
In .NET development, converting HTML to plain text is a common task, whether you need to extract content from web pages, process HTML emails, or generate lightweight text reports. However, HTML’s rich formatting, tags, and structural elements can complicate workflows that require clean, unformatted text. This is why using C# for HTML to text conversion becomes essential.
Spire.Doc for .NET simplifies this process: it’s a robust library for document manipulation that natively supports loading HTML files/strings and converting them to clean plain text. This guide will explore how to convert HTML to plain text in C# using the library, including detailed breakdowns of two core scenarios: converting HTML strings (in-memory content) and HTML files (disk-based content).
- Why Use Spire.Doc for HTML to Text Conversion?
- Installing Spire.Doc
- Convert HTML Strings to Text in C#
- Convert HTML File to Text in C#
- FAQs
- Conclusion
Why Use Spire.Doc for HTML to Text Conversion?
Spire.Doc is a .NET document processing library that stands out for HTML-to-text conversion due to:
- Simplified Code: Minimal lines of code to handle even complex HTML.
- Structure Preservation: Maintains logical formatting (line breaks, list indentation) in the output text.
- Special Character Support: Automatically converts HTML entities to their plain text equivalents.
- Lightweight: Avoids heavy dependencies, making it suitable for both desktop and web applications
Installing Spire.Doc
Spire.Doc is available via NuGet, the easiest way to manage dependencies:
- In Visual Studio, right-click your project > Manage NuGet Packages.
- Search for Spire.Doc and install the latest stable version.
- Alternatively, use the Package Manager Console:
Install-Package Spire.Doc
After installing, you can dive into the C# code to extract text from HTML.
Convert HTML Strings to Text in C#
This example renders an HTML string into a Document object, then uses SaveToFile() to save it as a plain text file.
using Spire.Doc;
using Spire.Doc.Documents;
namespace HtmlToTextSaver
{
class Program
{
static void Main(string[] args)
{
// Define HTML content
string htmlContent = @"
<html>
<body>
<h1>Sample HTML Content</h1>
<p>This is a paragraph with <strong>bold</strong> and <em>italic</em> text.</p>
<p>Another line with a <a href='https://example.com'>link</a>.</p>
<ul>
<li>List item 1</li>
<li>List item 2 (with <em>italic</em> text)</li>
</ul>
<p>Special characters: © & ®</p>
</body>
</html>";
// Create a Document object
Document doc = new Document();
// Add a section to hold content
Section section = doc.AddSection();
// Add a paragraph
Paragraph paragraph = section.AddParagraph();
// Render HTML into the paragraph
paragraph.AppendHTML(htmlContent);
// Save as plain text
doc.SaveToFile("HtmlStringtoText.txt", FileFormat.Txt);
}
}
}
How It Works:
- HTML String Definition: We start with a sample HTML string containing headings, paragraphs, formatting tags (
<strong>,<em>), links, lists, and special characters. - Document Setup: A
Documentobject is created to manage the content, with aSectionandParagraphto structure the HTML rendering. - HTML Rendering:
AppendHTML()parses the HTML string and converts it into the document's internal structure, preserving content hierarchy. - Text Conversion:
SaveToFile()withFileFormat.Txtconverts the rendered content to plain text, stripping HTML tags while retaining readable structure.
Output:
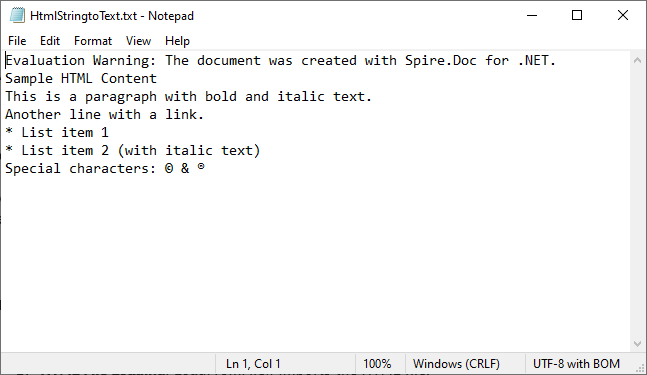
Extended reading: Parse or Read HTML in C#
Convert HTML File to Text in C#
This example directly loads an HTML file and converts it to text. Ideal for batch processing or working with pre-existing HTML documents (e.g., downloaded web pages, local templates).
