How to Convert Word to JSON in Python (DOCX to JSON)

Converting Word documents to JSON is a common requirement when building automated document processing pipelines, feeding content into AI models, or migrating structured data from DOCX files into databases and APIs. Unlike CSV or XML, JSON provides a flexible, hierarchical format that can represent paragraphs, tables, and nested document structures in a single output.
However, Word files do not have a native JSON export format. A .docx file is a rich-text document composed of sections, paragraphs, styles, and tables—not a structured data source. Converting it to JSON requires deciding how to map that content into a meaningful schema.
This tutorial demonstrates how to convert Word to JSON in Python using Spire.Doc for Python. You will learn three progressively advanced methods: extracting plain paragraph text, converting Word tables to JSON arrays, and preserving the full document structure—including headings, paragraphs, and tables—in a hierarchical JSON output. The examples in this tutorial work with both DOCX and legacy DOC files supported by Spire.Doc.
Quick Navigation
- How Is Word Converted into JSON?
- Install the Required Library
- Method 1 – Convert Word Text to JSON
- Method 2 – Convert Word Tables to JSON
- Method 3 – Preserve Document Structure in JSON
- When to Use Word to JSON Conversion
- Limitations and Best Practices
- FAQ
- Conclusion
1. How Is Word Converted into JSON?
A Word document is a rich-text format organized into sections, paragraphs, and tables—not a structured data format. When you convert Word to JSON, there is no single standard for how the content should be represented. The right schema depends on how the JSON will be used:
| Goal | Recommended Schema | Key Characteristics |
|---|---|---|
| AI embedding / semantic search | Paragraph array | Flat list of text strings, one per paragraph |
| Full-text search indexing | Text blocks with metadata | Paragraphs with section index and style info |
| Database import from tables | Table row objects | Header-keyed dictionaries, one per row |
| RAG pipeline / knowledge base | Hierarchical structure | Nested sections with headings, paragraphs, and tables |
| Document archival / interchange | Full document model | Sections, styles, metadata, and all content types |
For example, a Word document containing a heading and a paragraph could be represented in JSON as:
{
"document": [
{"type": "heading", "level": 1, "text": "Project Overview"},
{"type": "paragraph", "text": "This report summarizes the quarterly results."}
]
}
The three methods in this tutorial correspond directly to these schema choices:
- Method 1 produces a paragraph array (AI embedding, search indexing)
- Method 2 produces table row objects (database import, data extraction)
- Method 3 produces a hierarchical structure (RAG, knowledge base, document understanding)
Choose the method that matches your goal, or combine elements from multiple methods to build a custom schema.
2. Install the Required Library
This tutorial uses Spire.Doc for Python to read and parse DOC/DOCX files. Install it via pip:
pip install spire.doc
Alternatively, you can download Spire.Doc for Python and integrate it manually.
After installation, import the library in your Python script:
from spire.doc import Document, FileFormat
from spire.doc.common import *
Spire.Doc provides APIs to load Word documents, iterate through sections, paragraphs, and tables, and extract text content—everything needed to build a Word-to-JSON pipeline.
3. Method 1 – Convert Word Text to JSON
The simplest way to convert Word to JSON is to extract all paragraph text from the document and store it in a JSON array. This approach works well when you need the full text content without structural metadata—such as for full-text search, AI text embedding, or simple content export.
3.1 Read Paragraphs from a Word Document
Spire.Doc represents a Word document as a collection of Sections, each containing Paragraphs. To extract all text, you iterate through every section and every paragraph within it.
from spire.doc import Document
from spire.doc.common import *
input_file = "ProjectReport.docx"
document = Document()
document.LoadFromFile(input_file)
paragraphs = []
for i in range(document.Sections.Count):
section = document.Sections.get_Item(i)
for j in range(section.Paragraphs.Count):
paragraph = section.Paragraphs.get_Item(j)
text = paragraph.Text
if text.strip():
paragraphs.append(text)
document.Close()
Each paragraph's .Text property returns the plain text content, stripping away formatting. The if text.strip() check filters out empty paragraphs that exist as spacing or layout elements in Word.
3.2 Serialize the Extracted Text to JSON
Assuming the paragraph data extracted in the previous step is stored in the paragraphs list, you can serialize it to JSON and save it to a file as follows:
import json
output_file = "paragraphs.json"
result = {
"source": input_file,
"paragraph_count": len(paragraphs),
"paragraphs": paragraphs
}
with open(output_file, "w", encoding="utf-8") as f:
json.dump(result, f, indent=2, ensure_ascii=False)
Output Example
The following JSON snippet shows the structure of the generated output file:
{
"source": "ProjectReport.docx",
"paragraph_count": 3,
"paragraphs": [
"Quarterly Sales Report",
"This document provides an overview of sales performance across all regions."
]
}
Conversion Result
The image below shows the source Word document and the JSON file generated after extracting paragraph text.
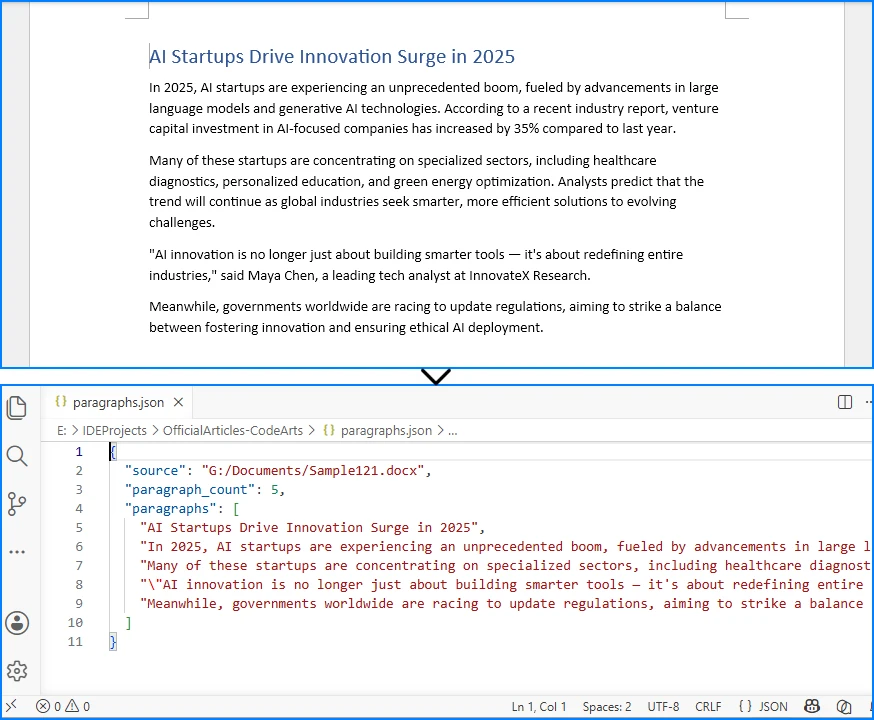
3.3 Explanation
Why iterate through Sections and Paragraphs instead of extracting all text at once? Because Word documents are organized hierarchically. A document contains one or more sections (each with its own page layout), and each section contains paragraphs. Iterating at this level gives you control over which content to include or skip—such as filtering empty paragraphs or limiting extraction to specific sections.
Storing paragraphs as a JSON array is the most straightforward structure. Each element is a string, making the output easy to consume in downstream systems. This approach is well-suited for:
- Full-text indexing – feed paragraph text into search engines like Elasticsearch
- AI text embedding – convert paragraphs into vector representations for semantic search
- Simple content export – extract readable text from Word files without formatting
However, this method loses structural information. Headings, body text, and list items are all treated the same way. If you need to distinguish between them, see Method 3.
If your goal is simply to extract text content from Word documents without converting it to JSON, you may also be interested in our guide on extracting text from Word documents in Python.
4. Method 2 – Convert Word Tables to JSON
In many Word documents—reports, invoices, product lists, configuration tables—the most valuable content lives inside tables, not in paragraphs. Converting Word tables to JSON allows you to extract structured row-and-column data that can be directly loaded into databases, APIs, or data analysis tools.
Why Tables Need Special Handling
Tables in Word are stored as a grid of rows and cells, where each cell contains its own paragraphs. Unlike paragraph text, table data has an inherent two-dimensional structure that maps naturally to JSON objects. The first row often contains column headers, and subsequent rows contain data records.
Extracting Tables from a Word Document
The following code reads all tables from a Word document, uses the first row as column headers, and converts each subsequent row into a JSON object:
import json
from spire.doc import Document
from spire.doc.common import *
input_file = "SalesData.docx"
output_file = "tables.json"
document = Document()
document.LoadFromFile(input_file)
all_tables = []
for i in range(document.Sections.Count):
section = document.Sections.get_Item(i)
for t in range(section.Tables.Count):
table = section.Tables.get_Item(t)
rows_data = []
if table.Rows.Count < 2:
continue
header_row = table.Rows[0]
headers = []
for c in range(header_row.Cells.Count):
cell_text = header_row.Cells[c].Paragraphs[0].Text.strip()
headers.append(cell_text)
for r in range(1, table.Rows.Count):
row = table.Rows[r]
row_dict = {}
for c in range(row.Cells.Count):
cell_text = row.Cells[c].Paragraphs[0].Text.strip()
row_dict[headers[c] if c < len(headers) else f"Column_{c}"] = cell_text
rows_data.append(row_dict)
all_tables.append({
"table_index": t,
"headers": headers,
"row_count": len(rows_data),
"rows": rows_data
})
document.Close()
result = {
"source": input_file,
"table_count": len(all_tables),
"tables": all_tables
}
with open(output_file, "w", encoding="utf-8") as f:
json.dump(result, f, indent=2, ensure_ascii=False)
Output Example
The following JSON snippet shows the structure of the generated output file, with each table row mapped to a JSON object using the header row as keys:
{
"source": "SalesData.docx",
"table_count": 1,
"tables": [
{
"table_index": 0,
"headers": ["Region", "Product", "Units Sold", "Revenue"],
"row_count": 3,
"rows": [
{"Region": "North", "Product": "Laptop", "Units Sold": "120", "Revenue": "114000"},
{"Region": "South", "Product": "Laptop", "Units Sold": "80", "Revenue": "76000"}
]
}
]
}
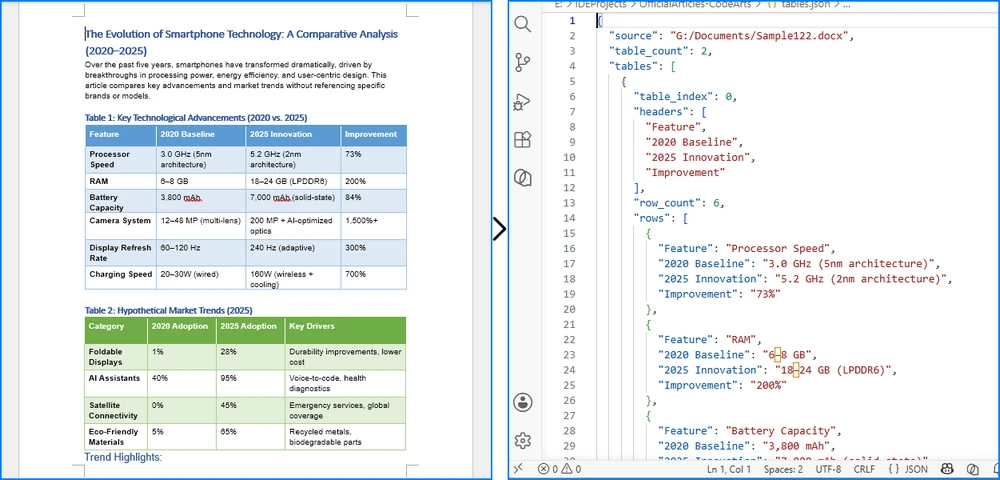
Conversion Result
The image below demonstrates how table data from a Word document is converted into structured JSON records.
Explanation
The code treats the first row as a header row and maps each cell in subsequent rows to the corresponding header key. This produces a JSON array of objects, which is the most common and useful format for tabular data.
Key considerations:
table.Rows.Count < 2skips tables that have only a header row or are emptyrow.Cells[c].Paragraphs[0].Textextracts text from the first paragraph in each cell. For simplicity, the example reads only the first paragraph. If a cell contains multiple paragraphs, iterate through the entireParagraphscollection and concatenate the results:
cell_text = "\n".join(
row.Cells[c].Paragraphs[p].Text.strip()
for p in range(row.Cells[c].Paragraphs.Count)
if row.Cells[c].Paragraphs[p].Text.strip()
)
headers[c] if c < len(headers) else f"Column_{c}"handles cases where a data row has more cells than the header row
This method is ideal for extracting structured data from reports, invoices, product catalogs, and configuration tables stored in Word documents. The resulting JSON can be directly loaded into databases, used in web APIs, or processed by data analysis tools.
If you need to generate Word documents from structured JSON data, see our tutorial on converting JSON to Word in Python, which covers creating Word content and tables directly from JSON objects and arrays.
5. Method 3 – Preserve Document Structure in JSON
Methods 1 and 2 treat paragraphs and tables as separate, isolated elements. In practice, Word documents have a meaningful hierarchy: headings introduce sections, paragraphs provide detail, and tables present structured data within a specific context.
Preserving this hierarchy in JSON produces output that is far more useful for knowledge base construction, RAG (Retrieval-Augmented Generation) pipelines, and document understanding systems. Instead of a flat list of text, you get a structured representation that maintains the logical flow of the original document.
How to Preserve Headings, Paragraphs, and Tables in a Hierarchical JSON Structure
The approach is to iterate through all child objects in each section's body, determine the type of each object (paragraph or table), and build a structured JSON representation accordingly. For paragraphs, you can detect headings by checking the StyleName property.
import json
from spire.doc import Document
from spire.doc.common import *
input_file = "ProjectReport.docx"
output_file = "structured_output.json"
HEADING_STYLES = {
"Heading1": 1,
"Heading2": 2,
"Heading3": 3,
"Heading4": 4,
}
def get_heading_level(style_name):
return HEADING_STYLES.get(style_name, None)
def extract_table_data(table):
rows_data = []
if table.Rows.Count < 1:
return {"headers": [], "rows": []}
header_row = table.Rows[0]
headers = []
for c in range(header_row.Cells.Count):
headers.append(header_row.Cells[c].Paragraphs[0].Text.strip())
for r in range(1, table.Rows.Count):
row = table.Rows[r]
row_dict = {}
for c in range(row.Cells.Count):
cell_text = row.Cells[c].Paragraphs[0].Text.strip()
row_dict[headers[c] if c < len(headers) else f"Column_{c}"] = cell_text
rows_data.append(row_dict)
return {"headers": headers, "rows": rows_data}
document = Document()
document.LoadFromFile(input_file)
sections_data = []
for i in range(document.Sections.Count):
section = document.Sections.get_Item(i)
content_items = []
for j in range(section.Body.ChildObjects.Count):
obj = section.Body.ChildObjects.get_Item(j)
if isinstance(obj, Paragraph):
text = obj.Text.strip()
if not text:
continue
heading_level = get_heading_level(obj.StyleName)
if heading_level:
content_items.append({
"type": "heading",
"level": heading_level,
"text": text
})
else:
content_items.append({
"type": "paragraph",
"text": text
})
elif isinstance(obj, Table):
table_data = extract_table_data(obj)
content_items.append({
"type": "table",
"row_count": len(table_data["rows"]),
"data": table_data
})
sections_data.append({
"section_index": i,
"content": content_items
})
document.Close()
result = {
"source": input_file,
"section_count": len(sections_data),
"sections": sections_data
}
with open(output_file, "w", encoding="utf-8") as f:
json.dump(result, f, indent=2, ensure_ascii=False)
Output Example
The following JSON snippet shows how headings, paragraphs, and tables are represented in the hierarchical output structure:
{
"source": "ProjectReport.docx",
"section_count": 1,
"sections": [
{
"section_index": 0,
"content": [
{
"type": "heading",
"level": 1,
"text": "Quarterly Sales Report"
},
{
"type": "paragraph",
"text": "This report provides an overview of sales performance across all regions."
