In today's digital age, extracting text from images or scanned PDFs is a common requirement for various applications. Optical Character Recognition (OCR) is a technology that enables computers to recognize and extract text from such documents. With it, we can effortlessly convert images and scanned PDFs into editable and searchable formats, making it easier to process and analyze the textual content. In this blog, we will explore how to extract text from images and scanned PDFs with OCR in C#.
- Extract Text from Images in C#
- Extract Text from Images with Coordinates in C#
- Extract Text from Scanned PDFs in C#
C# Libraries for Extracting Text from Images and Scanned PDFs
To extract text from images, we will utilize the Spire.OCR for .NET library. Spire.OCR for .NET is a powerful library designed specifically for extracting text from images in .NET applications. It supports various image formats such as BMP, JPG, PNG, TIFF, and GIF.
Here are the steps to install Spire.OCR for .NET:
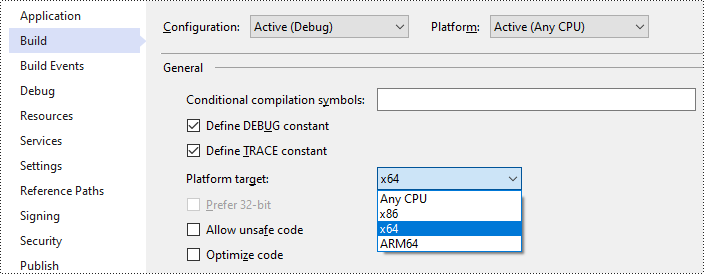
- Change the platform target of your solution to x64.
- Install Spire.OCR from NuGet by executing the following command in the NuGet Package Manager Console:
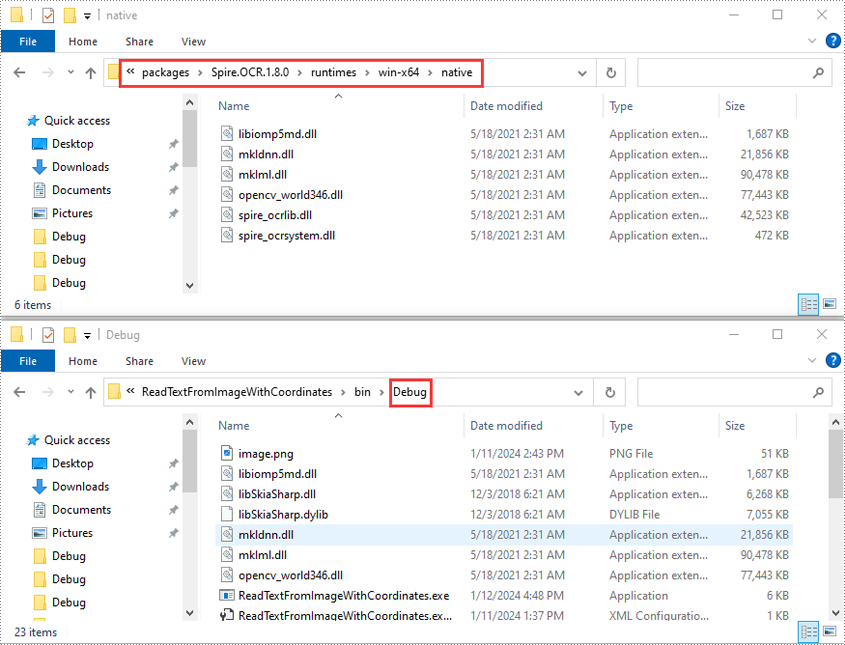
- Open your solution folder and navigate to the "packages\Spire.OCR.1.8.0\runtimes\win-x64\native" directory. Copy the DLL files from this directory and paste them into the "Debug" folder of your solution.
Install-Package Spire.OCR
To extract text from scanned PDFs, we first need to convert the PDF document into images. For this task, we will employ the Spire.PDF for .NET library. Once the conversion is complete, we can utilize Spire.OCR to extract text from the resulting images.
