
Word documents (.doc and .docx) are widely used in business, education, and professional workflows for reports, contracts, manuals, and other essential content. As a C# developer, you may find the need to programmatically read these files to extract information, analyze content, and integrate document data into applications.
In this complete guide, we will delve into the process of reading Word documents in C#. We will explore various scenarios, including:
- Extracting text, paragraphs, and formatting details
- Retrieving images and structured table data
- Accessing comments and document metadata
- Reading headers and footers for comprehensive document analysis
By the end of this guide, you will have a solid understanding of how to efficiently parse Word documents in C#, allowing your applications to access and utilize document content with accuracy and ease.
Table of Contents
- Set Up Your Development Environment for Reading Word Documents in C#
- Load Word Document (.doc/.docx) in C#
- Read and Extract Content from Word Document in C#
- Advanced Tips and Best Practices for Reading Word Documents in C#
- Conclusion
- FAQs
Set Up Your Development Environment for Reading Word Documents in C#
Before you can read Word documents in C#, it’s crucial to ensure that your development environment is properly set up. This section outlines the necessary prerequisites and step-by-step installation instructions to get you ready for seamless Word document handling.
Prerequisites
- Development Environment: Ensure you have Visual Studio or another compatible C# IDE installed.
- .NET Requirement: Ensure you have .NET Framework or .NET Core installed.
- Library Requirement: Spire.Doc for .NET, a versatile library that allows developers to:
- Create Word documents from scratch
- Edit and format existing Word documents
- Read and extract text, tables, images, and other content programmatically
- Convert Word documents to PDF, HTML, and other formats
- Work independently without requiring Microsoft Word installation
Install Spire.Doc
To incorporate Spire.Doc into your C# project, follow these steps to install it via NuGet:
- Open your project in Visual Studio.
- Right-click on your project in the Solution Explorer and select Manage NuGet Packages.
- In the Browse tab, search for "Spire.Doc" and click Install.
Alternatively, you can use the Package Manager Console with the following command:
PM> Install-Package Spire.Doc
This installation adds the necessary references, enabling you to programmatically work with Word documents.
Load Word Document (.doc/.docx) in C#
To begin, you need to load a Word document into your project. The following example demonstrates how to load a .docx or .doc file in C#:
using Spire.Doc;
using Spire.Doc.Documents;
using System;
namespace LoadWordExample
{
class Program
{
static void Main(string[] args)
{
// Specify the path of the Word document
string filePath = @"C:\Documents\Sample.docx";
// Create a Document object
using (Document document = new Document())
{
// Load the Word .docx or .doc document
document.LoadFromFile(filePath);
}
}
}
}
This code loads a Word file from the specified path into a Document object, which is the entry point for accessing all document elements.
Read and Extract Content from Word Document in C#
After loading the Word document into a Document object, you can access its contents programmatically. This section covers various methods for extracting different types of content effectively.
Extract Text
Extracting text is often the first step in reading Word documents. You can retrieve all text content using the built-in GetText() method:
using (StreamWriter writer = new StreamWriter("ExtractedText.txt", false, Encoding.UTF8))
{
// Get all text from the document
string allText = document.GetText();
// Write the entire text to a file
writer.Write(allText);
}
This method extracts all text, disregarding formatting and non-text elements like images.
Read Paragraphs and Formatting Information
When working with Word documents, it is often useful not only to access the text content of paragraphs but also to understand how each paragraph is formatted. This includes details such as alignment and spacing after the paragraph, which can affect layout and readability.
The following example demonstrates how to iterate through all paragraphs in a Word document and retrieve their text content and paragraph-level formatting in C#:
using (StreamWriter writer = new StreamWriter("Paragraphs.txt", false, Encoding.UTF8))
{
// Loop through all sections
foreach (Section section in document.Sections)
{
// Loop through all paragraphs in the section
foreach (Paragraph paragraph in section.Paragraphs)
{
// Get paragraph alignment
HorizontalAlignment alignment = paragraph.Format.HorizontalAlignment;
// Get spacing after paragraph
float afterSpacing = paragraph.Format.AfterSpacing;
// Write paragraph formatting and text to the file
writer.WriteLine($"[Alignment: {alignment}, AfterSpacing: {afterSpacing}]");
writer.WriteLine(paragraph.Text);
writer.WriteLine(); // Add empty line between paragraphs
}
}
}
This approach allows you to extract both the text and key paragraph formatting attributes, which can be useful for tasks such as document analysis, conditional processing, or preserving layout when exporting content.
