
Program Guide (4)
Children categories

Optical Character Recognition (OCR) has become an indispensable technology in modern software development, enabling computers to convert different types of documents, such as images or scanned documents, into editable and searchable text. In the Java ecosystem, integrating OCR capabilities enables powerful document processing, data extraction, and accessibility features. This guide explores how to implement OCR in Java using the Spire.OCR for Java library, leveraging its advanced features to extract text from images with or without positional coordinates.
Table of Contents:
- Why Perform OCR in Java?
- Environment Setup & Configuration
- Extract Text from an Image in Java
- Extract Text with Coordinates from an Image in Java
- Advanced OCR Techniques
- FAQs (Supported Languages and Image Formats)
- Conclusion & Free License
Why Perform OCR in Java?
OCR technology transforms images into machine-readable text. Java developers leverage OCR for:
- Automating invoice/receipt processing
- Digitizing printed records and forms
- Enabling text search in scanned documents
- Extracting structured data with spatial coordinates
Spire.OCR for Java stands out with its:
- Advanced OCR algorithms ensure accurate text recognition.
- Support for multiple image formats and languages.
- Batch processing of multiple images, improving efficiency.
- Ease of integration with Java applications
Environment Setup & Configuration
Step 1: Add Spire.OCR to Your Project
Add the following to your pom.xml:
<repositories>
<repository>
<id>com.e-iceblue</id>
<name>e-iceblue</name>
<url>https://repo.e-iceblue.com/nexus/content/groups/public/</url>
</repository>
</repositories>
<dependency>
<groupId>e-iceblue</groupId>
<artifactId>spire.ocr</artifactId>
<version>2.1.1</version>
</dependency>
Alternatively, you can download the Spire.OCR for Java library, and then add it to your Java project.
Step 2: Download the OCR Model Files
Spire.OCR for Java relies on pre-trained models to extract image text. Download the OCR model files for your OS:
After downloading, unzip the files to a directory (e.g., F:\win-x64)
Extract Text from an Image in Java
The following is a basic text extraction example, i.e., reading text from an image and saving it to .txt files.
Use Cases:
- Archiving printed materials (e.g., books, newspapers) as digital text.
- Converting images (e.g., screenshots, memes, signs) into shareable/editable text.
Java code to get text from an image:
import com.spire.ocr.*;
import java.io.BufferedWriter;
import java.io.FileWriter;
import java.io.IOException;
public class ocrJava {
public static void main(String[] args) throws Exception {
// Create an instance of the OcrScanner class
OcrScanner scanner = new OcrScanner();
// Create an instance of the ConfigureOptions class
ConfigureOptions configureOptions = new ConfigureOptions();
// Set the path to the OCR model
configureOptions.setModelPath("F:\\win-x64");
// Set the language for text recognition
configureOptions.setLanguage("English");
// Apply the configuration options to the scanner
scanner.ConfigureDependencies(configureOptions);
// Extract text from an image
scanner.scan("sample.png");
String text = scanner.getText().toString();
// Save the extracted text to a text file
try (BufferedWriter writer = new BufferedWriter(new FileWriter("output.txt"))) {
writer.write(text);
} catch (IOException e) {
e.printStackTrace();
}
}
}
Key Steps:
-
Initialize Scanner: OcrScanner handles OCR operations
-
Configure Settings:
- setModelPath(): Location of OCR model files
- setLanguage(): Supports multiple languages (Chinese, Spanish, etc.)
