
Lorsque l'on travaille avec des fichiers PDF en Java, il est souvent nécessaire de convertir entre des données binaires et des formats textuels. L'encodage Base64 permet de représenter le contenu d'un PDF sous forme de texte brut, ce qui est utile lors de la transmission de documents en JSON, de leur envoi via des soumissions de formulaires ou de leur stockage dans des systèmes basés sur du texte. La bibliothèque standard de Java fournit java.util.Base64, ce qui facilite la mise en œuvre des conversions Base64 vers PDF et PDF vers Base64 sans dépendances supplémentaires.
Dans ce tutoriel, nous explorerons comment gérer ces conversions en utilisant uniquement le JDK, ainsi que comment travailler avec des images Base64 et les intégrer dans des PDF. Pour des opérations plus avancées, telles que la modification d'un PDF reçu en Base64 et son réexportation, nous démontrerons l'utilisation de Free Spire.PDF for Java.
Table des matières
- Convertir Base64 en PDF en Java (JDK uniquement)
- Convertir PDF en Base64 en Java (JDK uniquement)
- Conseils de validation et de sécurité
- Enregistrer des images Base64 en PDF en Java
- Charger un PDF Base64, le modifier et le réenregistrer en Base64
- Considérations sur les performances et la mémoire
- FAQ
Convertir Base64 en PDF en Java (JDK uniquement)
L'approche la plus simple consiste à lire une chaîne Base64 en mémoire, à supprimer les préfixes facultatifs (tels que data:application/pdf;base64,), puis à la décoder en PDF. Cela fonctionne bien pour les fichiers de petite à moyenne taille.
import java.nio.file.*;
import java.nio.charset.StandardCharsets;
import java.util.Base64;
public class Base64ToPdf {
public static void main(String[] args) throws Exception {
// Lire le texte Base64 d'un fichier (ou de toute autre source)
String base64 = Files.readString(Paths.get("sample.pdf.b64"), StandardCharsets.UTF_8);
// Supprimer les préfixes d'URI de données courants s'ils sont présents
base64 = stripDataPrefix(base64);
// Décoder le Base64 en octets PDF bruts
// Le décodeur MIME tolère les sauts de ligne et le texte enveloppé
byte[] pdfBytes = Base64.getMimeDecoder().decode(base64);
// Écrire les octets décodés dans un fichier PDF
Files.write(Paths.get("output.pdf"), pdfBytes);
}
/** Utilitaire pour supprimer le préfixe "data:application/pdf;base64,", s'il est inclus */
private static String stripDataPrefix(String src) {
String s = src.trim();
int comma = s.indexOf(',');
if (comma > 0 && s.substring(0, comma).toLowerCase().contains("base64")) {
return s.substring(comma + 1).trim();
}
return s;
}
}
Explication Cet exemple est simple et fiable pour le contenu Base64 qui tient confortablement en mémoire. Le Base64.getMimeDecoder() est choisi car il gère avec élégance les sauts de ligne, qui sont courants dans le texte Base64 exporté depuis des systèmes de messagerie ou des API. Si vous savez que votre chaîne Base64 ne contient aucun saut de ligne, vous pouvez également utiliser Base64.getDecoder().
Assurez-vous de supprimer tout préfixe d'URI de données (data:application/pdf;base64,) avant de décoder, car il ne fait pas partie de la charge utile Base64. La méthode d'aide stripDataPrefix() le fait automatiquement.
Variante en streaming (pas de chaîne complète en mémoire)
Pour les gros PDF, il est préférable de traiter le Base64 en mode streaming. Cela évite de charger toute la chaîne Base64 en mémoire en une seule fois.
import java.io.*;
import java.nio.file.*;
import java.util.Base64;
public class Base64ToPdfStreamed {
public static void main(String[] args) throws Exception {
// Entrée : fichier texte contenant un PDF encodé en Base64
Path in = Paths.get("sample.pdf.b64");
// Sortie : fichier PDF décodé
Path out = Paths.get("output.pdf");
// Envelopper le décodeur Base64 autour du flux d'entrée
try (InputStream b64In = Base64.getMimeDecoder().wrap(Files.newInputStream(in));
OutputStream pdfOut = Files.newOutputStream(out)) {
// Transférer les octets décodés directement vers la sortie PDF
b64In.transferTo(pdfOut);
}
}
}
Explication Cette approche basée sur le streaming est plus efficace en termes de mémoire, car elle décode les données à la volée plutôt que de mettre en mémoire tampon la chaîne entière. C'est la méthode recommandée pour les fichiers volumineux ou les flux continus (par exemple, les sockets réseau).
