
When working with reports, invoices, or datasets stored in PDF format, developers often need a way to reuse the tabular data in spreadsheets, databases, or analytical tools. A common solution is to convert PDF to CSV using Java, since CSV is lightweight, structured, and compatible with almost every platform.
Unlike text or image export, a PDF-to-CSV conversion is mainly about extracting tables from PDF and saving them as CSV. With the help of Spire.PDF for Java, you can detect table structures in PDFs and export them programmatically with just a few lines of code.
In this article, you’ll learn step by step how to perform a PDF to CSV conversion in Java—from setting up the environment, to extracting tables, and even handling more complex scenarios like multi-page documents or multiple tables per page.
Overview of This Tutorial
Environment Setup for PDF to CSV Conversion in Java
Before extracting tables and converting PDF to CSV using Java, you need to set up the development environment. This involves choosing a suitable library and adding it to your project.
Why Choose Spire.PDF for Java
Since PDF files do not provide a built-in export to CSV, extracting tables programmatically is the practical approach. Spire.PDF for Java offers APIs to detect table structures in PDF documents and save them directly as CSV files, making the conversion process simple and efficient.
Install Spire.PDF for Java
Add Spire.PDF for Java to your project using Maven:
<repositories>
<repository>
<id>com.e-iceblue</id>
<name>e-iceblue</name>
<url>https://repo.e-iceblue.com/nexus/content/groups/public/</url>
</repository>
</repositories>
<dependencies>
<dependency>
<groupId>e-iceblue</groupId>
<artifactId>spire.pdf</artifactId>
<version>11.10.3</version>
</dependency>
</dependencies>
If you are not using Maven, you can download the Spire.PDF for Java package and add the JAR files to your project’s classpath.
Extract Tables from PDF and Save as CSV
The most practical way to perform PDF to CSV conversion is by extracting tables. With Spire.PDF for Java, this can be done with just a few steps:
- Load the PDF document.
- Use PdfTableExtractor to find tables on each page.
- Collect cell values row by row.
- Write the output into a CSV file.
Here is a Java example that shows the process from start to finish:
Java Code Example for PDF to CSV Conversion
import com.spire.pdf.*;
import com.spire.pdf.utilities.*;
import java.io.*;
public class PdfToCsvExample {
public static void main(String[] args) throws Exception {
// Load the PDF document
PdfDocument pdf = new PdfDocument();
pdf.loadFromFile("Sample.pdf");
// Create a StringBuilder to store extracted text
StringBuilder sb = new StringBuilder();
// Iterate through each page
for (int i = 0; i < pdf.getPages().getCount(); i++) {
PdfTableExtractor extractor = new PdfTableExtractor(pdf);
PdfTable[] tableLists = extractor.extractTable(i);
if (tableLists != null) {
for (PdfTable table : tableLists) {
for (int row = 0; row < table.getRowCount(); row++) {
for (int col = 0; col < table.getColumnCount(); col++) {
// Escape the cell text safely
String cellText = escapeCsvField(table.getText(row, col));
sb.append(cellText);
if (col < table.getColumnCount() - 1) {
sb.append(",");
}
}
sb.append("\n");
}
}
}
}
// Write the output to a CSV file
FileWriter writer = new FileWriter("output/PDFTable.csv");
writer.write(sb.toString());
writer.close();
pdf.close();
System.out.println("PDF tables successfully exported to CSV.");
}
// Utility method to escape CSV fields
private static String escapeCsvField(String text) {
if (text == null) return "";
// Remove line breaks
text = text.replaceAll("[\\n\\r]", "");
// Escape if contains special characters
if (text.contains(",") || text.contains(";") || text.contains("\"") || text.contains("\n")) {
text = text.replace("\"", "\"\""); // Escape double quotes
text = "\"" + text + "\""; // Wrap with quotes
}
return text;
}
}
Code Walkthrough
- PdfDocument loads the PDF file into memory.
- PdfTableExtractor checks each page for tables.
- PdfTable provides access to rows and columns.
- escapeCsvField() removes line breaks and safely quotes/escapes text if needed.
- StringBuilder accumulates cell text, separated by commas.
