for .NET stands out with its balance of simplicity, performance, and cost-effectiveness.
This guide explores how to merge PDF in C# using Spire.PDF, covering basic merging to advanced techniques with practical code examples.
- Why Programmatic PDF Merging Matters
- How to Merge PDFs in C#: Step-by-Step Guide
- Practical Example: Merge Selected Pages from Different PDFs
- Memory Efficient Solution: Merge PDF Files using Streams
- Conclusion
- FAQs
Why Programmatic PDF Merging Matters
In enterprise applications, PDF merging is crucial for:
- Consolidating financial reports
- Combining scanned document batches
- Assembling legal documentation packages
- Automated archiving systems
Spire.PDF for .NET stands out with:
- ✅ Pure .NET solution (no Acrobat dependencies)
- ✅ Cross-platform support (.NET framework, .NET Core, .NET 5+)
- ✅ Flexible page manipulation capabilities
How to Merge PDFs in C#: Step-by-Step Guide
Step 1. Install Spire.PDF
Before diving into the C# code to combine PDF files, it’s necessary to install the .NET PDF library via NuGet Package Manager.
- In Visual Studio, right-click your project in Solution Explorer
- Select Manage NuGet Packages
- Search for Spire.PDF and install
Or in Package Manager Console, run the following:
PM> Install-Package Spire.PDF
Step 2: Basic PDF Merging - C# / ASP.NET Sample
Spire.PDF provides a direct method PdfDocument.MergeFiles() method to merge multiple PDFs into a single file. The below C# code example defines three PDF file paths, merges them, and saves the result as a new PDF.
using Spire.Pdf;
namespace MergePDFs
{
class Program
{
static void Main(string[] args)
{
// Specify the PDF files to be merged
string[] files = new string[] {"sample0.pdf", "sample1.pdf", "sample2.pdf"};
// Merge PDF files
PdfDocumentBase pdf = PdfDocument.MergeFiles(files);
// Save the result file
pdf.Save("MergePDF.pdf", FileFormat.PDF);
}
}
}
Result: Combine three PDF files (total of 7 pages) into one PDF file.

Practical Example: Merge Selected Pages from Different PDFs
Merging selected pages involves combining specific pages from multiple PDFs into a new PDF document. Here’s how to achieve the task:
- Define the PDF files to be merged.
- Load PDFs into an array:
- Create an array of PdfDocument objects.
- Loops through to load each PDF into the array.
- Create a new PDF: Initializes a new PDF document to hold the merged pages.
- Insert specific pages into the new PDF:
- InsertPage(): Insert a specified page to the new PDF (Page index starts at 0).
- InsertPageRange(): Insert a range of pages to the new PDF.
- Save the merged PDF: Save the new document to a PDF file.
Code Example:
using Spire.Pdf;
namespace MergePDFs
{
class Program
{
static void Main(string[] args)
{
// Specify the PDF files to be merged
string[] files = new string[] {"sample0.pdf", "sample1.pdf", "sample2.pdf"};
// Create an array of PdfDocument
PdfDocument[] pdfs = new PdfDocument[files.Length];
// Loop through each PDF file
for (int i = 0; i < files.Length; i++)
{
pdfs[i] = new PdfDocument(files[i]);
}
// Create a new PdfDocument object
PdfDocument newPDF = new PdfDocument();
// Insert the selected pages from different PDFs to the new PDF file
newPDF.InsertPageRange(pdfs[0], 1, 2);
newPDF.InsertPage(pdfs[1], 0);
newPDF.InsertPage(pdfs[2], 1);
// Save the new PDF file
newPDF.SaveToFile("SelectivePageMerging.pdf");
}
}
}
Result: Combine selected pages from three separate PDF files into a new PDF.