},
{
"type": "heading",
"level": 2,
"text": "Regional Breakdown"
},
{
"type": "table",
"row_count": 3,
"data": {
"headers": ["Region", "Product", "Units Sold", "Revenue"],
"rows": [
{"Region": "North", "Product": "Laptop", "Units Sold": "120", "Revenue": "114000"}
]
}
}
]
}
]
}
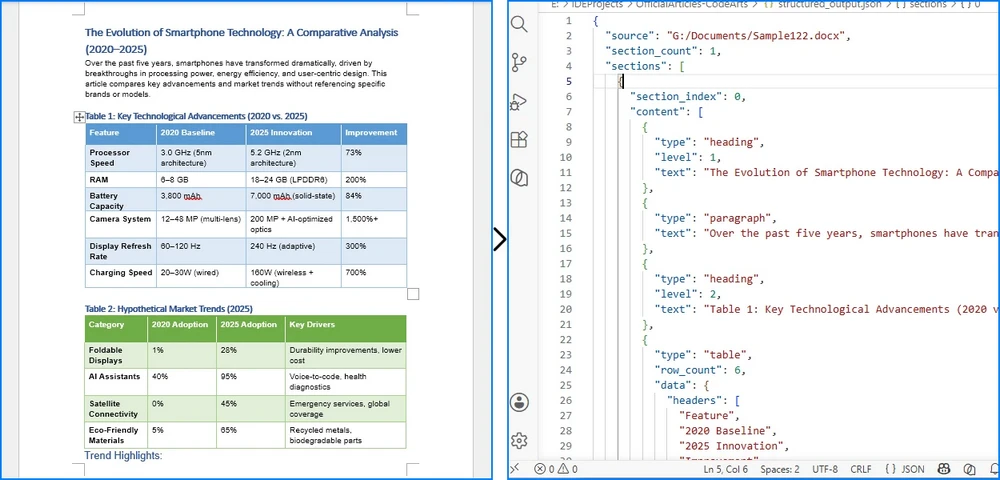
Conversion Result
The image below illustrates how headings, paragraphs, and tables are preserved in a hierarchical JSON structure.
Explanation
This method differs from the previous two in a fundamental way: it uses section.Body.ChildObjects to iterate through all content elements in document order, rather than separately iterating paragraphs and tables. This preserves the original sequence and interleaving of headings, paragraphs, and tables.
Key design decisions:
- Heading detection via
StyleName– Word headings are paragraphs styled with "Heading1", "Heading2", etc. Checking the style name allows you to distinguish headings from body text and record the heading level. Note that the exact heading style names may vary depending on the Word template or language settings (e.g., "Heading 1" with a space, or localized names like "标题 1" in Chinese). To handle these variations, normalize the style name before lookup:
def get_heading_level(style_name):
normalized = style_name.lower().replace(" ", "")
heading_map = {"heading1": 1, "heading2": 2, "heading3": 3, "heading4": 4}
return heading_map.get(normalized, None)
ChildObjectsiteration – Unlikesection.Paragraphs(which only returns paragraphs) orsection.Tables(which only returns tables),ChildObjectsreturns all elements in their original order. This is essential for preserving the document's logical structure.- Structured JSON output – Each content item includes a
typefield (heading,paragraph, ortable), making it easy for downstream systems to process different content types appropriately.
This approach is particularly valuable for:
- RAG and AI pipelines – the heading structure enables chunking documents by section, improving retrieval accuracy
- Knowledge base construction – hierarchical JSON maps directly to tree-structured knowledge graphs
- Document understanding – preserving the relationship between headings and their associated content allows semantic analysis of document sections
If you need to extract specific content types from Word documents, such as headings, paragraphs, or tables, see our tutorial on reading Word documents in Python, which covers content extraction techniques in more detail.
6. When to Use Word to JSON Conversion
Word to JSON conversion is useful in any scenario where structured data needs to be extracted from Word documents at scale. Common use cases include:
- AI and RAG document processing – Convert Word documents into JSON chunks for embedding and retrieval in LLM-based applications. The hierarchical structure from Method 3 enables section-level chunking, which produces better retrieval results than flat text splitting.
- Knowledge base construction – Build structured knowledge bases from technical documentation, policy documents, or manuals stored as .docx files.
- Batch data extraction – Extract data from hundreds of Word reports, invoices, or forms and load the results into a database or data warehouse.
- Contract and resume parsing – Convert legal contracts, HR documents, or resumes into structured JSON for automated analysis and comparison.
- API and web application data exchange – Serve Word document content through REST APIs as JSON, enabling web and mobile applications to consume document data without handling .docx files directly.
7. Limitations and Best Practices
Limitations
- No standard JSON schema for Word – Unlike CSV or XML, there is no universally accepted format for representing Word content in JSON. The structure you choose must be designed for your specific use case.
- Complex formatting is not captured – The methods in this tutorial extract text content and basic structural metadata (heading levels, table data). They do not capture fonts, colors, images, page layout, headers/footers, or footnotes. If your application requires these elements, additional extraction logic is needed.
- Merged table cells require special handling – Word tables can contain merged cells (both horizontal and vertical). The simple row-by-row extraction in Method 2 assumes a regular grid. Documents with merged cells may produce unexpected results.
- Large documents may need chunked processing – For documents with hundreds of pages or dozens of tables, consider processing sections or tables individually to manage memory usage.
Best Practices
- Design your JSON schema before writing code – Decide what you need (text only? headings? tables? full structure?) and choose the appropriate extraction method.
- Validate output against sample documents – Word documents vary widely in structure and formatting. Test your conversion logic against representative samples from your actual document set.
- Handle encoding explicitly – Always specify
encoding="utf-8"when writing JSON files to avoid character encoding issues with non-ASCII text. - Use
ensure_ascii=Falseinjson.dump– This preserves Unicode characters in the output rather than escaping them, which is important for documents containing non-English text.
8. FAQ
Can I convert DOCX to JSON in Python?
Yes. Using Spire.Doc for Python, you can load any .docx file, iterate through its sections, paragraphs, and tables, and serialize the extracted content to JSON using Python's built-in json module. This tutorial demonstrates three methods for doing so, from simple text extraction to full structural preservation.
What is the best Word to JSON converter for developers?
For developers who need batch processing, automation, or custom JSON schemas, a Python-based approach using Spire.Doc is more flexible than online converters. Online tools work for one-off conversions but cannot handle large-scale processing, custom output formats, or integration into automated pipelines.
Can I convert Word tables to JSON?
Yes. By iterating through the tables in a Word document and extracting cell text row by row, you can convert table data into a JSON array of objects. Method 2 in this tutorial demonstrates this with header-based key mapping.
Does Word have a native JSON export option?
No. Microsoft Word does not provide a built-in JSON export format. Word files can be saved as DOCX, PDF, HTML, RTF, and plain text, but converting to JSON requires a programmatic approach that reads the document structure and maps it to a JSON schema.
Can I preserve headings and structure when converting Word to JSON?
Yes. By iterating through all child objects in each section's body and checking paragraph style names, you can detect headings, body paragraphs, and tables, then build a hierarchical JSON structure that preserves the document's logical organization. Method 3 in this tutorial provides a complete implementation.
Can I convert Word to JSON online?
Yes, there are online Word to JSON converters that can handle one-off conversions. However, online tools are limited to single-file processing and do not allow customization of the JSON schema. For batch processing, automated pipelines, or custom output structures, a Python-based approach using Spire.Doc is more practical and scalable.
9. Conclusion
In this article, we demonstrated how to convert Word documents to JSON in Python using Spire.Doc for Python. We covered three methods of increasing complexity: extracting paragraph text as a flat JSON array, converting Word tables to structured JSON objects, and preserving the full document hierarchy—including headings, paragraphs, and tables—in a single JSON output.
Each method serves a different purpose. Plain text extraction works for indexing and embedding. Table extraction is ideal for data migration and report parsing. Full structural preservation enables knowledge base construction and RAG pipelines. Choose the approach that matches your requirements, and extend the JSON schema as needed for your specific use case.
Spire.Doc for Python provides comprehensive Word document processing capabilities beyond JSON conversion, including document creation, formatting, mail merge, and format conversion. You can apply for a 30-day free license to evaluate all features.
How to Convert JSON to Word in Python (JSON to DOCX)
JSON is one of the most common formats for exchanging structured data between applications, APIs, and databases. In many business scenarios, however, JSON data needs to be transformed into human-readable Word documents such as reports, invoices, summaries, contracts, or exported records.
Converting JSON to Word is not a simple file format conversion. JSON has no inherent Word structure, so the process requires parsing the JSON data and mapping its elements to appropriate Word document components such as paragraphs, tables, and headings.
This article demonstrates how to convert JSON data into Word documents in Python using Spire.Doc for Python. We'll cover multiple approaches, including exporting JSON as formatted text, creating Word tables from JSON arrays, and generating structured reports from nested JSON data.
Content Overview
- Understanding JSON-to-Word Conversion
- Install Spire.Doc for Python
- Method 1: Convert JSON to Word as Formatted Text
- Method 2: Convert JSON Arrays to Word Tables
- Method 3: Generate Structured Word Reports from JSON
- Handle Nested JSON Objects
- Handle Missing or Optional Fields
- Convert JSON Files to Word Documents
- Why Use Spire.Doc for JSON-to-Word Conversion
- FAQ
- Conclusion
1. Understanding JSON-to-Word Conversion
JSON and Word documents serve fundamentally different purposes. JSON is a structured data format designed for data exchange and machine processing, while Word documents are intended for human consumption with rich formatting, visual hierarchy, and page layout.
As a result, converting JSON to Word is not a direct format transformation. The JSON data must first be parsed and mapped to appropriate document elements before a Word document can be generated.
The conversion process typically follows this workflow:
JSON Data
↓
Parse JSON (json.loads)
↓
Map Data Structure
↓
Spire.Doc for Python
↓
Paragraphs / Tables / Headings
↓
DOCX Document
In Python, the built-in json module is commonly used to parse JSON data, while Spire.Doc for Python handles document generation. After the JSON structure is analyzed and mapped, Spire.Doc can create paragraphs, tables, headings, images, and other Word elements programmatically, producing a fully formatted DOCX document.
The table below shows common mappings between JSON structures and Word elements:
| JSON Structure | Word Element | Example |
|---|---|---|
| Key-Value Pair | Paragraph | "Name": "John" → Name: John |
| Array | Table | [{...}, {...}] → rows and columns |
| Object | Section | Nested object → grouped content |
| Title Field | Heading | "title": "Report" → Heading 1 |
| URL/Image Path | Image | "logo": "img.png" → embedded image |
Understanding these mappings is important because the same JSON data can be presented in different ways depending on the document's purpose. For example, simple key-value data may be exported as paragraphs, while collections of records are usually easier to read when rendered as tables. With Spire.Doc for Python, these mappings can be implemented programmatically to generate professional Word documents from structured JSON data.
2. Install Spire.Doc for Python
Before converting JSON to Word, you need to install Spire.Doc for Python in your development environment.
Install via pip (Recommended)
pip install spire.doc
Alternatively, you can download Spire.Doc for Python and integrate it manually.
After installation, import the library in your project:
from spire.doc import *
from spire.doc.common import *
3. Method 1: Convert JSON to Word as Formatted Text
This method is the simplest approach for converting JSON to Word. It works well for API responses, configuration files, and simple JSON exports where each key-value pair maps to a paragraph.
Sample JSON
{
"Name": "John Smith",
"Department": "Sales",
"Country": "USA"
}
Python Code
import json
from spire.doc import Document, FileFormat, HorizontalAlignment
json_data = '{"Name": "John Smith", "Department": "Sales", "Country": "USA"}'
data = json.loads(json_data)
document = Document()
section = document.AddSection()
for key, value in data.items():
paragraph = section.AddParagraph()
text_range = paragraph.AppendText(f"{key}: {value}")
text_range.CharacterFormat.FontSize = 12
paragraph.Format.AfterSpacing = 6
document.SaveToFile("json_to_text.docx", FileFormat.Docx)
document.Close()
Output
The following Word document shows how JSON key-value pairs can be converted into formatted paragraphs.
When to Use This Approach
This method is best suited for:
- Simple key-value JSON objects
- API response exports
- Configuration file documentation
- Quick data snapshots
It is not ideal for large datasets or tabular data, where Method 2 (tables) provides better readability.
If your goal is to analyze, filter, or manipulate structured JSON data in a spreadsheet, you may also be interested in our guide on converting JSON to Excel in Python.
4. Method 2: Convert JSON Arrays to Word Tables
When JSON data contains arrays of objects, tables provide the most effective way to present the data in a Word document. This is the most common scenario for converting JSON to Word, as many APIs and databases return data as JSON arrays.
Sample JSON
[
{"Product": "Laptop", "Price": 1200, "Stock": 45},
{"Product": "Mouse", "Price": 30, "Stock": 200},
{"Product": "Keyboard", "Price": 85, "Stock": 120}
]
Python Code
import json
from spire.doc import (
Document, FileFormat, HorizontalAlignment,
VerticalAlignment, TableRowHeightType, Color
)
json_data = '''[
{"Product": "Laptop", "Price": 1200, "Stock": 45},
{"Product": "Mouse", "Price": 30, "Stock": 200},
{"Product": "Keyboard", "Price": 85, "Stock": 120}
]'''
data = json.loads(json_data)
document = Document()
section = document.AddSection()
if data:
headers = list(data[0].keys())
table = section.AddTable(True)
table.ResetCells(len(data) + 1, len(headers))
header_row = table.Rows[0]
header_row.IsHeader = True
header_row.Height = 20
header_row.HeightType = TableRowHeightType.Exactly
for col_index, header in enumerate(headers):
header_row.Cells[col_index].CellFormat.Shading.BackgroundPatternColor = Color.get_Gray()
header_row.Cells[col_index].CellFormat.VerticalAlignment = VerticalAlignment.Middle
paragraph = header_row.Cells[col_index].AddParagraph()
paragraph.Format.HorizontalAlignment = HorizontalAlignment.Center
text_range = paragraph.AppendText(header)
text_range.CharacterFormat.Bold = True
text_range.CharacterFormat.FontSize = 12
for row_index, record in enumerate(data):
data_row = table.Rows[row_index + 1]
data_row.Height = 20
data_row.HeightType = TableRowHeightType.Exactly
for col_index, key in enumerate(headers):
data_row.Cells[col_index].CellFormat.VerticalAlignment = VerticalAlignment.Middle
paragraph = data_row.Cells[col_index].AddParagraph()
paragraph.Format.HorizontalAlignment = HorizontalAlignment.Center
text_range = paragraph.AppendText(str(record.get(key, "")))
text_range.CharacterFormat.FontSize = 11
document.SaveToFile("json_to_table.docx", FileFormat.Docx)
document.Close()
Output
The following screenshot shows the generated Word table created from the JSON array.
