Download PDF from URL Using Python: Complete Guide

Downloading PDF files from URLs programmatically is essential for developers building document processing systems, web scrapers, content aggregators, or automated report generators. Automating PDF download and processing improves workflow efficiency, allowing developers to extract information, archive documents, or perform analysis without manual intervention.
In this guide, we demonstrate how to download PDFs from URLs using Python with Spire.PDF, process them entirely in memory, handle network errors, manage large files, and troubleshoot common issues.
Quick Navigation:
- Why Use Spire.PDF for Python
- Install Required Libraries
- Download PDF from URL
- Processing PDFs Without Saving
- Handling Large PDFs
- Adding Retry Logic
- Common Issues and Troubleshooting
- Conclusion
- FAQs
1. Why Use Spire.PDF for Python
Spire.PDF for Python enables loading PDFs directly from memory, without needing a disk path. This makes in-memory processing fast and avoids unnecessary disk I/O.
Key capabilities include:
- Load PDFs from bytes or Stream objects
- Extract text, images, and metadata
- Modify PDFs and convert to other formats
- Efficiently handle large files in memory
These capabilities are particularly useful in web scraping pipelines, document archiving systems, automated report generation, and content extraction workflows, where performance and memory efficiency are important.
2. Install Required Libraries
Install Spire.PDF and requests via pip:
pip install spire.pdf requests
Import the necessary modules:
from spire.pdf import *
import requests
3. Download PDF from URL
Here’s a complete example showing how to download a PDF from a URL, process it in memory, and save it to disk. Each line includes explanations for clarity.
import requests
from spire.pdf import *
def download_pdf_from_url():
# Specify the PDF URL
url = "resource/sample.pdf"
# Send HTTP GET request to download the PDF
response = requests.get(url)
# Raise an error if the request failed (4xx or 5xx)
response.raise_for_status()
# Create a Stream object from the downloaded bytes
stream = Stream(response.content)
# Load PDF from Stream
document = PdfDocument(stream)
# Save PDF to local file
document.SaveToFile("Downloaded.pdf")
document.Close()
print("PDF downloaded and saved successfully!")
if __name__ == "__main__":
download_pdf_from_url()
Output:
Explanation of key components:
requests.get(url)– Sends the HTTP GET request. The server responds with headers and the PDF binary.response.raise_for_status()– Checks for HTTP errors (e.g., 404, 500).response.content– Contains raw PDF bytes.Stream(response.content)– Wraps bytes in a readable, seekable in-memory stream.PdfDocument(stream)– Loads the PDF into memory for further operations.document.SaveToFile()– writes the PDF to disk.
This workflow loads PDF data into memory for instant saving, improving speed and avoiding unnecessary disk writes.
4. Processing PDFs Without Saving
You can extract metadata or text directly in memory without writing files:
def process_pdf_from_url():
url = "resource/sample.pdf"
response = requests.get(url)
response.raise_for_status()
# Load PDF in memory
document = PdfDocument(Stream(response.content))
# Retrieve document information
print(f"Number of pages: {document.Pages.Count}")
info = document.DocumentInformation
print(f"Title: {info.Title}")
print(f"Author: {info.Author}")
# Extract text from the first page
from spire.pdf import PdfTextExtractor
extractor = PdfTextExtractor(document.Pages[0])
text = extractor.ExtractText()
print(f"First 100 characters: {text[:100]}")
document.Close()
if __name__ == "__main__":
process_pdf_from_url()
Why this is useful: You can analyze content, index text, or extract metadata without creating unnecessary files on disk. This is ideal for server-side scripts, cloud functions, or batch processing.
5. Handling Large PDFs
Downloading very large PDFs (e.g., 100MB+) can consume significant memory. Use streaming download and temporary files to reduce memory usage:
import tempfile
import os
def download_large_pdf(url: str, output_path: str):
try:
response = requests.get(url, stream=True, timeout=60)
response.raise_for_status()
# Write chunks to a temporary file
with tempfile.NamedTemporaryFile(delete=False, suffix=".pdf") as tmp:
for chunk in response.iter_content(chunk_size=8192):
if chunk:
tmp.write(chunk)
temp_path = tmp.name
# Load PDF from temporary file
document = PdfDocument()
document.LoadFromFile(temp_path)
document.SaveToFile(output_path)
document.Close()
# Clean up temporary file
os.unlink(temp_path)
print(f"Large PDF saved to: {output_path}")
except Exception as e:
print(f"Error: {e}")
Notes:
stream=Trueavoids loading the entire file into memory.- Temporary files allow processing PDFs that exceed available RAM.
6. Adding Retry Logic
Network requests may fail intermittently. Adding retries improves robustness:
import time
def download_with_retry(url: str, output_path: str, max_retries: int = 3):
for attempt in range(max_retries):
try:
response = requests.get(url, timeout=30)
response.raise_for_status()
document = PdfDocument(Stream(response.content))
document.SaveToFile(output_path)
document.Close()
print(f"Downloaded successfully: {output_path}")
return True
except requests.exceptions.RequestException as e:
print(f"Attempt {attempt + 1} failed: {e}")
if attempt < max_retries - 1:
wait_time = 2 ** attempt
print(f"Retrying in {wait_time} seconds...")
time.sleep(wait_time)
print("All retry attempts failed.")
return False
Why use this: Exponential backoff prevents overwhelming servers and handles transient network failures gracefully.
7. Common Issues and Troubleshooting
PDF Not Found (404)
Problem: The URL does not point to a valid PDF, resulting in a 404 error.
Solution: Verify the URL and add a User-Agent header if needed:
import requests
url = "https://example.com/missing.pdf"
headers = {'User-Agent': 'Mozilla/5.0'}
response = requests.get(url, headers=headers)
if response.status_code == 404:
print("PDF not found (404)")
Server Returns HTML Instead of PDF
Problem: The URL returns an HTML page instead of a PDF.
Solution: Check the Content-Type and parse HTML to locate the actual PDF:
import requests
from bs4 import BeautifulSoup
url = "https://example.com/download-page"
response = requests.get(url)
content_type = response.headers.get('Content-Type', '')
if 'application/pdf' not in content_type and 'text/html' in content_type:
soup = BeautifulSoup(response.text, 'html.parser')
for link in soup.find_all('a', href=True):
if link['href'].endswith('.pdf'):
print(f"Found PDF link: {link['href']}")
# Download the actual PDF URL
Extracted Text Shows Garbled Characters
Problem: Text extraction returns unreadable characters, often due to encoding or scanned PDFs.
Solution: Ensure proper handling or use OCR for scanned PDFs:
from spire.pdf import PdfDocument, PdfTextExtractor
document = PdfDocument("example.pdf")
extractor = PdfTextExtractor(document.Pages[0])
text = extractor.ExtractText()
print(text[:200])
# If text is still garbled, the PDF may be image-based; consider OCR
PDF Loads But Has No Pages
Problem: document.Pages.Count returns 0 even though the file exists.
Solution: PDF may be corrupted or password-protected:
from spire.pdf import PdfDocument, Stream
with open("protected.pdf", "rb") as f:
pdf_bytes = f.read()
# For password-protected PDF
document = PdfDocument(Stream(pdf_bytes), "password")
print(f"Pages: {document.Pages.Count}")
8. Conclusion
In this article, we demonstrated how to download PDF files from URLs in Python using Spire.PDF for Python. By leveraging the Stream class, developers can load PDF data directly from memory without unnecessary disk I/O, enabling efficient document processing pipelines.
We covered the complete workflow: downloading PDF data with the requests library, creating Stream objects from bytes, loading PdfDocument instances, handling network errors, managing large files, and troubleshooting common issues. The production-ready code examples provide a solid foundation for building robust PDF download and processing systems.
To fully experience the capabilities of Spire.PDF for Python without any evaluation limitations, you can request a free 30-day trial license.
9. FAQs
Q1. How do I download a PDF from a URL using Python?
Use the requests library to fetch the PDF data and Spire.PDF to load it from memory:
response = requests.get(url)
stream = Stream(response.content)
document = PdfDocument(stream)
Q2. How do I handle authentication-protected PDFs?
For basic authentication, use the auth parameter:
response = requests.get(url, auth=('username', 'password'))
For token-based authentication, add headers:
headers = {'Authorization': 'Bearer YOUR_TOKEN'}
response = requests.get(url, headers=headers)
Q3. What's the maximum PDF file size I can download?
The theoretical limit depends on your system's available memory. For files larger than 200MB, use the streaming approach with a temporary file instead of loading everything into memory.
Q4. Can I download multiple PDFs in parallel?
Yes. Use concurrent.futures or asyncio to download multiple PDFs simultaneously for better performance.
from concurrent.futures import ThreadPoolExecutor
urls = ["url1.pdf", "url2.pdf", "url3.pdf"]
with ThreadPoolExecutor(max_workers=5) as executor:
executor.map(lambda u: download_pdf(u), urls)
How to Read PDF Files in Python – Text, Tables, Images, and More

Reading PDF files using Python is essential for tasks like document automation, content analysis, and data scraping. Whether you're working with contracts, reports, invoices, or scientific papers, being able to programmatically access PDF content saves time and enables powerful workflows.
To reliably read PDF content in Python — including text, tables, images, and metadata — you need a reliable Python PDF reader. In this guide, we’ll show you how to read PDFs in Python using Spire.PDF for Python, a professional and easy-to-use library that supports full-featured PDF reading without relying on any third-party tools.
Here's what's covered:
- Preparing Your Environment
- Load a PDF File in Python
- Read Text from PDF Pages in Python
- Read Table Data from PDFs in Python
- Read Images from PDFs in Python
- Read PDF Metadata (Title, Author, etc.)
- Common Questions on Reading PDFs
Environment Setup for Reading PDFs in Python
Spire.PDF for Python is a powerful Python PDF reader that allows users to read PDF content with simple Python code, including text, tables, images, and metadata. It offers a developer-friendly interface and supports a wide range of PDF reading operations:
- Read PDF files from disk or memory
- Access text, tables, metadata, and images
- No need for third-party tools
- High accuracy for structured data reading
- Free version available
It’s suitable for developers who want to read and process PDFs with minimal setup.
