Converting PDFs to HTML within a React application enables users to transform static documents into dynamic, accessible web content. This approach enhances responsiveness across devices, simplifies content updates, and integrates directly into web pages—eliminating the need for external PDF viewers. It preserves the original layout while leveraging web-native features such as state-driven UI updates. By merging the structure of PDFs with the flexibility of modern web interfaces, this method creates content that is both adaptable and user-friendly without compromising design integrity.
In this article, we explore how to use Spire.PDF for JavaScript to convert PDF files into HTML with JavaScript in a React application.
- Steps for Converting PDF to HTML Using JavaScript
- Convert a PDF Document to a Single HTML File
- Convert PDF to HTML Without Embedding Images
- Convert PDF to Separated HTML Files
- Optimize the Files Size of the Converted HTML File
Install and Configure Spire.PDF for JavaScript in Your React App
To begin converting PDFs to HTML in your React application, follow these steps:
1. Install via npm:
Run the following command in your project's root directory:
npm install spire.pdf
(Alternatively, you can download Spire.PDF for JavaScript from our website.)
2. Add the required files:
Copy the Spire.Pdf.Base.js and Spire.Pdf.Base.wasm files into your project's public folder. This ensures the WebAssembly module initializes correctly.
3. Include font files:
Place the necessary font files in the designated folder (e.g., /public/fonts) to ensure accurate and consistent text rendering.
For more details, please refer to our documentation: How to Integrate Spire.PDF for JavaScript in a React Project
Steps for Converting PDF to HTML Using JavaScript
Spire.PDF for JavaScript includes a WebAssembly module for processing PDF documents. By fetching PDFs into the virtual file system (VFS), developers can load them into a PdfDocument object and convert them into various formats such as HTML. The main steps are as follows:
- Load the Spire.Pdf.Base.js file to initialize the WebAssembly module.
- Fetch the PDF file to the VFS using the wasmModule.FetchFileToVFS() method.
- Fetch the font files used in the PDF document to the "/Library/Fonts/" folder in the VFS using the wasmModule.FetchFileToVFS() method.
- Create an instance of the PdfDocument class using the wasmModule.PdfDocument.Create() method.
- (Optional) Configure the conversion options using the PdfDocument.ConvertOptions.SetPdfToHtmlOptions() method.
- Convert the PDF document to HTML format and save it to the VFS using the PdfDocument.SaveToFile() method.
- Read and download the HTML file or use it as needed.
When configuring conversion options using the PdfDocument.ConvertOptions.SetPdfToHtmlOptions() method, the following parameters can be set:
| Parameter | Description |
| useEmbeddedSvg: bool | Embeds SVGs in the resulting HTML file. |
| useEmbeddedImg: bool | Embeds images as SVGs in the resulting HTML file (requires useEmbeddedSvg to be true). |
| maxPageOneFile: int | Specifies the maximum number of PDF pages contained in one HTML file (effective when useEmbeddedSvg is true). |
| useHighQualityEmbeddedSvg: bool | Embeds high-quality SVGs in the HTML file. This affects both image quality and file size (effective when useEmbeddedSvg is true). |
Convert a PDF Document to a Single HTML File
By embedding SVGs and images and setting the maximum pages per file to the total page count of the PDF or to 0, developers can convert an entire PDF document into a single HTML file. Alternatively, developers can convert the PDF without configuring any options, which results in all elements being embedded in the HTML file with high-quality SVGs.
