
When working with PDF files in Java, it is often necessary to convert between binary data and text-based formats. Base64 encoding allows PDF content to be represented as plain text, which is useful when transmitting documents in JSON, sending them through form submissions, or storing them in text-based systems. Java’s standard library provides java.util.Base64, making it straightforward to implement both Base64 to PDF and PDF to Base64 conversions without additional dependencies.
In this tutorial, we will explore how to handle these conversions using only the JDK, as well as how to work with Base64 images and embed them into PDFs. For more advanced operations, such as editing a PDF received as Base64 and exporting it back, we will demonstrate the use of Free Spire.PDF for Java.
Table of Contents
- Convert Base64 to PDF in Java (JDK only)
- Convert PDF to Base64 in Java (JDK only)
- Validation & Safety Tips
- Save Base64 Images as PDF in Java
- Load Base64 PDF, Modify, and Save Back as Base64
- Performance & Memory Considerations
- FAQ
Convert Base64 to PDF in Java (JDK only)
The simplest approach is to read a Base64 string into memory, remove any optional prefixes (such as data:application/pdf;base64,), and then decode it into a PDF. This works well for small to medium files.
import java.nio.file.*;
import java.nio.charset.StandardCharsets;
import java.util.Base64;
public class Base64ToPdf {
public static void main(String[] args) throws Exception {
// Read Base64 text from a file (or any other source)
String base64 = Files.readString(Paths.get("sample.pdf.b64"), StandardCharsets.UTF_8);
// Remove common Data URI prefixes if present
base64 = stripDataPrefix(base64);
// Decode Base64 into raw PDF bytes
// MIME decoder tolerates line breaks and wrapped text
byte[] pdfBytes = Base64.getMimeDecoder().decode(base64);
// Write decoded bytes to a PDF file
Files.write(Paths.get("output.pdf"), pdfBytes);
}
/** Utility to strip "data:application/pdf;base64," if included */
private static String stripDataPrefix(String src) {
String s = src.trim();
int comma = s.indexOf(',');
if (comma > 0 && s.substring(0, comma).toLowerCase().contains("base64")) {
return s.substring(comma + 1).trim();
}
return s;
}
}
Explanation This example is straightforward and reliable for Base64 content that fits comfortably in memory. The Base64.getMimeDecoder() is chosen because it gracefully handles line breaks, which are common in Base64 text exported from email systems or APIs. If you know your Base64 string contains no newlines, you could also use Base64.getDecoder().
Make sure to strip out any Data URI prefix (data:application/pdf;base64,) before decoding, as it is not part of the Base64 payload. The helper method stripDataPrefix() does this automatically.
Streaming variant (no full string in memory)
For large PDFs, it’s better to process Base64 in a streaming fashion. This avoids loading the entire Base64 string into memory at once.
import java.io.*;
import java.nio.file.*;
import java.util.Base64;
public class Base64ToPdfStreamed {
public static void main(String[] args) throws Exception {
// Input: text file containing Base64-encoded PDF
Path in = Paths.get("sample.pdf.b64");
// Output: decoded PDF file
Path out = Paths.get("output.pdf");
// Wrap the Base64 decoder around the input stream
try (InputStream b64In = Base64.getMimeDecoder().wrap(Files.newInputStream(in));
OutputStream pdfOut = Files.newOutputStream(out)) {
// Stream decoded bytes directly to the PDF output
b64In.transferTo(pdfOut);
}
}
}
Explanation This streaming-based approach is more memory-efficient, as it decodes data on-the-fly rather than buffering the entire string. It is the recommended method for large files or continuous streams (e.g., network sockets).
- Base64.getMimeDecoder() is used to tolerate line breaks in the input.
- The transferTo() method efficiently copies decoded bytes from input to output without manual buffer handling.
- In real-world use, consider adding exception handling to manage file access errors or partial writes.
Convert PDF to Base64 in Java (JDK only)
Encoding a PDF into Base64 is just as simple. For smaller files, reading the entire PDF into memory is fine:
import java.nio.file.*;
import java.util.Base64;
public class PdfToBase64 {
public static void main(String[] args) throws Exception {
// Read the PDF file into a byte array
byte[] pdfBytes = Files.readAllBytes(Paths.get("input.pdf"));
// Encode the PDF bytes as a Base64 string
String base64 = Base64.getEncoder().encodeToString(pdfBytes);
// Write the Base64 string to a text file
Files.writeString(Paths.get("output.pdf.b64"), base64);
}
}
Explanation This approach is simple and works well for small or medium-sized files. The entire PDF is read into a byte array and encoded as a single Base64 string. This string can be stored, transmitted in JSON, or embedded in a Data URI.