Memory Efficient Solution: Merge PDF Files using Streams
For stream-based merging, refer to the C# code below:
using System.IO;
using Spire.Pdf;
namespace MergePDFsByStream
{
class Program
{
static void Main(string[] args)
{
// Specify the PDF files to be merged
string[] pdfFiles = {
"MergePdfsTemplate_1.pdf",
"MergePdfsTemplate_2.pdf",
"MergePdfsTemplate_3.pdf"
};
// Initialize a MemoryStream array
MemoryStream[] ms = new MemoryStream[pdfFiles.Length];
// Read all PDF files to the MemoryStream
for (int i = 0; i < pdfFiles.Length; i++)
{
byte[] fileBytes = File.ReadAllBytes(pdfFiles[i]);
ms[i] = new MemoryStream(fileBytes);
}
// Merge PDF files using streams
PdfDocumentBase pdf = PdfDocument.MergeFiles(ms);
// Save the merged PDF file
pdf.Save("MergePDFByStream.pdf", FileFormat.PDF);
}
}
}
Pro Tip: Learn more stream-based PDF handling techniques via the article: Load and Save PDF Files in Streams Using C#
Conclusion
Spire.PDF simplifies PDF merging in C# with its intuitive API and robust feature set. Whether you need to combine entire documents or specific pages, this library provides a reliable solution. By following the steps outlined in this guide, you can efficiently merge PDFs in your .NET applications while maintaining high quality and performance.
FAQs
Q1: Is Spire.PDF free to use?
A: Spire.PDF offers a free Community Edition with limitations (max 10 pages per document). To evaluate the commercial version without any limitations, request a free trial license here.
Q2: Can I merge PDFs from different sources?
A: Yes. Spire.PDF supports merging PDFs from various sources:
- Local Files: Use LoadFromFile() method.
- Streams: Use LoadFromStream() method.
- Base64: Convert Base64 to a byte array first, then use LoadFromBytes() method.
- URLs: Download the PDF to a stream or file first, then load it.
Q3: Can I add page numbers during merging?
A: After merging, you can add page numbers by following this guide: Add Page Numbers to a PDF in C#.
Q4. Where can I get support for Spire.PDF?
A: Check below resources:
PDF properties are metadata that provide additional information about a PDF file. Typically, these properties include, but are not limited to, the title of the document, the author, keywords, subject and the application that created the document. When there are a large number of PDF files, adding properties is essential as it can make the files easily retrievable. In this article, you will learn how to programmatically set or get PDF properties using Spire.PDF for .NET.
Install Spire.PDF for .NET
To begin with, you need to add the DLL files included in the Spire.PDF for.NET package as references in your .NET project. The DLL files can be either downloaded from this link or installed via NuGet.
PM> Install-Package Spire.PDF
Set the Properties of a PDF File in C# and VB.NET
Basic PDF document properties such as title, author, subject and keywords make it easier for users to search or retrieve specific documents later on. The following are the detailed steps on how to set these properties using Spire.PDF for .NET.
- Create a PdfDocument instance.
- Load a PDF file using PdfDocument.LoadFromFile() method.
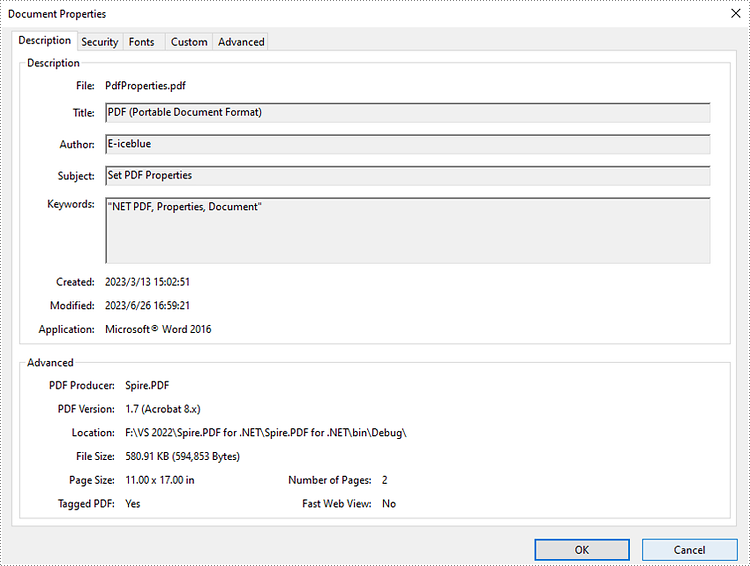
- Get PDF properties using PdfDocument.DocumentInformation property, and then set values for specific document properties such as title, subject and author through Title, Subject and Author properties of PdfDocumentInformation class.