Why Use Tables for JSON Arrays
Tables are the natural fit for JSON array data because:
- Each JSON object maps to a table row
- Each key maps to a column header
- Data is aligned for easy scanning and comparison
- Tables are the standard format for reports, inventory lists, and exported database records
Enhancing JSON Tables with Formatting
Unlike plain text exports, Spire.Doc allows JSON data to be rendered as professionally formatted Word tables. Beyond basic table creation, you can apply:
- Table styles – Use
DefaultTableStyleorApplyStylefor consistent, polished table appearances - Borders and shading – Control cell borders, background colors, and alternating row colors
- Alignment – Set horizontal and vertical alignment at the cell, row, or table level
- Custom formatting – Apply font size, bold, and color to individual cells or ranges
- Auto-fit behavior – Use
AutoFitto adjust column widths to content or window size
These formatting capabilities transform raw JSON data into professional report layouts suitable for business documents, client deliverables, and automated reporting pipelines.
If you need to create more sophisticated Word tables, such as merged cells, custom table layouts, or advanced formatting, see our guide on creating and formatting tables in Word documents using Python.
5. Method 3: Generate Structured Word Reports from JSON
Real-world JSON data often contains a mix of metadata, summary text, and tabular data. This method combines headings, paragraphs, and tables to generate a complete structured Word report from JSON.
Sample JSON
{
"title": "Monthly Sales Report",
"period": "June 2026",
"summary": "Total revenue reached $580,000 this month, representing a 12% increase over the previous period. All regions showed positive growth.",
"sales": [
{"Region": "North", "Revenue": 150000, "Units": 320},
{"Region": "South", "Revenue": 120000, "Units": 280},
{"Region": "East", "Revenue": 180000, "Units": 410},
{"Region": "West", "Revenue": 130000, "Units": 290}
]
}
Python Code
import json
from spire.doc import (
Document, FileFormat, HorizontalAlignment,
VerticalAlignment, TableRowHeightType, Color,
BuiltinStyle
)
json_data = '''{
"title": "Monthly Sales Report",
"period": "June 2026",
"summary": "Total revenue reached $580,000 this month, representing a 12% increase over the previous period. All regions showed positive growth.",
"sales": [
{"Region": "North", "Revenue": 150000, "Units": 320},
{"Region": "South", "Revenue": 120000, "Units": 280},
{"Region": "East", "Revenue": 180000, "Units": 410},
{"Region": "West", "Revenue": 130000, "Units": 290}
]
}'''
data = json.loads(json_data)
document = Document()
section = document.AddSection()
heading_style = document.AddStyle(BuiltinStyle.Heading1)
subheading_style = document.AddStyle(BuiltinStyle.Heading2)
title_para = section.AddParagraph()
title_para.ApplyStyle(heading_style.Name)
title_para.AppendText(data.get("title", "Report"))
period_para = section.AddParagraph()
period_para.AppendText(f"Period: {data.get('period', 'N/A')}")
period_para.Format.AfterSpacing = 12
summary_heading = section.AddParagraph()
summary_heading.ApplyStyle(subheading_style.Name)
summary_heading.AppendText("Executive Summary")
summary_para = section.AddParagraph()
summary_para.AppendText(data.get("summary", ""))
summary_para.Format.AfterSpacing = 12
sales_heading = section.AddParagraph()
sales_heading.ApplyStyle(subheading_style.Name)
sales_heading.AppendText("Sales Data")
sales = data.get("sales", [])
if sales:
headers = list(sales[0].keys())
table = section.AddTable(True)
table.ResetCells(len(sales) + 1, len(headers))
header_row = table.Rows[0]
header_row.IsHeader = True
header_row.Height = 20
header_row.HeightType = TableRowHeightType.Exactly
for col_index, header in enumerate(headers):
header_row.Cells[col_index].CellFormat.Shading.BackgroundPatternColor = Color.get_Gray()
header_row.Cells[col_index].CellFormat.VerticalAlignment = VerticalAlignment.Middle
paragraph = header_row.Cells[col_index].AddParagraph()
paragraph.Format.HorizontalAlignment = HorizontalAlignment.Center
text_range = paragraph.AppendText(header)
text_range.CharacterFormat.Bold = True
for row_index, record in enumerate(sales):
data_row = table.Rows[row_index + 1]
data_row.Height = 20
data_row.HeightType = TableRowHeightType.Exactly
for col_index, key in enumerate(headers):
data_row.Cells[col_index].CellFormat.VerticalAlignment = VerticalAlignment.Middle
paragraph = data_row.Cells[col_index].AddParagraph()
paragraph.Format.HorizontalAlignment = HorizontalAlignment.Center
paragraph.AppendText(str(record.get(key, "")))
document.SaveToFile("json_report.docx", FileFormat.Docx)
document.Close()
Output
The generated Word document combines headings, descriptive text, and tabular data into a structured report, making the JSON data easier to read and share.
Key Techniques
This example demonstrates several important techniques for generating Word reports from JSON:
- Headings – Use
BuiltinStyle.Heading1andHeading2for document structure and table-of-contents compatibility - Paragraphs – Add summary and descriptive text between headings
- Tables – Render JSON arrays as tabular data within the report
- Combinations – Mix multiple Word element types in a single document
Why Structured Reports Matter
In business environments, JSON data rarely exists in isolation. It typically comes from APIs, databases, or reporting systems and needs to be transformed into documents that decision-makers can read, share, and archive. Common scenarios include:
- Sales reports – Revenue, units, and regional breakdowns from CRM or ERP systems
- Inventory reports – Stock levels, reorder alerts, and warehouse summaries
- Customer summaries – Contact details, order history, and account status
- Compliance reports – Audit logs, access records, and policy status
- Automated reporting systems – Scheduled jobs that generate documents from JSON data and distribute them via email or document management systems
Spire.Doc makes it possible to transform structured JSON data into polished business documents automatically, combining headings, paragraphs, and tables in a single output.
If you need to build more sophisticated document layouts, such as multi-section reports, cover pages, tables of contents, headers, footers, or custom document templates, see our guide on creating structured Word documents in Python.
6. Handle Nested JSON Objects
Many real-world JSON responses contain nested objects. For example, a customer record may include an address object with its own fields. Handling these nested structures is essential for complete JSON-to-Word conversion.
Example JSON
{
"customer": {
"name": "Tom Wilson",
"email": "tom@example.com",
"address": {
"street": "123 Main St",
"city": "Springfield",
"state": "IL"
}
}
}
Python Code
import json
from spire.doc import Document, FileFormat, HorizontalAlignment
def add_nested_object(section, obj, indent_level=0):
for key, value in obj.items():
if isinstance(value, dict):
heading_para = section.AddParagraph()
heading_text = " " * indent_level + key.capitalize()
text_range = heading_para.AppendText(heading_text)
text_range.CharacterFormat.Bold = True
text_range.CharacterFormat.FontSize = 12 - indent_level
heading_para.Format.AfterSpacing = 4
add_nested_object(section, value, indent_level + 1)
else:
paragraph = section.AddParagraph()
label = " " * indent_level + f"{key}: {value}"
text_range = paragraph.AppendText(label)
text_range.CharacterFormat.FontSize = 11
paragraph.Format.AfterSpacing = 2
json_data = '''{
"customer": {
"name": "Tom Wilson",
"email": "tom@example.com",
"address": {
"street": "123 Main St",
"city": "Springfield",
"state": "IL"
}
}
}'''
data = json.loads(json_data)
document = Document()
section = document.AddSection()
add_nested_object(section, data)
document.SaveToFile("json_nested.docx", FileFormat.Docx)
document.Close()
Output
The following screenshot shows the hierarchical Word document generated from the nested JSON structure.
Nested JSON objects can be represented as hierarchical sections in a Word document, making complex data structures easier to read and navigate.
How It Works
The add_nested_object function recursively traverses the JSON structure:
- When it encounters a dict value, it creates a bold heading for the key and recurses into the nested object
- When it encounters a scalar value, it creates a paragraph with the key-value pair
- The
indent_levelparameter controls indentation and font size to create a visual hierarchy
This recursive approach handles arbitrarily deep nesting and produces a readable hierarchical layout in the Word document.
7. Handle Missing or Optional JSON Fields
In real-world applications, JSON data from APIs and databases often contains missing or optional fields. Records may have inconsistent keys, and some fields may be absent entirely. Handling these cases gracefully prevents errors and ensures the generated Word document remains complete.
Example JSON with Missing Fields
[
{"Name": "Tom Wilson", "Email": "tom@example.com", "Phone": "555-0100"},
{"Name": "Jane Doe", "Email": "jane@example.com"},
{"Name": "Bob Brown", "Phone": "555-0300"}
]
Python Code
import json
from spire.doc import (
Document, FileFormat, HorizontalAlignment,
VerticalAlignment, TableRowHeightType, Color
)
json_data = '''[
{"Name": "Tom Wilson", "Email": "tom@example.com", "Phone": "555-0100"},
{"Name": "Jane Doe", "Email": "jane@example.com"},
{"Name": "Bob Brown", "Phone": "555-0300"}
]'''
data = json.loads(json_data)
document = Document()
section = document.AddSection()
if data:
all_keys = []
for record in data:
for key in record.keys():
if key not in all_keys:
all_keys.append(key)
table = section.AddTable(True)
table.ResetCells(len(data) + 1, len(all_keys))
header_row = table.Rows[0]
header_row.IsHeader = True
header_row.Height = 20
header_row.HeightType = TableRowHeightType.Exactly
for col_index, header in enumerate(all_keys):
header_row.Cells[col_index].CellFormat.Shading.BackgroundPatternColor = Color.get_Gray()
header_row.Cells[col_index].CellFormat.VerticalAlignment = VerticalAlignment.Middle
paragraph = header_row.Cells[col_index].AddParagraph()
paragraph.Format.HorizontalAlignment = HorizontalAlignment.Center
text_range = paragraph.AppendText(header)
text_range.CharacterFormat.Bold = True
for row_index, record in enumerate(data):
data_row = table.Rows[row_index + 1]
data_row.Height = 20
data_row.HeightType = TableRowHeightType.Exactly
for col_index, key in enumerate(all_keys):
data_row.Cells[col_index].CellFormat.VerticalAlignment = VerticalAlignment.Middle
paragraph = data_row.Cells[col_index].AddParagraph()
paragraph.Format.HorizontalAlignment = HorizontalAlignment.Center
paragraph.AppendText(str(record.get(key, "N/A")))
document.SaveToFile("json_missing_fields.docx", FileFormat.Docx)
document.Close()
Output
The following screenshot shows the generated Word table, where missing fields are automatically filled with placeholder values to maintain a consistent document structure.

Key Techniques
dict.get(key, "N/A")– Returns a default value when a key is missing, preventingKeyErrorexceptions- Dynamic column collection – Iterates all records to build a complete set of column headers, ensuring no field is missed even when it appears in only some records
- Consistent table structure – All rows have the same number of columns regardless of which fields are present in each record
This approach is essential for production use cases where API responses may vary in structure across different records or over time.
8. Convert JSON Files to Word Documents
In practice, JSON data often originates from files rather than inline strings. API export results, configuration files, database dumps, data exchange files, and log data are all commonly stored as .json files that need to be converted to Word documents.
The conversion process for JSON files follows this workflow:
JSON File (.json)
↓
Load JSON (json.load)
↓
Generate Word Document (Spire.Doc)
↓
DOCX Document
Python Code
import json
from spire.doc import Document, FileFormat
with open("data.json", "r", encoding="utf-8") as f:
data = json.load(f)
document = Document()
section = document.AddSection()
# Process the loaded JSON data
# using any of the techniques shown in Methods 1–3
# (formatted text, tables, or structured reports)
document.SaveToFile("data_report.docx", FileFormat.Docx)
document.Close()
Key Points
json.load()reads and parses a JSON file directly, unlikejson.loads()which parses a stringencoding="utf-8"ensures proper handling of non-ASCII characters in JSON files- Once the JSON file is loaded into a Python dictionary or list, Spire.Doc for Python can generate paragraphs, tables, or structured reports from the parsed data using any of the methods described earlier in this article
For complete examples of processing the loaded data, refer to Method 1 for formatted text, Method 2 for tables, or Method 3 for structured reports.
9. Why Use Spire.Doc for JSON-to-Word Conversion
Converting JSON to Word involves several practical challenges that go beyond simple data parsing. Generating properly formatted tables, applying consistent styles, creating structured reports with headings and paragraphs, and handling nested or incomplete data all require a capable document generation API.
Challenges of JSON-to-Word Conversion
- Table generation – JSON arrays must be mapped to Word tables with headers, rows, and cell formatting
- Document formatting – Raw data exports lack the visual hierarchy that makes Word documents readable
- Structured reports – Combining headings, paragraphs, and tables in a single document requires coordinating multiple element types
- Nested data – Deeply nested JSON objects need recursive traversal and hierarchical layout
- Large documents – Generating multi-page reports from large JSON datasets demands efficient resource management
Benefits of Spire.Doc for Python
Spire.Doc for Python addresses these challenges with a straightforward API:
- Create Word documents without Microsoft Word – No Office installation or Interop dependencies required
- Generate paragraphs, tables, images, headers, and footers – Full coverage of Word document elements
- Apply built-in and custom styles – Consistent formatting across documents using
BuiltinStyleandParagraphStyle - Automate report generation – Programmatically build structured reports from any JSON data source
- Export to DOCX and other formats – Save to DOCX, PDF, HTML, RTF, and more using
FileFormat
With Spire.Doc, the JSON-to-Word conversion process becomes a structured mapping from parsed data to Word elements, rather than manual string formatting or template manipulation.
10. FAQ
How do I convert JSON to Word in Python?
Parse the JSON data using Python's built-in json module, then use Spire.Doc for Python to create a Word document. Map JSON key-value pairs to paragraphs, JSON arrays to tables, and use headings for structure. See Method 1 for a basic example and Method 3 for a complete report.
Can JSON arrays be converted into Word tables?
Yes. JSON arrays of objects map naturally to Word tables, where each object becomes a row and each key becomes a column. See Method 2 for a complete code example that creates a formatted table from a JSON array.
How do I create a DOCX report from API JSON responses?
Fetch the API response as JSON, parse it, and use Spire.Doc for Python to generate the report. Combine headings for titles, paragraphs for summaries, and tables for data arrays. See Method 3 for a structured report example.
Can nested JSON objects be exported to Word?
Yes. Use a recursive function to traverse nested JSON objects, creating headings for object keys and paragraphs for scalar values. See Section 6 for a detailed example of handling nested structures with visual hierarchy.
How do I convert a JSON file to a Word document?
Use Python's json.load() to read the JSON file, then process the parsed data with Spire.Doc for Python. See Section 8 for a code example.
What is the best way to generate Word documents from JSON data?
The best approach depends on the JSON structure. For simple key-value data, use formatted paragraphs. For arrays, use tables. For complex nested data with mixed content, combine headings, paragraphs, and tables as shown in Method 3.
11. Conclusion
Generating Word documents from JSON data is a common requirement in reporting, document automation, and data export workflows. With Spire.Doc for Python, you can create paragraphs, tables, and structured document layouts directly from JSON, making it easier to produce professional DOCX files from application data.
The same approach can be extended to API responses, database records, configuration files, and other structured data sources, helping automate document generation in both small projects and enterprise systems.
For scenarios involving large documents or document conversion requirements, a licensed version is required.