You can install Spire.PDF for .NET from NuGet by executing the following command in the NuGet Package Manager Console:
Install-Package Spire.PDF
Extract Text from Images in C#
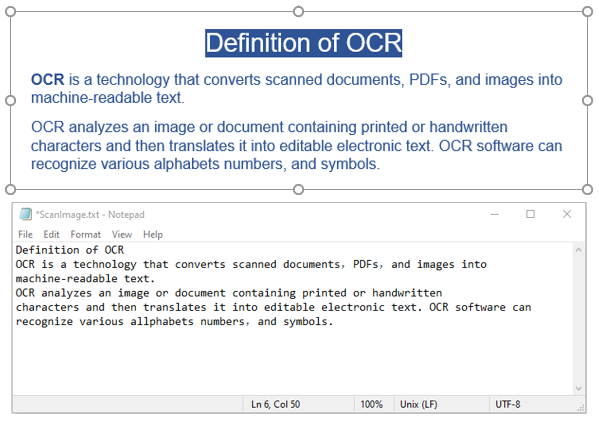
Spire.OCR provides the OcrScanner.Scan() method to recognize text from an image. After recognition, you can get the recognized text using the OcrScanner.Text property.
Here are the main steps to recognize text from an image using Spire.OCR:
- Create an instance of the OcrScanner class.
- Recognize text from an image using OcrScanner.Scan() method.
- Get the recognized text from the OcrScanner object using the OcrScanner.Text property.
- Save the text to a text file.
Here is a code example that shows how to recognize text from an image and save the result to a text file:
- C#
using Spire.OCR;
using System.IO;
namespace ReadTextFromImage
{
internal class Program
{
static void Main(string[] args)
{
//Specify the path of the input image file
string imageFilePath = "Image.png";
//Specify the path of the output text file
string outputFilePath = "ScanImage.txt";
//Call the ScanTextFromImage method to scan text from an image
string scannedText = ScanTextFromImage(imageFilePath);
//Write the text to the specified file
File.WriteAllText(outputFilePath, scannedText);
}
public static string ScanTextFromImage(string imageFilePath)
{
//Instantiate an OcrScanner object
using (OcrScanner ocrScanner = new OcrScanner())
{
//Scan text from the image
ocrScanner.Scan(imageFilePath);
//Get the recognized text from the OcrScanner object
IOCRText text = ocrScanner.Text;
//Return the text
return text.ToString();
}
}
}
}
Extract Text from Images with Coordinates in C#
Extracting coordinates is useful when you need to identify the exact location of specific text elements in your image. With Spire.OCR, you can retrieve the recognized text in blocks or lines. For each block, you can get its detailed location information, including the x and y coordinates, as well as its width and height.
Here are the main steps to extract text along with its location information from an image using Spire.OCR:
- Create an instance of the OcrScanner class.
- Recognize text from an image using OcrScanner.Scan() method.
- Get the recognized text from the OcrScanner object using the OcrScanner.Text property.
- Iterate through the text blocks of the recognized text.
- For each block, get its text and location information using IOCRTextBlock.Text and IOCRTextBlock.Box properties, then append the result to a string list.
- Save the content of the list to a text file.
