
Extract/Read (4)

Optical Character Recognition (OCR) technology has become essential for developers working with scanned documents and image-based PDFs. In this tutorial, you learn how to perform OCR on PDFs in C# to extract text from scanned documents or images within a PDF using the Spire.PDF for .NET and Spire.OCR for .NET libraries. By transferring scanned PDFs into editable and searchable formats, you can significantly improve your document management processes.
Table of Contents :
- Why OCR is Needed for Scanned PDFs?
- Setting Up: Installing Required Libraries
- Performing OCR on Scanned PDFs
- Extracting Text from Images within PDFs
- Wrapping Up
- FAQs
Why OCR is Needed for Scanned PDFs?
Scanned PDFs are essentially image files —they contain pictures of text rather than actual selectable and searchable text content. When you scan a paper document or receive an image-based PDF, the text exists only as pixels , making it impossible to edit, search, or extract. This creates significant limitations for businesses and individuals who need to work with these documents digitally.
OCR technology solves this problem by analyzing the shapes of letters and numbers in scanned images and converting them into machine-readable text. This process transforms static PDFs into usable, searchable, and editable documents—enabling text extraction, keyword searches, and seamless integration with databases and workflow automation tools.
In fields such as legal, healthcare, and education, where large volumes of scanned documents are common, OCR plays a crucial role in document digitization, making important data easily accessible and actionable.
Setting Up: Installing Required Libraries
Before we dive into the code, let's first set up our development environment with the necessary components: Spire.PDF and Spire.OCR . Spire.PDF handles PDF operations, while Spire.OCR performs the actual text recognition.
Step 1. Install Spire.PDF and Spire.OCR via NuGet
To begin, open the NuGet Package Manager in Visual Studio, and search for "Spire.PDF" and "Spire.OCR" to install them in your project. Alternatively, you can use the Package Manager Console :
Install-Package Spire.PDF
Install-Package Spire.OCR
Step 2. Download OCR Models:
Spire.OCR requires pre-trained language models for text recognition. Download the appropriate model files for your operating system (Windows, Linux, or MacOS) and extract them to a directory (e.g., D:\win-x64).
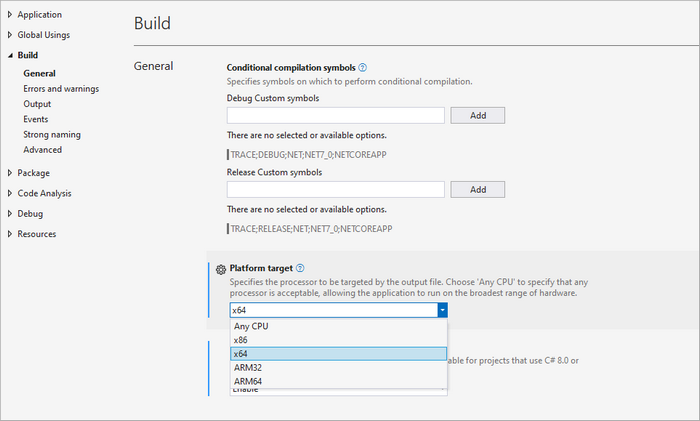
Important Note : Ensure your project targets x64 platform (Project Properties > Build > Platform target) as Spire.OCR only supports 64-bit systems.
Performing OCR on Scanned PDFs in C#
With the necessary libraries installed, we can now perform OCR on scanned PDFs. Below is a sample code snippet demonstrating this process.