- Save the result PDF file using PdfDocument.SaveToFile () method.
- C#
- VB.NET
using Spire.Pdf;
namespace PDFProperties
{
class Properties
{
static void Main(string[] args)
{
//Create a PdfDocument instance
PdfDocument pdf = new PdfDocument();
//Load a sample PDF document
pdf.LoadFromFile("input.pdf");
//Set the title
pdf.DocumentInformation.Title = "PDF (Portable Document Format)";
//Set the author
pdf.DocumentInformation.Author = "E-iceblue";
//Set the subject
pdf.DocumentInformation.Subject = "Set PDF Properties";
//Set the keywords
pdf.DocumentInformation.Keywords = "NET PDF, Properties, Document";
//Set the producer name
pdf.DocumentInformation.Producer = "Spire.PDF";
//Save the result document
pdf.SaveToFile("PdfProperties.pdf");
}
}
}
Get the Properties of a PDF File in C# and VB.NET
To get specific PDF properties, you can use the corresponding properties under the PdfDocumentInformation class. The following are the detailed steps.
- Create a PdfDocument instance.
- Load a PDF file using PdfDocument.LoadFromFile() method.
- Create a StringBuilder instance.
- Get PDF properties using PdfDocument.DocumentInformation property, and then get specific document properties such as title, author, keyword using properties under PdfDocumentInformation class.
- Append the extracted properties to the StringBuilder instance using StringBuilder.Append() method.
- Write the StringBuilder to a TXT file using File.WriteAllText() method.
- C#
- VB.NET
using Spire.Pdf;
using System.IO;
using System.Text;
namespace GetPdfProperties
{
class Program
{
static void Main(string[] args)
{
//Create a PdfDocument instance
PdfDocument pdf = new PdfDocument();
//Load a sample PDF document
pdf.LoadFromFile("PdfProperties.pdf");
//Create a StringBuilder instance
StringBuilder content = new StringBuilder();
//Get the PDF document properties and append them in the StringBuilder
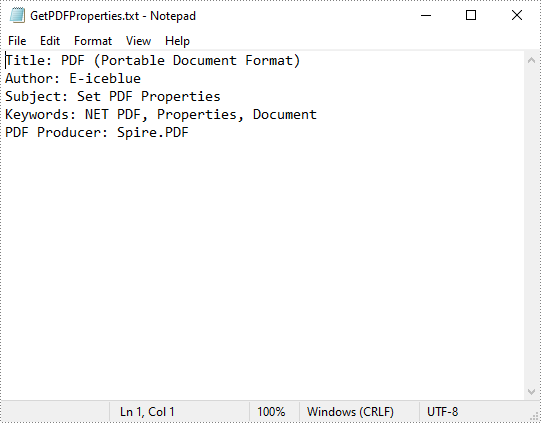
content.Append("Title: " + pdf.DocumentInformation.Title + "\r\n");
content.Append("Author: " + pdf.DocumentInformation.Author + "\r\n");
content.Append("Subject: " + pdf.DocumentInformation.Subject + "\r\n");
content.Append("Keywords: " + pdf.DocumentInformation.Keywords + "\r\n");
content.Append("PDF Producer: " + pdf.DocumentInformation.Producer + "\r\n");
//Write the StringBuilder to a TXT file
File.WriteAllText("GetPDFProperties.txt", content.ToString());
}
}
}
Apply for a Temporary License
If you'd like to remove the evaluation message from the generated documents, or to get rid of the function limitations, please request a 30-day trial license for yourself.
After searching so much information about PDF merge, it is easy to find that whether you merge PDF files online or use C#/VB.NET to realize this task, you never escape worrying some important points such as the safety of your PDF file, so much time it costs or whether the merged file supports to print page number and so on. However, as long as you come here, these troubles will not appear. This section will specifically introduce you a secure solution to merge PDF files into one with C#, VB.NET via a .NET PDF component Spire.PDF for .NET.