Streaming encoder (handles large files efficiently)
For large PDFs, you can avoid memory overhead by encoding directly as a stream:
import java.io.*;
import java.nio.file.*;
import java.util.Base64;
public class PdfToBase64Streamed {
public static void main(String[] args) throws Exception {
// Input: binary PDF file
try (InputStream pdfIn = Files.newInputStream(Paths.get("input.pdf"));
// Raw output stream for Base64 text file
OutputStream rawOut = Files.newOutputStream(Paths.get("output.pdf.b64"));
// Wrap output stream with Base64 encoder
OutputStream b64Out = Base64.getEncoder().wrap(rawOut)) {
// Stream PDF bytes directly into Base64-encoded output
pdfIn.transferTo(b64Out);
}
}
}
Explanation The streaming encoder efficiently handles large files by encoding data incrementally instead of loading everything into memory. The Base64.getEncoder().wrap() method turns a regular output stream into one that writes Base64 text automatically.
This design scales better for large PDFs, network streams, or services that must handle many documents concurrently without running into memory pressure.
Validation & Safety Tips
- Detect Data URIs: Users may send data:application/pdf;base64, prefixes. Strip them before decoding.
- Line breaks: When decoding text that may contain wrapped lines (emails, logs), use Base64.getMimeDecoder().
- Quick sanity check: After decoding, the first bytes of a valid PDF usually start with %PDF-. You can assert this for early failure detection.
- Character encoding: Treat Base64 text as UTF-8 (or US-ASCII) when reading/writing .b64 files.
- Error handling: Wrap decode/encode in try/catch and surface actionable messages (e.g., size, header mismatch).
Save Base64 Images as PDF in Java
Sometimes you receive images (e.g., PNG or JPEG) as Base64 strings and need to wrap them into a PDF. While Java’s standard library doesn’t have PDF APIs, Free Spire.PDF for Java makes this straightforward.
You can download Free Spire.PDF for Java and add it to your project or install Free Spire.PDF for Java from Maven repository.
Key Spire.PDF concepts
- PdfDocument — the container for one or more PDF pages.
- PdfPageBase — represents a page you can draw on.
- PdfImage.fromImage() — load a BufferedImage or stream into a drawable PDF image.
- drawImage() — place the image at specified coordinates and size.
- Coordinate System — Spire.PDF uses a coordinate system where (0,0) is the top left corner.
Example: Convert Base64 image to PDF Using Java
import com.spire.pdf.PdfDocument;
import com.spire.pdf.PdfPageBase;
import com.spire.pdf.graphics.PdfImage;
import java.io.*;
import java.nio.charset.StandardCharsets;
import java.nio.file.*;
import java.util.Base64;
public class Base64ImageToPdf {
public static void main(String[] args) throws Exception {
// 1) Read Base64 file and decode (strip data URI prefix if exists)
String base64Image = Files.readString(Paths.get("G:/Document/image.b64"), StandardCharsets.UTF_8).trim();
int comma = base64Image.indexOf(',');
if (comma > 0 && base64Image.substring(0, comma).toLowerCase().contains("base64")) {
base64Image = base64Image.substring(comma + 1).trim();
}
byte[] imageBytes = Base64.getMimeDecoder().decode(base64Image);
// 2) Create PDF and insert the image
PdfDocument pdf = new PdfDocument();
try (ByteArrayInputStream in = new ByteArrayInputStream(imageBytes)) {
PdfImage img = PdfImage.fromStream(in);
pdf.getPageSettings().setWidth(img.getWidth());
pdf.getPageSettings().setHeight(img.getHeight());
pdf.getPageSettings().setMargins(0, 0, 0, 0);
PdfPageBase page = pdf.getPages().add();
page.getCanvas().drawImage(img, 0, 0);
}
// 3) Save PDF file
pdf.saveToFile("output/image.pdf");
}
}
The following example decodes a Base64 image and embeds it into a PDF page. The output looks like this:
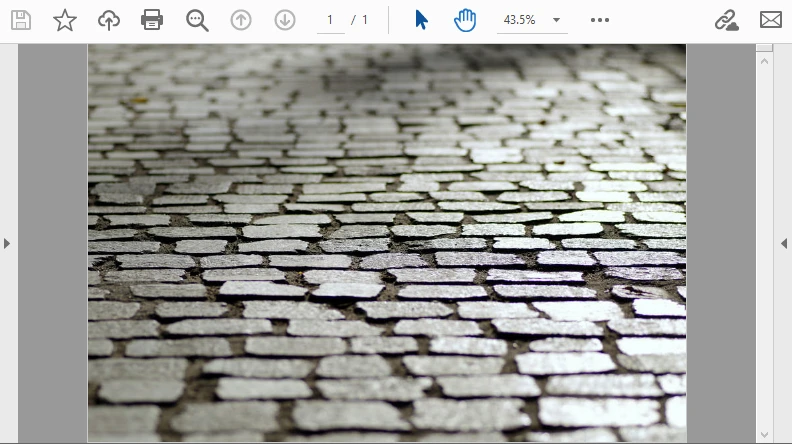
This workflow is ideal for embedding scanned documents or signatures that arrive as Base64.