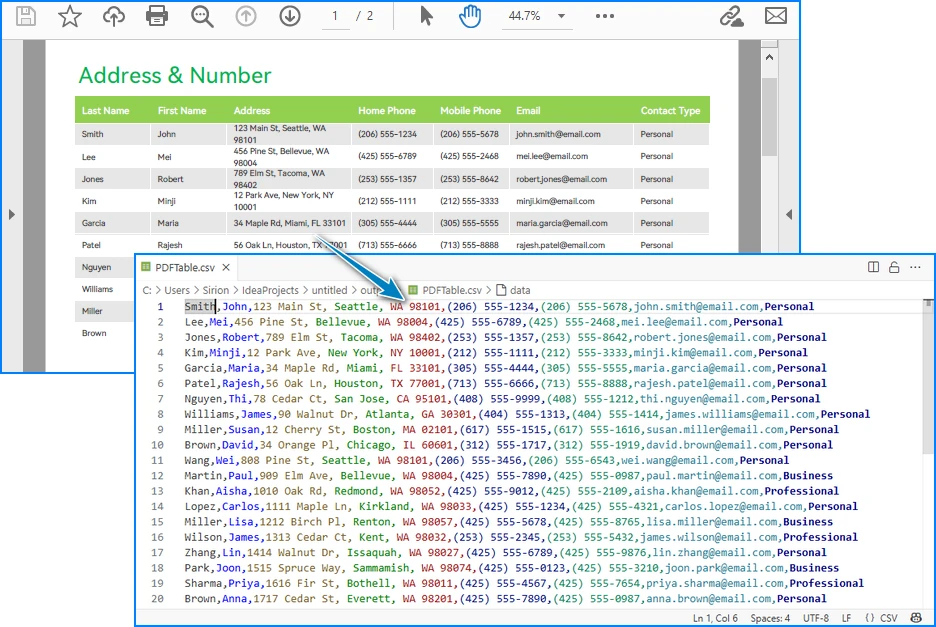
- The result is written into Output.csv, which you can open in Excel or any editor.
CSV file generated from a PDF table after running the Java code.
Handling Complex PDF-to-CSV Conversion Cases
In practice, PDFs often contain multiple tables, span multiple pages, or have irregular structures. Let’s see how to extend the solution to handle these scenarios.
1. Multiple Tables per Page
The PdfTable[] returned by extractTable(i) contains all tables detected on a page. You can process each one separately. For example, to save each table as a different CSV file:
for (int i = 0; i < pdf.getPages().getCount(); i++) {
PdfTableExtractor extractor = new PdfTableExtractor(pdf);
PdfTable[] tableLists = extractor.extractTable(i);
if (tableLists != null) {
for (int t = 0; t < tableLists.length; t++) {
PdfTable table = tableLists[t];
StringBuilder tableContent = new StringBuilder();
for (int row = 0; row < table.getRowCount(); row++) {
for (int col = 0; col < table.getColumnCount(); col++) {
tableContent.append(escapeCsvField(table.getText(row, col)));
if (col < table.getColumnCount() - 1) {
tableContent.append(",");
}
}
tableContent.append("\n");
}
FileWriter writer = new FileWriter("Table_Page" + i + "_Index" + t + ".csv");
writer.write(tableContent.toString());
writer.close();
}
}
}
Example of multiple tables in one PDF page exported into separate CSV files.
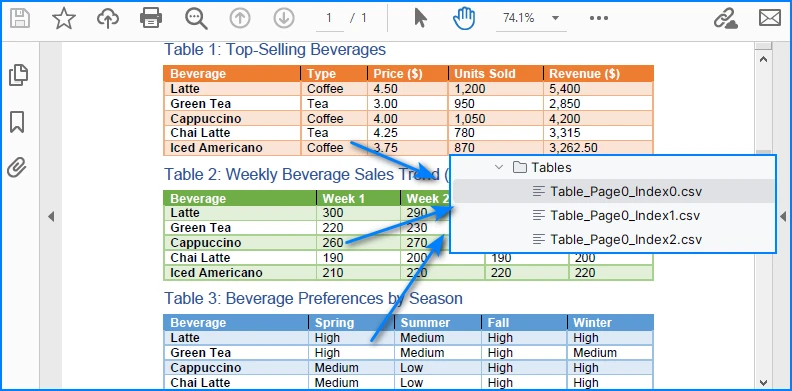
This way, every table is saved as an independent CSV file for better organization.
