
In modern Java applications, PDF data is not always stored as files on disk. Instead, it may be transmitted over a network, returned by a REST API, or stored as a byte array in a database. In such cases, you’ll often need to convert a byte array back into a PDF file or even generate a new PDF from plain text bytes.
This tutorial will walk you through both scenarios using Spire.PDF for Java, a powerful library for working with PDF documents.
Table of Contents:
- Getting Started with Spire.PDF for Java
- Understanding PDF Bytes vs. Text Bytes
- Loading PDF from Byte Array
- Creating PDF from Text Bytes
- Common Pitfalls to Avoid
- Frequently Asked Questions
- Conclusion
Getting Started with Spire.PDF for Java
Spire.PDF is a powerful and feature-rich API that allows Java developers to create, read, edit, convert, and print PDF documents without any dependencies on Adobe Acrobat.
Key Features:
- Create PDFs with text, images, tables, and shapes.
- Edit existing PDFs and extract text and images.
- Convert PDFs to formats like HTML, Word, Excel, and images.
- Encrypt PDFs with password protection.
- Add watermarks, annotations, and digital signatures.
To get started, download Spire.PDF for Java from our website and add the JAR files to your project's build path. If you’re using Maven, include the following dependency in your pom.xml.
<repositories>
<repository>
<id>com.e-iceblue</id>
<name>e-iceblue</name>
<url>https://repo.e-iceblue.com/nexus/content/groups/public/</url>
</repository>
</repositories>
<dependencies>
<dependency>
<groupId>e-iceblue</groupId>
<artifactId>spire.pdf</artifactId>
<version>11.10.3</version>
</dependency>
</dependencies>
Once set up, you can now proceed to convert byte arrays to PDFs and perform other PDF-related operations.
Understanding PDF Bytes vs. Text Bytes
Before coding, it’s important to distinguish between two very different kinds of byte arrays :
- PDF File Bytes : These represent the actual binary structure of a valid PDF document. They always start with %PDF-1.x and contain objects, cross-reference tables, and streams. Such byte arrays can be loaded directly into a PdfDocument.
- Text Bytes : These are simply ASCII or UTF-8 encodings of characters. For example,
byte[] bytes = {84, 104, 105, 115};
System.out.println(new String(bytes)); // Output: "This"
Such arrays are not valid PDFs, but you can create a new PDF and write the text into it.
Loading PDF from Byte Array in Java
Suppose you want to download a PDF from a URL and work with it in memory as a byte array. With Spire.PDF for Java, you can easily load and save it back as a PDF document.
import com.spire.pdf.PdfDocument;
import java.io.ByteArrayInputStream;
import java.io.ByteArrayOutputStream;
import java.io.InputStream;
import java.net.HttpURLConnection;
import java.net.URL;
public class LoadPdfFromByteArray throws Exception{
public static void main(String[] args) {
// The PDF URL
String fileUrl = "https://www.e-iceblue.com/resource/sample.pdf";
// Download PDF into a byte array
byte[] pdfBytes = downloadPdfAsBytes(fileUrl);
// Create a PdfDocument object
PdfDocument doc = new PdfDocument();
// Load PDF from byte array
doc.loadFromStream(new ByteArrayInputStream(pdfBytes));
// Save the document locally
doc.saveToFile("downloaded.pdf");
doc.close();
}
// Helper method: download file as byte[]
private static byte[] downloadPdfAsBytes(String fileUrl) throws Exception {
URL url = new URL(fileUrl);
HttpURLConnection conn = (HttpURLConnection) url.openConnection();
conn.setRequestMethod("GET");
InputStream inputStream = conn.getInputStream();
ByteArrayOutputStream buffer = new ByteArrayOutputStream();
byte[] data = new byte[4096];
int nRead;
while ((nRead = inputStream.read(data, 0, data.length)) != -1) {
buffer.write(data, 0, nRead);
}
buffer.flush();
inputStream.close();
conn.disconnect();
return buffer.toByteArray();
}
}
How this works
- Make an HTTP request to fetch the PDF file.
- Convert the InputStream into a byte array using ByteArrayOutputStream .
- Pass the byte array into Spire.PDF via loadFromStream .
- Save or manipulate the document as needed.