-
Process Image: scan() performs OCR on the image file
-
Export Text: getText() retrieves results as a string
Output:

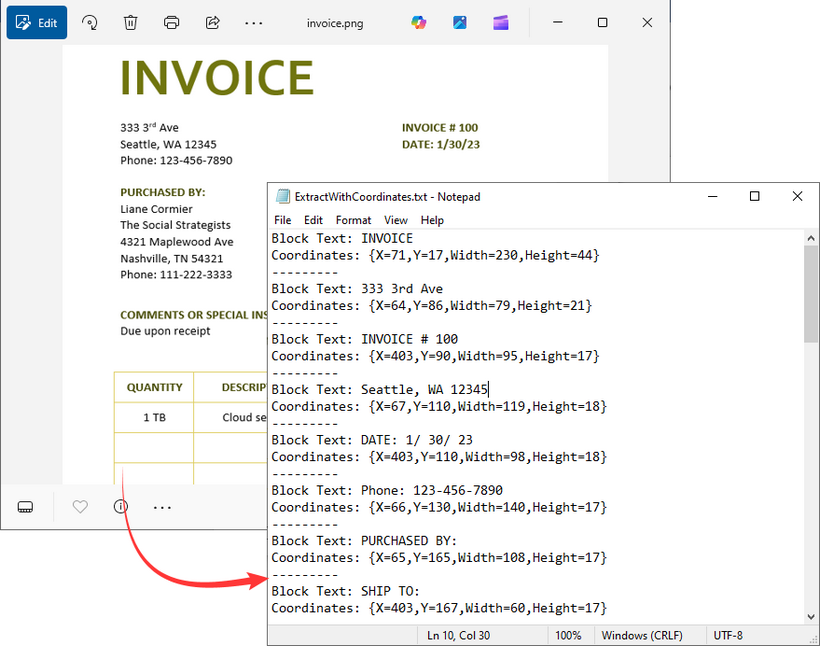
Extract Text with Coordinates from an Image in Java
In some applications, knowing the position of text within the image is crucial, for example, when processing structured documents like invoices or forms. The Spire.OCR library supports this through its block-based text extraction feature.
Use Cases:
- Automated invoice processing (locate amounts, dates)
- Form data extraction (identify fields by position)
Java code to extract text with coordinates:
import com.spire.ocr.*;
import java.io.IOException;
import java.nio.file.Files;
import java.nio.file.Paths;
import java.util.ArrayList;
import java.util.List;
public class ExtractWithCoordinates {
public static void main(String[] args) throws Exception {
// Create an instance of the OcrScanner class
OcrScanner scanner = new OcrScanner();
// Create an instance of the ConfigureOptions class
ConfigureOptions configureOptions = new ConfigureOptions();
// Set the path to the OCR model
configureOptions.setModelPath("F:\\win-x64");
// Set the language for text recognition
configureOptions.setLanguage("English");
// Apply the configuration options to the scanner
scanner.ConfigureDependencies(configureOptions);
// Extract text from an image
scanner.scan("invoice.png");
IOCRText text = scanner.getText();
// Create a list to store information
List<String> results = new ArrayList<>();
// Iterate through each detected text block
for (IOCRTextBlock block : text.getBlocks()) {
// Add the extracted text and coordinates to the list
results.add("Block Text: " + block.getText());
results.add("Coordinates: " + block.getBox());
results.add("---------");
}
// Save to a text file
try {
Files.write(Paths.get("ExtractWithCoordinates.txt"), results);
} catch (IOException e) {
e.printStackTrace();
}
}
}
Key Features:
-
Text & Coordinate Extraction:
-
Iterates over text blocks detected in the image.
-
getText(): Returns an IOCRText object containing recognized text.
-
getBox(): Returns bounding box coordinates [x, y, width, height]
-
-
Efficient File Writing:
-
Uses Java NIO for efficient file operations.
-
Outputs human-readable results for easy parsing.
-
Output:
Advanced OCR Techniques
1. Enable Auto-Rotation of Images
For accurate processing of skewed or rotated images, enable the SetAutoRotate() method to rotate the image to the correct upright position automatically:
ConfigureOptions configureOptions = new ConfigureOptions();
configureOptions.SetAutoRotate(true);
2. Preserve the Original Layout
If you need to preserve the original visual layout in the image (e.g., table, multi-column layout), initialize the VisualTextAligner class to enhance the formatting of the extracted text.
// Align the recognized text (for better formatting)
VisualTextAligner visualTextAligner = new VisualTextAligner(scanner.getText());
String scannedText = visualTextAligner.toString();
FAQs (Supported Languages and Image Formats)
Q1: What image formats does Spire.OCR for Java support?