Here is a code example that shows how to recognize text along with its location information from an image and save the result to a text file:
- C#
using Spire.OCR;
using System.Collections.Generic;
using System.IO;
namespace ReadTextFromImageWithCoordinates
{
internal class Program
{
static void Main(string[] args)
{
//Specify the path of the input image file
string imagePath = "Image.png";
//Specify the path of the output text file
string outputFile = "ScanImageWithCoordinates.txt";
//Call the ScanTextFromImageWithCoordinates method to extract text and its area information from the image
List<string> extractedText = ScanTextFromImageWithCoordinates(imagePath);
//Write the result to the specified file
File.WriteAllLines(outputFile, extractedText);
}
//Retrieve the text blocks along with their location information (x, y, width, height) from an image
public static List<string> ScanTextFromImageWithCoordinates(string imageFilePath)
{
//Create a list
List<string> extractedText = new List<string>();
//Instantiate an OcrScanner object
using (OcrScanner ocrScanner = new OcrScanner())
{
//Scan text from the image
ocrScanner.Scan(imageFilePath);
//Get the scanned text
IOCRText text = ocrScanner.Text;
//Iterate through each text block
foreach (IOCRTextBlock block in text.Blocks)
{
//Append the text of each block and its location information to the list
extractedText.Add($"Text: {block.Text}\nRectangular Area: {block.Box}");
}
}
return extractedText;
}
}
}
Extract Text from Scanned PDFs in C#
To extract text from scanned PDFs, we need to follow a two-step process. First, we use Spire.PDF to convert the scanned PDFs into images. Then, we utilize Spire.OCR to extract the text from those images.
Here are the main steps to recognize text from a scanned PDF using Spire.PDF and Spire.OCR:
- Create an instance of the PdfDocument class.
- Load a PDF document using PdfDocument.LoadFromFile() method.
- Iterate through the pages of the PDF document.
- Convert each page to an Image object using PdfDocument.SaveAsImage() method.
- Save the Image object to a stream using Image.Save() method.
- Create an instance of the OcrScanner class.
- Recognize text from the stream using OcrScanner.Scan() method.
- Get the recognized text using IOCRText.Text property and append it to a string list.
- Save the content of the list to a text file.
Here is a code example that shows how to recognize text from a scanned PDF and save the result to a text file:
- C#
using Spire.OCR;
using Spire.Pdf;
using System.Collections.Generic;
using System.Drawing;
using System.Drawing.Imaging;
using System.IO;
namespace ReadTextFromScannedPDF
{
internal class Program
{
static void Main(string[] args)
{
//Specify the path of the scanned PDF file
string pdfFilePath = "Sample.pdf";
//Specify the path of the output text file
string outputFilePath = "ScanPDF.txt";
//Extract text from the scanned PDF
List<string> extractedText = ExtractTextFromScannedPDF(pdfFilePath);
//Write the text to the specified file
File.WriteAllLines(outputFilePath, extractedText);
}
//Extract text from a scanned PDF
public static List<string> ExtractTextFromScannedPDF(string pdfFilePath)
{
//Create a list to store the extracted text
List<string> extractedText = new List<string>();
//Create an instance of the PdfDocument class
using (PdfDocument document = new PdfDocument())
{
//Load the PDF document
document.LoadFromFile(pdfFilePath);
//Iterate through each page of the document
for (int pageIndex = 0; pageIndex < document.Pages.Count; pageIndex++)
{
//Convert the page to an image
using (Image image = document.SaveAsImage(pageIndex, 300, 300))
{
//Create a memory stream to hold the image data
using (MemoryStream stream = new MemoryStream())
{
//Save the image to the memory stream in PNG format
image.Save(stream, ImageFormat.Png);
stream.Position = 0;
//Scan the text from the image and add it to the list
string text = ScanTextFromImageStream(stream);
extractedText.Add(text);
}
}
}
}
//Return the list
return extractedText;
}
//Scan text from an image stream
public static string ScanTextFromImageStream(Stream stream)
{
//Create an instance of the OcrScanner class
using (OcrScanner ocrScanner = new OcrScanner())
{
//Scan the text from the image stream in PNG format
ocrScanner.Scan(stream, OCRImageFormat.Png);
IOCRText text = ocrScanner.Text;
//Return the text
return text.ToString();
}
}
}
}
Get a Free License
To fully experience the capabilities of Spire.OCR for .NET or Spire.PDF for .NET without any evaluation limitations, you can request a free 30-day trial license.
Conclusion
This blog post demonstrated how to extract text from images and scanned PDF documents in C#. If you have any questions, please feel free to post them on our forum or send them to our support team via email.