You can install Spire.PDF for Python via pip:
pip install spire.pdf
Or the free version Free Spire.PDF for Python for small tasks:
pip install spire.pdf.free
Load a PDF File in Python
Before accessing content, the first step is to load the PDF into memory. Spire.PDF lets you read PDF files from a path on disk or directly from in-memory byte streams — ideal for reading from web uploads or APIs.
Read PDF from File Path
To begin reading a PDF in Python, load the file using PdfDocument.LoadFromFile(). This creates a document object you can use to access content.
from spire.pdf import PdfDocument
# Create a PdfDocument instance
pdf = PdfDocument()
# Load a PDF document
pdf.LoadFromFile("sample.pdf")
Read PDF from Bytes (In-Memory)
To read a PDF file from memory without saving it to disk, you can first load its byte content and then initialize a PdfDocument using a Stream object. This method is especially useful when handling PDF files received from web uploads, APIs, or temporary in-memory data.
from spire.pdf import PdfDocument, Stream
# Read the PDF file to a byte array
with open("sample.pdf", "rb") as f:
byte_data = f.read()
# Create a stream using the byte array
pdfStream = Stream(byte_data)
# Create a PdfDocument using the stream
pdf = PdfDocument(pdfStream)
To go further, check out this guide: Loading and Saving PDFs via Byte Streams in Python
Read Text from PDF Pages in Python
Reading text from a PDF file is one of the most common use cases in document automation. With Spire.PDF, you can easily retrieve all visible text from the entire PDF or from individual pages using simple methods.
Read All Text from PDF
To extract all text from a PDF, loop through each page and call PdfTextExtractor.ExtractText() to collect visible text content.
from spire.pdf import PdfDocument, PdfTextExtractor, PdfTextExtractOptions
# Create a PdfDocument instance
pdf = PdfDocument()
# Load a PDF document
pdf.LoadFromFile("sample.pdf")
all_text = ""
# Loop through each page
for pageIndex in range(pdf.Pages.Count):
page = pdf.Pages.get_Item(pageIndex)
# Create a PdfTextExtract instance
text_extractor = PdfTextExtractor(page)
# Configure extracting options
options = PdfTextExtractOptions()
options.IsExtractAllText = True
options.IsSimpleExtraction = True
# Extract text from the current page
all_text += text_extractor.ExtractText(options)
print(all_text)
Sample text content retrieved:

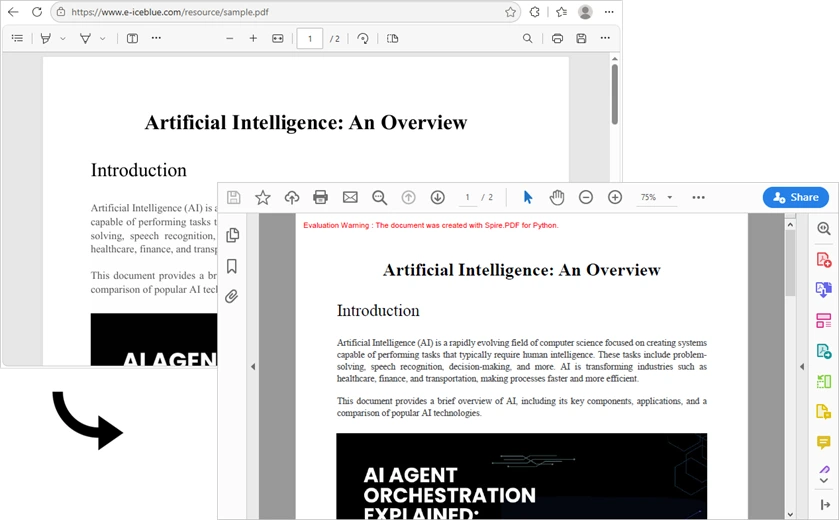
Read Text from Specific Area of a Page
You can also read text from a defined region of a page using a bounding box. This is useful when only a portion of the layout contains relevant information.
from spire.pdf import RectangleF, PdfDocument, PdfTextExtractor, PdfTextExtractOptions
# Load the PDF file
pdf = PdfDocument()
pdf.LoadFromFile("sample.pdf")
# Get the first page
page = pdf.Pages.get_Item(0)
# Create a PdfTextExtractor instance
textExtractor = PdfTextExtractor(page)
# Set the area to extract text by configuring the PdfTextExtractOptions
options = PdfTextExtractOptions()
area = RectangleF.FromLTRB(0, 200, page.Size.Width, 270) # x, y, width, height
options.ExtractArea = area
options.IsSimpleExtraction = True
# Extract text from the area
text = textExtractor.ExtractText(options)
print(text)
The text read from the PDF page area:
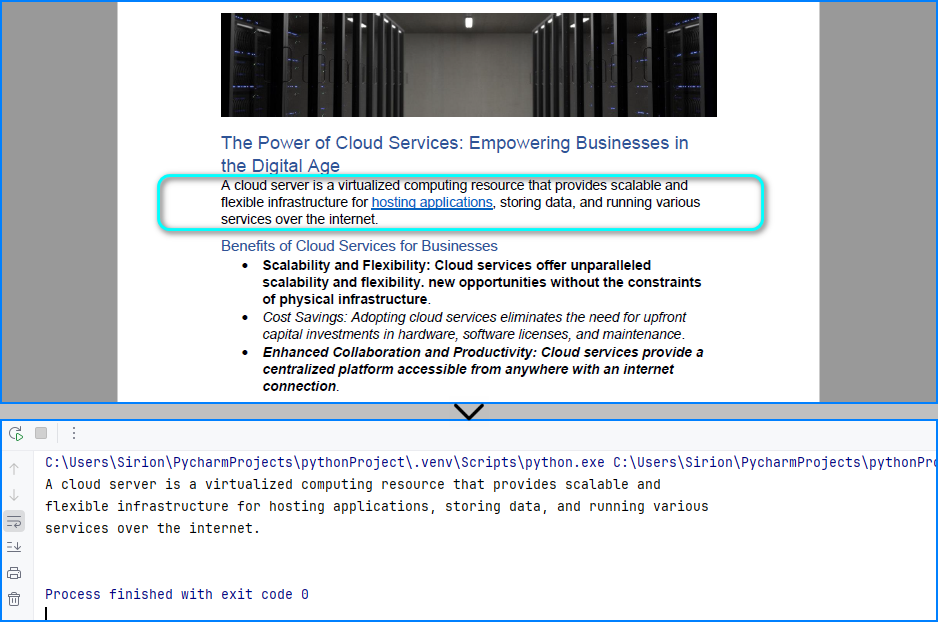
Read Table Data from PDFs in Python
PDF tables are often used in reports, invoices, and statements. With Spire.PDF, you can read PDF tables in Python by extracting structured tabular content using its layout-aware table extractor, making it ideal for financial and business documents. Use PdfTableExtractor.ExtractTable() to detect tables page by page and output each row and cell as structured text.
from spire.pdf import PdfDocument, PdfTableExtractor
# Load the PDF file
pdf = PdfDocument()
pdf.LoadFromFile("sample.pdf")
# Create a PdfTableExtractor instance
table_extractor = PdfTableExtractor(pdf)
# Extract the table from the first page
tables = table_extractor.ExtractTable(0)
for table in tables:
# Get the number of rows and columns
row_count = table.GetRowCount()
column_count = table.GetColumnCount()
# Iterate all rows
for i in range(row_count):
table_row = []
# Iterate all columns
for j in range(column_count):
# Get the cell
cell_text = table.GetText(i, j)
table_row.append(cell_text)
print(table_row)
Table content extracted using the code above:
Want to extract text from scanned PDFs using OCR? Read this guide on OCR with Python
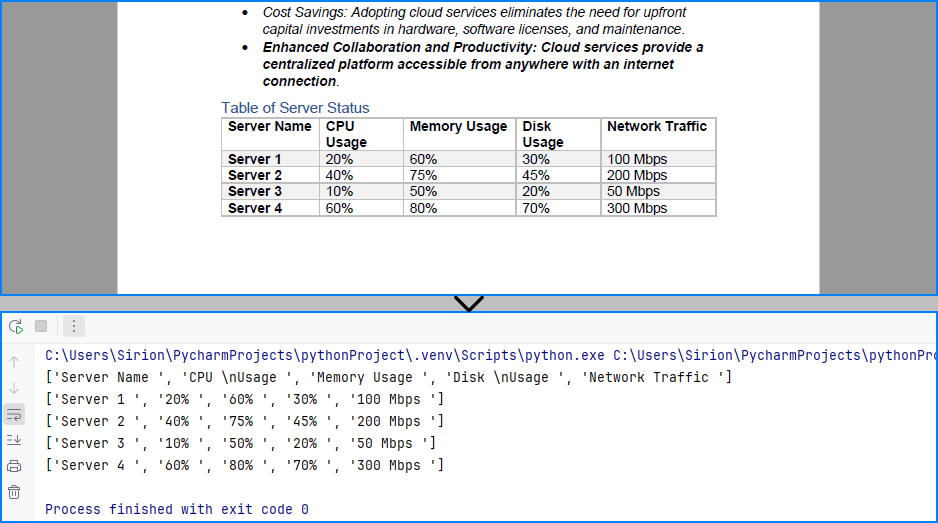
Read Images from PDF in Python
PDF files often contain logos, scanned pages, or embedded images. Spire.PDF allows you to read and export these images, which is helpful for working with digitized documents or preserving visual content. Use PdfImageHelper.GetImagesInfo() on each page to retrieve and save all embedded images.
from spire.pdf import PdfDocument, PdfImageHelper
# Load the PDF file
pdf = PdfDocument()
pdf.LoadFromFile("sample.pdf")
# Get the first page
page = pdf.Pages.get_Item(0)
# Create a PdfImageHelper object
image_helper = PdfImageHelper()
# Get the image information from the page
images_info = image_helper.GetImagesInfo(page)
# Save the images from the page as image files
for i in range(len(images_info)):
images_info[i].Image.Save("output/Images/image" + str(i) + ".png")
The image read from the PDF file:
Read PDF Metadata (Title, Author, etc.)