2. Multi-page or Large Tables
If a table spans across multiple pages, iterating page by page ensures that all data is collected. The key is to append data instead of overwriting:
StringBuilder sb = new StringBuilder();
for (int i = 0; i < pdf.getPages().getCount(); i++) {
PdfTableExtractor extractor = new PdfTableExtractor(pdf);
PdfTable[] tables = extractor.extractTable(i);
if (tables != null) {
for (PdfTable table : tables) {
for (int row = 0; row < table.getRowCount(); row++) {
for (int col = 0; col < table.getColumnCount(); col++) {
sb.append(escapeCsvField(table.getText(row, col)));
if (col < table.getColumnCount() - 1) sb.append(",");
}
sb.append("\n");
}
}
}
}
FileWriter writer = new FileWriter("MergedTables.csv");
writer.write(sb.toString());
writer.close();
Example of a large table across multiple PDF pages merged into one CSV file.
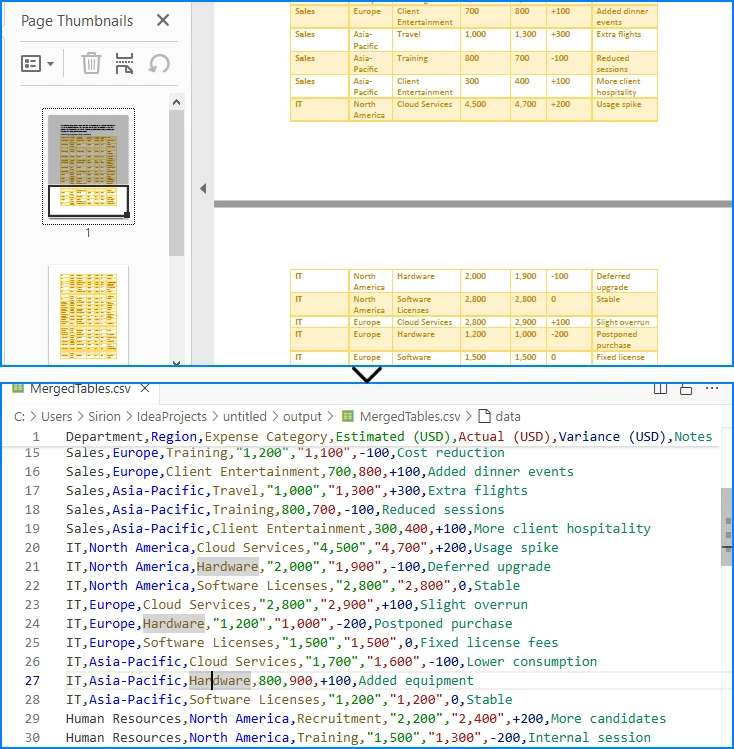
Here, all tables across pages are merged into one CSV file, useful when dealing with continuous reports.
3. Limitations with Formatting
CSV only stores plain text values. Elements like merged cells, fonts, or images are discarded. If preserving styling is critical, exporting to Excel (.xlsx) is a better alternative, which the same library also supports. See How to Export PDF Table to Excel in Java for more details.
4. CSV Special Characters Handling
When writing tables to CSV, certain characters like commas, semicolons, double quotes, or line breaks can break the file structure if not handled properly.
In the Java examples above, the escapeCsvField method removes line breaks and safely quotes or escapes text when needed.
For more advanced scenarios, you can also use Spire.XLS for Java to write data into worksheets and then save as CSV, which automatically handles special characters and ensures correct CSV formatting without manual processing.
Alternatively, for open-source options, libraries like OpenCSV or Apache Commons CSV also automatically handle special characters and CSV formatting, reducing potential issues and simplifying code.
Conclusion
Converting PDF to CSV in Java essentially means extracting tables and saving them in a structured format. CSV is widely supported, lightweight, and ideal for storing and analyzing tabular data. By setting up Spire.PDF for Java and following the code example, you can automate this process, saving time and reducing manual effort.
If you want to explore more advanced features of Spire.PDF for Java, please apply for a free trial license. You can also use Free Spire.PDF for Java for small projects.
FAQ
Q: Can I turn a PDF into a CSV file? A: Yes. While images and styled text cannot be exported, you can extract tables and save them as CSV files using Java.
Q: How to extract data from a PDF file in Java? A: Use a PDF library like Spire.PDF for Java to parse the document, detect tables, and export them to CSV or Excel.
Q: What is the best PDF to CSV converter? A: For Java developers, programmatic solutions such as Spire.PDF for Java offer more flexibility and automation than manual converters.
Q: How to convert PDF to Excel using Java code? A: The process is similar to CSV export. Instead of writing data as comma-separated text, you can export tables into Excel format for richer features.