Below is a code example demonstrating how to convert a PDF document to a single HTML file using Spire.PDF for JavaScript:
- JavaScript
import React, { useState, useEffect } from 'react';
import JSZip from 'jszip';
function App() {
// State to store the loaded WASM module
const [wasmModule, setWasmModule] = useState(null);
// useEffect hook to load the WASM module when the component mounts
useEffect(() => {
const loadWasm = async () => {
try {
// Access the Module and spirepdf from the global window object
const { Module, spirepdf } = window;
// Set the wasmModule state when the runtime is initialized
Module.onRuntimeInitialized = () => {
setWasmModule(spirepdf);
};
} catch (err) {
// Log any errors that occur during module loading
console.error('Failed to load the WASM module:', err);
}
};
// Create a script element to load the WASM JavaScript file
const script = document.createElement('script');
script.src = `${process.env.PUBLIC_URL}/Spire.Pdf.Base.js`;
script.onload = loadWasm;
// Append the script to the document body
document.body.appendChild(script);
// Cleanup function to remove the script when the component unmounts
return () => {
document.body.removeChild(script);
};
}, []);
// Function to convert PDF to HTML
const ConvertPDFToHTML = async () => {
if (wasmModule) {
// Specify the input and output file names
const inputFileName = 'Sample.pdf';
const outputFileName = 'PDFToHTML.html';
// Fetch the input file and add it to the VFS
await wasmModule.FetchFileToVFS(inputFileName, '', `${process.env.PUBLIC_URL}/`);
// Fetch the font file used in the PDF to the VFS
await wasmModule.FetchFileToVFS('Calibri.ttf', '/Library/Fonts/', `${process.env.PUBLIC_URL}/`);
await wasmModule.FetchFileToVFS('CalibriBold.ttf', '/Library/Fonts/', `${process.env.PUBLIC_URL}/`);
// Create an instance of the PdfDocument class
const pdf = wasmModule.PdfDocument.Create();
// Load the PDF document from the VFS
pdf.LoadFromFile(inputFileName);
// Convert the PDF document to an HTML file
pdf.SaveToFile({ fileName: outputFileName, fileFormat: wasmModule.FileFormat.HTML});
// Set the conversion options (optional)
pdf.ConvertOptions.SetPdfToHtmlOptions({ useEmbeddedSvg: true, useEmbeddedImg: true, maxPageOneFile: pdf.Pages.Count, useHighQualityEmbeddedSvg: true})
// Read the HTML file from the VFS
const htmlArray = wasmModule.FS.readFile(outputFileName)
// Create a Blob from the HTML file and download it
const blob = new Blob([htmlArray], { type: 'text/html' });
const url = URL.createObjectURL(blob);
const link = document.createElement('a');
link.href = url;
link.download = outputFileName;
link.click();
}
};
return (
<div style={{ textAlign: 'center', height: '300px' }}>
<h1>Convert PDF to HTML Using JavaScript in React</h1>
<button onClick={ConvertPDFToHTML} disabled={!wasmModule}>
Convert and Download
</button>
</div>
);
}
export default App;
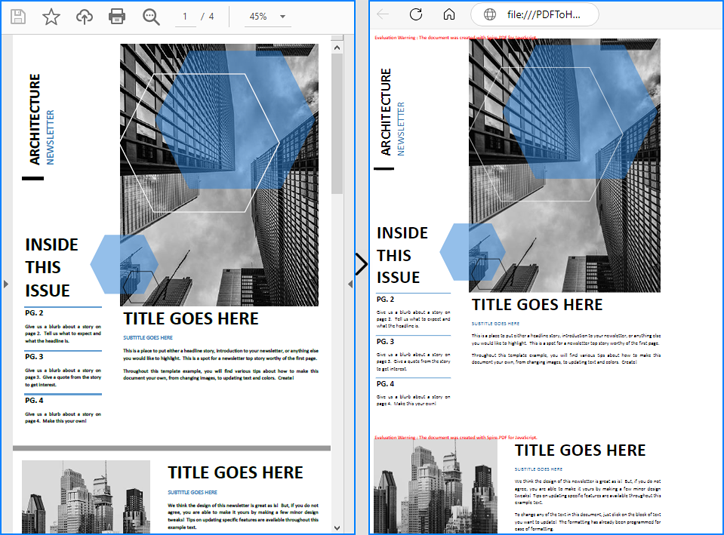
Convert PDF to HTML Without Embedding Images
To separate the HTML body from images for easier individual editing, developers can convert PDFs to HTML without embedding images and SVGs. This requires setting the useEmbeddedSvg and useEmbeddedImg parameters to false.