Sometimes you may want to access document metadata like author, subject, and title. This can be helpful for indexing or organizing files. Use the ocumentInformation property to read metadata fields.
from spire.pdf import PdfDocument
# Load the PDF file
pdf = PdfDocument()
pdf.LoadFromFile("sample.pdf")
# Get the document properties
properties = pdf.DocumentInformation
print("Title: " + properties.Title)
print("Author: " + properties.Author)
print("Subject: " + properties.Subject)
print("Keywords: " + properties.Keywords)
The metadata read from the PDF document:

Common Questions on Reading PDFs
Can Python parse a PDF file?
Yes. Libraries like Spire.PDF for Python allow you to read PDF text, extract tables, and access embedded images or metadata. It supports methods like PdfTextExtractor.ExtractText() and PdfTableExtractor.ExtractTable() for structured content parsing.
How do I read a PDF in Jupyter?
Spire.PDF works seamlessly in Jupyter Notebooks. Just install it via pip and use its API to read PDF files, extract text, or parse tables and images directly in your notebook environment.
How to read text from a PDF file?
Use the PdfTextExtractor.ExtractText() method on each page after loading the PDF with Spire.PDF. This lets you read PDF file to text in Python and retrieve visible content for processing or analysis.
Can I read a PDF file without saving it to disk?
Yes. You can use LoadFromStream() to read PDF content as bytes and load it directly from memory. This is useful for processing PDFs received from web APIs or file uploads.
Conclusion
With Spire.PDF for Python, you can easily read a PDF in Python — including reading PDF text, tables, images, and metadata — and even read a PDF file to text for further processing or automation. This makes it an ideal solution for document automation, data ingestion, and content parsing in Python.
Need to process large PDF files or unlock all features? Request a free license and take full advantage of Spire.PDF for Python today!
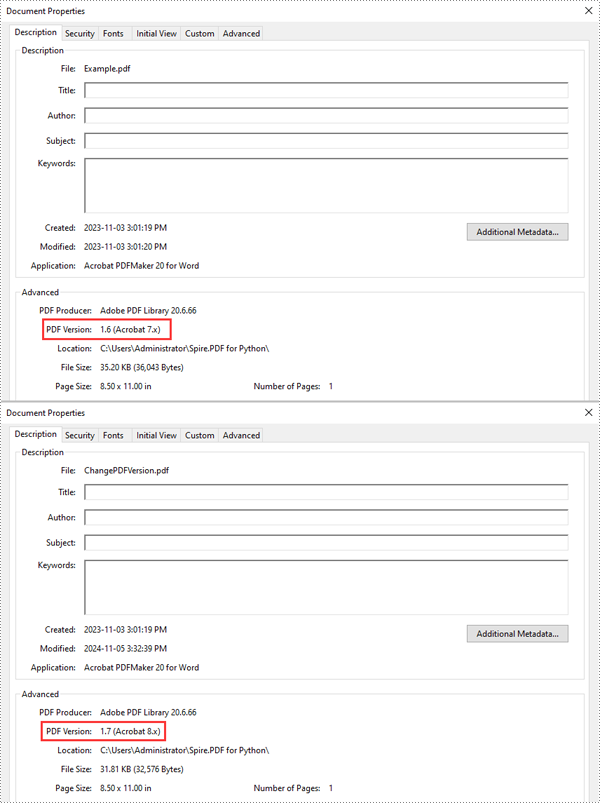
Python: Change PDF Version
PDF files have different versions, each with unique features and compatibility standards. Changing the version of a PDF can be important when specific versions are required for compatibility with certain devices, software, or regulatory requirements. For instance, you may need to use an older PDF version when archiving or sharing files with users using older software. This article will introduce how to change the version of a PDF document in Python using Spire.PDF for Python.
Install Spire.PDF for Python
This scenario requires Spire.PDF for Python and plum-dispatch v1.7.4. They can be easily installed in your Windows through the following pip command.
pip install Spire.PDF
If you are unsure how to install, please refer to this tutorial: How to Install Spire.PDF for Python on Windows
Change PDF Version in Python
Spire.PDF for Python supports PDF versions ranging from 1.0 to 1.7. To convert a PDF file to a different version, simply set the desired version using the PdfDocument.FileInfo.Version property. The detailed steps are as follows.
- Create an object of the PdfDocument class.
- Load a sample PDF document using the PdfDocument.LoadFromFile() method.
- Change the version of the PDF document to a newer or older version using the PdfDocument.FileInfo.Version property.
- Save the resulting document using the PdfDocument.SaveToFile() method.
- Python
from spire.pdf.common import *
from spire.pdf import *
# Create an object of the PdfDocument class
pdf = PdfDocument()
# Load a PDF document
pdf.LoadFromFile("Example.pdf")
# Change the version of the PDF to version 1.7
pdf.FileInfo.Version = PdfVersion.Version1_7
# Save the resulting document
pdf.SaveToFile("ChangePDFVersion.pdf")
pdf.Close()
Apply for a Temporary License
If you'd like to remove the evaluation message from the generated documents, or to get rid of the function limitations, please request a 30-day trial license for yourself.
Python: Set Viewer Preferences of PDF Documents
Setting view preferences in PDF documents is a crucial feature that can significantly enhance user experience. By configuring options like page layout, display mode, and zoom level, you ensure recipients view the document as intended, without manual adjustments. This is especially useful for business reports, design plans, or educational materials, where consistent presentation is crucial for effectively delivering information and leaving a professional impression. This article will show how to set view preferences of PDF documents with Python code using Spire.PDF for Python.
Install Spire.PDF for Python
This scenario requires Spire.PDF for Python and plum-dispatch v1.7.4. They can be easily installed in your Windows through the following pip command.
pip install Spire.PDF
If you are unsure how to install, please refer to: How to Install Spire.PDF for Python on Windows
Set PDF Viewer Preferences with Python
Viewer preferences allow document creators to define how a PDF document is displayed when opened, including page layout, window layout, and display mode. Developers can use the properties under ViewerPreferences class to set those display options. The detailed steps are as follows:
- Create a PdfDocument object.
- Load a PDF document using PdfDocument.LoadFromFile() method.
- Get the ViewerPreferences through using PdfDocument.ViewerPreferences property.
- Set the viewer preferences using properties under ViewerPreferences class.
- Save the document using PdfDocument.SaveToFile() method.
- Python
from spire.pdf import *
# Create a PdfDocument object
pdf = PdfDocument()
# Load a PDF file
pdf.LoadFromFile("Sample.pdf")
# Get the viewer preferences
preferences = pdf.ViewerPreferences
# Set the viewer preferences
preferences.FitWindow = True
preferences.CenterWindow = True
preferences.HideMenubar = True
preferences.HideToolbar = True
preferences.DisplayTitle = True
preferences.HideWindowUI = True
preferences.PageLayout = PdfPageLayout.SinglePage
preferences.BookMarkExpandOrCollapse = True
preferences.PrintScaling = PrintScalingMode.AppDefault
preferences.PageMode = PdfPageMode.UseThumbs
# Save the document
pdf.SaveToFile("output/ViewerPreferences.pdf")
pdf.Close()
Set the Opening Page and Zoom Level with Python
By creating PDF actions and setting them to be executed when the document is opened, developers can configure additional viewer preferences, such as the initial page display and zoom level. Here are the steps to follow:
- Create a PdfDocument object.
- Load a PDF document using PdfDocument.LoadFromFile() method.
- Get a page using PdfDocument.Pages.get_Item() method.
- Create a PdfDestination object and set the location and zoom factor of the destination.
- Create a PdfGoToAction object using the destination.
- Set the action as the document open action through PdfDocument.AfterOpenAction property.
- Save the document using PdfDocument.SaveToFile() method.
- Python
from spire.pdf import *
# Create a PdfDocument object
pdf = PdfDocument()
# Load a PDF file
pdf.LoadFromFile("Sample1.pdf")
# Get the second page
page = pdf.Pages.get_Item(1)
# Create a PdfDestination object
dest = PdfDestination(page)
# Set the location and zoom factor of the destination
dest.Mode = PdfDestinationMode.Location
dest.Location = PointF(0.0, page.Size.Height / 2)
dest.Zoom = 0.8
# Create a PdfGoToAction object
action = PdfGoToAction(dest)
# Set the action as the document open action
pdf.AfterOpenAction = action
# Save the document
pdf.SaveToFile("output/OpenPageZoom.pdf")
pdf.Close()
Apply for a Temporary License
If you'd like to remove the evaluation message from the generated documents, or to get rid of the function limitations, please request a 30-day trial license for yourself.
Python: Create Actions in PDF Documents
One powerful feature that enhances the interactivity and utility of PDF documents is the actions in these documents. By embedding actions such as document jumping, navigation controls, or even media playing, users can transform static documents into dynamic tools that streamline workflows, improve user engagement, and automate routine tasks, making the use of PDFs more efficient and versatile than ever before. This article will show how to use Spire.PDF for Python to create actions in PDF documents with Python code effortlessly.
- Create a Navigation Action in PDF with Python
- Create a Sound Action in PDF with Python
- Create a File Open Action in PDF with Python
Install Spire.PDF for Python
This scenario requires Spire.PDF for Python and plum-dispatch v1.7.4. They can be easily installed in your Windows through the following pip command.
pip install Spire.PDF
If you are unsure how to install, please refer to: How to Install Spire.PDF for Python on Windows
Create a Navigation Action in PDF with Python
A navigation button is an action that allows users to jump to a specified position on a designated page within a document. Developers can create a PdfDestination object, use it to create a PdfGoToAction, and then create an annotation based on this object and add it to the page to complete the creation of the navigation button. The following are the detailed steps:
- Create an object of PdfDocument class and load a PDF document using PdfDocument.LoadFromFile() method.
- Create a PdfDestination object and set its property.
- Create a PdfGoToAction object based on the destination.