- Base64.getMimeDecoder() est utilisé pour tolérer les sauts de ligne dans l'entrée.
- La méthode transferTo() copie efficacement les octets décodés de l'entrée vers la sortie sans gestion manuelle de la mémoire tampon.
- Dans un cas d'utilisation réel, envisagez d'ajouter une gestion des exceptions pour gérer les erreurs d'accès aux fichiers ou les écritures partielles.
Convertir PDF en Base64 en Java (JDK uniquement)
Encoder un PDF en Base64 est tout aussi simple. Pour les fichiers plus petits, lire l'intégralité du PDF en mémoire convient parfaitement :
import java.nio.file.*;
import java.util.Base64;
public class PdfToBase64 {
public static void main(String[] args) throws Exception {
// Lire le fichier PDF dans un tableau d'octets
byte[] pdfBytes = Files.readAllBytes(Paths.get("input.pdf"));
// Encoder les octets du PDF en une chaîne Base64
String base64 = Base64.getEncoder().encodeToString(pdfBytes);
// Écrire la chaîne Base64 dans un fichier texte
Files.writeString(Paths.get("output.pdf.b64"), base64);
}
}
Explication Cette approche est simple et fonctionne bien pour les fichiers de petite ou moyenne taille. L'intégralité du fichier PDF est lue dans un tableau d'octets et encodée en une seule chaîne Base64. Cette chaîne peut être stockée, transmise en JSON ou intégrée dans une URI de données.
Encodeur en streaming (gère efficacement les gros fichiers)
Pour les gros PDF, vous pouvez éviter la surcharge de mémoire en encodant directement en tant que flux :
import java.io.*;
import java.nio.file.*;
import java.util.Base64;
public class PdfToBase64Streamed {
public static void main(String[] args) throws Exception {
// Entrée : fichier PDF binaire
try (InputStream pdfIn = Files.newInputStream(Paths.get("input.pdf"));
// Flux de sortie brut pour le fichier texte Base64
OutputStream rawOut = Files.newOutputStream(Paths.get("output.pdf.b64"));
// Envelopper le flux de sortie avec l'encodeur Base64
OutputStream b64Out = Base64.getEncoder().wrap(rawOut)) {
// Transférer les octets du PDF directement dans la sortie encodée en Base64
pdfIn.transferTo(b64Out);
}
}
}
Explication L'encodeur en streaming gère efficacement les fichiers volumineux en encodant les données de manière incrémentielle au lieu de tout charger en mémoire. La méthode Base64.getEncoder().wrap() transforme un flux de sortie ordinaire en un flux qui écrit automatiquement du texte Base64.
Cette conception s'adapte mieux aux PDF volumineux, aux flux réseau ou aux services qui doivent gérer de nombreux documents simultanément sans subir de pression sur la mémoire.
Conseils de validation et de sécurité
- Détecter les URI de données : les utilisateurs peuvent envoyer des préfixes data:application/pdf;base64,. Supprimez-les avant de décoder.
- Sauts de ligne : lors du décodage de texte pouvant contenir des lignes enveloppées (e-mails, journaux), utilisez Base64.getMimeDecoder().
- Vérification rapide : après le décodage, les premiers octets d'un PDF valide commencent généralement par %PDF-. Vous pouvez l'affirmer pour une détection précoce des défaillances.
- Encodage des caractères : traitez le texte Base64 en UTF-8 (ou US-ASCII) lors de la lecture/écriture de fichiers .b64.
- Gestion des erreurs : enveloppez le décodage/encodage dans des blocs try/catch et affichez des messages exploitables (par exemple, taille, discordance d'en-tête).
Enregistrer des images Base64 en PDF en Java
Parfois, vous recevez des images (par exemple, PNG ou JPEG) sous forme de chaînes Base64 et vous devez les encapsuler dans un PDF. Bien que la bibliothèque standard de Java ne dispose pas d'API PDF, Free Spire.PDF for Java rend cela simple.
Vous pouvez télécharger Free Spire.PDF for Java et l'ajouter à votre projet ou installer Free Spire.PDF for Java depuis le référentiel Maven.
Concepts clés de Spire.PDF
- PdfDocument — le conteneur pour une ou plusieurs pages PDF.