A: Spire.OCR for Java supports all common formats:
- PNG
- JPEG/JPG
- BMP
- TIFF
- GIF
Q2: What languages does Spire.OCR for Java support?
A: Multiple languages are supported:
- English (default)
- Chinese (Simplified and Traditional)
- Japanese
- Korean
- German
- French
Q3: How to improve OCR accuracy?
A: To boost accuracy:
- Use high-quality images (300+ DPI, well-lit, low noise).
- Preprocess images (adjust contrast, remove artifacts) before scanning.
- Specify the correct language(s) for the text in the image.
Q4: Can Spire.OCR for Java extract text from scanned PDFs?
A: This task requires the Spire.PDF for Java integration to convert PDFs to images or extract images from scanned PDFs first, and then use the above Java examples to get text from the images.
Conclusion & Free License
This guide provides a comprehensive roadmap for mastering Spire.OCR for Java, equipping developers with the knowledge to seamlessly integrate powerful OCR capabilities into their Java applications. From step-by-step installation to implementing basic and advanced text extraction, every critical aspect of recognizing text from images has been covered. Whether you're new to OCR or experienced, you now have the tools to convert images to text simply and effectively.
Request a 30-day free trial license here to enjoy unlimited OCR processing in Java.
Spire.OCR for Java is a professional OCR library to read text from Images in JPG, PNG, GIF, BMP and TIFF formats. Developers can easily add OCR functionalities on Java applications (J2SE and J2EE). It supports commonly used image formats and provides functionalities like reading multiple characters and fonts from images, bold and italic styles and much more.
Spire.OCR for Java provides a very easy way to extract text from images. With just three lines of code in Java, Spire.OCR supports read texts from variable common image formats, such as Bitmap, JPG, PNG, TIFF and GIF.
Java: Extract Text from Images Using the New Model of Spire.OCR for Java
2024-09-14 00:59:31 Written by hayes LiuSpire.OCR for Java offers developers a new model for extracting text from images. In this article, we will demonstrate how to extract text from images in Java using the new model of Spire.OCR for Java.
The detailed steps are as follows.
Step 1: Create a Java Project in IntelliJ IDEA.
Step 2: Add Spire.OCR.jar to Your Project.
Option 1: Install Spire.OCR for Java via Maven.
If you're using Maven, you can install Spire.OCR for Java by adding the following code to your project's pom.xml file:
<repositories>
<repository>
<id>com.e-iceblue</id>
<name>e-iceblue</name>
<url>https://repo.e-iceblue.com/nexus/content/groups/public/</url>
</repository>
</repositories>
<dependencies>
<dependency>
<groupId>e-iceblue</groupId>
<artifactId>spire.ocr</artifactId>
<version>2.1.5</version>
</dependency>
</dependencies>
Option 2: Manually Import Spire.OCR.jar.
First, download Spire.OCR for Java from the following link and extract it to a specific directory:
https://www.e-iceblue.com/Download/ocr-for-java.html
Next, in IntelliJ IDEA, go to File > Project Structure > Modules > Dependencies. In the Dependencies pane, click the "+" button and select JARs or Directories. Navigate to the directory where Spire.OCR for Java is located, open the lib folder and select the Spire.OCR.jar file, then click OK to add it as the project’s dependency.
Step 3: Download the New Model of Spire.OCR for Java.
Download the model that fits in with your operating system from one of the following links.
Linux x64 (CentOS 8, Ubuntu 18 and above versions are required)
Then extract the package and save it to a specific directory on your computer. In this example, we saved the package to "D:\".
Step 4: Implement Text Extraction from Images Using the New Model of Spire.OCR for Java.
Use the following code to extract text from images with the new OCR model of Spire.OCR for Java:
- Java
import com.spire.ocr.*;
import java.io.BufferedWriter;
import java.io.FileWriter;
import java.io.IOException;
public class Main {
public static void main(String[] args) {
try {
// Create an instance of the OcrScanner class
OcrScanner scanner = new OcrScanner();
// Create an instance of the ConfigureOptions class to set up the scanner configurations
ConfigureOptions configureOptions = new ConfigureOptions();
// Set the path to the new model
configureOptions.setModelPath("D:\\win-x64");
// Set the language for text recognition. The default is English.