- Draw a rectangle on a page using PdfPageBase.Canvas.DrawRectangle() method.
- Create a PdfActionAnnotation object based on the action and add it to the page using PdfPageBase.Annotations.Add() method.
- Save the document using PdfDocument.SaveToFile() method.
- Python
from spire.pdf import *
# Create an instance of PdfDocument class and load a PDF document
pdf = PdfDocument()
pdf.LoadFromFile("Sample.pdf")
# Create a PdfDestination instance and set its properties
destination = PdfDestination(pdf.Pages[0])
destination.Location = PointF(0.0, 0.0)
destination.Mode = PdfDestinationMode.Location
destination.Zoom = 0.8
# Create a rectangle
rect = RectangleF.FromLTRB(70, pdf.PageSettings.Size.Height - 120, 140, pdf.PageSettings.Size.Height - 100)
# Create a PdfGoToAction instance
action = PdfGoToAction(destination)
# Draw a rectangle on the second page
pdf.Pages.get_Item(1).Canvas.DrawRectangle(PdfBrushes.get_LightGray(), rect)
# Draw text of the button
font = PdfFont(PdfFontFamily.TimesRoman, 14.0)
stringFormat = PdfStringFormat(PdfTextAlignment.Center)
pdf.Pages.get_Item(1).Canvas.DrawString("To Page 1", font, PdfBrushes.get_Green(), rect, stringFormat)
# Create a PdfActionAnnotation instance
annotation = PdfActionAnnotation(rect, action)
# Add the annotation to the second page
pdf.Pages.get_Item(1).Annotations.Add(annotation)
# Save the document
pdf.SaveToFile("output/AddPDFNavigationButton.pdf")
pdf.Close()

Create a Sound Action in PDF with Python
Developers can embed audio as actions in PDF documents, which allows the audio to play when the user performs a specified action, such as playing when the file opens or when a button is clicked. The following are the steps for creating a sound action:
- Create an instance of PdfDocument class.
- Load a PDF document using PdfDocument.LoadFromFile() method.
- Create an instance of PdfSoundAction class with an audio file.
- Set the audio parameters through properties under PdfSound class.
- Set the playing parameters through properties under PdfSoundAction class.
- Get a page using PdfDocument.Pgaes.get_Item(() method.
- Draw an image on the page using PdfPageBase.Canvas.Draw() method.
- Create a PdfActionAnnotation object with the sound action at the location of the image.
- Add the annotation to the page
- Or you can only set the sound action as the action performed after the document is opened through PdfDocument.AfterOpenAction property. This doesn’t need to add it as an annotation on a PDF page.
- Save the document using PdfDocument.SaveToFile() method.
- Python
from spire.pdf import *
# Create a PdfDocument instance and load a PDF file
pdf = PdfDocument()
pdf.LoadFromFile("Sample.pdf")
# Get the first page of the document
page = pdf.Pages.get_Item(0)
# Create an instance of PdfSoundAction with the sound file path
soundAction = PdfSoundAction("Wave.wav")
# Set the audio parameters
soundAction.Sound.Bits = 16
soundAction.Sound.Channels = PdfSoundChannels.Stereo
soundAction.Sound.Encoding = PdfSoundEncoding.Signed
soundAction.Sound.Rate = 44100
# Set the playing parameters
soundAction.Volume = 0.5
soundAction.Repeat = True
soundAction.Mix = True
soundAction.Synchronous = False
# Draw an image on the page
image = PdfImage.FromFile("Sound.png")
page.Canvas.DrawImage(image, PointF(30.0, 30.0))
# Create an instance of PdfActionAnnotation with the sound action
rect = RectangleF.FromLTRB(30.0, 30.0, image.GetBounds().Width + 30.0, image.GetBounds().Height + 30.0)
annotation = PdfActionAnnotation(rect, soundAction)
# Add the annotation to the page
page.Annotations.Add(annotation)
# Set the sound action to play after the document is opened
# pdf.AfterOpenAction = soundAction
# Save the document
pdf.SaveToFile("output/AddMusicPDF.pdf")
pdf.Close()
Create a File Open Action in PDF with Python
The PdfLaunchAction class represents a file open action in PDF that allows users to open the corresponding file by clicking on a button on a PDF page. Developers can specify the absolute or relative path of the file to be opened and whether to open in a new window when creating a file open action. The detailed steps for creating a file open action in a PDF document are as follows:
- Create an object of PdfDocument class and load a PDF document using PdfDocument.LoadFromFile() method.
- Get a page of the document using PdfDocument.Pages.get_Item() method.
- Draw a rectangle on the page using PdfPageBase.Canvas.DrawRectangle() method.
- Create an object of PdfLaunchAction class and specify the file path and path type.
- Set the opening mode to new window through PdfLaunchAction.IsNewWindow property.
- Create an object of PdfActionAnnotation class based on the action and set its color through PdfActionAnnotation.Color property.
- Add the annotation to the page using PdfPageBase.Annotations.Add() method.
- Save the document using PdfDocument.SaveToFile() method.
- Python
from spire.pdf import *
# Create an instance of PdfDocument class
pdf = PdfDocument()
# Load a PDF file
pdf.LoadFromFile("Sample.pdf")
# Get the first page of the document
page = pdf.Pages.get_Item(0)
# Draw a rectangle on the page
rect = RectangleF.FromLTRB(50, pdf.PageSettings.Size.Height - 100, 200, pdf.PageSettings.Size.Height - 80)
page.Canvas.DrawRectangle(PdfPens.get_LightGray(), rect)
# Draw text in the rectangle
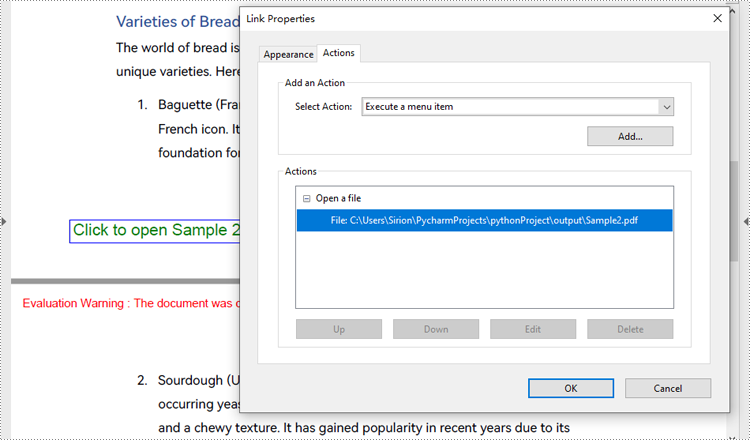
page.Canvas.DrawString("Click to open Sample 2", PdfFont(PdfFontFamily.Helvetica, 14.0), PdfBrushes.get_Green(), rect, PdfStringFormat(PdfTextAlignment.Center))
# Create a PdfLaunchAction object
action = PdfLaunchAction("Sample2.pdf", PdfFilePathType.Relative)
action.IsNewWindow = True
# Create a PdfActionAnnotation object based on the action
annotation = PdfActionAnnotation(rect, action)
annotation.Color = PdfRGBColor(Color.get_Blue())
# Add the annotation to the page
page.Annotations.Add(annotation)
# Save the document
pdf.SaveToFile("output/CreatePDFLaunchAction.pdf")
pdf.Close()
Apply for a Temporary License
If you'd like to remove the evaluation message from the generated documents, or to get rid of the function limitations, please request a 30-day trial license for yourself.
Python: Add Barcodes to PDF
Barcodes in PDFs can facilitate quicker data retrieval and processing. You can add barcodes to PDF files that contain detailed information such as the document's unique identifier, version number, creator, or even the entire document content. When scanned, all information is decoded immediately. This instant access is invaluable for businesses dealing with large volumes of documents, as it minimizes the time and effort required for manual searching and data entry. In this article, you will learn how to add barcodes to PDF in Python using Spire.PDF for Python and Spire.Barcode for Python.
Install Spire.PDF for Python
This scenario requires Spire.PDF for Python and Spire.Barcode for Python. They can be easily installed in your Windows through the following pip command.
pip install Spire.PDF pip install Spire.Barcode
If you are unsure how to install, please refer to this tutorial: How to Install Spire.PDF for Python on Windows
Add Barcodes to PDF in Python
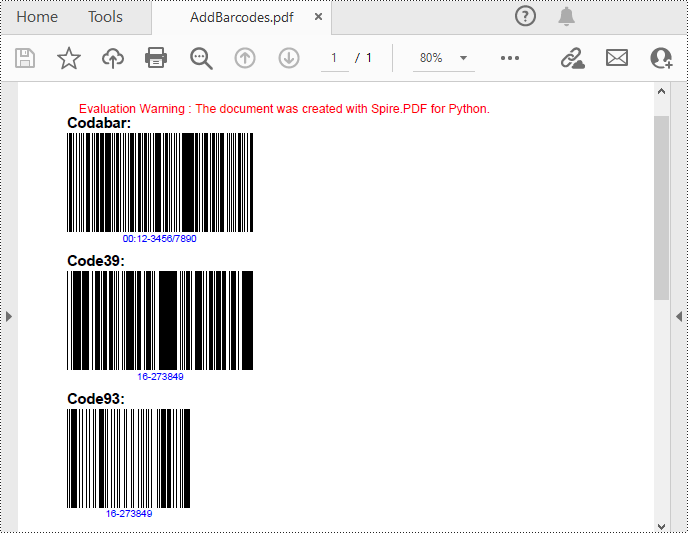
Spire.PDF for Python support several 1D barcode types represented by different classes, such as PdfCodabarBarcode, PdfCode11Barcode, PdfCode32Barcode, PdfCode39Barcode, PdfCode93Barcode.
Each class provides corresponding properties for setting the barcode text, size, color, etc. The following are the steps to draw the common Codabar, Code39 and Code93 barcodes at the specified locations on a PDF page.
- Create a PdfDocument object.
- Add a PDF page using PdfDocument.Pages.Add() method.
- Create a PdfTextWidget object and draw text on the page using PdfTextWidget.Draw() method.