Spire.PDF for .NET, built from scratch in C#, enables programmers and developers to create, read, write and manipulate PDF documents in .NET applications without using Adobe Acrobat or any external libraries. Using Spire.PDF for .NET, you not only can quickly merge PDF files but also enables you to print PDF page with page number. Now please preview the effective screenshot below:
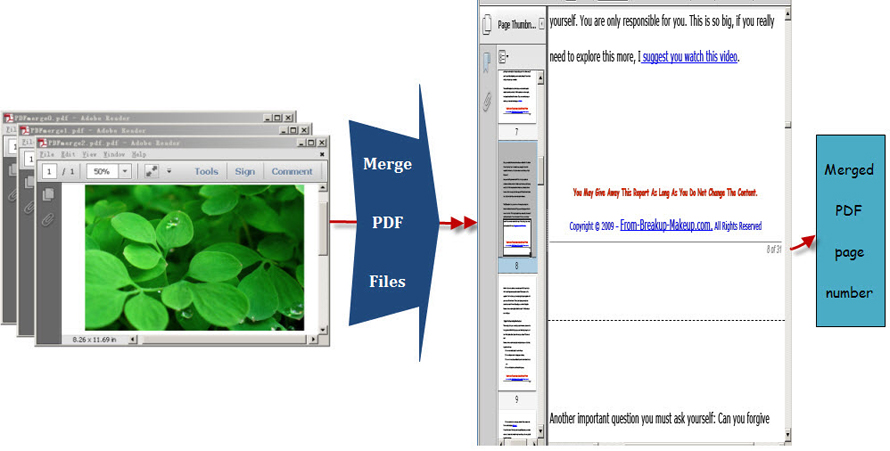
Before following below procedure, please download Spire.PDF for .NET and install it on system.
Step1: You can use the String array to save the names of the three PDF files which will be merged into one PDF and demonstrate Spire.Pdf.PdfDocument array. Then, load three PDF files and select the first PdfDocument for the purpose of merging the second and third PDF file to it. In order to import all pages from the second PDF file to the first PDF file, you need to call the method public void AppendPage(PdfDocument doc). Also by calling another method public PdfPageBase InsertPage(PdfDocument doc, int pageIndex),every page of the third PDF file can be imported to the first PDF file.
private void button1_Click(object sender, EventArgs e)
{
//pdf document list
String[] files = new String[]
{
@"..\PDFmerge0.pdf",
@"..\ PDFmerge1.pdf",
@"..\ PDFmerge2.pdf"
};
//open pdf documents
PdfDocument[] docs = new PdfDocument[files.Length];
for (int i = 0; i < files.Length; i++)
{
docs[i] = new PdfDocument(files[i]);
}
//append document
docs[0].AppendPage(docs[1]);
//import PDF pages
for (int i = 0; i < docs[2].Pages.Count; i = i + 2)
{
docs[0].InsertPage(docs[2], i);
}
Private Sub button1_Click(sender As Object, e As EventArgs)
'pdf document list
Dim files As [String]() = New [String]() {"..\PDFmerge0.pdf", "..\ PDFmerge1.pdf", "..\ PDFmerge2.pdf"}
'open pdf documents
Dim docs As PdfDocument() = New PdfDocument(files.Length - 1) {}
For i As Integer = 0 To files.Length - 1
docs(i) = New PdfDocument(files(i))
Next
'append document
docs(0).AppendPage(docs(1))
'import PDF pages
Dim i As Integer = 0
While i < docs(2).Pages.Count
docs(0).InsertPage(docs(2), i)
i = i + 2
End While
Step2: Draw page number in the first PDF file. In this step, you can set PDF page number margin by invoking the class Spire.Pdf.Graphics. PdfMargins. Then, Call the custom method DrawPageNumber(PdfPageCollection pages, PdfMargins margin, int startNumber, int pageCount) to add page number in the bottom of every page in the first PDF. Please see the detail code below:
//set PDF margin
PdfUnitConvertor unitCvtr = new PdfUnitConvertor();
PdfMargins margin = new PdfMargins();
margin.Top = unitCvtr.ConvertUnits(2.54f, PdfGraphicsUnit.Centimeter, PdfGraphicsUnit.Point);
margin.Bottom = margin.Top;
margin.Left = unitCvtr.ConvertUnits(3.17f, PdfGraphicsUnit.Centimeter, PdfGraphicsUnit.Point);
margin.Right = margin.Left;
this.DrawPageNumber(docs[0].Pages, margin, 1, docs[0].Pages.Count);
private void DrawPageNumber(PdfPageCollection pages, PdfMargins margin, int startNumber, int pageCount)
{
foreach (PdfPageBase page in pages)
{
page.Canvas.SetTransparency(0.5f);
PdfBrush brush = PdfBrushes.Black;
PdfPen pen = new PdfPen(brush, 0.75f);