- PdfPageBase — représente une page sur laquelle vous pouvez dessiner.
- PdfImage.fromImage() — charge une BufferedImage ou un flux dans une image PDF dessinable.
- drawImage() — place l'image aux coordonnées et à la taille spécifiées.
- Système de coordonnées — Spire.PDF utilise un système de coordonnées où (0,0) est le coin supérieur gauche.
Exemple : Convertir une image Base64 en PDF en utilisant Java
import com.spire.pdf.PdfDocument;
import com.spire.pdf.PdfPageBase;
import com.spire.pdf.graphics.PdfImage;
import java.io.*;
import java.nio.charset.StandardCharsets;
import java.nio.file.*;
import java.util.Base64;
public class Base64ImageToPdf {
public static void main(String[] args) throws Exception {
// 1) Lire le fichier Base64 et décoder (supprimer le préfixe de l'URI de données s'il existe)
String base64Image = Files.readString(Paths.get("G:/Document/image.b64"), StandardCharsets.UTF_8).trim();
int comma = base64Image.indexOf(',');
if (comma > 0 && base64Image.substring(0, comma).toLowerCase().contains("base64")) {
base64Image = base64Image.substring(comma + 1).trim();
}
byte[] imageBytes = Base64.getMimeDecoder().decode(base64Image);
// 2) Créer un PDF et y insérer l'image
PdfDocument pdf = new PdfDocument();
try (ByteArrayInputStream in = new ByteArrayInputStream(imageBytes)) {
PdfImage img = PdfImage.fromStream(in);
pdf.getPageSettings().setWidth(img.getWidth());
pdf.getPageSettings().setHeight(img.getHeight());
pdf.getPageSettings().setMargins(0, 0, 0, 0);
PdfPageBase page = pdf.getPages().add();
page.getCanvas().drawImage(img, 0, 0);
}
// 3) Enregistrer le fichier PDF
pdf.saveToFile("output/image.pdf");
}
}
L'exemple suivant décode une image Base64 et l'intègre dans une page PDF. La sortie ressemble à ceci :
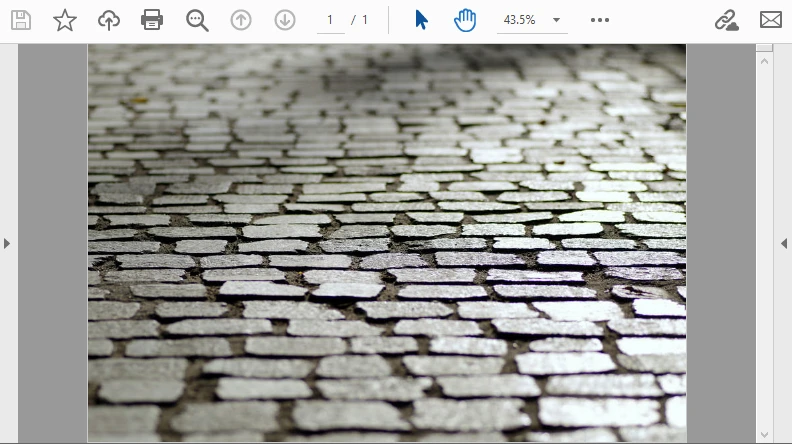
Ce flux de travail est idéal pour intégrer des documents numérisés ou des signatures qui arrivent en Base64.
Pour les graphiques vectoriels, vous pouvez également consulter notre guide sur la conversion de SVG en PDF en Java.
Charger un PDF Base64, le modifier et le réenregistrer en Base64
Dans de nombreuses API, un PDF arrive en Base64. Avec Spire.PDF, vous pouvez le charger, dessiner sur les pages (texte/filigranes) et renvoyer à nouveau du Base64 — idéal pour les fonctions sans serveur ou les microservices.
Concepts clés de Spire.PDF utilisés ici
- PdfDocument.loadFromBytes(byte[]) — construit un document directement à partir d'octets décodés.
- PdfPageBase#getCanvas() — obtient une surface de dessin pour placer du texte, des formes ou des images.
- Polices et pinceaux — par ex., PdfTrueTypeFont ou polices intégrées via PdfFont, avec PdfSolidBrush pour la coloration.
- Enregistrement en mémoire — pdf.saveToStream(ByteArrayOutputStream) produit des octets bruts, que vous pouvez réencoder avec Base64.