- Create PdfCodabarBarcode, PdfCode39Barcode, PdfCode93Barcode objects.
- Set the gap between the barcode and the displayed text through the BarcodeToTextGapHeight property of the corresponding classes.
- Sets the barcode text display location through the TextDisplayLocation property of the corresponding classes.
- Set the barcode text color through the TextColor property of the corresponding classes.
- Draw the barcodes at specified locations on the PDF page using the Draw(page: PdfPageBase, location: PointF) method of the corresponding classes.
- Save the result PDF file using PdfDocument.SaveToFile() method.
- Python
from spire.pdf.common import *
from spire.pdf import *
# Create a PDF document
pdf = PdfDocument()
# Add a page
page = pdf.Pages.Add(PdfPageSize.A4())
# Initialize y-coordinate
y = 20.0
# Create a true type font
font = PdfTrueTypeFont("Arial", 12.0, PdfFontStyle.Bold, True)
# Draw text on the page
text = PdfTextWidget()
text.Font = font
text.Text = "Codabar:"
result = text.Draw(page, 0.0, y)
page = result.Page
y = result.Bounds.Bottom + 2
# Draw Codabar barcode on the page
Codabar = PdfCodabarBarcode("00:12-3456/7890")
Codabar.BarcodeToTextGapHeight = 1.0
Codabar.EnableCheckDigit = True
Codabar.ShowCheckDigit = True
Codabar.TextDisplayLocation = TextLocation.Bottom
Codabar.TextColor = PdfRGBColor(Color.get_Blue())
Codabar.Draw(page, PointF(0.0, y))
y = Codabar.Bounds.Bottom + 6
# Draw text on the page
text.Text = "Code39:"
result = text.Draw(page, 0.0, y)
page = result.Page
y = result.Bounds.Bottom + 2
# Draw Code39 barcode on the page
Code39 = PdfCode39Barcode("16-273849")
Code39.BarcodeToTextGapHeight = 1.0
Code39.TextDisplayLocation = TextLocation.Bottom
Code39.TextColor = PdfRGBColor(Color.get_Blue())
Code39.Draw(page, PointF(0.0, y))
y = Code39.Bounds.Bottom + 6
# Draw text on the page
text.Text = "Code93:"
result = text.Draw(page, 0.0, y)
page = result.Page
y = result.Bounds.Bottom + 2
# Draw Code93 barcode on the page
Code93 = PdfCode93Barcode("16-273849")
Code93.BarcodeToTextGapHeight = 1.0
Code93.TextDisplayLocation = TextLocation.Bottom
Code93.TextColor = PdfRGBColor(Color.get_Blue())
Code93.QuietZone.Bottom = 5.0
Code93.Draw(page, PointF(0.0, y))
# Save the document
pdf.SaveToFile("AddBarcodes.pdf")
pdf.Close()
Add QR Codes to PDF in Python
To add 2D barcodes to a PDF file, the Spire.Barcode for Python library is required to generate QR code first, and then you can add the QR code image to the PDF file with the Spire.PDF for Python library. The following are the detailed steps.
- Create a PdfDocument object.
- Add a PDF page using PdfDocument.Pages.Add() method.
- Create a BarcodeSettings object.
- Call the corresponding properties of the BarcodeSettings class to set the barcode type, data, error correction level and width, etc.
- Create a BarCodeGenerator object based on the settings.
- Generate QR code image using BarCodeGenerator.GenerateImage() method.
- Save the QR code image to a PNG file.
- Draw the QR code image at a specified location on the PDF page using PdfPageBase.Canvas.DrawImage() method.
- Save the result PDF file using PdfDocument.SaveToFile() method.
- Python
from spire.pdf.common import *
from spire.pdf import *
from spire.barcode import *
# Create a PdfDocument instance
pdf = PdfDocument()
# Add a page
page = pdf.Pages.Add()
# Create a BarcodeSettings object
settings = BarcodeSettings()
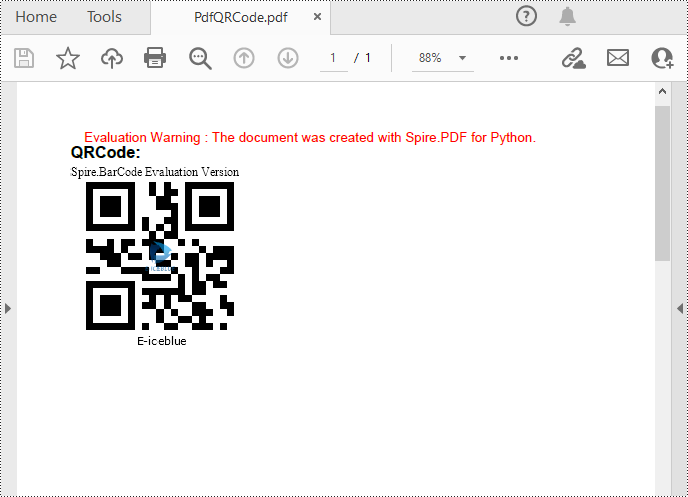
# Set the barcode type to QR code
settings.Type = BarCodeType.QRCode
# Set the data of the QR code
settings.Data = "E-iceblue"
settings.Data2D = "E-iceblue"
# Set the width of the QR code
settings.X = 2
# Set the error correction level of the QR code
settings.QRCodeECL = QRCodeECL.M
# Set to show QR code text at the bottom
settings.ShowTextOnBottom = True
# Generate QR code image based on the settings
barCodeGenerator = BarCodeGenerator(settings)
QRimage = barCodeGenerator.GenerateImage()
# Save the QR code image to a .png file
with open("QRCode.png", "wb") as file:
file.write(QRimage)
# Initialize y-coordinate
y = 20.0
# Create a true type font
font = PdfTrueTypeFont("Arial", 12.0, PdfFontStyle.Bold, True)
# Draw text on the PDF page
text = PdfTextWidget()
text.Font = font
text.Text = "QRCode:"
result = text.Draw(page, 0.0, y)
page = result.Page
y = result.Bounds.Bottom + 2
# Draw QR code image on the PDF page
pdfImage = PdfImage.FromFile("QRCode.png")
page.Canvas.DrawImage(pdfImage, 0.0, y)
# Save the document
pdf.SaveToFile("PdfQRCode.pdf")
pdf.Close()
Apply for a Temporary License
If you'd like to remove the evaluation message from the generated documents, or to get rid of the function limitations, please request a 30-day trial license for yourself.
Python: Compare Two PDF Documents for Differences
Comparing PDF documents is a common task when collaborating on projects or tracking changes. This allows users to quickly review and understand what has been modified, added, or removed between revisions. Effective PDF comparison streamlines the review process and ensures all stakeholders are aligned on the latest document content.
In this article, you will learn how to compare two PDF documents using Python and the Spire.PDF for Python library.
Install Spire.PDF for Python
This scenario requires Spire.PDF for Python and plum-dispatch v1.7.4. They can be easily installed in your Windows through the following pip command.
pip install Spire.PDF
If you are unsure how to install, please refer to this tutorial: How to Install Spire.PDF for Python on Windows
Compare Two PDF Documents in Python
Spire.PDF for Python provides the PdfComparer.Compare() method allowing developers to compare two PDF documents and save the comparison result to another PDF document. Here are the detailed steps.
- Load the first PDF document while initializing the PdfDocument object.
- Load the second PDF document while initializing another PdfDocument object.
- Initialize an instance of PdfComparer class, passing the two PdfDocument objects are the parameter.
- Call Compare() method of the PdfComparer object to compare the two PDF documents and save the result to a different PDF document.
- Python
from spire.pdf.common import *
from spire.pdf import *
# Load the first document
doc_one = PdfDocument("C:\\Users\\Administrator\\Desktop\\PDF_ONE.pdf")
# Load the section document
doc_two = PdfDocument("C:\\Users\\Administrator\\Desktop\\PDF_TWO.pdf")
# Create a PdfComparer object
comparer = PdfComparer(doc_two, doc_one)
# Compare two documents and save the comparison result in a pdf document
comparer.Compare("output/CompareResult.pdf")
# Dispose resources
doc_one.Dispose()
doc_two.Dispose()

Compare Selected Pages in PDF Documents in Python
Instead of comparing two entire documents, you can specify the pages to compare using the PdfComparer.PdfCompareOptions.SetPageRanges() method. The following are the detailed steps.
- Load the first PDF document while initializing the PdfDocument object.
- Load the second PDF document while initializing another PdfDocument object.
- Initialize an instance of PdfComparer class, passing the two PdfDocument objects are the parameter.
- Specify the page range to compare using PdfComparer.PdfCompareOptions.SetPageRanges() method
- Call PdfComparer.Compare() method to compare the selected pages and save the result to a different PDF document.
- Python
from spire.pdf.common import *
from spire.pdf import *
# Load the first document
doc_one = PdfDocument("C:\\Users\\Administrator\\Desktop\\PDF_ONE.pdf")
# Load the section document
doc_two = PdfDocument("C:\\Users\\Administrator\\Desktop\\PDF_TWO.pdf")
# Create a PdfComparer object
comparer = PdfComparer(doc_two, doc_one)
# Set page range for comparison
comparer.PdfCompareOptions.SetPageRanges(1, 3, 1, 3)
# Compare the selected pages and save the comparison result in a pdf document
comparer.Compare("output/CompareResult.pdf")
# Dispose resources
doc_one.Dispose()
doc_two.Dispose()
Apply for a Temporary License
If you'd like to remove the evaluation message from the generated documents, or to get rid of the function limitations, please request a 30-day trial license for yourself.
Efficient PDF Compression in Python (A Practical Guide)

Large PDF files can slow down email delivery, break upload limits, and consume unnecessary storage. This is especially common in PDFs that include high-resolution scans, images, or embedded fonts. If you're working with Python and need to automate PDF compression without compromising quality, this guide will help you get started.
In this tutorial, you’ll learn how to compress PDF files in Python using the Spire.PDF for Python library. We'll cover several effective techniques, including image recompression, font optimization, metadata removal, and batch compression—perfect for web, backend, or desktop applications.