using Spire.OCR;
using Spire.Pdf;
using Spire.Pdf.Graphics;
using System.Drawing;
namespace OCRPDF
{
class Program
{
static void Main(string[] args)
{
// Create an instance of the OcrScanner class
OcrScanner scanner = new OcrScanner();
// Configure the scanner
ConfigureOptions configureOptions = new ConfigureOptions
{
ModelPath = @"D:\win-x64", // Set model path
Language = "English" // Set language
};
// Apply the configuration options
scanner.ConfigureDependencies(configureOptions);
// Load a PDF document
PdfDocument doc = new PdfDocument();
doc.LoadFromFile(@"C:\Users\Administrator\Desktop\Input5.pdf");
// Iterate through all pages
for (int i = 0; i < doc.Pages.Count; i++)
{
// Convert page to image
Image image = doc.SaveAsImage(i, PdfImageType.Bitmap);
// Convert the image to a MemoryStream
using (MemoryStream stream = new MemoryStream())
{
image.Save(stream, System.Drawing.Imaging.ImageFormat.Png);
stream.Position = 0; // Reset the stream position
// Perform OCR on the image stream
scanner.Scan(stream, OCRImageFormat.Png);
string pageText = scanner.Text.ToString();
// Save extracted text to a separate file
string outputTxtPath = Path.Combine(@"C:\Users\Administrator\Desktop\Output", $"Page-{i + 1}.txt");
File.WriteAllText(outputTxtPath, pageText);
}
}
// Close the document
doc.Close();
}
}
}
Key Components Explained :
- OcrScanner Class : This class is crucial for performing OCR. It provides methods to configure and execute the scanning operation.
- ConfigureOptions Class : This class is used to set up the OCR scanner's configurations. The ModelPath property specifies the path to the OCR model files, and the Language property allows you to specify the language for text recognition.
- PdfDocument Class : This class represents the PDF document. The LoadFromFile method loads the PDF file that you want to process.
- Image Conversion : Each PDF page is converted to an image using the SaveAsImage method. This is essential because OCR works on image files.
- MemoryStream : The image is saved into a MemoryStream , allowing us to perform OCR without saving the image to disk.
- OCR Processing : The Scan method performs OCR on the image stream. The recognized text can be accessed using the Text property of the OcrScanner instance.
- Output : The extracted text is saved to a text file for each page.
Output :
To extract text from searchable PDFs, refer to this guide: Automate PDF Text Extraction Using C#
Extracting Text from Images within PDFs in C#
In addition to processing entire PDF pages, you can also extract text from images embedded within PDFs. Here’s how:
using Spire.OCR;
using Spire.Pdf;
using Spire.Pdf.Graphics;
using System.Drawing;
namespace OCRPDF
{
class Program
{
static void Main(string[] args)
{
// Create an instance of the OcrScanner class
OcrScanner scanner = new OcrScanner();
// Configure the scanner
ConfigureOptions configureOptions = new ConfigureOptions
{
ModelPath = @"D:\win-x64", // Set model path
Language = "English" // Set language
};
// Apply the configuration options
scanner.ConfigureDependencies(configureOptions);
// Load a PDF document
PdfDocument doc = new PdfDocument();
doc.LoadFromFile(@"C:\Users\Administrator\Desktop\Input5.pdf");
// Iterate through all pages
for (int i = 0; i < doc.Pages.Count; i++)
{
// Convert page to image
Image image = doc.SaveAsImage(i, PdfImageType.Bitmap);
// Convert the image to a MemoryStream
using (MemoryStream stream = new MemoryStream())
{
image.Save(stream, System.Drawing.Imaging.ImageFormat.Png);
stream.Position = 0; // Reset the stream position
// Perform OCR on the image stream
scanner.Scan(stream, OCRImageFormat.Png);
string pageText = scanner.Text.ToString();
// Save extracted text to a separate file
string outputTxtPath = Path.Combine(@"C:\Users\Administrator\Desktop\Output", $"Page-{i + 1}.txt");
File.WriteAllText(outputTxtPath, pageText);
}
}
// Close the document
doc.Close();
}
}
}
Key Components Explained :
- PdfImageHelper Class : This class is essential for extracting images from a PDF page. It provides methods to retrieve image information such as GetImagesInfo , which returns an array of PdfImageInfo objects.
- PdfImageInfo Class : Each PdfImageInfo object contains properties related to an image, including the actual Image object that can be processed further.
- Image Processing : Similar to the previous example, each image is saved to a MemoryStream for OCR processing.
- Output : The extracted text from each image is saved to a separate text file.
