Optical Character Recognition (OCR) technology bridges the physical and digital worlds by converting text within images into machine-readable data. For .NET developers, the ability to extract text from images in C# is essential for building intelligent document processing, automated data entry, and accessibility solutions.
In this article, we’ll explore how to implement OCR in C# using the Spire.OCR for .NET library, covering basic extraction, advanced features like coordinate tracking, and best practices to ensure accuracy and efficiency.
Table of Contents:
- Understanding OCR and Spire.OCR
- Setting Up Your OCR Environment
- Basic Recognition: Extract Text from Images in C#
- Advanced Extraction: Extract Text with Coordinates in C#
- Tips to Optimize OCR Accuracy
- FAQs (Supported Languages and Image Formats)
- Conclusion & Free License
Understanding OCR and Spire.OCR
What is OCR?
OCR technology analyzes images of text - such as scanned documents, screenshots, or photos - and converts them into text strings that can be edited, searched, or processed programmatically.
Why Spire.OCR Stands Out?
Spire.OCR for .NET is a powerful, developer-friendly library that enables highly accurate text recognition from images in C# applications. Key features include:
- Support for multiple languages (English, Chinese, Japanese, etc.).
- High accuracy recognition algorithms optimized for various fonts and styles.
- Text coordinate extraction for precise positioning.
- Batch processing capabilities.
- Compatibility with .NET Framework and .NET Core.
Setting Up Your OCR Environment
Before diving into the C# code for image to text OCR operations, configure your development environment first:
1. Install via NuGet:
Open the NuGet Package Manager in Visual Studio. Search for "Spire.OCR" and install the latest version in your project. Alternatively, use the Package Manager Console:
Install-Package Spire.OCR
2. Download OCR Models:
Spire.OCR relies on pre-trained models to recognize image text. Download the model files for your operating system:
After downloading, extract to a directory (e.g., F:\OCR Model\win-x64)
Important Note: Remember to change the platform target of your solution to x64 as Spire.OCR only supports 64-bit platforms.
Basic Recognition: Extract Text from Images in C#
Let’s start with a simple example that demonstrates how to read text from an image using Spire.OCR.
C# code to get text from an image:
using Spire.OCR;
using System.IO;
namespace OCRTextFromImage
{
internal class Program
{
static void Main(string[] args)
{
// Create an instance of the OcrScanner class
OcrScanner scanner = new OcrScanner();
// Create an instance of the ConfigureOptions class
ConfigureOptions configureOptions = new ConfigureOptions();
// Set the path to the OCR model
configureOptions.ModelPath = "F:\\OCR Model\\win-x64";
// Set the language for text recognition. (The default is English.)
configureOptions.Language = "English";
// Apply the configuration options to the scanner
scanner.ConfigureDependencies(configureOptions);
// Scan image and extract text
scanner.Scan("sample.png");
// Save the extracted text to a txt file
string text = scanner.Text.ToString();
File.WriteAllText("output.txt", text);
}
}
}
Code Explanation:
- OcrScanner: Core class for text recognition.
- ConfigureOptions: Sets OCR parameters:
- ModelPath: Specifies the path to the OCR model files.
- Language: Defines the recognition language (e.g., "English", "Chinese").
- Scan(): Processes image and extracts text using the configured settings.
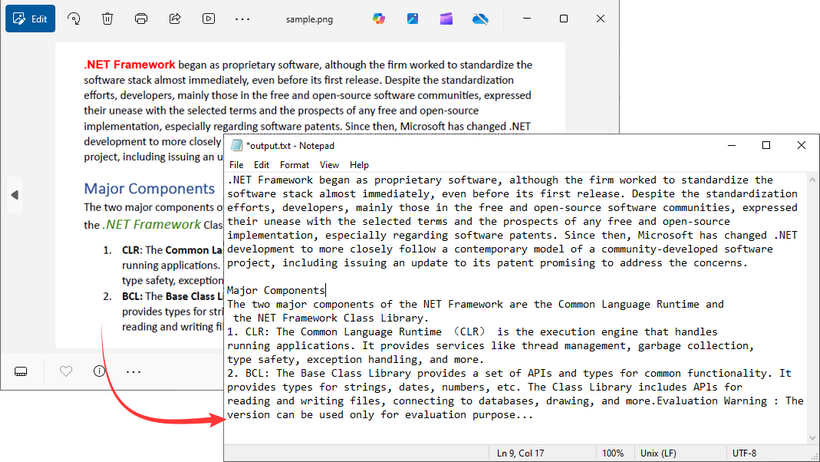
Output:
This C# code processes an image file (sample.png) and saves the extracted text to a text file (output.txt) using File.WriteAllText().
Advanced Extraction: Extract Text with Coordinates in C#
In many cases, knowing the position of extracted text within an image is as important as the text itself - for example, when processing invoices, forms, or structured documents. Spire.OCR allows you to extract not just text but also the coordinates of the text blocks, enabling precise analysis.