Extract Images
Images embedded within Word documents play a vital role in conveying information. To extract these images, you will examine each paragraph's content, identify images (typically represented as DocPicture objects), and save them for further use:
// Create the folder if it does not exist
string imageFolder = "ExtractedImages";
if (!Directory.Exists(imageFolder))
Directory.CreateDirectory(imageFolder);
int imageIndex = 1;
// Loop through sections and paragraphs to find images
foreach (Section section in document.Sections)
{
foreach (Paragraph paragraph in section.Paragraphs)
{
foreach (DocumentObject obj in paragraph.ChildObjects)
{
if (obj is DocPicture picture)
{
// Save each image as a separate PNG file
string fileName = Path.Combine(imageFolder, $"Image_{imageIndex}.png");
picture.Image.Save(fileName, System.Drawing.Imaging.ImageFormat.Png);
imageIndex++;
}
}
}
}
This code saves all images in the document as separate PNG files, with options to choose other formats like JPEG or BMP.
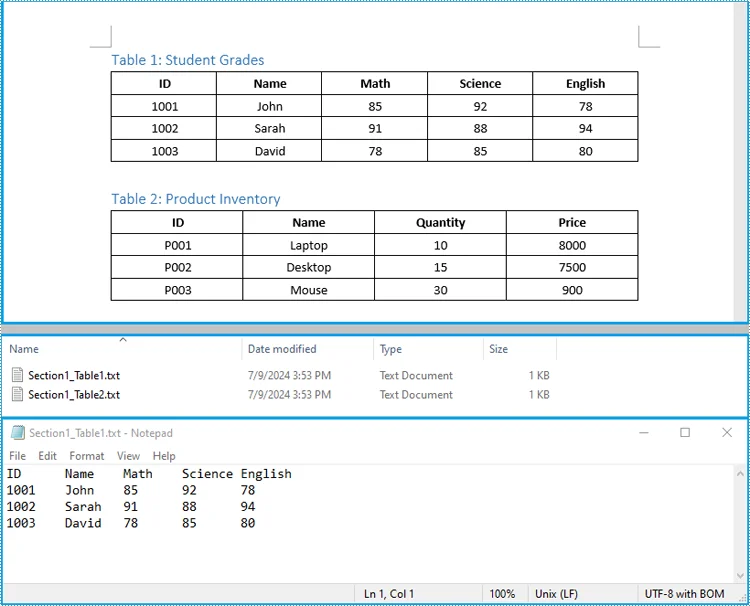
Extract Table Data
Tables are commonly used to organize structured data, such as financial reports or survey results. To access this data, iterate through the tables in each section and retrieve the content of individual cells:
// Create a folder to store tables
string tableDir = "Tables";
if (!Directory.Exists(tableDir))
Directory.CreateDirectory(tableDir);
// Loop through each section
for (int sectionIndex = 0; sectionIndex < document.Sections.Count; sectionIndex++)
{
Section section = document.Sections[sectionIndex];
TableCollection tables = section.Tables;
// Loop through all tables in the section
for (int tableIndex = 0; tableIndex < tables.Count; tableIndex++)
{
ITable table = tables[tableIndex];
string fileName = Path.Combine(tableDir, $"Section{sectionIndex + 1}_Table{tableIndex + 1}.txt");
using (StreamWriter writer = new StreamWriter(fileName, false, Encoding.UTF8))
{
// Loop through each row
for (int rowIndex = 0; rowIndex < table.Rows.Count; rowIndex++)
{
TableRow row = table.Rows[rowIndex];
// Loop through each cell
for (int cellIndex = 0; cellIndex < row.Cells.Count; cellIndex++)
{
TableCell cell = row.Cells[cellIndex];
// Loop through each paragraph in the cell
for (int paraIndex = 0; paraIndex < cell.Paragraphs.Count; paraIndex++)
{
writer.Write(cell.Paragraphs[paraIndex].Text.Trim() + " ");
}
// Add tab between cells
if (cellIndex < row.Cells.Count - 1) writer.Write("\t");
}
// Add newline after each row
writer.WriteLine();
}
}
}
}
This method allows efficient extraction of structured data, making it ideal for generating reports or integrating content into databases.