Output:
Wrapping Up
By combining Spire.PDF with Spire.OCR , you can seamlessly transform scanned PDFs and image-based documents into fully searchable and editable text. Whether you need to process entire pages or extract text from specific embedded images, the approach is straightforward and flexible.
This OCR integration not only streamlines document digitization but also enhances productivity by enabling search, copy, and automated data extraction. In industries where large volumes of scanned documents are the norm, implementing OCR with C# can significantly improve accessibility, compliance, and information retrieval speed.
FAQs
Q1. Can I perform OCR on non-English PDFs?
Yes, Spire.OCR supports multiple languages. You can set the Language property in ConfigureOptions to the desired language.
Q2. What should I do if the output is garbled or incorrect?
Check the quality of the input PDF images. If the images are blurry or have low contrast, OCR may struggle to recognize text accurately. Consider enhancing the image quality before processing.
Q3. Can I extract text from images embedded within a PDF?
Yes, you can. Use a helper class to extract images from each page and then apply OCR to recognize text.
Q4. Can Spire.OCR handle handwritten text in PDFs?
Spire.OCR is primarily optimized for printed text. Handwriting recognition typically has lower accuracy.
Q5. Do I need to install additional language models for OCR?
Yes, Spire.OCR requires pre-trained language model files. Download and configure the appropriate models for your target language before performing OCR.
Get a Free License
To fully experience the capabilities of Spire.PDF for .NET and Spire.OCR for .NET without any evaluation limitations, you can request a free 30-day trial license.
Extract Image from PDF and Save it to New PDF File in C#
2013-12-12 07:44:14 Written by AdministratorExtracting image from PDF is not a complex operation, but sometimes we need to save the image to new PDF file. So the article describes the simple c# code to extract image from PDF and save it to new PDF file through a professional PDF .NET library Spire.PDF.
First we need to complete the preparatory work before the procedure:
- Download the Spire.PDF and install it on your machine.
- Add the Spire.PDF.dll files as reference.
- Open bin folder and select the three dll files under .NET 4.0.
- Right click property and select properties in its menu.
- Set the target framework as .NET 4.
- Add Spire.PDF as namespace.
The following steps will show you how to do this with ease:
Step 1: Create a PDF document.
PdfDocument doc = new PdfDocument(); doc.LoadFromFile(@"..\..\Sample.pdf");
Step 2: Extract the image from PDF document.
doc.ExtractImages();
Step 3: Save image file.
image.Save("image.png",System.Drawing.Imaging.ImageFormat.Png);
PdfImage image2 = PdfImage.FromFile(@"image.png");
PdfDocument doc2=new PdfDocument ();
PdfPageBase page=doc2.Pages.Add();
Step 4: Draw image to new PDF file.
float width = image.Width * 0.75f; float height = image.Height * 0.75f; float x = (page.Canvas.ClientSize.Width - width) / 2; page.Canvas.DrawImage(image2,x,60,width,height); doc2.SaveToFile(@"..\..\Image.pdf");
Here is the whole code:
static void Main(string[] args)
{
PdfDocument doc = new PdfDocument();
doc.LoadFromFile(@"..\..\Sample.pdf");
doc.ExtractImages();
image.Save("image.png",System.Drawing.Imaging.ImageFormat.Png);
PdfImage image2 = PdfImage.FromFile(@"image.png");
PdfDocument doc2=new PdfDocument ();
PdfPageBase page=doc2.Pages.Add();
float width = image.Width * 0.75f;
float height = image.Height * 0.75f;
float x = (page.Canvas.ClientSize.Width - width) / 2;
page.Canvas.DrawImage(image2,x,60,width,height);
doc2.SaveToFile(@"..\..\Image.pdf");
}
Here comes to the preview of the effect picture:
Extracting images from PDFs is a common task for many users, whether it's for repurposing visuals in a presentation, archiving important graphics, or facilitating easier analysis. By mastering image extraction using C#, developers can enhance resource management and streamline their workflow.
In this article, you will learn how to extract images from individual PDF pages as well as from entire documents using C# and Spire.PDF for .NET.