Convert JavaScript to Word with Python Automation
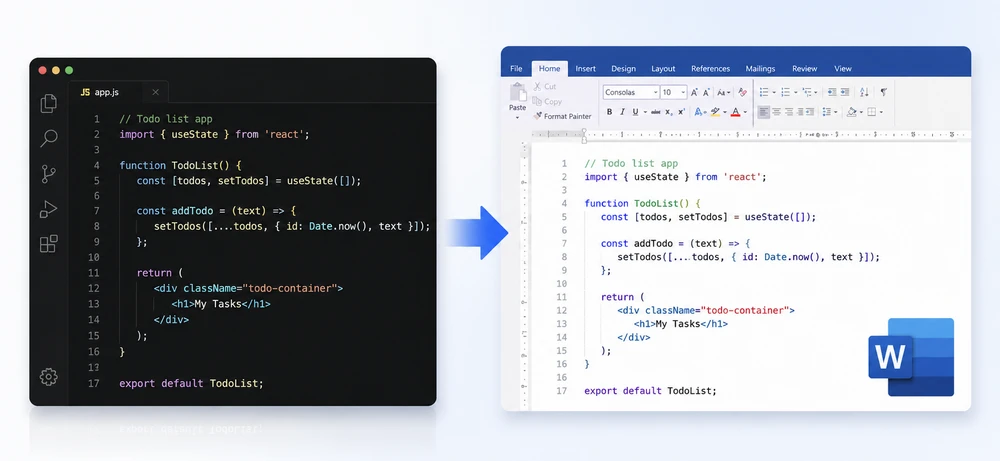
Modern development teams often need to share JavaScript or JSX source code with project managers, clients, auditors, or educators who don't use code editors. However, raw .js and .jsx files are difficult to review outside tools like VS Code or WebStorm, while manually copying code into Word documents frequently breaks indentation, formatting, and readability.
Using Spire.Doc for Python together with Pygments, developers can convert JavaScript to Word in Python with syntax highlighting and customizable document formatting. This automated approach is useful for technical documentation, compliance archiving, educational materials, code reviews, and client deliverables.
In this article, you'll learn how to convert JavaScript and JSX files to Word documents in Python using Spire.Doc for Python, including basic conversion, advanced formatting techniques, batch processing, and PDF export.
Quick Navigation
- Understanding the Conversion Workflow
- Prerequisites
- Basic Implementation of JavaScript to Word Conversion
- Advanced Scenarios
- Common Pitfalls
- Conclusion
- FAQ
1. Understanding the Conversion Workflow
The conversion process uses Pygments to generate syntax-highlighted HTML, then imports this HTML into a Word document using Spire.Doc's HTML import functionality:
- Read source code from
.jsor.jsxfiles - Generate syntax-highlighted HTML using Pygments'
highlight()function - Import the HTML into Word using
AppendHTML()
This approach provides syntax coloring through Pygments' built-in styles, while Spire.Doc handles document structure including margins, headers, footers, and multi-format export. It provides a simple and flexible API for automating the conversion process.
2. Prerequisites
Before converting JavaScript files to Word documents in Python, you need to install Spire.Doc for Python and Pygments:
pip install spire.doc
pip install pygments
Verify the packages are available:
import spire.doc
from pygments import highlight
from pygments.formatters import HtmlFormatter
Alternatively, you can download Spire.Doc for Python and add it to your project.
3. Basic Implementation
The following example converts a JavaScript file to a Word document with syntax highlighting:
from spire.doc import *
from pygments import highlight
from pygments.lexers import JavascriptLexer
from pygments.formatters import HtmlFormatter
def convert_js_to_word(input_file: str, output_file: str) -> None:
"""Convert JavaScript file to Word document with syntax highlighting."""
with open(input_file, "r", encoding="utf-8") as file:
js_code = file.read()
document = Document()
section = document.AddSection()
section.PageSetup.Margins.All = 50
title_paragraph = section.AddParagraph()
title_text = title_paragraph.AppendText(f"Source Code: {input_file}")
title_text.CharacterFormat.FontName = "Arial"
title_text.CharacterFormat.FontSize = 14
title_text.CharacterFormat.Bold = True
title_paragraph.Format.AfterSpacing = 10
html_formatter = HtmlFormatter(
nowrap=True,
style='colorful',
noclasses=True
)
highlighted_html = highlight(js_code, JavascriptLexer(), html_formatter)
code_paragraph = section.AddParagraph()
code_paragraph.AppendHTML(f'<pre style="font-family: Consolas; font-size: 10pt;">{highlighted_html}</pre>')
document.SaveToFile(output_file, FileFormat.Docx)
document.Close()
print(f"Converted {input_file} to {output_file}")
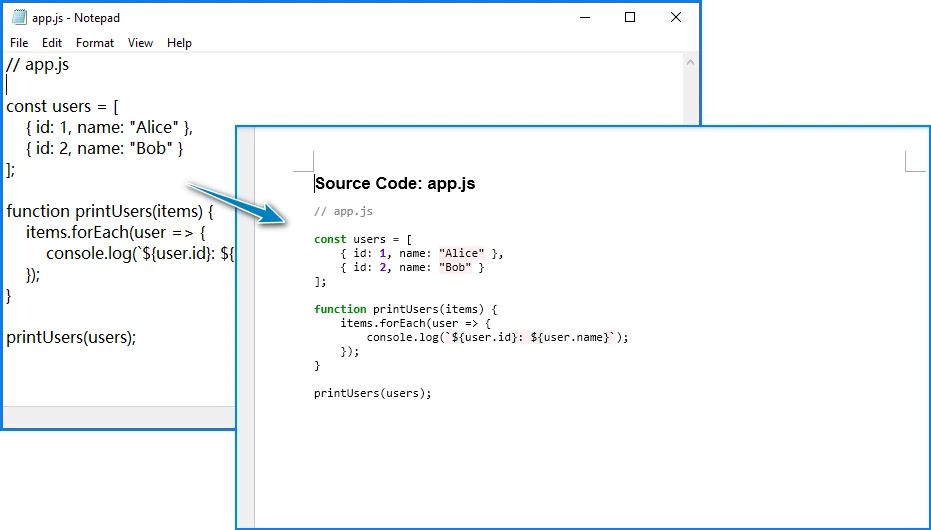
convert_js_to_word("app.js", "JavaScriptCode.docx")
Key Components
- Document – Word document container for sections, paragraphs, and content
- Section – Document section with page setup properties (margins, orientation)
- Paragraph – Text container with formatting options
- AppendHTML() – Imports HTML content into the paragraph, including inline styles for colors and fonts
- highlight() – Pygments function that generates syntax-highlighted output
- HtmlFormatter – Pygments formatter producing HTML with inline styles (use
noclasses=True) - JavascriptLexer – Pygments lexer that identifies JavaScript syntax elements
Spire.Doc can import syntax-highlighted HTML generated by Pygments, allowing JavaScript code formatting and colors to be preserved in Word documents.
4. Advanced Scenarios
Convert JSX Files
For JSX files, it's recommended to use JsxLexer instead of JavascriptLexer to achieve more accurate syntax highlighting for component tags and embedded JSX expressions.
Example JSX input (App.jsx):
``jsx import React, { useState } from 'react';
const TodoList = () => { const [todos, setTodos] = useState([]);
return (
<div className="todo-container">
<h1>My Tasks</h1>
</div>
);
};
export default TodoList;
Use `JsxLexer` when generating syntax-highlighted HTML:
```python
from pygments.lexers import JsxLexer
highlighted_html = highlight(
jsx_code,
JsxLexer(),
html_formatter
)
Then convert the highlighted JSX content to Word using the same AppendHTML() workflow:
convert_js_to_word("App.jsx", "ReactComponent.docx")
The conversion result looks like this:
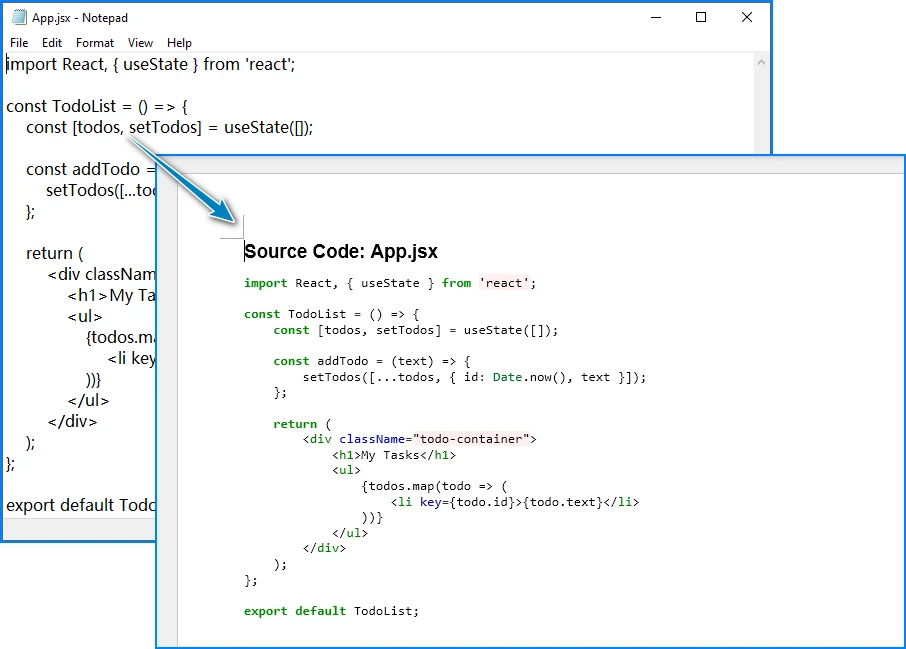
JsxLexer provides improved recognition for JSX tags, attributes, and embedded expressions compared to the standard JavaScript lexer, resulting in more accurate syntax coloring in the generated Word document.
Batch Convert Multiple Files
If you need to convert large numbers of JavaScript or JSX files, you can automate the process by scanning a folder and generating Word documents in batches.
import os
from pathlib import Path
def batch_convert_js_files(source_folder: str, output_folder: str) -> None:
"""Convert all JavaScript files in a folder to Word documents."""
Path(output_folder).mkdir(parents=True, exist_ok=True)
js_extensions = ('.js', '.jsx', '.mjs')
converted_count = 0
error_count = 0
for filename in os.listdir(source_folder):
if filename.lower().endswith(js_extensions):
input_path = os.path.join(source_folder, filename)
base_name = os.path.splitext(filename)[0]
output_path = os.path.join(output_folder, f"{base_name}.docx")
try:
convert_js_to_word(input_path, output_path)
converted_count += 1
except Exception as e:
print(f"Error converting {filename}: {str(e)}")
error_count += 1
print(f"\nBatch conversion complete:")
print(f" Converted: {converted_count} files")
print(f" Errors: {error_count} files")
batch_convert_js_files("src/scripts", "output/docs")
Add Line Numbers
Line numbers can improve readability during code reviews, audits, or technical documentation. Since Word HTML rendering may not fully support Pygments' built-in line number layouts, a practical approach is to prepend custom line numbers after syntax highlighting.
html_formatter = HtmlFormatter(
nowrap=True,
noclasses=True,
style="colorful"
)
highlighted_html = highlight(
js_code,
JavascriptLexer(),
html_formatter
)
highlighted_lines = highlighted_html.splitlines()
numbered_lines = []
for index, line in enumerate(highlighted_lines, start=1):
numbered_line = (
f'<span style="color: gray; font-weight: bold;">'
f'{index:4d} '
f'</span>{line}'
)
numbered_lines.append(numbered_line)
combined_html = (
'<pre style="font-family: Consolas; '
'font-size: 10pt; line-height: 1.4;">'
+ '\n'.join(numbered_lines) +
'</pre>'
)
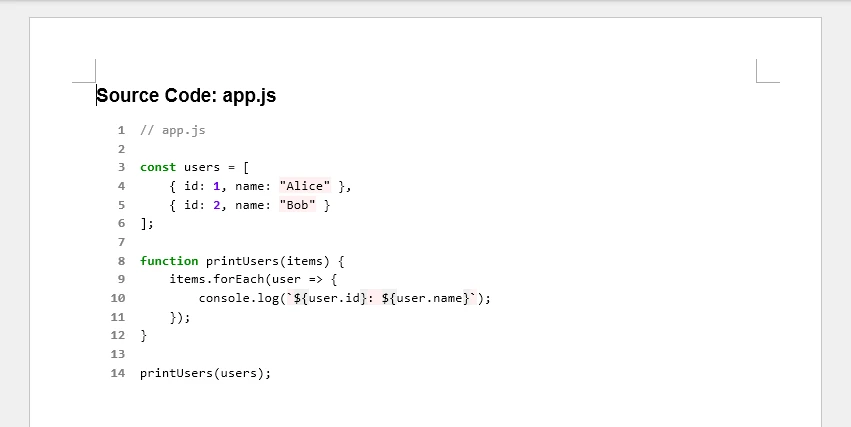
paragraph.AppendHTML(combined_html)
The generated Word document with line numbers looks like this:
Add Headers and Footers
Headers and footers help organize generated Word documents by adding titles, page numbers, and document metadata. This is especially useful for formal reports or exported technical documentation.
def add_document_metadata(section: Section, document_title: str) -> None:
"""Add header and footer to document section."""
header = section.HeadersFooters.Header.AddParagraph()
header_text = header.AppendText(document_title)
header_text.CharacterFormat.FontName = "Arial"
header_text.CharacterFormat.FontSize = 10
header_text.CharacterFormat.TextColor = Color.get_Black()
header.Format.HorizontalAlignment = HorizontalAlignment.Left
header.Format.TextAlignment = TextAlignment.Top
header.Format.Borders.Bottom.BorderType = BorderStyle.Single
header.Format.Borders.Bottom.Color = Color.get_Black()
footer = section.HeadersFooters.Footer.AddParagraph()
footer.Format.HorizontalAlignment = HorizontalAlignment.Center
footer.Format.TextAlignment = TextAlignment.Bottom
page_field = footer.AppendField("page", FieldType.FieldPage)
page_field.CharacterFormat.FontName = "Arial"
page_field.CharacterFormat.FontSize = 9
footer.AppendText(" of ")
total_pages_field = footer.AppendField("numPages", FieldType.FieldNumPages)
total_pages_field.CharacterFormat.FontName = "Arial"
total_pages_field.CharacterFormat.FontSize = 9
document = Document()
document.LoadFromFile("CodeWithLines.docx")
section = document.Sections[0]
add_document_metadata(section, "JavaScript Source Code Documentation")
document.SaveToFile("CodeWithHeadersFooters.docx", FileFormat.Docx)
The generated Word document with headers and footers looks like this:
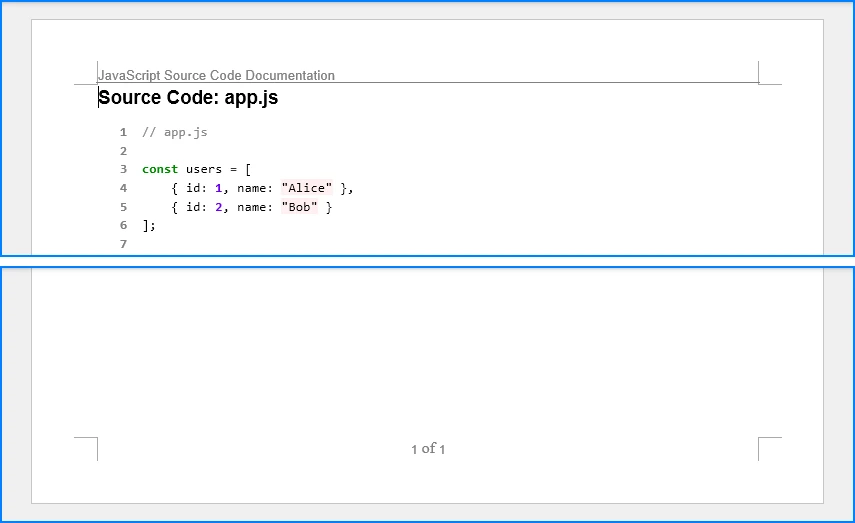
For more advanced customization options, refer to our guide on how to add headers and footers to Word documents in Python.