Table of Contents
- Common Scenarios Requiring PDF Compression
- Prerequisites
- Practical PDF Compression Techniques in Python
- Summary
Common Scenarios Requiring PDF Compression
Reducing the size of PDF documents is often essential in the following situations:
| Use Case | Benefit |
|---|---|
| Email Attachments | Avoid size limits and improve deliverability |
| Web Uploads | Reduce upload time and server storage |
| Mobile Access | Faster loading and less data consumption |
| Cloud Archiving | Lower storage cost for backups |
| App Submissions | Meet strict file size limits |
Prerequisites
Before you begin compressing PDFs with Python, make sure the following requirements are met:
- Python 3.7 or above
Ensure that Python (version 3.7 or later) is installed on your system. You can download it from the official Python website. - Spire.PDF for Python
This is a powerful PDF library that allows you to programmatically create, manipulate, and compress PDF documents—without relying on external software like Adobe Acrobat.
To install Spire.PDF for Python, run the following command in your terminal or command prompt:
pip install spire.pdf
Need help with the installation? See our step-by-step guide: How to Install Spire.PDF for Python on Windows_
Practical PDF Compression Techniques in Python
In this section, you'll explore five practical techniques for reducing PDF file size:
- Font compression and unembedding
- Image compression
- Full-document compression
- Metadata and attachment removal
- Batch compressing multiple PDFs
Font Compression and Unembedding
Fonts embedded in a PDF—especially those from large font libraries or multilingual character sets—can significantly increase the file size. Spire.PDF allows you to:
- Compress embedded fonts to minimize space usage
- Unembed fonts that are not essential for rendering
from spire.pdf import *
# Create a PdfCompressor object and load the PDF file
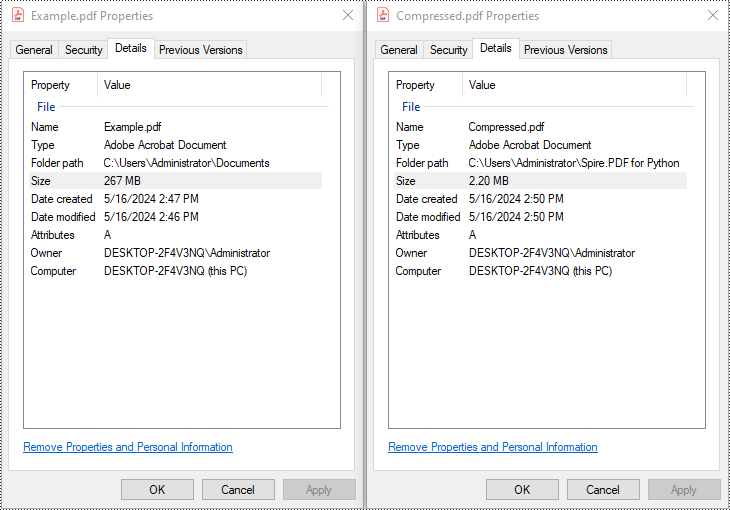
compressor = PdfCompressor("C:/Users/Administrator/Documents/Example.pdf")
# Get the OptimizationOptions object
compression_options = compressor.OptimizationOptions
# Enable font compression
compression_options.SetIsCompressFonts(True)
# Optional: unembed fonts to further reduce size
# compression_options.SetIsUnembedFonts(True)
# Compress the PDF and save the result
compressor.CompressToFile("CompressFonts.pdf")
Image Compression
Spire.PDF lets you reduce the size of all images in a PDF by creating a PdfCompressor instance, enabling the image resizing and compression options, and specifying the image quality level. This approach applies compression uniformly across the entire document.
from spire.pdf import *
# Create a PdfCompressor object and load the PDF file
compressor = PdfCompressor("C:/Users/Administrator/Documents/Example.pdf")
# Get the OptimizationOptions object
compression_options = compressor.OptimizationOptions
# Enable image resizing
compression_options.SetResizeImages(True)
# Enable image compression
compression_options.SetIsCompressImage(True)
# Set image quality (available options: Low, Medium, High)
compression_options.SetImageQuality(ImageQuality.Medium)
# Compress and save the PDF file
compressor.CompressToFile("Compressed.pdf")
Full Document Compression
Beyond optimizing individual elements, Spire.PDF also supports full-document compression. By adjusting the document's CompressionLevel and disabling incremental updates, you can apply comprehensive optimization to reduce overall file size.
from spire.pdf import *
# Create a PdfDocument object
pdf = PdfDocument()
# Load the PDF file
pdf.LoadFromFile("C:/Users/Administrator/Documents/Example.pdf")
# Disable incremental update
pdf.FileInfo.IncrementalUpdate = False
# Set the compression level to the highest
pdf.CompressionLevel = PdfCompressionLevel.Best
# Save the optimized PDF
pdf.SaveToFile("OptimizeDocumentContent.pdf")
pdf.Close()
Removing Metadata and Attachments
Cleaning up metadata and removing embedded attachments is a quick way to reduce PDF size. Spire.PDF lets you remove unnecessary information like author/title fields and attached files:
from spire.pdf import *
# Load the PDF
pdf = PdfDocument()
pdf.LoadFromFile("Example.pdf")
# Disable the incremental update
pdf.FileInfo.IncrementalUpdate = False
# Remove metadata
pdf.DocumentInformation.Author = ""
pdf.DocumentInformation.Title = ""
# Remove attachments
pdf.Attachments.Clear()
# Save the optimized PDF
pdf.SaveToFile("Cleaned.pdf")
pdf.Close()
Batch Compressing Multiple PDFs
You can compress multiple PDFs at once by looping through files in a folder and applying the same optimization settings:
import os
from spire.pdf import *
# Folder containing the PDF files to compress
input_folder = "C:/PDFs/"
# Loop through all files in the input folder
for file in os.listdir(input_folder):
# Process only PDF files
if file.endswith(".pdf"):
# Create a PdfCompressor instance and load the file
compressor = PdfCompressor(os.path.join(input_folder, file))
# Access compression options
opt = compressor.OptimizationOptions
# Enable image resizing
opt.SetResizeImages(True)
# Enable image compression
opt.SetIsCompressImage(True)
# Set image quality to medium (options: Low, Medium, High)
opt.SetImageQuality(ImageQuality.Medium)
# Define output file path with "compressed_" prefix
output_path = os.path.join(input_folder, "compressed_" + file)
# Perform compression and save the result
compressor.CompressToFile(output_path)
Summary
Reducing the size of PDF files is a practical step toward faster workflows, especially when dealing with email sharing, web uploads, and large-scale archiving. With Spire.PDF for Python, developers can implement smart compression techniques—ranging from optimizing images and fonts to stripping unnecessary elements like metadata and attachments.
Whether you're building automation scripts, integrating PDF handling into backend services, or preparing documents for long-term storage, these tools give you the flexibility to control file size without losing visual quality. By combining multiple strategies—like full-document compression and batch processing—you can keep your PDFs lightweight, efficient, and ready for distribution across platforms.
Want to explore more ways to work with PDFs in Python? Explore the full range of Spire.PDF for Python tutorials to learn how to merge/split PDFs, convert PDF to PDF/A, add password protection, and more.
Frequently Asked Questions
Q1: Can I use Spire.PDF for Python on Linux or macOS?
A1: Yes. Spire.PDF for Python is compatible with Windows, Linux, and macOS.
Q2: Is Spire.PDF for Python free?
A2: Spire.PDF for Python offers a free version suitable for small-scale and non-commercial use. For full functionality, including unrestricted use in commercial applications, a commercial version is available. You can request a free 30-day trial license to explore all its premium features.
Q3: Will compressing the PDF reduce the visual quality?
A3: Not necessarily. Spire.PDF’s compression methods are designed to preserve visual fidelity while optimizing file size. You can fine-tune image quality or leave it to the default settings.
Extract Tables from PDF Using Python - Easy Table Parsing Guide

Extracting tables from PDF using Python typically involves understanding how content is visually laid out in rows and columns. Many PDF tables are defined using cell borders, making them easier to detect programmatically. In such cases, a layout-aware library that reads content positioning—rather than just raw text—is essential for accurate PDF table extraction in Python.
In this tutorial, you’ll learn a reliable method to extract tables from PDF using Python, no OCR or machine learning required. Whether your PDF contains clean grids or complex layouts, we'll show how to turn table data into structured formats like Excel or pandas DataFrames for further analysis.
Table of Contents
- Install and Set Up Spire.PDF for Python
- Extract Tables from PDF
- Tips for Better Accuracy
- Common Questions (FAQ)
- Conclusion
Handling Table Extraction from PDF in Python
Unlike Excel or CSV files, PDF documents don’t store tables as structured data. To extract tables from PDF files using Python, you need a library that can analyze the layout and detect tabular structures.
Spire.PDF for Python simplifies this process by providing built-in methods to extract tables page by page. It works best with clearly formatted tables and helps developers convert PDF content into usable data formats like Excel or CSV.
You can install the library with:
pip install Spire.PDF
Or install the free version for smaller PDF table extraction tasks:
pip install spire.pdf.free
Extracting Tables from PDF – Step-by-Step
To extract tables from a PDF file using Python, we start by loading the document and analyzing each page individually. With Spire.PDF for Python, you can detect tables based on their layout structure and extract them programmatically—even from multi-page documents.
Load PDF and Extract Tables
Here's a basic example that shows how to read tables from a PDF using Python. This method uses Spire.PDF to extract each table from the document page by page, making it ideal for developers who want to programmatically extract tabular data from PDFs.
from spire.pdf import PdfDocument, PdfTableExtractor
# Load PDF document
pdf = PdfDocument()
pdf.LoadFromFile("Sample.pdf")
# Create a PdfTableExtractor object
table_extractor = PdfTableExtractor(pdf)
# Extract tables from each page
for i in range(pdf.Pages.Count):
tables = table_extractor.ExtractTable(i)
for table_index, table in enumerate(tables):
print(f"Table {table_index + 1} on page {i + 1}:")
for row in range(table.GetRowCount()):
row_data = []
for col in range(table.GetColumnCount()):
text = table.GetText(row, col).replace("\n", " ")
row_data.append(text.strip())
print("\t".join(row_data))
This method works reliably for bordered tables. However, for tables without visible borders—especially those with multi-line cells or unmarked headers—the extractor may fail to detect the tabular structure.