Install Spire.PDF for .NET
To begin with, you need to add the DLL files included in the Spire.PDF for.NET package as references in your .NET project. The DLL files can be either downloaded from this link or installed via NuGet.
PM> Install-Package Spire.PDF
Extract Images from a Specific PDF Page
The PdfImageHelper class in Spire.PDF for .NET is designed to help users manage images within PDF documents. It allows for various operations, such as deleting, replacing, and retrieving images.
To obtain information about the images on a specific PDF page, developers can utilize the PdfImageHelper.GetImagesInfo(PdfPageBase page) method. Once they have the image information, they can save the images to files using the PdfImageInfo.Image.Save() method.
The steps to extract images from a specific PDF page are as follows:
- Create a PdfDocument object.
- Load a PDF file using PdfDocument.LoadFromFile() method.
- Get a specific page using PdfDocument.Pages[index] property.
- Create a PdfImageHelper object.
- Get the image information collection from the page using PdfImageHelper.GetImagesInfo() method.
- Iterate through the image information collection and save each instance as a PNG file using PdfImageInfo.Image.Save() method.
- C#
using Spire.Pdf;
using Spire.Pdf.Utilities;
using System.Drawing;
namespace ExtractImagesFromSpecificPage
{
class Program
{
static void Main(string[] args)
{
// Create a PdfDocument object
PdfDocument doc = new PdfDocument();
// Load a PDF document
doc.LoadFromFile("C:\\Users\\Administrator\\Desktop\\Input.pdf");
// Get a specific page
PdfPageBase page = doc.Pages[0];
// Create a PdfImageHelper object
PdfImageHelper imageHelper = new PdfImageHelper();
// Get all image information from the page
PdfImageInfo[] imageInfos = imageHelper.GetImagesInfo(page);
// Iterate through the image information
for (int i = 0; i < imageInfos.Length; i++)
{
// Get a specific image information
PdfImageInfo imageInfo = imageInfos[i];
// Get the image
Image image = imageInfo.Image;
// Save the image to a png file
image.Save("C:\\Users\\Administrator\\Desktop\\Extracted\\Image-" + i + ".png");
}
// Dispose resources
doc.Dispose();
}
}
}
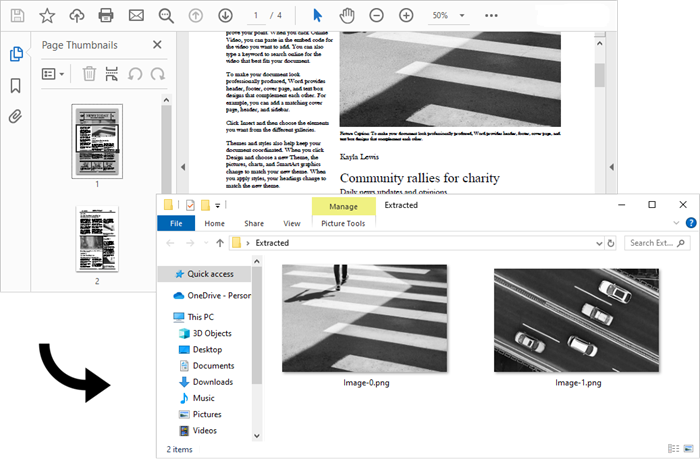
Extract All Images from an Entire PDF Document
Now that you know how to extract images from a specific page, you can iterate through the pages in a PDF document and extract images from each page. This allows you to collect all the images contained in the document.
The steps to extract all images throughout an entire PDF document are as follows:
- Create a PdfDocument object.
- Load a PDF file using PdfDocument.LoadFromFile() method.
- Create a PdfImageHelper object.
- Iterate through the pages in the document.
- Get a specific page using PdfDocument.Pages[index] property.
- Get the image information collection from the page using PdfImageHelper.GetImagesInfo() method.
- Iterate through the image information collection and save each instance as a PNG file using PdfImageInfo.Image.Save() method.