Export to PDF Format
In addition to DOCX output, Spire.Doc can export syntax-highlighted JavaScript code directly to PDF format. This is useful when distributing read-only documentation or sharing code outside Microsoft Word environments.
def convert_js_to_pdf(input_file: str, output_file: str) -> None:
"""Convert JavaScript file directly to PDF."""
with open(input_file, "r", encoding="utf-8") as file:
js_code = file.read()
document = Document()
section = document.AddSection()
section.PageSetup.Margins.All = 50
html_formatter = HtmlFormatter(noclasses=True, style='colorful')
highlighted_html = highlight(js_code, JavascriptLexer(), html_formatter)
paragraph = section.AddParagraph()
paragraph.AppendHTML(f'<pre style="font-family: Consolas; font-size: 10pt;">{highlighted_html}</pre>')
document.SaveToFile(output_file, FileFormat.PDF)
document.Close()
convert_js_to_pdf("app.js", "JavaScriptCode.pdf")
For more advanced PDF conversion techniques, including layout control and document formatting, see our detailed guide on converting Word documents to PDF in Python.
Customize Syntax Highlighting Style
Pygments provides multiple built-in color schemes:
def convert_with_custom_style(input_file: str, output_file: str, style_name: str = 'monokai') -> None:
"""Convert JavaScript to Word with custom highlighting style."""
with open(input_file, "r", encoding="utf-8") as file:
js_code = file.read()
document = Document()
section = document.AddSection()
section.PageSetup.Margins.All = 50
html_formatter = HtmlFormatter(
noclasses=True,
style=style_name,
nowrap=True
)
highlighted_html = highlight(js_code, JavascriptLexer(), html_formatter)
paragraph = section.AddParagraph()
paragraph.AppendHTML(f'<pre style="font-family: Consolas; font-size: 10pt;">{highlighted_html}</pre>')
document.SaveToFile(output_file, FileFormat.Docx)
document.Close()
convert_with_custom_style("app.js", "CodeMonokai.docx", style_name='monokai')
Available styles include: 'monokai', 'colorful', 'vim', 'vs', 'tango', 'friendly', 'default'
5. Common Pitfalls
Missing HtmlFormatter Configuration
Problem: Default HtmlFormatter generates CSS classes instead of inline styles, which Word cannot process without external stylesheets.
Solution: Always use noclasses=True:
html_formatter = HtmlFormatter(noclasses=True, style='colorful')
highlighted_html = highlight(js_code, JavascriptLexer(), html_formatter)
Encoding Errors with Special Characters
Problem: Reading files without UTF-8 encoding causes character corruption on some platforms.
Solution: Explicitly specify UTF-8 encoding:
with open(input_file, "r", encoding="utf-8") as file:
js_code = file.read()
For files with BOM (Byte Order Mark), use utf-8-sig:
with open(input_file, "r", encoding="utf-8-sig") as file:
js_code = file.read()
Indentation Loss
Problem: Not wrapping highlighted code in <pre> tags causes indentation to disappear.
Solution: Wrap syntax-highlighted HTML in <pre> tags:
highlighted_html = highlight(js_code, JavascriptLexer(), html_formatter)
paragraph.AppendHTML(f'<pre style="font-family: Consolas;">{highlighted_html}</pre>')
ModuleNotFoundError
Problem: Package not installed in current Python environment.
Solution:
pip install spire.doc
For virtual environments, ensure activation before installation:
source venv/bin/activate # Linux/Mac
venv\Scripts\activate # Windows
pip install spire.doc
Performance with Large Files
Problem: Very large JavaScript files (10,000+ lines) may cause slow conversion.
Solution: Process files in chunks:
def convert_large_file(input_file: str, output_file: str, chunk_size: int = 500) -> None:
"""Convert large JavaScript file in chunks."""
with open(input_file, "r", encoding="utf-8") as file:
lines = file.readlines()
document = Document()
section = document.AddSection()
section.PageSetup.Margins.All = 50
html_formatter = HtmlFormatter(noclasses=True, style='colorful')
for i in range(0, len(lines), chunk_size):
chunk = ''.join(lines[i:i + chunk_size])
highlighted_html = highlight(chunk, JavascriptLexer(), html_formatter)
paragraph = section.AddParagraph()
paragraph.AppendHTML(f'<pre style="font-family: Consolas; font-size: 10pt;">{highlighted_html}</pre>')
document.SaveToFile(output_file, FileFormat.Docx)
document.Close()
Conclusion
This article demonstrated how to convert JavaScript and JSX files to Word documents in Python using Spire.Doc for Python and Pygments. By leveraging the highlight() function with HtmlFormatter and Spire.Doc's AppendHTML() method, developers can automate code documentation workflows with syntax highlighting.
Spire.Doc for Python provides document generation capabilities including table creation, image insertion, header/footer management, and multi-format export.
You can apply for a 30-day free license to evaluate all features.
7. FAQ
Can Spire.Doc convert JSX files to Word documents?
Yes. Pygments can highlight many JSX constructs using the JavaScript lexer, including component tags, props, and embedded expressions. However, JSX-specific syntax may not receive dedicated highlighting categories.
Does this solution require Microsoft Word installation?
No. Spire.Doc for Python operates independently without requiring Microsoft Word. The library generates DOCX files directly, making it suitable for server environments and CI/CD pipelines.
Can I convert JavaScript to formats other than DOCX?
Yes. Spire.Doc supports multiple export formats:
document.SaveToFile("output.pdf", FileFormat.PDF)
document.SaveToFile("output.html", FileFormat.Html)
document.SaveToFile("output.rtf", FileFormat.Rtf)
How do I handle TypeScript files (.ts, .tsx)?
Use TypescriptLexer:
from pygments.lexers import TypescriptLexer
highlighted_html = highlight(ts_code, TypescriptLexer(), html_formatter)
Is this approach suitable for enterprise-scale projects?
Yes. Python automation integrates with CI/CD pipelines and batch processing workflows. Local execution avoids security risks from uploading source code to online converters. Consider implementing logging, progress reporting, and error tracking for large deployments.
Can I customize syntax highlighting colors?
Yes. Pygments offers numerous built-in styles:
html_formatter = HtmlFormatter(noclasses=True, style='monokai')
Available styles: 'monokai', 'colorful', 'vim', 'vs', 'tango', 'friendly', 'default'
Convert Python Code to Word (Plain or Syntax-Highlighted)

Developers often need to include Python code inside Word documents for technical documentation, tutorials, code reviews, internal reports, or client deliverables. While copying and pasting code manually works for small snippets, automated solutions provide better consistency, formatting control, and scalability — especially when working with long scripts or multiple files.
This tutorial demonstrates multiple practical methods to export Python code into Word documents using Python. Each method has its own strengths depending on whether you prioritize formatting, automation, syntax highlighting, or readability.
On This Page:
- Install Required Libraries
- Export Python Code to Word as Plain Text
- Add Syntax-Highlighted Python Code to Word
- Conclusion
- FAQs
Install Required Libraries
Install the necessary dependencies before running the examples:
pip install spire.doc pygments
Library Overview:
- Spire.Doc for Python — used to create and manipulate Word documents programmatically
- Pygments — used to generate syntax-highlighted code in RTF, HTML, or image formats
- Pathlib (built-in) — used for reading Python files from disk
- textwrap (built-in) — used to wrap long code lines before generating images formatting
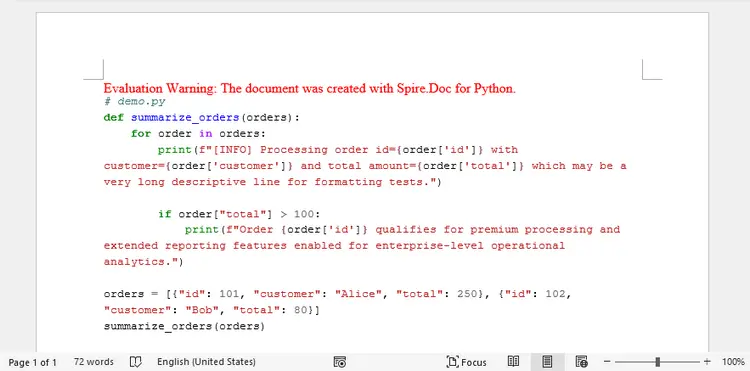
Export Python Code to Word as Plain Text
Plain text insertion is the most straightforward method for embedding code in Word. It keeps scripts fully editable and preserves formatting such as indentation and line breaks.
Method 1. Insert Raw Python Code into a Word Document
This method reads a .py file and inserts the code directly into Word while applying a monospace font style.
from pathlib import Path
from spire.doc import *
# Read Python file
code_string = Path("demo.py").read_text(encoding="utf-8")
# Create a Word document
doc = Document()
# Add a section
section = doc.AddSection()
section.PageSetup.Margins.All = 60
# Add a paragraph
paragraph = section.AddParagraph()
# Insert code string to the paragraph
paragraph.AppendText(code_string)
# Create a paragraph style
style = ParagraphStyle(doc)
style.Name = "code"
style.CharacterFormat.FontName = "Consolas"
style.CharacterFormat.FontSize = 12
style.ParagraphFormat.LineSpacing = 12
doc.Styles.Add(style)
# Apply the style to the paragraph
paragraph.ApplyStyle("code")
# Save the document
doc.SaveToFile("Output.docx", FileFormat.Docx2019)
doc.Dispose()
How It Works:
This technique treats Python code as plain text and inserts it directly into a Word paragraph. The script reads the .py file using Path.read_text(), preserving indentation, blank lines, and overall structure.
After inserting the text, a custom paragraph style is created and applied. The use of a monospace font such as Consolas ensures alignment and readability, while fixed line spacing maintains consistent formatting across lines.
Because no intermediate format is used, this is the simplest and fastest approach. However, it does not provide syntax highlighting or semantic styling—Word only displays the code as formatted text.
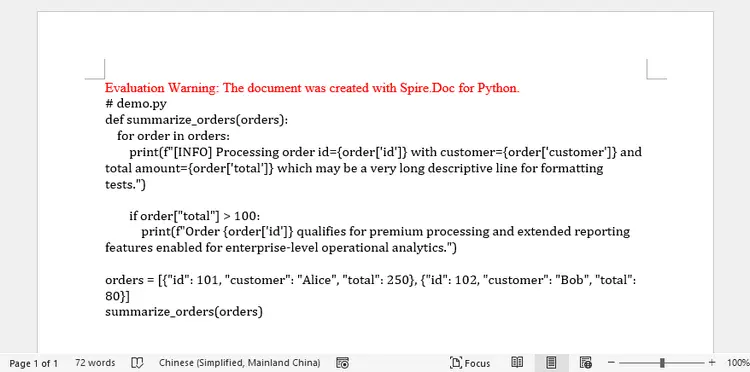
Output:
You May Also Like: Generate Word Documents Using Python
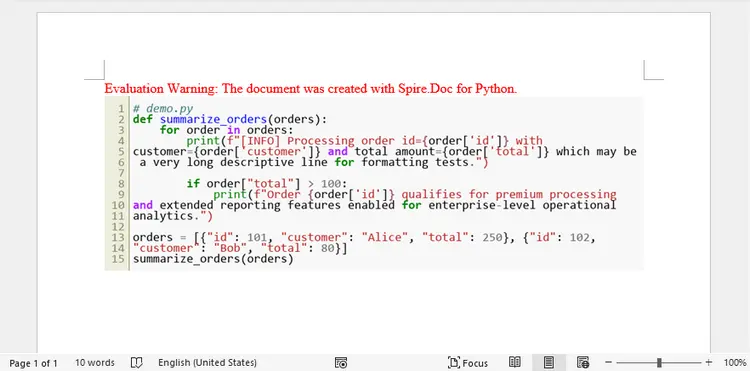
Method 2. Generate a Word File from Markdown-Wrapped Code
If your workflow already uses Markdown, wrapping Python code inside fenced blocks provides a structured way to convert scripts into Word documents.
from pathlib import Path
from spire.doc import *
# Read Python file
code = Path("demo.py").read_text(encoding="utf-8")
# Convert to Markdown
md_content = f"```python\n{code}\n```"
Path("temp.md").write_text(md_content, encoding="utf-8")
# Load Markdown into Word
doc = Document()
doc.LoadFromFile("temp.md")
# Update page settings
doc.Sections[0].PageSetup.Margins.All = 60
# Save as a DOCX file
doc.SaveToFile("Output.docx", FileFormat.Docx)
doc.Dispose()
How It Works:
Instead of inserting text directly, this method wraps Python code inside Markdown fenced code blocks. The generated Markdown file is then loaded into Word using Spire.Doc’s Markdown parsing capability.
When Word imports Markdown, it automatically preserves code formatting such as indentation and line breaks. This approach is useful when your documentation workflow already uses Markdown or when code needs to coexist with headings, lists, and descriptive text.
Since Markdown itself does not inherently apply syntax coloring inside Word, the result is still plain code formatting—but the structure is cleaner and easier to manage within technical documentation pipelines.
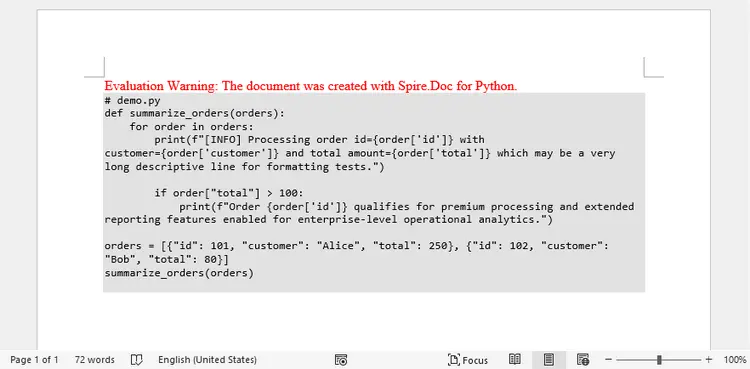
Output:
Add Syntax-Highlighted Python Code to Word
Syntax highlighting makes code easier to read and understand. By integrating Pygments, Python scripts can be converted into stylized formats before being embedded into Word.
This section explores three approaches — RTF, HTML, and image rendering — each with different strengths depending on your formatting goals.
Method 1. Use RTF for Preformatted Code Blocks
RTF allows syntax-highlighted code to remain fully editable within Word.
from pathlib import Path
from pygments import highlight
from pygments.lexers import PythonLexer
from pygments.formatters import RtfFormatter
from spire.doc import *
# Read Python file
code = Path("demo.py").read_text(encoding="utf-8")
# Set font
formatter = RtfFormatter(fontface ="Consolas")
# Specify the lexer
rtf_text = highlight(code, PythonLexer(), formatter)
rtf_text = rtf_text.replace(r"\f0", r"\f0\fs24") # font size (24 for 12-point font)
# Create a Word document
doc = Document()
# Add a section
section = doc.AddSection()
section.PageSetup.Margins.All = 60
# Add a paragraph
paragraph = section.AddParagraph()
# Insert the syntax-highlighted code as RTF
paragraph.AppendRTF(rtf_text)
# Save the document
doc.SaveToFile("Output.docx", FileFormat.Docx2019)
doc.Dispose()
How It Works:
Pygments analyzes Python syntax using a lexer, identifying tokens such as keywords, strings, and comments. The RTF formatter applies styling rules that represent colors and fonts using RTF control words.
The resulting RTF string is inserted directly into Word using AppendRTF(). Because RTF is a native Word-compatible format, the document preserves fonts, colors, and spacing without requiring additional rendering steps.