Read Comments
Comments are valuable for collaboration and feedback within documents. Extracting them is crucial for auditing and understanding the document's revision history.
The Document object provides a Comments collection, which allows you to access all comments in a Word document. Each comment contains one or more paragraphs, and you can extract their text for further processing or save them into a file.
using (StreamWriter writer = new StreamWriter("Comments.txt", false, Encoding.UTF8))
{
// Loop through all comments in the document
foreach (Comment comment in document.Comments)
{
// Loop through each paragraph in the comment
foreach (Paragraph p in comment.Body.Paragraphs)
{
writer.WriteLine(p.Text);
}
// Add empty line to separate different comments
writer.WriteLine();
}
}
This code retrieves the content of all comments and outputs it into a single text file.
Retrieve Document Metadata
Word documents contain metadata such as the title, author, and subject. These metadata items are stored as document properties, which can be accessed through the BuiltinDocumentProperties property of the Document object:
using (StreamWriter writer = new StreamWriter("Metadata.txt", false, Encoding.UTF8))
{
// Write built-in document properties to file
writer.WriteLine("Title: " + document.BuiltinDocumentProperties.Title);
writer.WriteLine("Author: " + document.BuiltinDocumentProperties.Author);
writer.WriteLine("Subject: " + document.BuiltinDocumentProperties.Subject);
}
Read Headers and Footers
Headers and footers frequently contain essential content like page numbers and titles. To programmatically access this information, iterate through each section's header and footer paragraphs and retrieve the text of each paragraph:
using (StreamWriter writer = new StreamWriter("HeadersFooters.txt", false, Encoding.UTF8))
{
// Loop through all sections
foreach (Section section in document.Sections)
{
// Write header paragraphs
foreach (Paragraph headerParagraph in section.HeadersFooters.Header.Paragraphs)
{
writer.WriteLine("Header: " + headerParagraph.Text);
}
// Write footer paragraphs
foreach (Paragraph footerParagraph in section.HeadersFooters.Footer.Paragraphs)
{
writer.WriteLine("Footer: " + footerParagraph.Text);
}
}
}
This method ensures that all recurring content is accurately captured during document processing.
Advanced Tips and Best Practices for Reading Word Documents in C#
To get the most out of programmatically reading Word documents, following these tips can help improve efficiency, reliability, and code maintainability:
- Use using Statements: Always wrap Document objects in using to ensure proper memory management.
- Check for Null or Empty Sections: Prevent errors by verifying sections, paragraphs, tables, or images exist before accessing them.
- Batch Reading Multiple Documents: Loop through a folder of Word files and apply the same extraction logic to each file. This helps automate workflows and consolidate extracted content efficiently.
Conclusion
Efficiently reading Word documents programmatically in C# involves handling various content types. With the techniques outlined in this guide, developers can:
- Load Word documents (.doc and .docx) with ease.
- Extract text, paragraphs, and formatting details for thorough analysis.
- Retrieve images, structured table data, and comments.
- Access headers, footers, and document metadata for complete insights.
FAQs
Q1: Can I read Word documents without installing Microsoft Word?
A1: Yes, libraries like Spire.Doc enable you to read and process Word files without requiring Microsoft Word installation.
Q2: Does this support both .doc and .docx formats?
A2: Absolutely, all methods discussed in this guide work seamlessly with both legacy (.doc) and modern (.docx) Word files.
Q3: Can I extract only specific sections of a document?
A3: Yes, by iterating through sections and paragraphs, you can selectively filter and extract the desired content.