Below is a code example demonstrating this conversion and its result:
- JavaScript
import React, { useState, useEffect } from 'react';
import JSZip from 'jszip';
function App() {
// State to store the loaded WASM module
const [wasmModule, setWasmModule] = useState(null);
// useEffect hook to load the WASM module when the component mounts
useEffect(() => {
const loadWasm = async () => {
try {
// Access the Module and spirepdf from the global window object
const { Module, spirepdf } = window;
// Set the wasmModule state when the runtime is initialized
Module.onRuntimeInitialized = () => {
setWasmModule(spirepdf);
};
} catch (err) {
// Log any errors that occur during module loading
console.error('Failed to load the WASM module:', err);
}
};
// Create a script element to load the WASM JavaScript file
const script = document.createElement('script');
script.src = `${process.env.PUBLIC_URL}/Spire.Pdf.Base.js`;
script.onload = loadWasm;
// Append the script to the document body
document.body.appendChild(script);
// Cleanup function to remove the script when the component unmounts
return () => {
document.body.removeChild(script);
};
}, []);
// Function to convert PDF to HTML
const ConvertPDFToHTML = async () => {
if (wasmModule) {
// Specify the input and output file names
const inputFileName = 'Sample.pdf';
const outputFileName = '/output/PDFToHTML.html';
// Fetch the input file and add it to the VFS
await wasmModule.FetchFileToVFS(inputFileName, '', `${process.env.PUBLIC_URL}/`);
// Fetch the font file used in the PDF to the VFS
await wasmModule.FetchFileToVFS('Calibri.ttf', '/Library/Fonts/', `${process.env.PUBLIC_URL}/`);
await wasmModule.FetchFileToVFS('CalibriBold.ttf', '/Library/Fonts/', `${process.env.PUBLIC_URL}/`);
// Create an instance of the PdfDocument class
const pdf = wasmModule.PdfDocument.Create();
// Load the PDF document from the VFS
pdf.LoadFromFile(inputFileName);
// Set the conversion options to disable SVG and image embedding
pdf.ConvertOptions.SetPdfToHtmlOptions({ useEmbeddedSvg: false, useEmbeddedImg: false})
// Convert the PDF document to an HTML file
pdf.SaveToFile({ fileName: outputFileName, fileFormat: wasmModule.FileFormat.HTML});
// Create a new JSZip object
const zip = new JSZip();
// Recursive function to add a directory and its contents to the ZIP
const addFilesToZip = (folderPath, zipFolder) => {
const items = wasmModule.FS.readdir(folderPath);
items.filter(item => item !== "." && item !== "..").forEach((item) => {
const itemPath = `${folderPath}/${item}`;
try {
// Attempt to read file data
const fileData = wasmModule.FS.readFile(itemPath);
zipFolder.file(item, fileData);
} catch (error) {
if (error.code === 'EISDIR') {
// If it's a directory, create a new folder in the ZIP and recurse into it
const zipSubFolder = zipFolder.folder(item);
addFilesToZip(itemPath, zipSubFolder);
} else {
// Handle other errors
console.error(`Error processing ${itemPath}:`, error);
}
}
});
};
// Add all files in the output folder to the ZIP
addFilesToZip('/output', zip);
// Generate and download the ZIP file
zip.generateAsync({ type: 'blob' }).then((content) => {
const url = URL.createObjectURL(content);
const a = document.createElement('a');
a.href = url;
a.download = `PDFToHTML.zip`;
document.body.appendChild(a);
a.click();
document.body.removeChild(a);
URL.revokeObjectURL(url);
});
}
};
return (
<div style={{ textAlign: 'center', height: '300px' }}>
<h1>Convert PDF to HTML Without Embedding Images Using JavaScript in React</h1>
<button onClick={ConvertPDFToHTML} disabled={!wasmModule}>
Convert and Download
</button>
</div>
);
}
export default App;

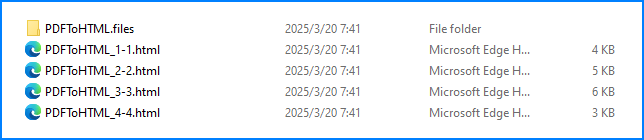
Convert PDF to Separated HTML Files
Instead of converting all PDF pages into a single HTML file, developers can set the maxPageOneFile parameter to generate multiple HTML files, each containing a limited number of pages. For this to work, useEmbeddedSvg and useEmbeddedImg must be set to true.