- C#
using Spire.Pdf;
using Spire.Pdf.Utilities;
using System.Drawing;
namespace ExtractAllImages
{
class Program
{
static void Main(string[] args)
{
// Create a PdfDocument object
PdfDocument doc = new PdfDocument();
// Load a PDF document
doc.LoadFromFile("C:\\Users\\Administrator\\Desktop\\Input.pdf");
// Create a PdfImageHelper object
PdfImageHelper imageHelper = new PdfImageHelper();
// Declare an int variable
int m = 0;
// Iterate through the pages
for (int i = 0; i < doc.Pages.Count; i++)
{
// Get a specific page
PdfPageBase page = doc.Pages[i];
// Get all image information from the page
PdfImageInfo[] imageInfos = imageHelper.GetImagesInfo(page);
// Iterate through the image information
for (int j = 0; j < imageInfos.Length; j++)
{
// Get a specific image information
PdfImageInfo imageInfo = imageInfos[j];
// Get the image
Image image = imageInfo.Image;
// Save the image to a png file
image.Save("C:\\Users\\Administrator\\Desktop\\Extracted\\Image-" + m + ".png");
m++;
}
}
// Dispose resources
doc.Dispose();
}
}
}
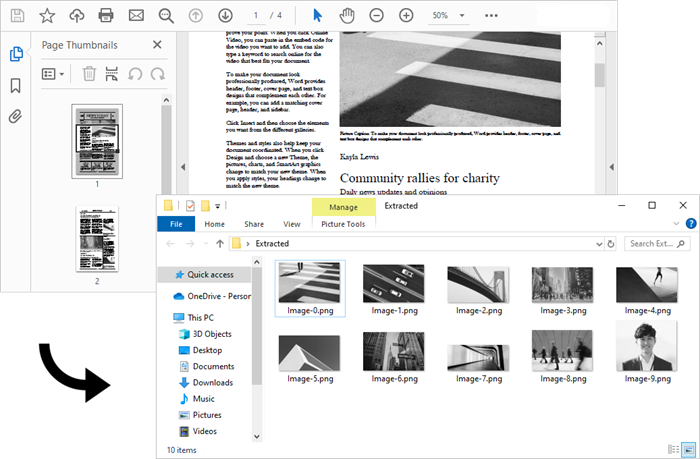
Apply for a Temporary License
If you'd like to remove the evaluation message from the generated documents, or to get rid of the function limitations, please request a 30-day trial license for yourself.
Effortlessly Automate PDF Text Extraction Using C# .NET: A Complete Guide
2022-07-29 06:33:00 Written by Koohji
Manually extracting text from PDF files can be tedious, error-prone, and inefficient—especially when working with large volumes of documents or complex layouts. PDFs store content based on coordinates rather than linear text flow, making it difficult to retrieve structured or readable text without specialized tools.
For developers working in C# .NET, automating PDF text extraction is essential for streamlining workflows such as document processing, content indexing, data migration, and digital archiving.
This comprehensive guide shows you how to read text from PDF using C# and Spire.PDF for .NET, a powerful library for reading and processing PDF documents. You’ll learn how to:
- Extract full-text content from entire documents
- Retrieve text from individual pages
- Capture content within defined regions
- Obtain position and font metadata for advanced use cases
Whether you're building a PDF parser, developing an automated document management system, or migrating PDF data into structured formats, this article provides ready-to-use C# code examples and best practices to help you extract text from PDFs quickly, accurately, and at scale.
Table of Contents
- Why Use Spire.PDF for Text Extraction in .NET?
- Extract Text from PDF (Basic Example)
- Advanced Text Extraction Options
- Conclusion
- FAQs
Why Use Spire.PDF for Text Extraction in .NET?
Spire.PDF for .NET is a feature-rich and developer friendly library that supports seamless text extraction from PDFs in .NET applications. Here's why it stands out:
- Precise Layout Preservation: Maintains original layout, spacing, and reading order.
- Detailed Extraction: Retrieve text along with its metadata like position and size.
- No Adobe Dependency: Works independently of Adobe Acrobat or other third-party tools.
- Quick Integration: Clean API and extensive documentation for faster development.
Installation
Before getting started, install the library in your project via NuGet:
Install-Package Spire.PDF
Or download the DLL and manually reference it in your solution.