PdfTrueTypeFont font = new PdfTrueTypeFont(new Font("Arial", 9f, System.Drawing.FontStyle.Italic), true);
PdfStringFormat format = new PdfStringFormat(PdfTextAlignment.Right);
format.MeasureTrailingSpaces = true;
float space = font.Height * 0.75f;
float x = margin.Left;
float width = page.Canvas.ClientSize.Width - margin.Left - margin.Right;
float y = page.Canvas.ClientSize.Height - margin.Bottom + space;
page.Canvas.DrawLine(pen, x, y, x + width, y);
y = y + 1;
String numberLabel
= String.Format("{0} of {1}", startNumber++, pageCount);
page.Canvas.DrawString(numberLabel, font, brush, x + width, y, format);
page.Canvas.SetTransparency(1);
}
}
'set PDF margin
Dim unitCvtr As New PdfUnitConvertor()
Dim margin As New PdfMargins()
margin.Top = unitCvtr.ConvertUnits(2.54F, PdfGraphicsUnit.Centimeter, PdfGraphicsUnit.Point)
margin.Bottom = margin.Top
margin.Left = unitCvtr.ConvertUnits(3.17F, PdfGraphicsUnit.Centimeter, PdfGraphicsUnit.Point)
margin.Right = margin.Left
Me.DrawPageNumber(docs(0).Pages, margin, 1, docs(0).Pages.Count)
Private Sub DrawPageNumber(pages As PdfPageCollection, margin As PdfMargins, startNumber As Integer, pageCount As Integer)
For Each page As PdfPageBase In pages
page.Canvas.SetTransparency(0.5F)
Dim brush As PdfBrush = PdfBrushes.Black
Dim pen As New PdfPen(brush, 0.75F)
Dim font As New PdfTrueTypeFont(New Font("Arial", 9F, System.Drawing.FontStyle.Italic), True)
Dim format As New PdfStringFormat(PdfTextAlignment.Right)
format.MeasureTrailingSpaces = True
Dim space As Single = font.Height * 0.75F
Dim x As Single = margin.Left
Dim width As Single = page.Canvas.ClientSize.Width - margin.Left - margin.Right
Dim y As Single = page.Canvas.ClientSize.Height - margin.Bottom + space
page.Canvas.DrawLine(pen, x, y, x + width, y)
y = y + 1
Dim numberLabel As [String] = [String].Format("{0} of {1}", System.Math.Max(System.Threading.Interlocked.Increment(startNumber),startNumber - 1), pageCount)
page.Canvas.DrawString(numberLabel, font, brush, x + width, y, format)
page.Canvas.SetTransparency(1)
Next
End Sub
The PDF merge code can be very long when you view it at first sight, actually, if you do not need to add page number in your merged PDF, steps two should be avoided. However, in many cases, page number brings great convenience for users to read PDF as well as print it. Spire.PDF for .NET can satisfy both your requirements of merging PDF files and adding page numbers in the merged PDF file.
How to Split PDF Files in C# .NET (Complete Guide with Code Examples)
2022-06-28 07:52:00 Written by Koohji
Splitting PDF files programmatically is a crucial step for automating document management in many C# and .NET applications. Whether you need to extract specific pages, divide PDFs by defined ranges, or organize large reports, using code to segment PDFs saves time and improves accuracy.
This comprehensive guide shows how to programmatically split or divide PDF files in C# using the Spire.PDF for .NET library, with practical methods and clear code examples to help developers easily integrate PDF splitting into their applications.
Table of Contents
- Why Split a PDF Programmatically in C#?