For vector graphics, you may also check out our guide on Converting SVG to PDF in Java.
Load Base64 PDF, Modify, and Save Back as Base64
In many APIs, a PDF arrives as Base64. With Spire.PDF you can load it, draw on pages (text/watermarks), and return Base64 again—ideal for serverless functions or microservices.
Key Spire.PDF concepts used here
- PdfDocument.loadFromBytes(byte[]) — construct a document directly from decoded bytes.
- PdfPageBase#getCanvas() — obtain a drawing surface to place text, shapes, or images.
- Fonts & brushes — e.g., PdfTrueTypeFont or built-in fonts via PdfFont, with PdfSolidBrush for coloring.
- Saving to memory — pdf.saveToStream(ByteArrayOutputStream) yields raw bytes, which you can re-encode with Base64.
Example: Load, Modify, and Save Base64 PDF in Java
import com.spire.pdf.*;
import com.spire.pdf.graphics.*;
import java.awt.*;
import java.io.*;
import java.util.Base64;
public class EditBase64Pdf {
public static void main(String[] args) throws Exception {
String base64Pdf = "..."; // incoming Base64 PDF string
// Decode to bytes
byte[] pdfBytes = Base64.getDecoder().decode(base64Pdf);
// Load PDF
PdfDocument pdf = new PdfDocument();
pdf.loadFromBytes(pdfBytes);
// Add stamp on each page
for (PdfPageBase page : (Iterable<PdfPageBase>) pdf.getPages()) {
PdfTrueTypeFont font = new PdfTrueTypeFont(new Font("Arial", Font.BOLD, 36));
PdfSolidBrush brush = new PdfSolidBrush(new PdfRGBColor(Color.BLUE));
page.getCanvas().drawString("Processed", font, brush, 100, 100);
}
// Save to memory and encode back to Base64
ByteArrayOutputStream output = new ByteArrayOutputStream();
pdf.saveToStream(output);
pdf.close();
String resultBase64 = Base64.getEncoder().encodeToString(output.toByteArray());
System.out.println(resultBase64);
}
}
In this example, a blue ‘Processed’ watermark is added to each page of the PDF before re-encoding it back to Base64. The result looks like this:
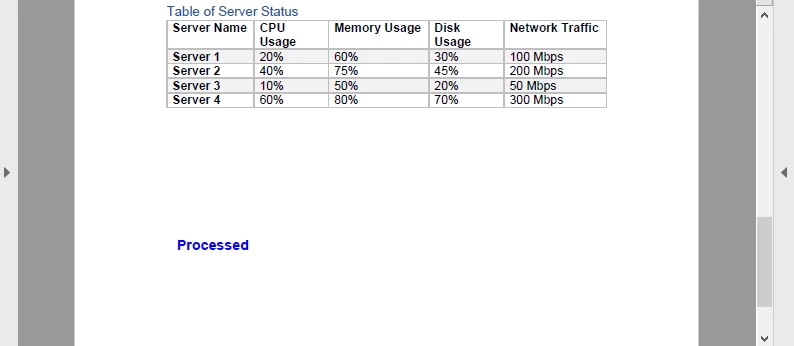
This round-trip (Base64 → PDF → Base64) is useful for document pipelines, such as stamping invoices or adding dynamic signatures in a cloud service.
Related tutorials:
Extract Text from PDF in Java | Create PDF Documents in Java
Performance & Memory Considerations
- Streaming vs. file I/O — when dealing with Base64, prefer ByteArrayInputStream and ByteArrayOutputStream to avoid unnecessary temp files.
- Image-heavy PDFs — decoding Base64 images can spike memory usage; consider scaling or compressing before embedding.
- Large PDFs — Spire.PDF handles multi-MB PDFs, but for very large documents consider page-by-page processing.
- Serverless functions — Base64 workflows fit well because you avoid filesystem dependency and return results directly via API responses.
FAQ
Q: Can I convert Base64 to PDF using only JDK?
Yes. Java SE provides Base64 and file I/O utilities, so you can handle conversion without extra libraries.
Q: Can I edit PDF with standard Java library?
No. Java SE doesn’t support PDF structure parsing or rendering. For editing, use a dedicated library such as Spire.PDF for Java.
Q: Is Free Spire.PDF for Java enough?
Yes. The Free Spire.PDF for Java is limited in document size, but sufficient for testing or small-scale projects.
Q: Do I need to save PDFs to disk?
Not always. Conversion can also run in-memory using streams, which is often preferred for APIs and cloud apps.