Extract Text from PDF (Basic Example)
Extract full text content from a PDF is crucial for capturing all information for analysis or processing.
This basic example extracts all text content from a PDF file uses the PdfTextExtractor class and saves it to a text file with the original spacing, line breaks and layout preserved.
using Spire.Pdf;
using Spire.Pdf.Texts;
using System.IO;
using System.Text;
namespace ExtractAllTextFromPDF
{
internal class Program
{
static void Main(string[] args)
{
// Create a PDF document instance
PdfDocument pdf = new PdfDocument();
// Load the PDF file
pdf.LoadFromFile("Sample.pdf");
// Initialize a StringBuilder to hold the extracted text
StringBuilder extractedText = new StringBuilder();
// Loop through each page in the PDF
foreach (PdfPageBase page in pdf.Pages)
{
// Create a PdfTextExtractor for the current page
PdfTextExtractor extractor = new PdfTextExtractor(page);
// Set extraction options
PdfTextExtractOptions option = new PdfTextExtractOptions
{
IsExtractAllText = true
};
// Extract text from the current page
string text = extractor.ExtractText(option);
// Append the extracted text to the StringBuilder
extractedText.AppendLine(text);
}
// Save the extracted text to a text file
File.WriteAllText("ExtractedText.txt", extractedText.ToString());
// Close the PDF document
pdf.Close();
}
}
}
Advanced Text Extraction Options
Spire.PDF offers more than basic full-document extraction. It supports advanced scenarios like retrieving text from specific pages, extracting content from defined areas, and accessing text layout details such as position and dimensions. This section explores these capabilities with practical examples.
Retrieve Text from Individual PDF Pages
Sometimes, you only need text from a particular page—for example, when processing a specific section of a multi-page document. You can access the desired page from the Pages collection of the document and then apply the extraction logic to it.
using Spire.Pdf;
using Spire.Pdf.Texts;
using System.IO;
namespace ExtractTextFromIndividualPages
{
internal class Program
{
static void Main(string[] args)
{
// Create a PDF document instance
PdfDocument pdf = new PdfDocument();
// Load the PDF file
pdf.LoadFromFile("Sample.pdf");
// Access the page to extract text from (e.g., index 1 = the second page)
PdfPageBase page = pdf.Pages[1];
// Create a PdfTextExtractor for the selected page
PdfTextExtractor extractor = new PdfTextExtractor(page);
// Set extraction options
PdfTextExtractOptions option = new PdfTextExtractOptions
{
IsExtractAllText = true
};
// Extract text from the specified page
string text = extractor.ExtractText(option);
// Save the extracted text to a text file
File.WriteAllText("IndividualPage.txt", text);
// Close the PDF document
pdf.Close();
}
}
}
Read Text within a Defined Area on a PDF Page
If you're interested in text within a specific rectangular area (e.g., header or footer), you can set a rectangular extraction region via PdfTextExtractOptions.ExtractArea to limit the extraction scope.