The result of extracting table data from a PDF using Python and Spire.PDF is shown below:
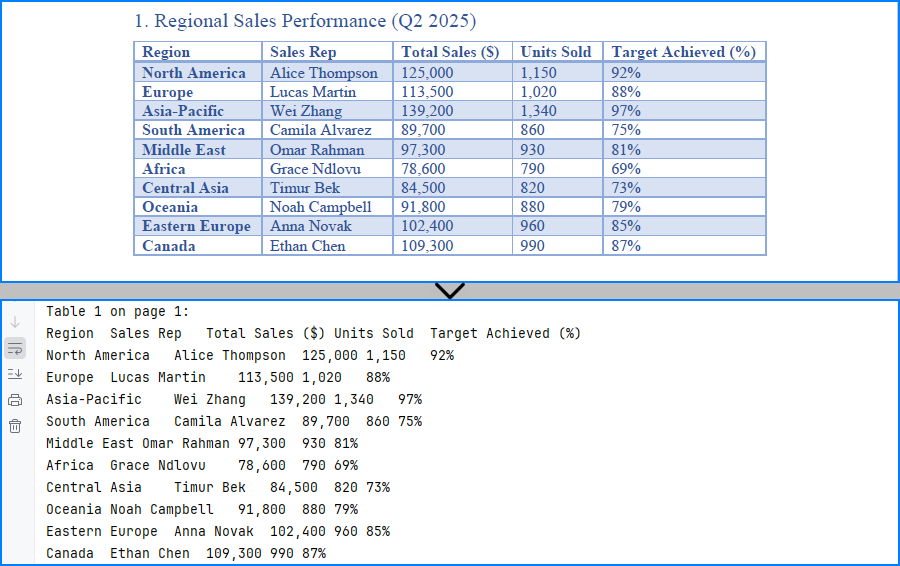
Export Tables to Excel and CSV
If you want to analyze or store the extracted PDF tables, you can convert them to Excel and CSV formats using Python. In this example, we use Spire.XLS for Python to create a spreadsheet for each table, allowing easy data processing or sharing. You can install the library from pip: pip install spire.xls.
from spire.pdf import PdfDocument, PdfTableExtractor
from spire.xls import Workbook, FileFormat
# Load PDF document
pdf = PdfDocument()
pdf.LoadFromFile("G:/Documents/Sample101.pdf")
# Set up extractor and Excel workbook
extractor = PdfTableExtractor(pdf)
workbook = Workbook()
workbook.Worksheets.Clear()
# Extract tables page by page
for page_index in range(pdf.Pages.Count):
tables = extractor.ExtractTable(page_index)
for t_index, table in enumerate(tables):
sheet = workbook.Worksheets.Add(f"Page{page_index+1}_Table{t_index+1}")
for row in range(table.GetRowCount()):
for col in range(table.GetColumnCount()):
text = table.GetText(row, col).replace("\n", " ").strip()
sheet.Range.get_Item(row + 1, col + 1).Value = text
sheet.AutoFitColumn(col + 1)
# Save all tables to one Excel file
workbook.SaveToFile("output/Sample.xlsx", FileFormat.Version2016)
As shown below, the extracted PDF tables are converted to Excel and CSV using Spire.XLS for Python.
You may also like: How to Insert Data into Excel Files in Python
Tips to Improve PDF Table Extraction Accuracy in Python
Extracting tables from PDFs can sometimes yield imperfect results—especially when dealing with complex layouts, page breaks, or inconsistent formatting. Below are a few practical techniques to help improve table extraction accuracy in Python and get cleaner, more structured output.
1. Merging Multi-Page Tables
Spire.PDF extracts tables on a per-page basis. If a table spans multiple pages, you can combine them manually by appending the rows:
Example:
# Extract and combine tables
combined_rows = []
for i in range(start_page, end_page + 1):
tables = table_extractor.ExtractTable(i)
if tables:
table = tables[0] # Assuming one table per page
for row in range(table.GetRowCount()):
cells = [table.GetText(row, col).strip().replace("\n", " ") for col in range(table.GetColumnCount())]
combined_rows.append(cells)
You can then convert combined_rows into Excel or CSV if you prefer analysis via these formats.
2. Filtering Out Empty or Invalid Rows
Tables may contain empty rows or columns, or the extractor may return blank rows depending on layout. You can filter them out before exporting.
Example:
# Step 1: Filter out empty rows
filtered_rows = []
for row in range(table.GetRowCount()):
row_data = [table.GetText(row, col).strip().replace("\n", " ") for col in range(table.GetColumnCount())]
if any(cell for cell in row_data): # Skip completely empty rows
filtered_rows.append(row_data)
# Step 2: Transpose and filter out empty columns
transposed = list(zip(*filtered_rows))
filtered_columns = [col for col in transposed if any(cell.strip() for cell in col)]
# Step 3: Transpose back to original row-column format
filtered_data = list(zip(*filtered_columns))
This helps improve accuracy when working with noisy or inconsistent layouts.
Common Questions (FAQ)
Q: Can I extract both text and tables from a PDF?
Yes, use PdfTextExtractor to retrieve the full page text and PdfTableExtractor to extract structured tables.
Q: Why aren't my tables detected?
Make sure the PDF is text-based (not scanned images) and that the layout follows a logical row-column format. Spire.PDF for Python detects only bordered tables; unbordered tables are often not recognized.
If you are handling an image-based PDF document, you can use Spire.OCR for Python to extract table data. Please refer to: How to Extract Text from Images Using Python.
Q: How to extract tables without borders from PDF documents?
Spire.PDF may have difficulty extracting tables without visible borders. If the tables are not extracted correctly, consider the following approaches:
- Using
PdfTextExtractorto extract raw text and then writing custom logic to identify rows and columns. - Using a large language model API (e.g., GPT) to interpret the structure from extracted plain text and return only structured table data.
- Consider adding visible borders to tables in the original document before generating the PDF, as this makes it easier to extract them using Python code.
Q: How do I convert extracted tables to a pandas DataFrame?
While Spire.PDF doesn’t provide native DataFrame output, you can collect cell values into a list of lists and then convert:
import pandas as pd
df = pd.DataFrame(table_data)
This lets you convert PDF tables into pandas DataFrames using Python for data analysis.
Q: Is Spire.PDF for Python free to use?
Yes, there are two options available:
- Free Spire.PDF for Python – a permanently free version with limited features (e.g., page count limits). You can install it via pip or download it from the official Free Spire.PDF for Python page.
- Temporary Free License – to unlock all features of the commercial version for evaluation or internal use, you can apply for a temporary free license here.
Conclusion
Whether you're working with structured reports, financial data, or standardized forms, extracting tables from PDFs in Python can streamline your workflow. With a layout-aware parser like Spire.PDF for Python, you can reliably detect and export tables—no OCR or manual formatting needed. By converting tables to Excel, CSV, or DataFrame, you unlock their full potential for automation and analysis.
In summary, extracting tables from PDFs in Python becomes much easier with Spire.PDF, especially when converting them into structured formats like Excel and CSV for analysis.
Python: Draw Shapes in PDF Documents
Shapes play a vital role in PDF documents. By drawing graphics, defining outlines, filling colors, setting border styles, and applying geometric transformations, shapes provide rich visual effects and design options for documents. The properties of shapes such as color, line type, and fill effects can be customized according to requirements to meet personalized design needs. They can be used to create charts, decorations, logos, and other elements that enhance the readability and appeal of the document. This article will introduce how to use Spire.PDF for Python to draw shapes into PDF documents from Python.
- Draw Lines in PDF Documents in Python
- Draw Pies in PDF Documents in Python
- Draw Rectangles in PDF Documents in Python
- Draw Ellipses in PDF Documents in Python
Install Spire.PDF for Python
This scenario requires Spire.PDF for Python and plum-dispatch v1.7.4. They can be easily installed in your Windows through the following pip command.
pip install Spire.PDF
If you are unsure how to install, please refer to this tutorial: How to Install Spire.PDF for Python on Windows
Draw Lines in PDF Documents in Python
Spire.PDF for Python provides the PdfPageBase.Canvas.DrawLine() method to draw lines by specifying the coordinates of the starting point and end point and a brush object. Here is a detailed step-by-step guide on how to draw lines:
- Create a PdfDocument object.
- Use the PdfDocument.Pages.Add() method to add a blank page to the PDF document.
- Save the current drawing state using the PdfPageBase.Canvas.Save() method so it can be restored later.
- Define the start point coordinate (x, y) and the length of a solid line segment.
- Create a PdfPen object.
- Draw a solid line segment using the PdfPageBase.Canvas.DrawLine() method with the previously created pen object.
- Set the DashStyle property of the pen to PdfDashStyle.Dash to create a dashed line style.
- Draw a dashed line segment using the pen with a dashed line style via the PdfPageBase.Canvas.DrawLine() method.
- Restore the previous drawing state using the PdfPageBase.Canvas.Restore(state) method.
- Save the document to a file using the PdfDocument.SaveToFile() method.