// Supported languages include English, Chinese, Chinesetraditional, French, German, Japanese, and Korean.
configureOptions.setLanguage("English");
// Apply the configuration options to the scanner
scanner.ConfigureDependencies(configureOptions);
// Extract text from an image
scanner.scan("Sample.png");
// Save the extracted text to a text file
saveTextToFile(scanner, "output.txt");
} catch (OcrException e) {
e.printStackTrace();
}
}
private static void saveTextToFile(OcrScanner scanner, String filePath) {
try {
String text = scanner.getText().toString();
try (BufferedWriter writer = new BufferedWriter(new FileWriter(filePath))) {
writer.write(text);
}
} catch (IOException | OcrException e) {
e.printStackTrace();
}
}
}
Apply for a Temporary License
If you'd like to remove the evaluation message from the generated documents, or to get rid of the function limitations, please request a 30-day trial license for yourself.
OCR (Optical Character Recognition) technology is the primary method to extract text from images. Spire.OCR for Java provides developers with a quick and efficient solution to scan and extract text from images in Java projects. This article will guide you on how to use Spire.OCR for Java to recognize and extract text from images in Java projects.
Obtaining Spire.OCR for Java
To scan and recognize text in images using Spire.OCR for Java, you need to first import the Spire.OCR.jar file along with other relevant dependencies into your Java project.
You can download Spire.OCR for Java from our website. If you are using Maven, you can add the following code to your project's pom.xml file to import the JAR file into your application.
<repositories>
<repository>
<id>com.e-iceblue</id>
<name>e-iceblue</name>
<url>https://repo.e-iceblue.com/nexus/content/groups/public/</url>
</repository>
</repositories>
<dependencies>
<dependency>
<groupId>e-iceblue</groupId>
<artifactId>spire.ocr</artifactId>
<version>2.1.5</version>
</dependency>
</dependencies>
Please download the other dependencies based on your operating system:
Install Dependencies
Step 1: Create a Java project in IntelliJ IDEA.
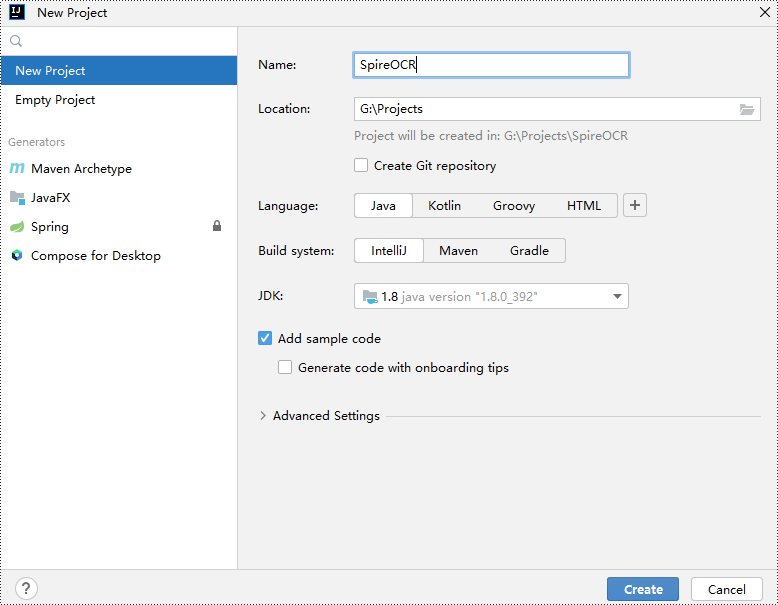
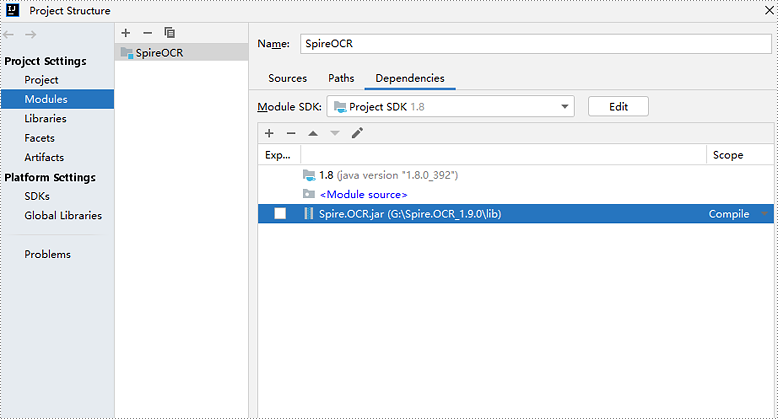
Step 2: Go to File > Project Structure > Modules > Dependencies in the menu and add Spire.OCR.jar as a project dependency.