Exemple : Charger, modifier et enregistrer un PDF Base64 en Java
import com.spire.pdf.*;
import com.spire.pdf.graphics.*;
import java.awt.*;
import java.io.*;
import java.util.Base64;
public class EditBase64Pdf {
public static void main(String[] args) throws Exception {
String base64Pdf = "..."; // chaîne PDF en Base64 entrante
// Décoder en octets
byte[] pdfBytes = Base64.getDecoder().decode(base64Pdf);
// Charger le PDF
PdfDocument pdf = new PdfDocument();
pdf.loadFromBytes(pdfBytes);
// Ajouter un tampon sur chaque page
for (PdfPageBase page : (Iterable) pdf.getPages()) {
PdfTrueTypeFont font = new PdfTrueTypeFont(new Font("Arial", Font.BOLD, 36));
PdfSolidBrush brush = new PdfSolidBrush(new PdfRGBColor(Color.BLUE));
page.getCanvas().drawString("Processed", font, brush, 100, 100);
}
// Enregistrer en mémoire et réencoder en Base64
ByteArrayOutputStream output = new ByteArrayOutputStream();
pdf.saveToStream(output);
pdf.close();
String resultBase64 = Base64.getEncoder().encodeToString(output.toByteArray());
System.out.println(resultBase64);
}
}
Dans cet exemple, un filigrane bleu « Processed » est ajouté à chaque page du PDF avant de le réencoder en Base64. Le résultat ressemble à ceci :
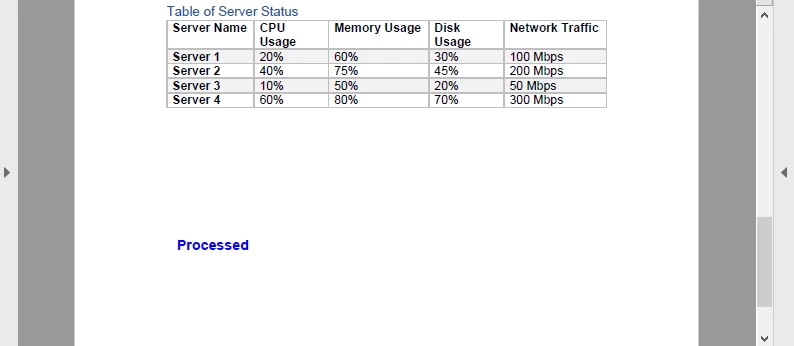
Ce cycle (Base64 → PDF → Base64) est utile pour les pipelines de documents, tels que l'estampillage de factures ou l'ajout de signatures dynamiques dans un service cloud.
Tutoriels associés :
Extraire du texte d'un PDF en Java | Créer des documents PDF en Java
Considérations sur les performances et la mémoire
- Streaming vs. E/S de fichiers — lors du traitement de Base64, préférez ByteArrayInputStream et ByteArrayOutputStream pour éviter les fichiers temporaires inutiles.
- PDF riches en images — le décodage d'images Base64 peut augmenter considérablement l'utilisation de la mémoire ; envisagez de les redimensionner ou de les compresser avant de les intégrer.
- Gros PDF — Spire.PDF gère les PDF de plusieurs Mo, mais pour les documents très volumineux, envisagez un traitement page par page.
- Fonctions sans serveur — les flux de travail Base64 s'intègrent bien car vous évitez la dépendance au système de fichiers et renvoyez les résultats directement via les réponses de l'API.
FAQ
Q : Puis-je convertir Base64 en PDF en utilisant uniquement le JDK ?
Oui. Java SE fournit des utilitaires Base64 et d'E/S de fichiers, vous pouvez donc gérer la conversion sans bibliothèques supplémentaires.
Q : Puis-je modifier un PDF avec la bibliothèque standard de Java ?
Non. Java SE ne prend pas en charge l'analyse de la structure ou le rendu des PDF. Pour l'édition, utilisez une bibliothèque dédiée telle que Spire.PDF for Java.
Q : Free Spire.PDF for Java est-il suffisant ?
Oui. La version gratuite de Spire.PDF for Java est limitée en taille de document, mais suffisante pour les tests ou les projets à petite échelle.
Q : Dois-je enregistrer les PDF sur le disque ?
Pas toujours. La conversion peut également s'exécuter en mémoire à l'aide de flux, ce qui est souvent préférable pour les API et les applications cloud.