The following is a code example demonstrating this conversion and its effect:
- JavaScript
import React, { useState, useEffect } from 'react';
import JSZip from 'jszip';
function App() {
// State to store the loaded WASM module
const [wasmModule, setWasmModule] = useState(null);
// useEffect hook to load the WASM module when the component mounts
useEffect(() => {
const loadWasm = async () => {
try {
// Access the Module and spirepdf from the global window object
const { Module, spirepdf } = window;
// Set the wasmModule state when the runtime is initialized
Module.onRuntimeInitialized = () => {
setWasmModule(spirepdf);
};
} catch (err) {
// Log any errors that occur during module loading
console.error('Failed to load the WASM module:', err);
}
};
// Create a script element to load the WASM JavaScript file
const script = document.createElement('script');
script.src = `${process.env.PUBLIC_URL}/Spire.Pdf.Base.js`;
script.onload = loadWasm;
// Append the script to the document body
document.body.appendChild(script);
// Cleanup function to remove the script when the component unmounts
return () => {
document.body.removeChild(script);
};
}, []);
// Function to convert PDF to HTML
const ConvertPDFToHTML = async () => {
if (wasmModule) {
// Specify the input and output file names
const inputFileName = 'Sample.pdf';
const outputFileName = '/output/PDFToHTML.html';
// Fetch the input file and add it to the VFS
await wasmModule.FetchFileToVFS(inputFileName, '', `${process.env.PUBLIC_URL}/`);
// Fetch the font file used in the PDF to the VFS
await wasmModule.FetchFileToVFS('Calibri.ttf', '/Library/Fonts/', `${process.env.PUBLIC_URL}/`);
await wasmModule.FetchFileToVFS('CalibriBold.ttf', '/Library/Fonts/', `${process.env.PUBLIC_URL}/`);
// Create an instance of the PdfDocument class
const pdf = wasmModule.PdfDocument.Create();
// Load the PDF document from the VFS
pdf.LoadFromFile(inputFileName);
// Set the conversion options to disable SVG and image embedding
pdf.ConvertOptions.SetPdfToHtmlOptions({ useEmbeddedSvg: false, useEmbeddedImg: false, maxPageOneFile: 1 })
// Convert the PDF document to an HTML file
pdf.SaveToFile({ fileName: outputFileName, fileFormat: wasmModule.FileFormat.HTML});
// Create a new JSZip object
const zip = new JSZip();
// Recursive function to add a directory and its contents to the ZIP
const addFilesToZip = (folderPath, zipFolder) => {
const items = wasmModule.FS.readdir(folderPath);
items.filter(item => item !== "." && item !== "..").forEach((item) => {
const itemPath = `${folderPath}/${item}`;
try {
// Attempt to read file data
const fileData = wasmModule.FS.readFile(itemPath);
zipFolder.file(item, fileData);
} catch (error) {
if (error.code === 'EISDIR') {
// If it's a directory, create a new folder in the ZIP and recurse into it
const zipSubFolder = zipFolder.folder(item);
addFilesToZip(itemPath, zipSubFolder);
} else {
// Handle other errors
console.error(`Error processing ${itemPath}:`, error);
}
}
});
};
// Add all files in the output folder to the ZIP
addFilesToZip('/output', zip);
// Generate and download the ZIP file
zip.generateAsync({ type: 'blob' }).then((content) => {
const url = URL.createObjectURL(content);
const a = document.createElement('a');
a.href = url;
a.download = `PDFToHTML.zip`;
document.body.appendChild(a);
a.click();
document.body.removeChild(a);
URL.revokeObjectURL(url);
});
}
};
return (
<div style={{ textAlign: 'center', height: '300px' }}>
<h1>Convert PDF to HTML Without Embedding Images Using JavaScript in React
Convert and Download
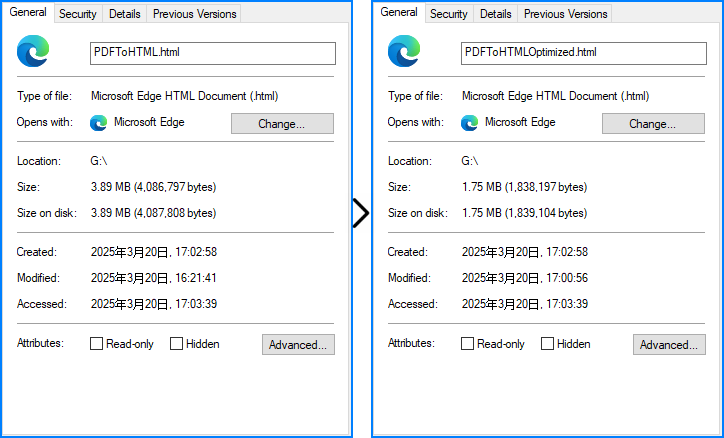
Optimize the Files Size of the Converted HTML File
When embedding SVGs in the converted HTML file, developers can optimize file size by lowering the quality of embedded SVGs using the useHighQualityEmbeddedSvg parameter. Note that this parameter only affects embedded SVGs.