Font size is controlled by modifying RTF control words (e.g., \fs24), allowing precise control over appearance. This method produces editable, selectable code with syntax highlighting inside Word.
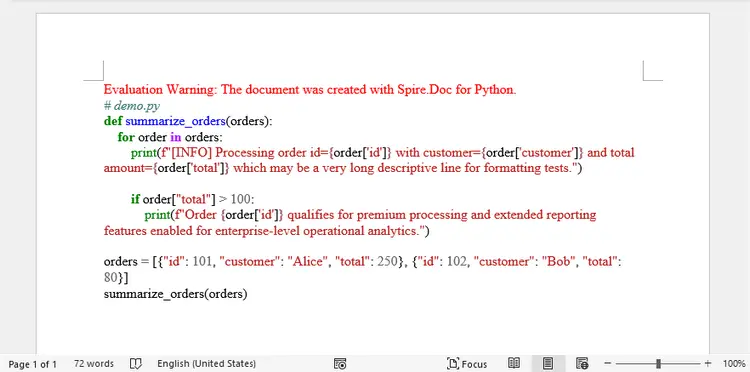
Output:
Method 2. Render Highlighted Code via HTML Formatting
HTML rendering provides visually rich syntax highlighting and automatic text wrapping.
from pathlib import Path
from pygments import highlight
from pygments.lexers import PythonLexer
from pygments.formatters import HtmlFormatter
from spire.doc import *
# Read Python file
code = Path("demo.py").read_text(encoding="utf-8")
# Generate HTML from the Python code with syntax highlighting
html_text = highlight(code, PythonLexer(), HtmlFormatter(full=True))
# Create a Word document
doc = Document()
# Add a section
section = doc.AddSection()
section.PageSetup.Margins.All = 60
# Add a paragraph
paragraph = section.AddParagraph()
# Add the HTML string to the paragraph
paragraph.AppendHTML(html_text)
# Save the document
doc.SaveToFile("Output.docx", FileFormat.Docx2019)
doc.Dispose()
How It Works:
Here, Pygments converts Python code into styled HTML using the HtmlFormatter. The HTML output includes inline styles or CSS rules that represent syntax colors and formatting.
Spire.Doc then interprets the HTML content and renders it into Word. During this process, HTML elements are translated into Word formatting structures, allowing the highlighted code to appear visually similar to web-based code blocks.
This approach is ideal when code originates from web content, static documentation sites, or Markdown-to-HTML workflows.
Output:
You May Also Like: Convert HTML to Word DOC or DOCX in Python
Method 3. Insert Syntax-Highlighted Code as Images
For scenarios where visual consistency matters more than editability, code can be rendered as an image before insertion.
from pathlib import Path
import textwrap
from pygments import highlight
from pygments.lexers import PythonLexer
from pygments.formatters import ImageFormatter
from spire.doc import *
# Read Python file
code = Path("demo.py").read_text(encoding="utf-8")
# Wrap long lines manually
def wrap_code_lines(code_text, max_width=75):
wrapped_lines = []
for line in code_text.splitlines():
if len(line) > max_width:
wrapped_lines.extend(textwrap.wrap(
line,
width=max_width,
replace_whitespace=False,
drop_whitespace=False
))
else:
wrapped_lines.append(line)
return "\n".join(wrapped_lines)
code = wrap_code_lines(code, max_width=75)
# Step 3: Generate image
formatter = ImageFormatter(
font_name="Consolas",
font_size=18,
scale=2,
image_pad=10,
line_pad=2,
background_color="#ffffff"
)
img_bytes = highlight(code, PythonLexer(), formatter)
with open("code.png", "wb") as f:
f.write(img_bytes)
# Create a Word document
doc = Document()
section = doc.AddSection()
section.PageSetup.Margins.All = 60
# Insert into Word
paragraph = section.AddParagraph()
picture = paragraph.AppendPicture("code.png")
# Ensure image fits page width
page_width = (
section.PageSetup.PageSize.Width
- section.PageSetup.Margins.Left
- section.PageSetup.Margins.Right
)
picture.Width = page_width
# Save the document
doc.SaveToFile("Output.docx", FileFormat.Docx2019)
doc.Dispose()
How It Works:
This method renders Python code as an image instead of editable text. Pygments generates a syntax-highlighted bitmap using the ImageFormatter, allowing full visual control over fonts, colors, padding, and DPI.
Since image rendering does not automatically wrap long lines, the script manually wraps lengthy code lines using Python’s textwrap module before generating the image. This prevents oversized images that exceed page width.
After inserting the image into Word, its width is dynamically resized to fit the printable page area. Because the code is embedded as a graphic, it preserves exact visual appearance across platforms and prevents formatting inconsistencies—but the text is no longer editable.
Output:
Conclusion
Converting Python code to Word documents can be achieved through several approaches depending on your goals. Plain text methods provide simplicity and flexibility, while RTF and HTML techniques offer powerful syntax highlighting with selectable text. Image-based code blocks deliver consistent visual formatting but require careful line wrapping and scaling.
For most documentation workflows:
- Use plain text for editable technical content
- Use HTML or RTF for syntax-highlighted documentation
- Use images when formatting consistency is critical
FAQs
Which method is best for tutorials?
HTML or RTF methods provide clear syntax highlighting with selectable text.
How can I preserve indentation and blank lines?
Read the .py file using .read_text() without stripping or modifying lines.
Why do image-based code blocks become too small?
Word scales images to fit page width. Increasing the image formatter’s scale or adjusting the wrapping width can improve readability.
Can readers copy code from Word?
Yes — except when code is inserted as an image.
Do I need Markdown for conversion?
No. Markdown is optional but useful when working with documentation pipelines.
Can I export the generated document as a PDF file?
Yes. When saving the document, simply specify PDF as the output format in the Document.SaveToFile() method.
Get a Free License
To fully experience the capabilities of Spire.Doc for Python without any evaluation limitations, you can request a 30-day trial license.
How to Convert HTML to Markdown in Python: Step-by-Step Guide

Converting HTML to Markdown using Python is a common task for developers managing web content, documentation, or API data. While HTML provides powerful formatting and structure, it can be verbose and harder to maintain for tasks like technical writing or static site generation. Markdown, by contrast, is lightweight, human-readable, and compatible with platforms such as GitHub, GitLab, Jekyll, and Hugo.
Automating HTML to Markdown conversion with Python streamlines workflows, reduces errors, and ensures consistent output. This guide covers everything from converting HTML files and strings to batch processing multiple files, along with best practices to ensure accurate Markdown results.
What You Will Learn
- Why Convert HTML to Markdown
- Install HTML to Markdown Library for Python
- Convert an HTML File to Markdown in Python
- Convert an HTML String to Markdown in Python
- Batch Conversion of Multiple HTML Files
- Best Practices for HTML to Markdown Conversion
- Conclusion
- FAQs
Why Convert HTML to Markdown?
Before diving into the code, let’s look at why developers often prefer Markdown over raw HTML in many workflows:
- Simplicity and Readability
Markdown is easier to read and edit than verbose HTML tags. - Portability Across Tools
Markdown is supported by GitHub, GitLab, Bitbucket, Obsidian, Notion, and static site generators like Hugo and Jekyll. - Better for Version Control
Being plain text, Markdown makes it easier to track changes with Git, review diffs, and collaborate. - Faster Content Creation
Writing Markdown is quicker than remembering HTML tag structures. - Integration with Static Site Generators
Popular frameworks rely on Markdown as the main content format. Converting from HTML ensures smooth migration. - Cleaner Documentation Workflows
Many documentation systems and wikis use Markdown as their primary format.
In short, converting HTML to Markdown improves maintainability, reduces clutter, and fits seamlessly into modern developer workflows.
Install HTML to Markdown Library for Python
Before converting HTML content to Markdown in Python, you’ll need a library that can handle both formats effectively. Spire.Doc for Python is a reliable choice that allows you to transform HTML files or HTML strings into Markdown while keeping headings, lists, images, and links intact.
You can install it from PyPI using pip:
pip install spire.doc
Once installed, you can automate the HTML to Markdown conversion in your Python scripts. The same library also supports broader scenarios. For example, when you need editable documents, you can rely on its HTML to Word conversion feature to transform web pages into Word files. And for distribution or archiving, HTML to PDF conversion is especially useful for generating standardized, platform-independent documents.
Convert an HTML File to Markdown in Python
One of the most common use cases is converting an existing .html file into a .md file. This is especially useful when migrating old websites, technical documentation, or blog posts into Markdown-based workflows, such as static site generators (Jekyll, Hugo) or Git-based documentation platforms (GitHub, GitLab, Read the Docs).
Steps
- Create a new Document instance.
- Load the .html file into the document using LoadFromFile().
- Save the document as a .md file using SaveToFile() with FileFormat.Markdown.
- Close the document to release resources.
Code Example
from spire.doc import *
# Create a Document instance
doc = Document()
# Load an existing HTML file
doc.LoadFromFile("input.html", FileFormat.Html)
# Save as Markdown file
doc.SaveToFile("output.md", FileFormat.Markdown)
# Close the document
doc.Close()
This converts input.html into output.md, preserving structural elements such as headings, paragraphs, lists, links, and images.
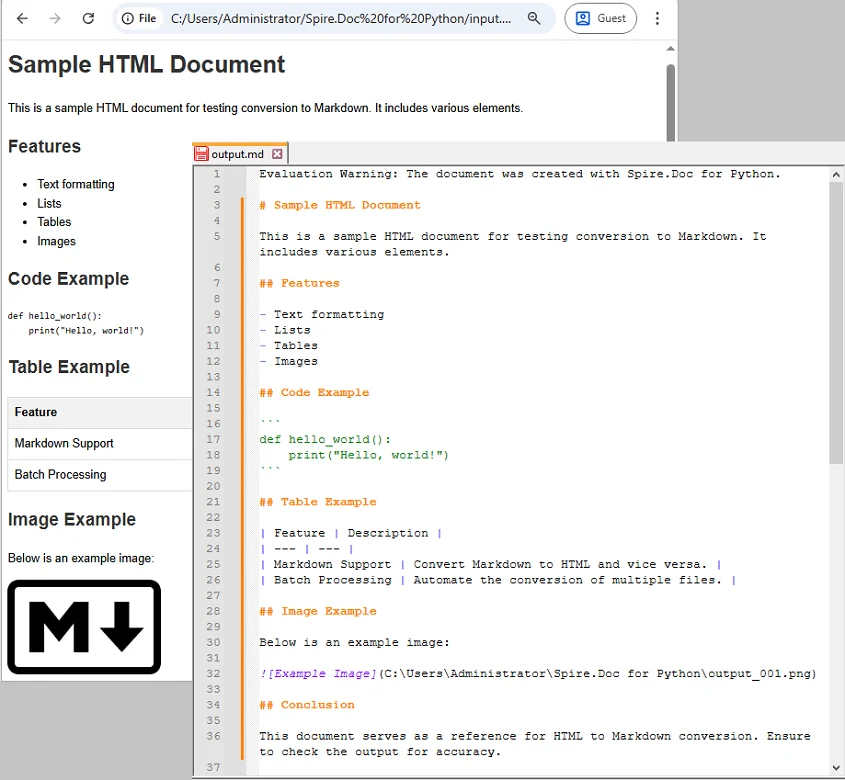
If you’re also interested in the reverse process, check out our guide on converting Markdown to HTML in Python.
Convert an HTML String to Markdown in Python
Sometimes, HTML content is not stored in a file but is dynamically generated—for example, when retrieving web content from an API or scraping. In these scenarios, you can convert directly from a string without needing to create a temporary HTML file.
Steps
- Create a new Document instance.
- Add a Section to the document.
- Add a Paragraph to the section.
- Append the HTML string to the paragraph using AppendHTML().
- Save the document as a Markdown file using SaveToFile().
- Close the document to release resources.
Code Example
from spire.doc import *
# Sample HTML string
html_content = """
<h1>Welcome</h1>
<p>This is a <strong>sample</strong> paragraph with <em>emphasis</em>.</p>
<ul>
<li>First item</li>
<li>Second item</li>
</ul>
"""
# Create a Document instance
doc = Document()
# Add a section
section = doc.AddSection()
# Add a paragraph and append the HTML string
paragraph = section.AddParagraph()
paragraph.AppendHTML(html_content)
# Save the document as Markdown
doc.SaveToFile("string_output.md", FileFormat.Markdown)
# close the document to release resources
doc.Close()
The resulting Markdown will look like this:
Batch Conversion of Multiple HTML Files
For larger projects, you may need to convert multiple .html files in bulk. A simple loop can automate the process.
import os
from spire.doc import *
# Define the folder containing HTML files to convert
input_folder = "html_files"
# Define the folder where converted Markdown files will be saved
output_folder = "markdown_files"
# Create the output folder if it doesn't exist
os.makedirs(output_folder, exist_ok=True)
# Loop through all files in the input folder
for filename in os.listdir(input_folder):
# Process only files with .html extension
if filename.endswith(".html"):
# Create a new Document object
doc = Document()
# Load the HTML file into the Document object
doc.LoadFromFile(os.path.join(input_folder, filename), FileFormat.Html)
# Generate the output file path by replacing .html with .md
output_file = os.path.join(output_folder, filename.replace(".html", ".md"))
# Save the Document as a Markdown file
doc.SaveToFile(output_file, FileFormat.Markdown)
# Close the Document to release resources
doc.Close()
This script processes all .html files inside html_files/ and saves the Markdown results into markdown_files/.
Best Practices for HTML to Markdown Conversion
Turning HTML to Markdown makes content easier to read, manage, and version-control. To ensure accurate and clean conversion, follow these best practices:
- Validate HTML Before Conversion
Ensure your HTML is properly structured. Invalid tags can cause incomplete or broken Markdown output. - Understand Markdown Limitations
Markdown does not support advanced CSS styling or custom HTML tags. Some formatting might get lost. - Choose File Encoding Carefully
Always be aware of character encoding. Open and save your files with a specific encoding (like UTF-8) to prevent issues with special characters. - Batch Processing
If converting multiple files, create a robust script that includes error handling (try-except blocks), logging, and skips problematic files instead of halting the entire process.
Conclusion
Converting HTML to Markdown in Python is a valuable skill for developers handling documentation pipelines, migrating web content, or processing data from APIs. With Spire.Doc for Python, you can:
- Convert individual HTML files into Markdown with ease.
- Transform HTML strings directly into .md files.
- Automate batch conversions to efficiently manage large projects.
By applying these methods, you can streamline your workflows and ensure your content remains clean, maintainable, and ready for modern publishing platforms.
FAQs
Q1: Can I convert Markdown back to HTML in Python?
A1: Yes, Spire.Doc supports the conversion of Markdown to HTML, allowing for seamless transitions between these formats.
Q2: Will the conversion preserve complex HTML elements like tables?
A2: While Spire.Doc effectively handles standard HTML elements, it's advisable to review complex layouts, such as tables and nested elements, to ensure accurate conversion results.
Q3: Can I automate batch conversion for multiple HTML files?
A3: Absolutely! You can automate batch conversion using scripts in Python, enabling efficient processing of multiple HTML files at once.
Q4: Is Spire.Doc free to use?
A4: Spire.Doc provides both free and commercial versions, giving developers the flexibility to access essential features at no cost or unlock advanced functionality with a license.
How to Convert Markdown to HTML in Python: Step-by-Step Guide

Markdown (.md) is widely used in web development, documentation, and technical writing. Its simple syntax makes content easy to write and read. However, web browsers do not render Markdown directly. Converting Markdown to HTML ensures your content is structured, readable, and compatible with web platforms.