using Spire.Pdf;
using Spire.Pdf.Texts;
using System.IO;
using System.Drawing;
namespace ExtractTextFromDefinedArea
{
internal class Program
{
static void Main(string[] args)
{
// Create a PDF document instance
PdfDocument doc = new PdfDocument();
// Load the PDF file
doc.LoadFromFile("Sample.pdf");
// Get the second page
PdfPageBase page = doc.Pages[1];
// Create a PdfTextExtractor for the selected page
PdfTextExtractor textExtractor = new PdfTextExtractor(page);
// Set extraction options with a defined rectangular area
PdfTextExtractOptions extractOptions = new PdfTextExtractOptions
{
ExtractArea = new RectangleF(0, 0, 890, 170)
};
// Extract text from the specified rectangular area
string text = textExtractor.ExtractText(extractOptions);
// Save the extracted text to a text file
File.WriteAllText("Extracted.txt", text);
// Close the PDF document
doc.Close();
}
}
}
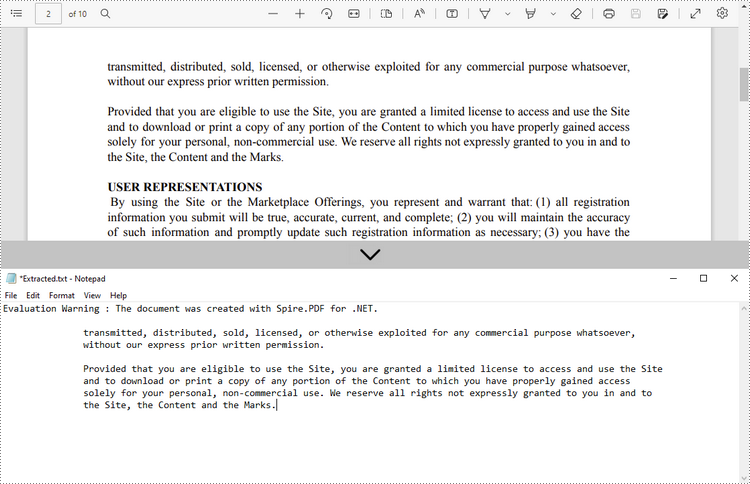
Get Text Position and Size Information for Advanced Processing
For advanced tasks like annotation or content overlay, accessing the position and size of each text fragment is crucial. You can obtain this information using PdfTextFinder and PdfTextFragment.
using Spire.Pdf;
using Spire.Pdf.Texts;
using System;
using System.Collections.Generic;
using System.Drawing;
namespace ExtractTextWithPositionAndSize
{
class Program
{
static void Main(string[] args)
{
// Load the PDF document
PdfDocument pdf = new PdfDocument();
pdf.LoadFromFile("Sample.pdf");
// Iterate through each page of the document
for (int i = 0; i < pdf.Pages.Count; i++)
{
PdfPageBase page = pdf.Pages[i];
// Create a PdfTextFinder object for the current page
PdfTextFinder finder = new PdfTextFinder(page);
// Find all text fragments on the page
List<PdfTextFragment> fragments = finder.FindAllText();
Console.WriteLine($"Page {i + 1}:");
// Iterate over each text fragment
foreach (PdfTextFragment fragment in fragments)
{
// Extract text content
string text = fragment.Text;
// Get bounding rectangles with position and size
RectangleF[] rects = fragment.Bounds;
Console.WriteLine($"Text: \"{text}\"");
// Iterate through each rectangle for this fragment
foreach (var rect in rects)
{
Console.WriteLine($"Position: ({rect.X}, {rect.Y}), Size: ({rect.Width} x {rect.Height})");
}
Console.WriteLine();
}
}
}
}
}
Conclusion
Whether you're performing simple extraction or building advanced document automation tools, Spire.PDF for .NET provides versatile and accurate methods to extract and manipulate PDF text:
- Full-text extraction for complete documents
- Page-level control to isolate relevant sections
- Area-based targeting for structured or repeated patterns
- Precise layout data for custom rendering and analysis
By combining these techniques, you can create powerful and flexible PDF processing workflows tailored to your application's needs.
FAQs
Q1: Can Spire.PDF extract text from password-protected PDFs?
A1: Yes, by providing the correct password when loading the documents, Spire.PDF can open and extract text from secured PDFs.
Q2: Does Spire.PDF support batch extraction?
A2: Absolutely. You can iterate over a directory of PDF files and apply the same extraction logic programmatically.
Q3: Can it extract font styles and sizes?
A3: Yes. Spire.PDF allows you to retrieve font-related details such as font name, size, style.
Q4: Can I extract images or tables as well?
A4: While text extraction is the focus of this guide, Spire.PDF can also extract images and supports table detection with additional logic.
Q5: Can Spire.PDF extract text from scanned (image-based) PDFs?
A5: Scanned PDFs require OCR (Optical Character Recognition). Spire.PDF doesn't provide built-in OCR, but you can combine it with an OCR library - Spire.OCR for image-to-text conversion.
Get a Free License
To fully experience the capabilities of Spire.PDF for .NET without any evaluation limitations, you can request a free 30-day trial license.