- What You Need to Get Started
- Installing Spire.PDF for .NET Library
- How to Split PDF Files in C# (Methods and Code Examples)
- Split PDF in VB.NET
- Conclusion
- Frequently Asked Questions (FAQs)
Why Split a PDF Programmatically in C#?
Splitting PDFs through code offers significant advantages over manual processing. It enables:
- Automated report generation
- Faster document preparation in enterprise workflows
- Easy content extraction for archiving or redistribution
- Dynamic document handling based on user or system input
It also reduces the risk of human error and ensures consistency across repetitive tasks.
What You Need to Get Started
Before diving into the code, make sure you have:
- .NET Framework or .NET Core installed
- Visual Studio or another C# IDE
- Spire.PDF for .NET library installed
- Basic familiarity with C# programming
Installing Spire.PDF for .NET Library
Spire.PDF for .NET is a professional .NET library that enables developers to create, read, edit, and manipulate PDF files without Adobe Acrobat. It supports advanced PDF operations like splitting, merging, extracting text, adding annotations, and more.
You can install Spire.PDF for .NET NuGet Package via NuGet Package Manager:
Install-Package Spire.PDF
Or through the NuGet UI in Visual Studio:
- Right-click your project > Manage NuGet Packages
- Search for Spire.PDF
- Click Install
How to Split PDF Files in C# (Methods and Code Examples)
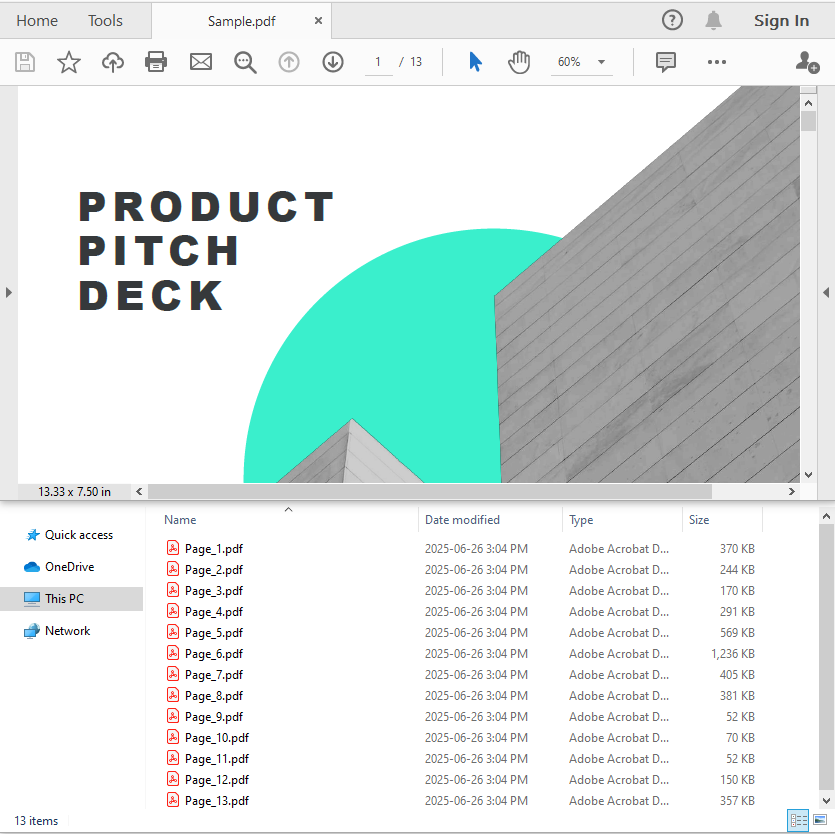
Breaking PDF by Every Page
When you want to break a PDF into multiple single-page files, the Split method is the easiest way. By specifying the output file name pattern, you can automatically save each page of the PDF as a separate file. This method simplifies batch processing or distributing pages individually.
using Spire.Pdf;
namespace SplitPDF
{
internal class Program
{
static void Main(string[] args)
{
PdfDocument pdf = new PdfDocument();
pdf.LoadFromFile("Sample.pdf");
// Split each page into separate PDF files.
// The first parameter is the output file pattern.