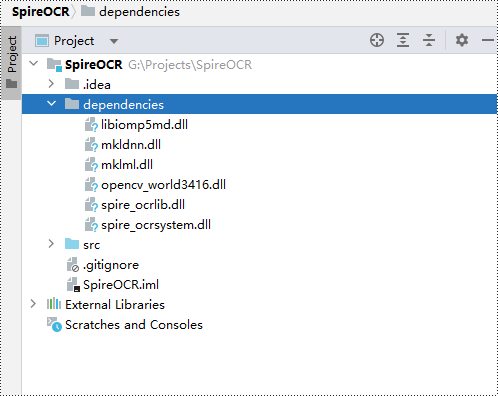
Step 3: Download and extract the other dependency files. Copy all the files from the extracted "dependencies" folder to your project directory.
Scanning and Recognizing Text from a Local Image
- Java
import com.spire.ocr.OcrScanner;
import java.io.*;
public class ScanLocalImage {
public static void main(String[] args) throws Exception {
// Specify the path to the dependency files
String dependencies = "dependencies/";
// Specify the path to the image file to be scanned
String imageFile = "data/Sample.png";
// Specify the path to the output file
String outputFile = "ScanLocalImage_out.txt";
// Create an OcrScanner object
OcrScanner scanner = new OcrScanner();
// Set the dependency file path for the OcrScanner object
scanner.setDependencies(dependencies);
// Use the OcrScanner object to scan the specified image file
scanner.scan(imageFile);
// Get the scanned text content
String scannedText = scanner.getText().toString();
// Create an output file object
File output = new File(outputFile);
// If the output file already exists, delete it
if (output.exists()) {
output.delete();
}
// Create a BufferedWriter object to write content to the output file
BufferedWriter writer = new BufferedWriter(new FileWriter(outputFile));
// Write the scanned text content to the output file
writer.write(scannedText);
// Close the BufferedWriter object to release resources
writer.close();
}
}
Specify the Language File to Scan and Recognize Text from an Image
- Java
import com.spire.ocr.OcrScanner;
import java.io.*;
public class ScanImageWithLanguageSelection {
public static void main(String[] args) throws Exception {
// Specify the path to the dependency files
String dependencies = "dependencies/";
// Specify the path to the language file
String languageFile = "data/japandata";
// Specify the path to the image file to be scanned
String imageFile = "data/JapaneseSample.png";
// Specify the path to the output file
String outputFile = "ScanImageWithLanguageSelection_out.txt";
// Create an OcrScanner object
OcrScanner scanner = new OcrScanner();
// Set the dependency file path for the OcrScanner object
scanner.setDependencies(dependencies);
// Load the specified language file
scanner.loadLanguageFile(languageFile);
// Use the OcrScanner object to scan the specified image file
scanner.scan(imageFile);
// Get the scanned text content
String scannedText = scanner.getText().toString();
// Create an output file object
File output = new File(outputFile);
// If the output file already exists, delete it
if (output.exists()) {
output.delete();
}
// Create a BufferedWriter object to write content to the output file
BufferedWriter writer = new BufferedWriter(new FileWriter(outputFile));
// Write the scanned text content to the output file
writer.write(scannedText);
// Close the BufferedWriter object to release resources
writer.close();
}
}
Apply for a Temporary License
If you'd like to remove the evaluation message from the generated documents, or to get rid of the function limitations, please request a 30-day trial license for yourself.