- Python
from spire.pdf.common import *
from spire.pdf import *
# Create PDF Document Object
doc = PdfDocument()
# Add a Page
page = doc.Pages.Add()
# Save the current drawing state
state = page.Canvas.Save()
# The starting X coordinate of the line
x = 100.0
# The starting Y coordinate of the line
y = 50.0
# The length of the line
width = 300.0
# Create a pen object with deep sky blue color and a line width of 3.0
pen = PdfPen(PdfRGBColor(Color.get_DeepSkyBlue()), 3.0)
# Draw a solid line
page.Canvas.DrawLine(pen, x, y, x + width, y)
# Set the pen style to dashed
pen.DashStyle = PdfDashStyle.Dash
# Set the dashed pattern to [1, 4, 1]
pen.DashPattern = [1, 4, 1]
# The Y coordinate for the start of the dashed line
y = 80.0
# Draw a dashed line
page.Canvas.DrawLine(pen, x, y, x + width, y)
# Restore the previously saved drawing state
page.Canvas.Restore(state)
# Save the document to a file
doc.SaveToFile("Drawing Lines.pdf")
# Close the document and release resources
doc.Close()
doc.Dispose()
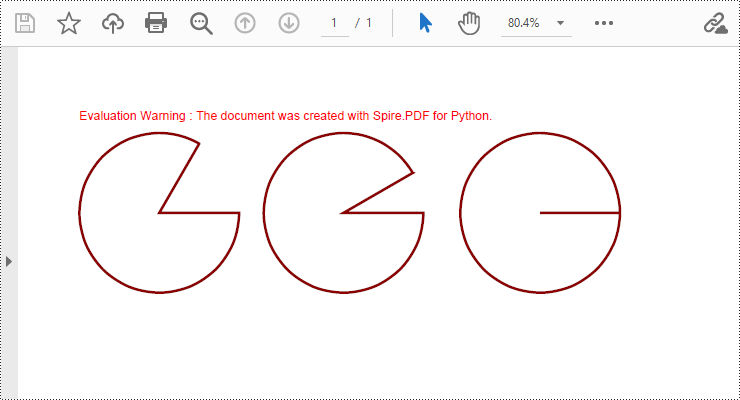
Draw Pies in PDF Documents in Python
To draw pie charts with different positions, sizes, and angles on a specified page, call the PdfPageBase.Canvas.DrawPie() method and pass appropriate parameters. The detailed steps are as follows:
- Create a PdfDocument object.
- Add a blank page to the PDF document using the PdfDocument.Pages.Add() method.
- Save the current drawing state using the PdfPageBase.Canvas.Save() method so it can be restored later.
- Create a PdfPen object.
- Call the PdfPageBase.Canvas.DrawPie() method and pass various position, size, and angle parameters to draw three pie charts.
- Restore the previous drawing state using the PdfPageBase.Canvas.Restore(state) method.
- Save the document to a file using the PdfDocument.SaveToFile() method.
- Python
from spire.pdf.common import *
from spire.pdf import *
# Create PDF Document Object
doc = PdfDocument()
# Add a Page
page = doc.Pages.Add()
# Save the current drawing state
state = page.Canvas.Save()
# Create a pen object with dark red color and a line width of 2.0
pen = PdfPen(PdfRGBColor(Color.get_DarkRed()), 2.0)
# Draw the first pie chart
page.Canvas.DrawPie(pen, 10.0, 30.0, 130.0, 130.0, 360.0, 300.0)
# Draw the second pie chart
page.Canvas.DrawPie(pen, 160.0, 30.0, 130.0, 130.0, 360.0, 330.0)
# Draw the third pie chart
page.Canvas.DrawPie(pen, 320.0, 30.0, 130.0, 130.0, 360.0, 360.0)
# Restore the previously saved drawing state
page.Canvas.Restore(state)
# Save the document to a file
doc.SaveToFile("Drawing Pie Charts.pdf")
# Close the document and release resources
doc.Close()
doc.Dispose()
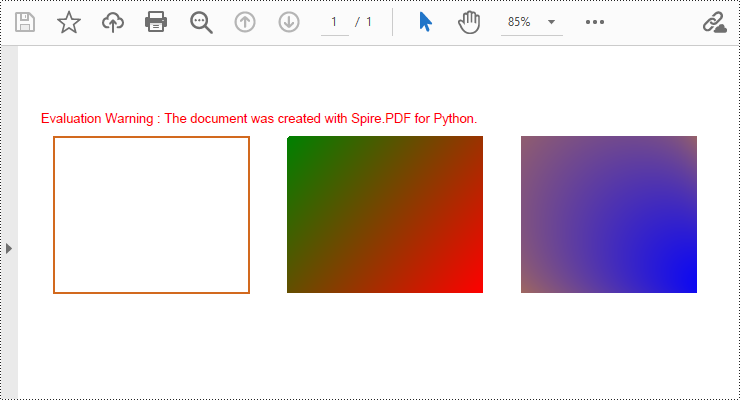
Draw Rectangles in PDF Documents in Python
Spire.PDF for Python provides the PdfPageBase.Canvas.DrawRectangle() method to draw rectangular shapes. By passing position and size parameters, you can define the position and dimensions of the rectangle. Here are the detailed steps for drawing a rectangle:
- Create a PdfDocument object.
- Use the PdfDocument.Pages.Add() method to add a blank page to the PDF document.
- Use the PdfPageBase.Canvas.Save() method to save the current drawing state for later restoration.
- Create a PdfPen object.
- Use the PdfPageBase.Canvas.DrawRectangle() method with the pen to draw the outline of a rectangle.
- Create a PdfLinearGradientBrush object for linear gradient filling.
- Use the PdfPageBase.Canvas.DrawRectangle() method with the linear gradient brush to draw a filled rectangle.
- Create a PdfRadialGradientBrush object for radial gradient filling.
- Use the PdfPageBase.Canvas.DrawRectangle() method with the radial gradient brush to draw a filled rectangle.
- Use the PdfPageBase.Canvas.Restore(state) method to restore the previously saved drawing state.
- Use the PdfDocument.SaveToFile() method to save the document to a file.
- Python
from spire.pdf.common import *
from spire.pdf import *
# Create PDF Document Object
doc = PdfDocument()
# Add a Page
page = doc.Pages.Add()
# Save the current drawing state
state = page.Canvas.Save()
# Create a Pen object with chocolate color and line width of 1.5
pen = PdfPen(PdfRGBColor(Color.get_Chocolate()), 1.5)
# Draw the outline of a rectangle using the pen
page.Canvas.DrawRectangle(pen, RectangleF(PointF(20.0, 30.0), SizeF(150.0, 120.0)))
# Create a linear gradient brush
linearGradientBrush = PdfLinearGradientBrush(PointF(200.0, 30.0), PointF(350.0, 150.0), PdfRGBColor(Color.get_Green()), PdfRGBColor(Color.get_Red()))
# Draw a filled rectangle using the linear gradient brush
page.Canvas.DrawRectangle(linearGradientBrush, RectangleF(PointF(200.0, 30.0), SizeF(150.0, 120.0)))
# Create a radial gradient brush
radialGradientBrush = PdfRadialGradientBrush(PointF(380.0, 30.0), 150.0, PointF(530.0, 150.0), 150.0, PdfRGBColor(Color.get_Orange()) , PdfRGBColor(Color.get_Blue()))
# Draw a filled rectangle using the radial gradient brush
page.Canvas.DrawRectangle(radialGradientBrush, RectangleF(PointF(380.0, 30.0), SizeF(150.0, 120.0)))
# Restore the previously saved drawing state
page.Canvas.Restore(state)
# Save the document to a file
doc.SaveToFile("Drawing Rectangle Shapes.pdf")
# Close the document and release resources
doc.Close()
doc.Dispose()
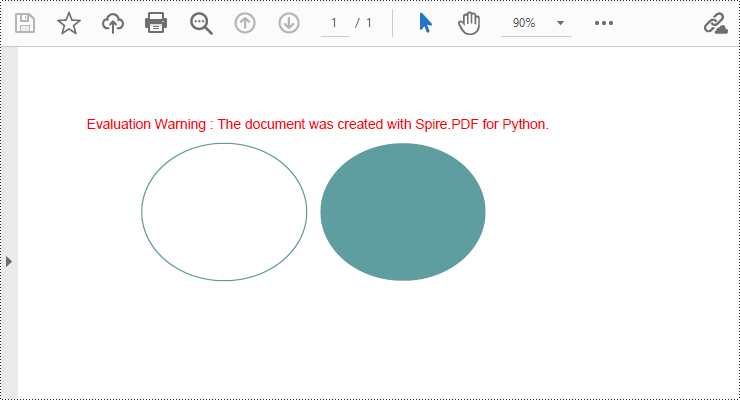
Draw Ellipses in PDF Documents in Python
Spire.PDF for Python provides the PdfPageBase.Canvas.DrawEllipse() method to draw elliptical shapes. You can use either a pen or a fill brush to draw ellipses in different styles. Here are the detailed steps for drawing an ellipse:
- Create a PdfDocument object.
- Use the PdfDocument.Pages.Add() method to add a blank page to the PDF document.
- Use the PdfPageBase.Canvas.Save() method to save the current drawing state for later restoration.
- Create a PdfPen object.
- Use the PdfPageBase.Canvas.DrawEllipse() method with the pen object to draw the outline of an ellipse, specifying the position and size of the ellipse.
- Create a PdfSolidBrush object.
- Use the PdfPageBase.Canvas.DrawEllipse() method with the fill brush object to draw a filled ellipse, specifying the position and size of the ellipse.
- Use the PdfPageBase.Canvas.Restore(state) method to restore the previously saved drawing state.
- Use the PdfDocument.SaveToFile() method to save the document to a file.
- Python
from spire.pdf.common import *
from spire.pdf import *
# Create PDF Document Object
doc = PdfDocument()
# Add a Page
page = doc.Pages.Add()
# Save the current drawing state
state = page.Canvas.Save()
# Create a Pen object
pen = PdfPens.get_CadetBlue()
# Draw the outline of an ellipse shape
page.Canvas.DrawEllipse(pen, 50.0, 30.0, 120.0, 100.0)
# Create a Brush object for filling
brush = PdfSolidBrush(PdfRGBColor(Color.get_CadetBlue()))
# Draw the filled ellipse shape
page.Canvas.DrawEllipse(brush, 180.0, 30.0, 120.0, 100.0)
# Restore the previously saved drawing state
page.Canvas.Restore(state)
# Save the document to a file
doc.SaveToFile("Drawing Ellipse Shape.pdf")
# Close the document and release resources
doc.Close()
doc.Dispose()
Apply for a Temporary License
If you'd like to remove the evaluation message from the generated documents, or to get rid of the function limitations, please request a 30-day trial license for yourself.