C# code to extract text with coordinates from an Image:
using Spire.OCR;
using System.Collections.Generic;
using System.IO;
namespace OCRWithCoordinates
{
internal class Program
{
static void Main(string[] args)
{
// Create an instance of the OcrScanner class
OcrScanner scanner = new OcrScanner();
// Create an instance of the ConfigureOptions class
ConfigureOptions configureOptions = new ConfigureOptions();
// Set the path to the OCR model
configureOptions.ModelPath = "F:\\OCR Model\\win-x64";
// Set the language for text recognition. (The default is English.)
configureOptions.Language = "English";
// Apply the configuration options to the scanner
scanner.ConfigureDependencies(configureOptions);
// Extract text from an image
scanner.Scan("invoice.png");
// Get the OCR result text
IOCRText text = scanner.Text;
// Create a list to store information
List<string> results = new List<string>();
// Iterate through each block of the OCR result text
foreach (IOCRTextBlock block in text.Blocks)
{
// Add the text of each block and its location information to the list
results.Add($"Block Text: {block.Text}");
results.Add($"Coordinates: {block.Box}");
results.Add("---------");
}
// Save the extracted text with coordinates to a txt file
File.WriteAllLines("ExtractWithCoordinates.txt", results);
}
}
}
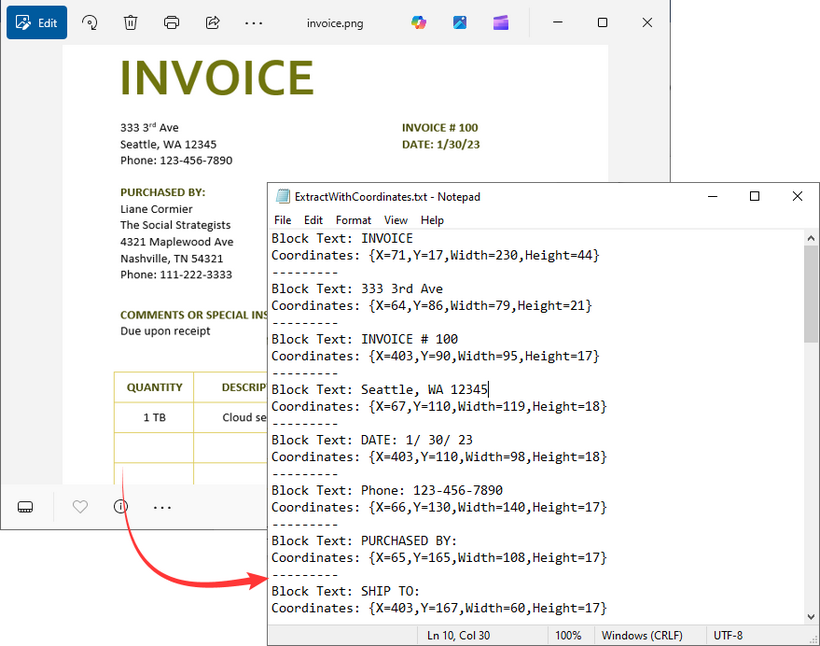
Critical Details
- IOCRText: Represents the entire OCR result.
- IOCRTextBlock: Represents a block of contiguous text (e.g., a paragraph, line, or word).
- IOCRTextBlock.Box: Contains the rectangular coordinates of the text block:
- X (horizontal position)
- Y (vertical position)
- Width
- Height
Output:
This C# code performs OCR on an image file (invoice.png), extracting both the recognized text and its position coordinates in the image, then saves this information to a text file (ExtractWithCoordinates.txt).
Tips to Optimize OCR Accuracy
To ensure reliable results when using C# to recognize text from images, consider these best practices:
- Use high-resolution images (300 DPI or higher).
- Preprocess images (e.g., resize, deskew) for better results.
- Ensure correct language settings correspond to the text in image.
- Store OCR models in a secure, accessible location.
FAQs (Supported Languages and Image Formats)
Q1: What image formats does Spire.OCR support?
A: Spire.OCR supports all common formats:
- PNG
- JPEG/JPG
- BMP
- TIFF
- GIF
Q2: What languages does Spire.OCR support?
A: Multiple languages are supported:
- English (default)
- Chinese (Simplified and Traditional)
- Japanese
- Korean
- German
- French
Q3: Can I use Spire.OCR in ASP.NET Core applications?
A: Yes. Supported environments:
- .NET Framework 2.0+
- .NET Standard 2.0+
- .NET Core 2.0+
- .NET 5
Q4: Can Spire.OCR extract text from scanned PDFs in C#?
A: The task requires the Spire.PDF integration to convert PDFs to images or extract images from scanned PDFs first, and then use the above C# examples to get text from the images.
Conclusion & Free License
Spire.OCR for .NET provides a powerful yet straightforward solution for extracting text from images in C# applications. Whether you’re building a simple tool to convert images to text or a complex system for processing thousands of invoices, by following the techniques and best practices outlined in this guide, you can integrate OCR functionality into your C# applications with ease.
Request a 30-day trial license here to get unlimited OCR capabilities and unlock valuable information trapped in visual format.