In this step-by-step guide, you will learn how to efficiently convert Markdown (.md) files into HTML using Python and Spire.Doc for Python, complete with practical code examples, clear instructions, and best practices for both single-file and batch conversions.
Table of Contents
- What is Markdown
- Why Convert Markdown to HTML
- Introducing Spire.Doc for Python
- Step-by-Step Guide: Converting Markdown to HTML in Python
- Automating Batch Conversion
- Best Practices for Markdown to HTML Conversion
- Conclusion
- FAQs
What is Markdown?
Markdown is a lightweight markup language designed for readability and ease of writing. Unlike HTML, which can be verbose and harder to write by hand, Markdown uses simple syntax to indicate headings, lists, links, images, and more.
Example Markdown:
# This is a Heading
This is a paragraph with \*\*bold text\*\* and \*italic text\*.
- Item 1
- Item 2
Even in its raw form, Markdown is easy to read, which makes it popular for documentation, blogging, README files, and technical writing.
For more on Markdown syntax, see the Markdown Guide.
Why Convert Markdown to HTML?
While Markdown is excellent for authoring content, web browsers cannot render it natively. Converting Markdown to HTML allows you to:
- Publish content on websites – Most CMS platforms require HTML for web pages.
- Enhance styling – HTML supports CSS and JavaScript for advanced formatting and interactivity.
- Maintain compatibility – HTML is universally supported by browsers, ensuring content displays correctly everywhere.
- Integrate with web frameworks – Frameworks like React, Vue, and Angular require HTML as the base for rendering components.
Introducing Spire.Doc for Python
Spire.Doc for Python is a robust library for handling multiple document formats. It supports reading and writing Word documents, Markdown files, and exporting content to HTML. The library allows developers to convert Markdown directly to HTML with minimal code, preserving proper formatting and structure.
In addition to HTML, Spire.Doc for Python also allows you to convert Markdown to Word in Python or convert Markdown to PDF in Python, making it particularly useful for developers who want a unified tool for handling Markdown across different output formats.
Benefits of Using Spire.Doc for Python for Markdown to HTML Conversion
- Easy-to-use API – Simple, intuitive methods that reduce development effort.
- Accurate formatting – Preserves all Markdown elements such as headings, lists, links, and emphasis in HTML.
- No extra dependencies – Eliminates the need for manual parsing or third-party libraries.
- Flexible usage – Supports both single-file conversion and automated batch processing.
Step-by-Step Guide: Converting Markdown to HTML in Python
Now that you understand the purpose and benefits of converting Markdown to HTML, let’s walk through a clear, step-by-step process to transform your Markdown files into structured, web-ready HTML.
Step 1: Install Spire.Doc for Python
First, ensure that Spire.Doc for Python is installed in your environment. You can install it directly from PyPI using pip:
pip install spire.doc
Step 2: Prepare Your Markdown File
Next, create a sample Markdown file that you want to convert. For example, example.md:
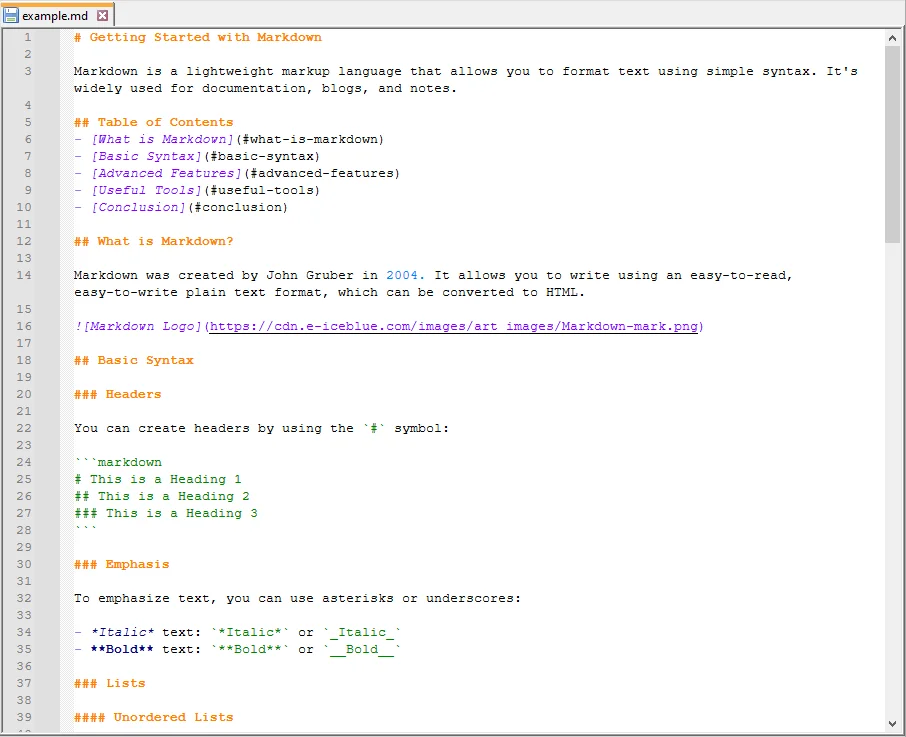
Step 3: Write the Python Script
Now, write a Python script that loads the Markdown file and converts it to HTML:
from spire.doc import *
# Create a Document object
doc = Document()
# Load the Markdown file
doc.LoadFromFile("example.md", FileFormat.Markdown)
# Save the document as HTML
doc.SaveToFile("example.html", FileFormat.Html)
# Close the document
doc.Close()
Explanation of the code:
- Document() initializes a new document object.
- LoadFromFile("example.md", FileFormat.Markdown) loads the Markdown file into memory.
- SaveToFile("example.html", FileFormat.Html) converts the loaded content into HTML and saves it to disk.
- doc.Close() ensures resources are released properly, which is particularly important when processing multiple files or running batch operations.
Step 4: Verify the HTML Output
Finally, open the generated example.html file in a web browser or HTML editor. Verify that the Markdown content has been correctly converted.

Automating Batch Conversion
You can convert multiple Markdown files in a folder automatically:
import os
from spire.doc import *
# Set the folder containing Markdown files
input_folder = "markdown_files"
# Set the folder where HTML files will be saved
output_folder = "html_files"
# Create the output folder if it doesn't exist
os.makedirs(output_folder, exist_ok=True)
# Loop through all files in the input folder
for filename in os.listdir(input_folder):
# Process only Markdown files
if filename.endswith(".md"):
# Create a new Document object for each file
doc = Document()
# Load the Markdown file into the Document object
doc.LoadFromFile(os.path.join(input_folder, filename), FileFormat.Markdown)
# Construct the output file path by replacing .md extension with .html
output_file = os.path.join(output_folder, filename.replace(".md", ".html"))
# Save the loaded Markdown content as HTML
doc.SaveToFile(output_file, FileFormat.Html)
# Close the document to release resources
doc.Close()
This approach allows you to process multiple Markdown files efficiently and generate corresponding HTML files automatically.
Best Practices for Markdown to HTML Conversion
While the basic steps are enough to complete a Markdown-to-HTML conversion, following a few best practices will help you avoid common pitfalls, improve compatibility, and ensure your output is both clean and professional:
- Use proper Markdown syntax – Ensure headings, lists, links, and emphasis are correctly written.
- Use UTF-8 Encoding: Always save your Markdown files in UTF-8 encoding to avoid issues with special characters or non-English text.
- Batch Processing: If you need to convert multiple files, wrap your script in a loop and process entire folders. This saves time and ensures consistent formatting across documents.
- Enhance Styling: Remember that HTML gives you the flexibility to add CSS and JavaScript for custom layouts, responsive design, and interactivity—something not possible in raw Markdown.
Conclusion
Converting Markdown to HTML using Python with Spire.Doc is simple, reliable, and efficient. It preserves formatting, supports automation, and produces clean HTML output ready for web use. By following this guide, you can implement a smooth Markdown to HTML workflow for both single documents and batch operations.
FAQs
Q1: Can I convert multiple Markdown files to HTML in Python?
A1: Yes, you can automate batch conversions by iterating through Markdown files in a directory and applying the conversion logic to each file.
Q2: Will the HTML preserve all Markdown formatting?
A2: Yes, Spire.Doc effectively preserves all essential Markdown formatting, including headings, lists, bold and italic text, links, and more.
Q3: Is there a way to handle images in Markdown during conversion?
A3: Yes, Spire.Doc supports the conversion of images embedded in Markdown, ensuring they are included in the resulting HTML.
Q4: Do I need additional libraries besides Spire.Doc?
A4: No additional libraries are required. Spire.Doc for Python provides a comprehensive solution for converting Markdown to HTML without any external dependencies.
Q5: Can I use the generated HTML in web frameworks?
A5: Yes, the HTML produced is fully compatible with popular web frameworks such as React, Vue, and Angular, making integration seamless.
Convert HTML to Text in Python | Simple Plain Text Output

HTML (HyperText Markup Language) is a markup language used to create web pages, allowing developers to build rich and visually appealing layouts. However, HTML files often contain a large number of tags, which makes them difficult to read if you only need the main content. By using Python to convert HTML to text, this problem can be easily solved. Unlike raw HTML, the converted text file strips away all unnecessary markup, leaving only clean and readable content that is easier to store, analyze, or process further.
- Install HTML to Text Converter in Python
- Python Convert HTML File to Text
- Python Convert HTML String to Text
- The Conclusion
- FAQs
Install HTML to Text Converter in Python
To simplify the task, we recommend using Spire.Doc for Python. This Python Word library allows you to quickly remove HTML markup and extract clean plain text with ease. It not only works as an HTML-to-text converter, but also offers a wide range of features—covering almost everything you can do in Microsoft Word.
To install it, you can run the following pip command:
pip install spire.doc
Alternatively, you can download the Spire.Doc package and install it manually.
Python Convert HTML Files to Text in 3 Steps
After preparing the necessary tools, let's dive into today's main topic: how to convert HTML to plain text using Python. With the help of Spire.Doc, this task can be accomplished in just three simple steps: create a new document object, load the HTML file, and save it as a text file. It’s straightforward and efficient, even for beginners. Let’s take a closer look at how this process can be implemented in code!
Code Example – Converting an HTML File to a Text File:
from spire.doc import *
from spire.doc.common import *
# Open an html file
document = Document()
document.LoadFromFile("/input/htmlsample.html", FileFormat.Html, XHTMLValidationType.none)
# Save it as a Text document.
document.SaveToFile("/output/HtmlFileTotext.txt", FileFormat.Txt)
document.Close()
The following is a preview comparison between the source document (.html) and the output document (.txt):
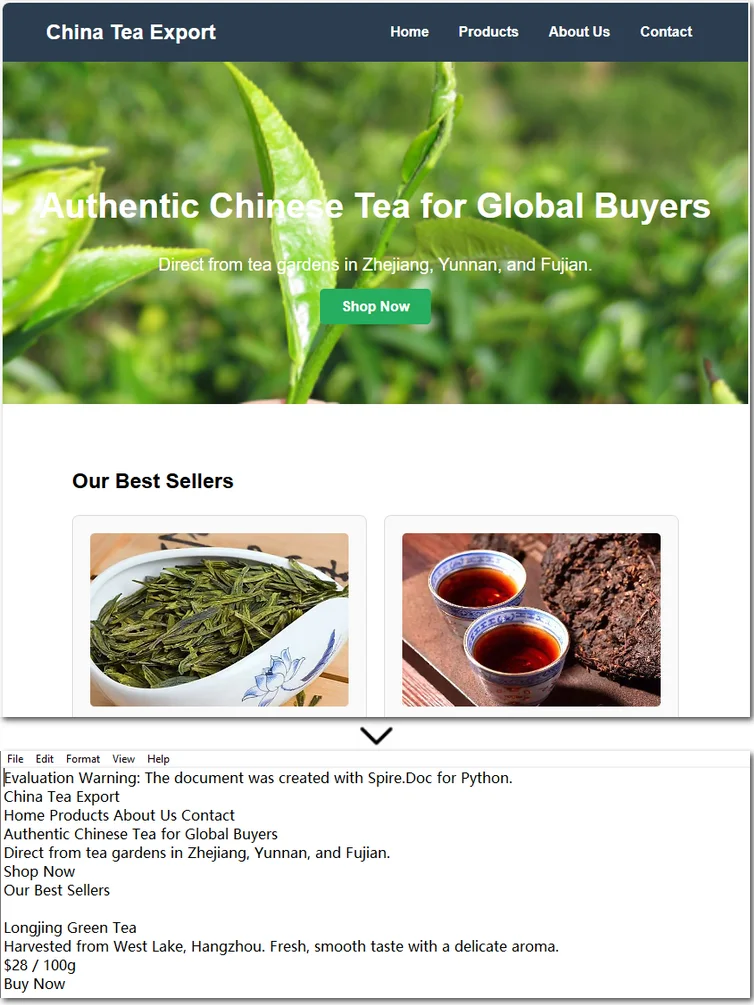
Note that if the HTML file contains tables, the output text file will only retain the values within the tables and cannot preserve the original table formatting. If you want to keep certain styles while removing markup, it is recommended to convert HTML to a Word document . This way, you can retain headings, tables, and other formatting, making the content easier to edit and use.
How to Convert an HTML String to Text in Python
Sometimes, we don’t need the entire content of a web page and only want to extract specific parts. In such cases, you can convert an HTML string directly to text. This approach allows you to precisely control the information you need without further editing. Using Python to convert an HTML string to a text file is also straightforward. Here’s a detailed step-by-step guide:
Steps to convert an HTML string to a text document using Spire.Doc:
- Input the HTML string directly or read it from a local file.
- Create a Document object and add sections and paragraphs.
- Use Paragraph.AppendHTML() method to insert the HTML string into a paragraph.
- Save the document as a .txt file using Document.SaveToFile() method.
The following code demonstrates how to convert an HTML string to a text file using Python:
from spire.doc import *
from spire.doc.common import *
#Get html string.
#with open(inputFile) as fp:
#HTML = fp.read()
# Load HTML from string
html = """<!DOCTYPE html>
<html lang="en">
<head>
<meta charset="UTF-8">
<title>HTML to Text Example</title>
<style>
body { font-family: Arial, sans-serif; margin: 20px; }
header { background: #f4f4f4; padding: 10px; }
nav a { margin: 0 10px; text-decoration: none; color: #333; }
main { margin-top: 20px; }
</style>
</head>
<body>
<header>
<h1>My Demo Page</h1>
<nav>
<a href="#">Home</a>
<a href="#">About</a>
<a href="#">Contact</a>
</nav>
</header>
<main>
<h2>Convert HTML to Text</h2>
<p>This is a simple demo showing how HTML content can be displayed before converting it to plain text.</p>
</main>
</body>
</html>
"""
# Create a new document
document = Document()
section = document.AddSection()
section.AddParagraph().AppendHTML(html)
# Save directly as TXT
document.SaveToFile("/output/HtmlStringTotext.txt", FileFormat.Txt)
document.Close()
Here's the preview of the converted .txt file: 
The Conclusion
In today’s tutorial, we focused on how to use Python to convert HTML to a text file. With the help of Spire.Doc, you can handle both HTML files and HTML strings in just a few lines of code, easily generating clean plain text files. If you’re interested in the other powerful features of the Python Word library, you can request a 30-day free trial license and explore its full capabilities for yourself.
FAQs about Converting HTML to Text in Python
Q1: How can I convert HTML to plain text using Python?
A: Use Spire.Doc to load an HTML file or string, insert it into a Document object with AppendHTML(), and save it as a .txt file.
Q2: Can I keep some formatting when converting HTML to text?