// {0} will be replaced by the page number starting from 1.
pdf.Split("Output/Page_{0}.pdf", 1);
pdf.Close();
}
}
}
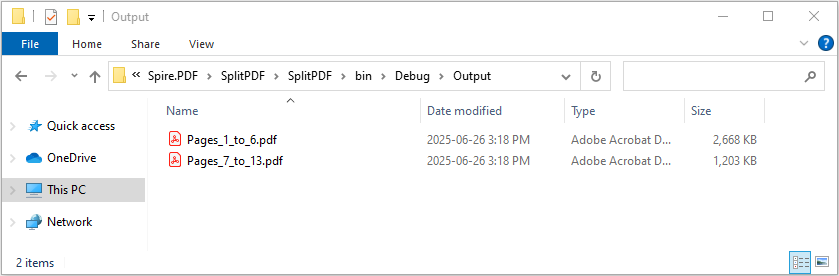
Dividing PDF by Page Ranges
To divide a PDF into multiple sections based on specific page ranges, the InsertPageRange method is ideal. This example shows how to define page ranges using zero-based start and end page indices, and then extract those ranges into separate PDF files efficiently.
using Spire.Pdf;
namespace SplitPDF
{
internal class Program
{
static void Main(string[] args)
{
// Load the PDF
PdfDocument document = new PdfDocument();
document.LoadFromFile("Sample.pdf");
// Define two ranges — pages 1–6 and 7–13 (0-based index)
int[][] ranges = new int[][]
{
new int[] { 0, 5 },
new int[] { 6, 12 }
};
// Split the PDF into smaller files by the predefined page ranges
for (int i = 0; i < ranges.Length; i++)
{
int startPage = ranges[i][0];
int endPage = ranges[i][1];
PdfDocument rangePdf = new PdfDocument();
rangePdf.InsertPageRange(document, startPage, endPage);
rangePdf.SaveToFile($"Output/Pages_{startPage + 1}_to_{endPage + 1}.pdf");
rangePdf.Close();
}
document.Close();
}
}
}
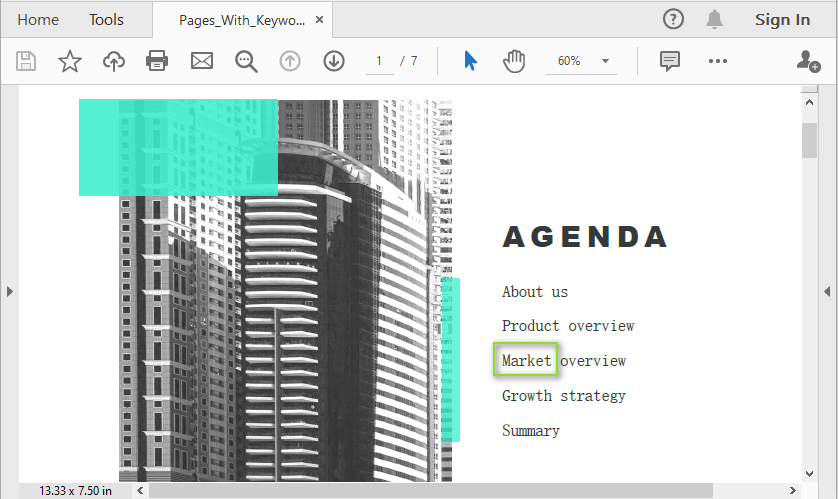
Splitting PDF by Text or Keywords
To perform content-based PDF splitting, use the Find method of the PdfTextFinder class to locate pages containing specific keywords. Once identified, you can extract these pages and insert them into new PDF files using the InsertPage method. This approach enables precise page extraction based on document content instead of fixed page numbers.
