Converting PDF files to Excel spreadsheets in Python is an effective way to extract structured data for analysis, reporting, and automation. While PDFs are excellent for preserving layout across platforms, their static format often makes data extraction challenging.
Excel, on the other hand, provides robust features for sorting, filtering, calculating, and visualizing data. By using Python along with the Spire.PDF for Python library, you can automate the entire PDF to Excel conversion process — from basic one-page documents to complex, multi-page PDFs.
Whether you're automating data extraction from PDFs or integrating PDF content into Excel workflows, this tutorial will walk you through both quick-start and advanced methods for reliable Python PDF to Excel conversion.
Table of Contents
- Why Convert PDF to Excel Programmatically in Python
- Setting Up Your Development Environment
- Quick Start: Convert PDF to Excel in Python
- Advanced PDF to Excel Conversion with Layout Control and Formatting Options
- Conclusion
Why Convert PDF to Excel Programmatically in Python
PDFs are ideal for sharing documents with consistent formatting, but their fixed structure makes them difficult to analyze or reuse, especially if they contain tables.
Converting PDF to Excel allows you to:
- Extract tabular data for analysis or visualization
- Automate monthly or recurring report extraction
- Enable downstream processing in Excel
- Save hours of manual copy-pasting
Using Python for this task adds automation, flexibility, and scalability — ideal for integration into data pipelines or backend services.
Setting Up Your Development Environment
Before you start converting PDF files to Excel using Python, it’s essential to set up your development environment properly. This ensures you have all the necessary tools and libraries installed to follow the tutorial smoothly.
Install Python
If you haven’t already installed Python on your system, download and install the latest version from the official website.
Make sure to add Python to your system PATH during installation to run Python commands from the terminal or command prompt easily.
Install Spire.PDF for Python
Spire.PDF for Python is the core library used in this tutorial to load, manipulate, and convert PDF documents.
To install it, open your terminal and run:
pip install Spire.PDF
This command downloads and installs Spire.PDF along with any required dependencies.
If you encounter any issues or need detailed installation help, please refer to our step-by-step guide: How to Install Spire.PDF for Python on Windows
Quick Start: Convert PDF to Excel in Python
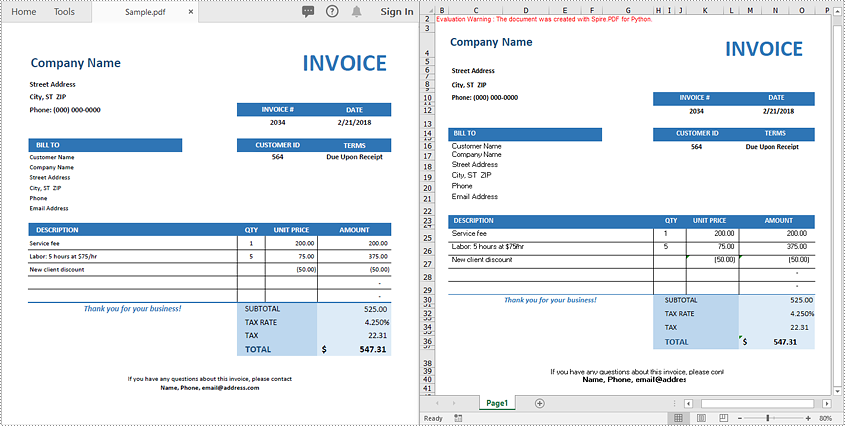
If your PDF has a clean and simple layout without complex formatting or multiple page structures, you can convert it directly to Excel with just 3 lines of code using Spire.PDF for Python.
Steps to Quickly Export PDF to Excel
Follow these straightforward steps to export your PDF file to an Excel spreadsheet in Python:
- Import the required classes.
- Create a PdfDocument object.
- Load your PDF file with the LoadFromFile method.
- Export the PDF to Excel (.xlsx) format using the SaveToFile method and specify FileFormat.XLSX as the output format.
Code Example
from spire.pdf import *
# Create a PdfDocument object
pdf = PdfDocument()
# Load your PDF file
pdf.LoadFromFile("Sample.pdf")
# Convert and save the PDF to Excel
pdf.SaveToFile("output.xlsx", FileFormat.XLSX)
# Close the document
pdf.Close()
Advanced PDF to Excel Conversion with Layout Control and Formatting Options
For more complex PDF documents—such as those containing multiple pages, rotated text, table cells with multiple lines of text, or overlapping content - you can use the XlsxLineLayoutOptions class to gain precise control over the conversion process.
This allows you to preserve the original structure and formatting of your PDF more accurately when exporting to Excel.
Layout Options You Can Configure
The XlsxLineLayoutOptions class in Spire.PDF provides several properties that give you granular control over how PDF content is exported to Excel. Below is a breakdown of each option and its behavior:
| Option | Description |
|---|---|
| convertToMultipleSheet | Determines whether to convert each PDF page into a separate worksheet. The default value is true. |
| rotatedText | Specifies whether to preserve the original rotation of angled text. The default value is true. |
| splitCell | Determines whether to split a PDF table cell with multiple lines of text into separate rows in the Excel output. The default value is true. |
| wrapText | Determines whether to enable word wrap inside Excel cells. The default value is true. |
| overlapText | Specifies whether text overlapping in the original PDF should be preserved in the Excel output. The default value is false. |
Code Example
from spire.pdf import *
# Create a PdfDocument object
pdf = PdfDocument()
# Load your PDF file
pdf.LoadFromFile("Sample.pdf")
# Define layout options
# Parameters: convertToMultipleSheet, rotatedText, splitCell, wrapText, overlapText
layout_options = XlsxLineLayoutOptions(True, True, False, True, False)
# Apply layout options
pdf.ConvertOptions.SetPdfToXlsxOptions(layout_options)
# Convert and save the PDF to Excel
pdf.SaveToFile("advanced_output.xlsx", FileFormat.XLSX)
# Close the document
pdf.Close()
Conclusion
Converting PDF files to Excel in Python is an efficient way to automate data extraction and processing tasks. Whether you need a quick conversion or fine-grained layout control, Spire.PDF for Python offers flexible options that scale from simple to complex scenarios.
Ready to automate your PDF to Excel conversions?
Get a free trial license for Spire.PDF for Python and explore the full Spire.PDF Documentation to get started today!
FAQs
Q1: Can I convert each PDF page into a separate Excel worksheet?
A1: Yes. Use the convertToMultipleSheet=True option in the XlsxLineLayoutOptions class to export each page to its own sheet.
Q2. What Excel format does Spire.PDF export to?
A2: Spire.PDF converts PDFs to .xlsx, the modern Excel format supported by Excel 2007 and later.
Q3: Can I convert a PDF to Excel in Python without losing formatting?
A3: Yes. Using Spire.PDF for Python, you can retain the original formatting, including merged cells, cell background colors, and other format settings when saving PDFs to Excel.
Q4: Can I extract only a specific table from a PDF to Excel instead of converting the whole document?
A4: Yes, Spire.PDF for Python supports extracting specific tables from PDF files. You can then write the extracted table data to Excel using our Excel processing library - Spire.XLS for Python.