using Spire.Doc;
using Spire.Doc.Documents;
namespace HtmlToText
{
class Program
{
static void Main()
{
// Create a Document object
Document doc = new Document();
// Load an HTML file
doc.LoadFromFile("sample.html", FileFormat.Html, XHTMLValidationType.None);
// Convert HTML to plain text
doc.SaveToFile("HTMLtoText.txt", FileFormat.Txt);
doc.Dispose();
}
}
}
How It Works:
- Document Initialization: A
Documentobject is created to handle the file operations. - HTML File Loading:
LoadFromFile()imports the HTML file, withFileFormat.Htmlspecifying the input type.XHTMLValidationType.Noneensures compatibility with non-strict HTML. - Text Conversion:
SaveToFile()withFileFormat.Txtconverts the loaded HTML content to plain text.
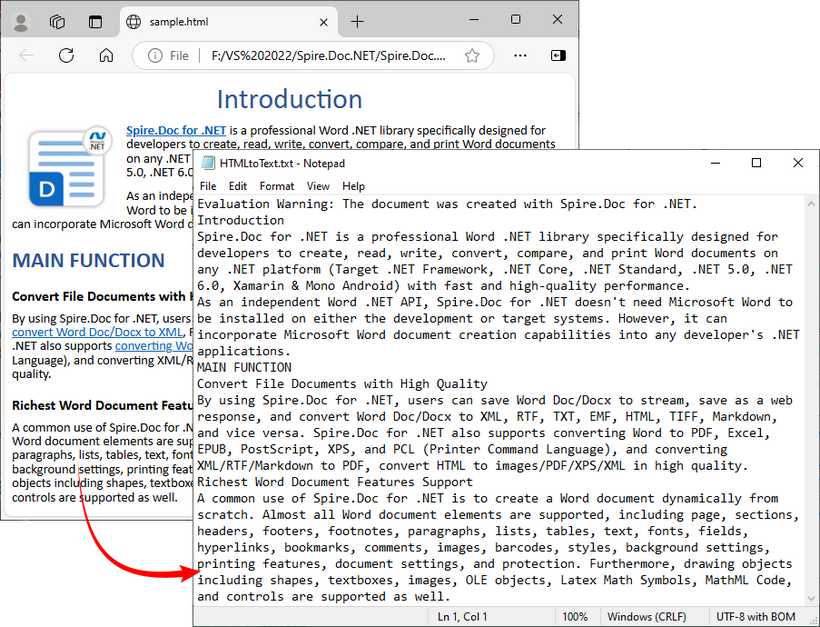
To preserve the original formatting and style, you can refer to the C# tutorial to convert the HTML file to Word.
FAQs
Q1: Can Spire.Doc process malformed HTML?
A: Yes. Spire.Doc includes built-in tolerance for malformed HTML, but you may need to disable strict validation to ensure proper parsing.
When loading HTML files, use XHTMLValidationType.None (as shown in the guide) to skip strict XHTML checks:
doc.LoadFromFile("malformed.html", FileFormat.Html, XHTMLValidationType.None);
This setting tells Spire.Doc to parse the HTML like a web browser (which automatically corrects minor issues like unclosed <p> or <li> tags) instead of rejecting non-compliant content.
Q2: Can I extract specific elements from HTML (like only paragraphs or headings)?
A: Yes, after loading the HTML into a Document object, you can access specific elements through the object model (like paragraphs, tables, etc.) and extract text from only those specific elements rather than the entire document.
Q3: Can I convert HTML to other formats besides plain text using Spire.Doc?
A: Yes, Spire.Doc supports conversion to multiple formats, including Word DOC/DOCX, PDF, image, RTF, and more, making it a versatile document processing solution.
Q4: Does Spire.Doc work with .NET Core/.NET 5+?
A: Spire.Doc fully supports .NET Core, .NET 5/6/7/8, and .NET Framework 4.0+. There’s no difference in functionality across these frameworks, which means you can use the same code (e.g., Document, AppendHTML(), SaveToFile()) regardless of which .NET runtime you’re targeting.
Conclusion
Converting HTML to text in C# is straightforward with the Spire.Doc library. Whether you’re working with HTML strings or files, Spire.Doc simplifies the process by handling HTML parsing, structure preservation, and text conversion. By following the examples in this guide, you can seamlessly integrate HTML-to-text conversion into your C# applications.
You can request a free 30-day trial license here to unlock full functionality and remove limitations of the Spire.Doc library.