A: To retain styles like headings or tables, convert HTML to a Word document first, then export to text if needed.
Q3: Is it possible to convert only part of an HTML page to text?
A: Yes, extract the specific HTML segment as a string and convert it to text using Python for precise control.
Python: Convert Word to Excel
While Word is a powerful tool for creating and formatting documents, it is not optimized for advanced data management and analysis. In contrast, Excel excels at handling data in tabular form, allowing users to perform calculations, create charts, and conduct thorough data analysis.
Generally, converting complex Word documents into Excel spreadsheets is not advisable, as Excel may struggle to preserve the original layout. However, if your Word document primarily consists of tables, converting it to Excel can be highly beneficial. This transformation unlocks Excel's advanced functions, formulas, and visualization tools, enabling you to organize your data more effectively and improve your reporting and decision-making capabilities. In this article, we will focus specifically on how to convert this kind of Word documents to Excel in Python using Spire.Office for Python.
Install Spire.Office for Python
This scenario requires Spire.Office for Python and plum-dispatch v1.7.4. They can be easily installed in your Windows through the following pip command.
pip install Spire.Office
Convert Word to Excel in Python
This process uses two libraries in the Spire.Office for Python package. They're Spire.XLS for Python and Spire.Doc for Python. The former is used to read and extract content from a Word document, and the latter is used to create an Excel document and write data in specific cells. To make this code example easy to understand, we have defined the following three custom methods that handle specific tasks:
- ExportTableInExcel() - Export data from a Word table to specified Excel cells.
- CopyContentInTable() - Copy content from a table cell in Word to an Excel cell.
- CopyTextAndStyle() - Copy text with formatting from a Word paragraph to an Excel cell.
The following steps demonstrate how to export data from an entire Word document to an Excel worksheet using Spire.Office for Python.
- Create a Document object to load a Word file.
- Create a Worbbook object and add a worksheet named "WordToExcel" to it.
- Traverse through all the sections in the Word document and all the document objects under a certain section, and then determine if a document object is a paragraph or a table.
- If the document object is a paragraph, write the paragraph in a specified cell in Excel using CoypTextAndStyle() method.
- If the document object is a table, export the table data from Word to Excel cells using ExportTableInExcel() method.
- Auto fit the row height and column width in Excel so that the data within a cell will not exceed the bound of the cell.
- Save the workbook to an Excel file using Workbook.SaveToFile() method.
- Python
from spire.xls import *
from spire.doc import *
# Export data from Word table to Excel cells
def ExportTableInExcel(worksheet, row, table):
for rowIndex in range(len(table.Rows)):
tbRow = table.Rows[rowIndex]
column = 1
for cellIndex in range(len(tbRow.Cells)):
tbCell = tbRow.Cells[cellIndex]
cell = worksheet.Range[row, column]
cell.BorderAround()
CopyContentInTable(worksheet, tbCell, cell)
column += 1
row += 1
return row
# Copy content from a Word table cell to an Excel cell
def CopyContentInTable(worksheet, tbCell, cell):
newPara = Paragraph(tbCell.Document)
for i in range(len(tbCell.ChildObjects)):
documentObject = tbCell.ChildObjects[i]
if isinstance(documentObject, Paragraph):
paragraph = documentObject
for cObj in range(len(paragraph.ChildObjects)):
newPara.ChildObjects.Add(paragraph.ChildObjects[cObj].Clone())
if i < len(tbCell.ChildObjects) - 1:
newPara.AppendText("\n")
CopyTextAndStyle(worksheet, cell, newPara)
# Copy text and style of a paragraph to a cell
def CopyTextAndStyle(worksheet, cell, paragraph):
richText = cell.RichText
richText.Text = paragraph.Text
startIndex = 0
for documentObject in range(len(paragraph.ChildObjects)):
documentObject = paragraph.ChildObjects[documentObject]
if isinstance(documentObject, TextRange):
textRange = documentObject
fontName = textRange.CharacterFormat.FontName
isBold = textRange.CharacterFormat.Bold
textColor = textRange.CharacterFormat.TextColor
fontSize = textRange.CharacterFormat.FontSize
textRangeText = textRange.Text
strLength = len(textRangeText)
font = worksheet.Workbook.CreateFont()
font.Color = textColor
font.IsBold = isBold
font.Size = fontSize
font.FontName = fontName
endIndex = startIndex + strLength
richText.SetFont(startIndex, endIndex, font)
startIndex += strLength
if isinstance(documentObject, DocPicture):
picture = documentObject
worksheet.Pictures.Add(cell.Row, cell.Column, picture.Image)
worksheet.SetRowHeightInPixels(cell.Row, 1, picture.Image.Height)
if paragraph.Format.HorizontalAlignment == HorizontalAlignment.Left:
cell.Style.HorizontalAlignment = HorizontalAlignType.Left
elif paragraph.Format.HorizontalAlignment == HorizontalAlignment.Center:
cell.Style.HorizontalAlignment = HorizontalAlignType.Center
elif paragraph.Format.HorizontalAlignment == HorizontalAlignment.Right:
cell.Style.HorizontalAlignment = HorizontalAlignType.Right
# Create a Document object
doc = Document()
# Load a Word file
doc.LoadFromFile("C:/Users/Administrator/Desktop/Invoice.docx")
# Create a Workbook object
wb = Workbook()
# Remove the default worksheets
wb.Worksheets.Clear()
# Create a worksheet named "WordToExcel"
worksheet = wb.CreateEmptySheet("WordToExcel")
row = 1
column = 1
# Loop through the sections in the Word document
for sec_index in range(doc.Sections.Count):
section = doc.Sections[sec_index]
# Loop through the document object under a certain section
for obj_index in range(section.Body.ChildObjects.Count):
documentObject = section.Body.ChildObjects[obj_index]
# Determine if the object is a paragraph
if isinstance(documentObject, Paragraph):
cell = worksheet.Range[row, column]
paragraph = documentObject
# Copy paragraph from Word to a specific cell
CopyTextAndStyle(worksheet, cell, paragraph)
row += 1
# Determine if the object is a table
if isinstance(documentObject, Table):
table = documentObject
# Export table data from Word to Excel
currentRow = ExportTableInExcel(worksheet, row, table)
row = currentRow
# Auto fit row height and column width
worksheet.AllocatedRange.AutoFitRows()
worksheet.AllocatedRange.AutoFitColumns()
# Wrap text in cells
worksheet.AllocatedRange.IsWrapText = True
# Save the workbook to an Excel file
wb.SaveToFile("WordToExcel.xlsx", ExcelVersion.Version2013)
wb.Dispose()
doc.Dispose()
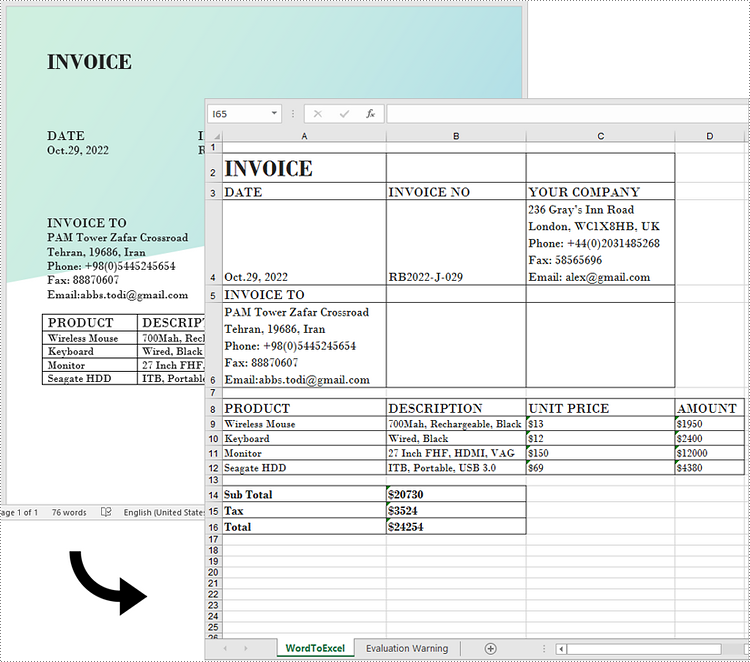
Get a Free License
To fully experience the capabilities of Spire.Doc for Python without any evaluation limitations, you can request a free 30-day trial license.
Python: Convert Word to XML, Word XML
XML (Extensible Markup Language) is widely used for its structured format and readability on different platforms and systems. Its self-descriptive tags enable you to process data more easily. Meanwhile, Word XML focuses specifically on storing and exchanging Microsoft Word documents. It allows Word documents to transfer without loss. They both show flexibility under various scenarios that Word documents cannot achieve.
On the page, you will learn how to convert Word to XML and Word XML formats using Python with Spire.Doc for Python.
Install Spire.Doc for Python
This scenario requires Spire.Doc for Python and plum-dispatch v1.7.4. They can be easily installed in your Windows through the following pip command.
pip install Spire.Doc
If you are unsure how to install, please refer to this tutorial: How to Install Spire.Doc for Python on Windows.
Convert Word to XML in Python with Spire.Doc for Python
This part will explain how to convert Word documents to XML in Python with step-by-step instructions and a code example. Spire.Doc for Python provides the Document.SaveToFile() method to make it easy to save Word as XML. Check out the steps below and start processing your Word documents without effort!
Steps to Convert Word to XML:
- Create a new Document object.
- Load the Word document that you wish to be operated using Document.LoadFromFile() method.
- Covert it to XML by calling Document.SaveToFile() method.
Here's the code example:
- Python
from spire.doc import *
from spire.doc.common import *
# Create a Word document object
document = Document()
# Load the file from the disk
document.LoadFromFile("sample.docx")
# Save the document to an XML file
document.SaveToFile("WordtoXML.xml", FileFormat.Xml)
document.Close()

Convert Word to Word XML in Python
To convert Word to Word XML, you can utilize the Document.SaveToFile() method provided by Spire.Doc for Python. It not only helps to convert Word documents to Word XML but also to many other formats, such as PDF, XPS, HTML, RTF, etc.
Steps to Convert Word to Word XML:
- Create a new Document object.
- Load the Word document by Document.LoadFromFile() method.
- Convert it to Word XML using Document.SaveToFile() method.
Here's the code example for you:
- Python
from spire.doc import *
from spire.doc.common import *
# Create a Word document object
document = Document()
# Load the file from the disk
document.LoadFromFile("sample.docx")
# For Word 2003
document.SaveToFile("WordtoWordML.wordml", FileFormat.WordML)
# For Word 2007-2013
document.SaveToFile("WordtoWordXML.wordxml", FileFormat.WordXml)
document.Close()

Get a Free License
To fully experience the capabilities of Spire.Doc for Python without any evaluation limitations, you can request a free 30-day trial license.
Python: Convert Markdown to PDF
Markdown has become a popular choice for writing structured text due to its simplicity and readability, making it widely used for documentation, README files, and note-taking. However, sometimes there arises a need to present this content in a more universal and polished format, such as PDF, which is compatible across various devices and platforms without formatting inconsistencies. Converting Markdown files to PDF documents not only enhances portability but also adds a professional touch, enabling easier distribution for reports, manuals, or sharing content with non-technical audiences who may not be familiar with Markdown syntax.
This article will demonstrate how to convert Markdown files to PDF documents using Spire.Doc for Python to automate the conversion process.
- Convert Markdown Files to PDF Documents with Python
- Convert Markdown to PDF and Customize Page Settings
Install Spire.Doc for Python
This scenario requires Spire.Doc for Python and plum-dispatch v1.7.4. They can be easily installed in your Windows through the following pip command.
pip install Spire.Doc
If you are unsure how to install, please refer to: How to Install Spire.Doc for Python on Windows
Convert Markdown Files to PDF Documents with Python
With Spire.Doc for Python, developers can load Markdown files using Document.LoadFromFile(string: fileName, FileFormat.Markdown) method, and then save the files to PDF documents using Document.SaveToFile(string: fileName, FileFormat.PDF) method. Besides, developers can also convert Markdown files to HTML, XPS, and SVG formats by specifying enumeration items of the FileFormat enumeration class.
The detailed steps for converting a Markdown file to a PDF document are as follows:
- Create an instance of Document class.
- Load a Markdown file using Document.LoadFromFile(string: fileName, FileFormat.Markdown) method.
- Convert the Markdown file to a PDF document and save it using Document.SaveToFile(string: fileName, FileFormat.PDF) method.
- Python
from spire.doc import *
from spire.doc.common import *
# Create an object of Document class
doc = Document()
# Load a Markdown file
doc.LoadFromFile("Sample.md", FileFormat.Markdown)
# Save the file to a PDF document
doc.SaveToFile("output/MarkdownToPDF.pdf", FileFormat.PDF)
doc.Dispose()
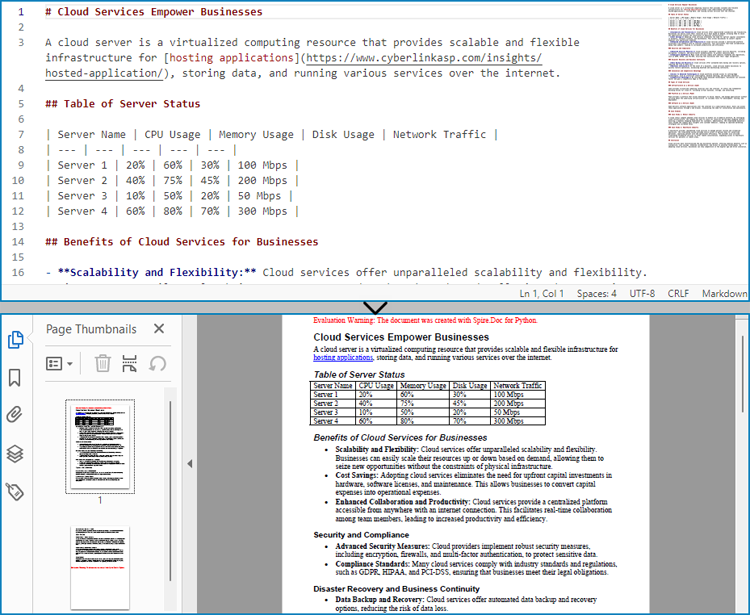
Convert Markdown to PDF and Customize Page Settings
Spire.Doc for Python supports performing basic page setup before converting Markdown files to formats like PDF, allowing for control over the appearance of the converted document.
The detailed steps to convert a Markdown file to a PDF document and customize the page settings are as follows:
- Create an instance of Document class.
- Load a Markdown file using Document.LoadFromFile(string: fileName, FileFormat.Markdown) method.
- Get the default section using Document.Sections.get_Item() method.
- Get the page settings through Section.PageSetup property and set the page size, orientation, and margins through properties under PageSetup class.
- Convert the Markdown file to a PDF document and save it using Document.SaveToFile(string: fileName, FileFormat.PDF) method.
- Python
from spire.doc import *
from spire.doc.common import *
# Create an instance of Document class
doc = Document()
# Load a Word document
doc.LoadFromFile("Sample.md", FileFormat.Markdown)
# Get the default section
section = doc.Sections.get_Item(0)
# Get the page settings
pageSetup = section.PageSetup
# Customize the page settings
pageSetup.PageSize = PageSize.A4()
pageSetup.Orientation = PageOrientation.Landscape
pageSetup.Margins.All = 50
# Save the Markdown document to a PDF file
doc.SaveToFile("output/MarkdownToPDFPageSetup.pdf", FileFormat.PDF)
doc.Dispose()
Get a Free License
To fully experience the capabilities of Spire.Doc for Python without any evaluation limitations, you can request a free 30-day trial license.