The following is a code example demonstrating this optimization and its effect:
- JavaScript
import React, { useState, useEffect } from 'react';
function App() {
// State to store the loaded WASM module
const [wasmModule, setWasmModule] = useState(null);
// useEffect hook to load the WASM module when the component mounts
useEffect(() => {
const loadWasm = async () => {
try {
// Access the Module and spirepdf from the global window object
const { Module, spirepdf } = window;
// Set the wasmModule state when the runtime is initialized
Module.onRuntimeInitialized = () => {
setWasmModule(spirepdf);
};
} catch (err) {
// Log any errors that occur during module loading
console.error('Failed to load the WASM module:', err);
}
};
// Create a script element to load the WASM JavaScript file
const script = document.createElement('script');
script.src = `${process.env.PUBLIC_URL}/Spire.Pdf.Base.js`;
script.onload = loadWasm;
// Append the script to the document body
document.body.appendChild(script);
// Cleanup function to remove the script when the component unmounts
return () => {
document.body.removeChild(script);
};
}, []);
// Function to convert PDF to HTML
const ConvertPDFToHTML = async () => {
if (wasmModule) {
// Specify the input and output file names
const inputFileName = 'Sample.pdf';
const outputFileName = 'PDFToHTML.html';
// Fetch the input file and add it to the VFS
await wasmModule.FetchFileToVFS(inputFileName, '', `${process.env.PUBLIC_URL}/`);
// Fetch the font file used in the PDF to the VFS
await wasmModule.FetchFileToVFS('Calibri.ttf', '/Library/Fonts/', `${process.env.PUBLIC_URL}/`);
await wasmModule.FetchFileToVFS('CalibriBold.ttf', '/Library/Fonts/', `${process.env.PUBLIC_URL}/`);
// Create an instance of the PdfDocument class
const pdf = wasmModule.PdfDocument.Create();
// Load the PDF document from the VFS
pdf.LoadFromFile(inputFileName);
// Set the conversion options to convert with lower quality embedded SVG
pdf.ConvertOptions.SetPdfToHtmlOptions({ useEmbeddedSvg: true, useEmbeddedImg: true, maxPageOneFile: 0, useHighQualityEmbeddedSvg: false })
// Convert the PDF document to an HTML file
pdf.SaveToFile({ fileName: outputFileName, fileFormat: wasmModule.FileFormat.HTML});
// Read the HTML file from the VFS
const htmlArray = wasmModule.FS.readFile(outputFileName)
// Create a Blob from the HTML file and download it
const blob = new Blob([htmlArray], { type: 'text/html' });
const url = URL.createObjectURL(blob);
const link = document.createElement('a');
link.href = url;
link.download = outputFileName;
link.click();
}
};
return (
<div style={{ textAlign: 'center', height: '300px' }}>
<h1>Convert PDF to HTML Optimize File Size Using JavaScript in React</h1>
<button onClick={ConvertPDFToHTML} disabled={!wasmModule}>
Convert and Download
</button>
</div>
);
}
export default App;
Request a Free License
Spire.PDF for JavaScript offers a free trial license for both enterprise and individual users. You can apply for a temporary license to convert PDF documents to HTML without any usage restrictions or watermarks.
If you encounter issues during conversion, technical support is available on the Spire.PDF forum.
Conclusion
Converting PDFs to HTML in your React app with Spire.PDF for JavaScript transforms static documents into dynamic, accessible web content. With a simple npm installation, proper setup of the JavaScript, WASM, and font files, and multiple conversion options—including single-file output, separated pages, and non-embedded images—you can preserve layout fidelity while unlocking modern web features like state-driven UI updates.
For advanced customization, be sure to check the documentation.