using Spire.Pdf;
using Spire.Pdf.Texts;
using System.Collections.Generic;
namespace SplitPDF
{
internal class Program
{
static void Main(string[] args)
{
// Load the PDF document
PdfDocument document = new PdfDocument();
document.LoadFromFile("Sample.pdf");
// Create a new PDF to hold extracted pages
PdfDocument resultDoc = new PdfDocument();
string keyword = "Market";
// Loop through all pages to find the keyword
for (int i = 0; i < document.Pages.Count; i++)
{
PdfPageBase page = document.Pages[i];
PdfTextFinder finder = new PdfTextFinder(page);
// Set search options
finder.Options.Parameter = TextFindParameter.WholeWord;
finder.Options.Parameter = TextFindParameter.IgnoreCase;
// Find keyword on the page
List<PdfTextFragment> fragments = finder.Find(keyword);
// If keyword found, append the page to result PDF
if (fragments.Count > 0)
{
resultDoc.InsertPage(document, page);
}
}
// Save the result PDF
resultDoc.SaveToFile("Pages_With_Keyword.pdf");
// Dispose resources
document.Dispose();
resultDoc.Dispose();
}
}
}
Extracting Specific Pages from PDF
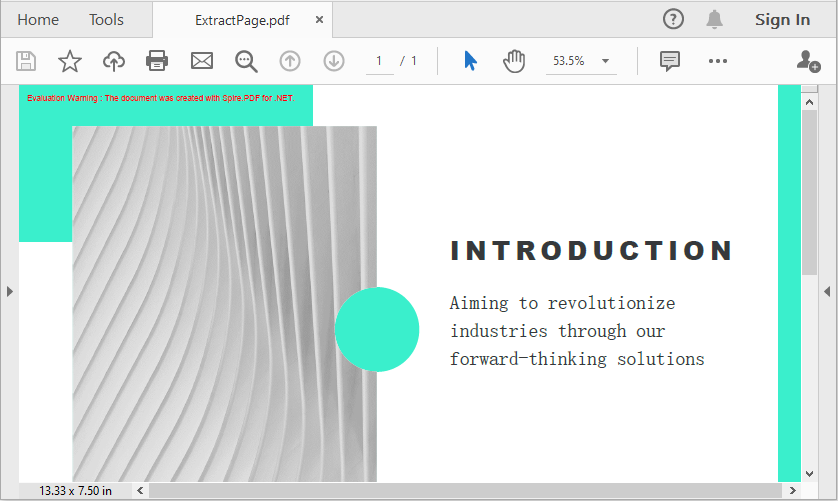
Sometimes you only need to extract one or a few individual pages from a PDF instead of splitting the whole document. This example demonstrates how to use the InsertPage method of the PdfDocument class to extract a specific page and save it as a new PDF. This method is useful for quickly pulling out important pages for review or distribution.
using Spire.Pdf;
namespace SplitPDF
{
internal class Program
{
static void Main(string[] args)
{
// Load the PDF file
PdfDocument pdf = new PdfDocument();
pdf.LoadFromFile("Sample.pdf");
// Create a new PDF to hold the extracted page
PdfDocument newPdf = new PdfDocument();
// Insert the third page (index 2, zero-based) from the PDF into the new PDF
newPdf.InsertPage(pdf, pdf.Pages[2]);
// Save the new PDF
newPdf.SaveToFile("ExtractPage.pdf");
newPdf.Close();
pdf.Close();
}
}
}
Split PDF in VB.NET
If you're working with VB.NET instead of C#, you don't need to worry about translating the code manually. You can easily convert the C# code examples in this article to VB.NET using our C# to VB.NET code converter. This tool ensures accurate syntax conversion, saving time and helping you stay focused on development.
Conclusion
Splitting PDF files programmatically in C# using Spire.PDF offers a reliable and flexible solution for automating document processing. Whether you're working with invoices, reports, or dynamic content, Spire.PDF supports various splitting methods—by page, page range, or keyword—allowing you to tailor the logic to fit any business or technical requirement.
Frequently Asked Questions (FAQs)
Q1: Is Spire.PDF free to use?
A1: Spire.PDF offers a free version suitable for small-scale or non-commercial use. For full functionality and advanced features, the commercial version is recommended.
Q2: Can I split encrypted PDFs?
A2: Yes, as long as you provide the correct password when loading the PDF files.
Q3: Does Spire.PDF support .NET Core?
A3: Yes, Spire.PDF is compatible with both .NET Framework and .NET Core.
Q4: Can I split and merge PDFs in the same project?
A4: Absolutely. Spire.PDF provides comprehensive support for both splitting and merging operations.
Get a Free License
To fully experience the capabilities of Spire.PDF for .NET without any evaluation limitations, you can request a free 30-day trial license.