Output:
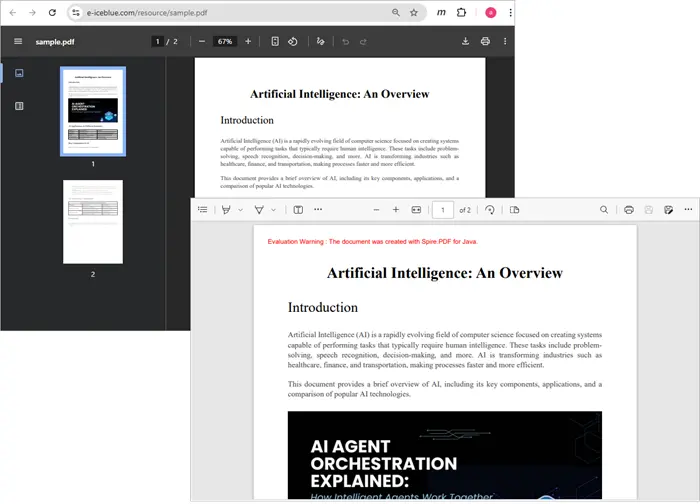
Creating PDF from Text Bytes in Java
If you only have plain text bytes (e.g., This document is created from text bytes.), you can decode them into a string and then draw the text onto a new PDF document.
import com.spire.pdf.*;
import com.spire.pdf.graphics.*;
import java.awt.*;
public class TextFromBytesToPdf {
public static void main(String[] args) {
// Your text bytes
byte[] byteArray = {
84, 104, 105, 115, 32,
100, 111, 99, 117, 109, 101, 110, 116, 32,
105, 115, 32,
99, 114, 101, 97, 116, 101, 100, 32,
102, 114, 111, 109, 32,
116, 101, 120, 116, 32,
98, 121, 116, 101, 115, 46
};
String text = new String(byteArray);
// Create a PDF document
PdfDocument doc = new PdfDocument();
// Configure the page settings
doc.getPageSettings().setSize(PdfPageSize.A4);
doc.getPageSettings().setMargins(40f);
// Add a page
PdfPageBase page = doc.getPages().add();
// Draw the string onto PDF
PdfFont font = new PdfFont(PdfFontFamily.Helvetica, 20f);
PdfSolidBrush brush = new PdfSolidBrush(new PdfRGBColor(Color.black));
page.getCanvas().drawString(text, font, brush, 20, 40);
// Save the document to a PDF file
doc.saveToFile("TextBytes.pdf");
doc.close();
}
}
This will produce a new PDF named TextBytes.pdf (shown below) containing the sentence represented by your byte array.

You might be interested in: How to Generate PDF Documents in Java
Common Pitfalls to Avoid
When converting byte arrays to PDFs, watch out for these issues:
- Confusing plain text with PDF bytes
Not every byte array is a valid PDF. Unless the array starts with %PDF-1.x and contains the proper structure, you can’t load it directly with PdfDocument.loadFromStream .
- Incorrect encoding
If your text bytes are in UTF-16, ISO-8859-1, or another encoding, you need to specify the charset when creating a string:
String text = new String(byteArray, StandardCharsets.UTF_8);
- Large byte arrays
When dealing with large PDFs, consider streaming instead of holding everything in memory to avoid OutOfMemoryError .
- Forgetting to close documents
Always call doc.close() to release resources after saving or processing a PDF.
Frequently Asked Questions
Q1. Can I store a PDF as a byte array in a database?
Yes. You can store a PDF as a BLOB in a relational database. Later, you can retrieve it, load it into a PdfDocument , and save or manipulate it.
Q2. How do I check if a byte array is a valid PDF?
Check if the array begins with the %PDF- header. You can do:
String header = new String(Arrays.copyOfRange(bytes, 0, 5));
if (header.startsWith("%PDF-")) {
// valid PDF
}
Q3. Can Spire.PDF load a PDF directly from an InputStream?
Yes. Instead of converting to a byte array, you can pass the InputStream directly to loadFromStream() .
Q4. Can I convert a PdfDocument back into a byte array?
You can save the document into a ByteArrayOutputStream instead of a file:
ByteArrayOutputStream baos = new ByteArrayOutputStream();
doc.saveToStream(baos);
byte[] pdfBytes = baos.toByteArray();
Q5. What if my byte array contains images instead of text or PDF?
In that case, you’ll need to create a new PDF and insert the image using Spire.PDF’s drawing APIs.
Conclusion
In this article, we explored how to efficiently convert byte arrays to PDF documents using Spire.PDF for Java. Whether you're loading existing PDF files from byte arrays retrieved via APIs or creating new PDFs from plain text bytes, Spire.PDF provides a robust solution to meet your needs.
We covered essential concepts, including the distinction between PDF file bytes and text bytes, and highlighted common pitfalls to avoid during the conversion process. With the right understanding and tools, you can seamlessly integrate PDF functionalities into your Java applications, enhancing your ability to manage and manipulate document data.
For further exploration, consider experimenting with additional features of Spire.PDF, such as editing, encrypting, and converting PDFs to other formats. The possibilities are extensive, and mastering these techniques will undoubtedly improve your development skills and project outcomes.
