IIm heutigen digitalen Zeitalter ist das Extrahieren von Text aus Bildern oder gescannten PDFs eine häufige Anforderung für verschiedene Anwendungen. Die optische Zeichenerkennung (OCR) ist eine Technologie, die es Computern ermöglicht, Text aus solchen Dokumenten zu erkennen und zu extrahieren. Damit können wir Bilder und gescannte PDFs mühelos in bearbeitbare und durchsuchbare Formate konvertieren, was die Verarbeitung und Analyse des Textinhalts erleichtert. In diesem Blog erfahren Sie, wie das geht Extrahieren Sie Text aus Bildern und gescannten PDFs mit OCR in C#.
- Text aus Bildern in C# extrahieren
- Extrahieren Sie Text aus Bildern mit Koordinaten in C#
- Text aus gescannten PDFs in C# extrahieren
C#-Bibliotheken zum Extrahieren von Text aus Bildern und gescannten PDFs
Um Text aus Bildern zu extrahieren, verwenden wir die Bibliothek Spire.OCR for .NET. Spire.OCR for .NET ist eine leistungsstarke Bibliothek, die speziell zum Extrahieren von Text aus Bildern in .NET-Anwendungen entwickelt wurde. Es unterstützt verschiedene Bildformate wie BMP, JPG, PNG, TIFF und GIF.
Hier sind die Schritte zur Installation von Spire.OCR for .NET:
- Ändern Sie das Plattformziel Ihrer Lösung auf x64.
- Installieren Sie Spire.OCR von NuGet, indem Sie den folgenden Befehl in der NuGet Package Manager-Konsole ausführen:
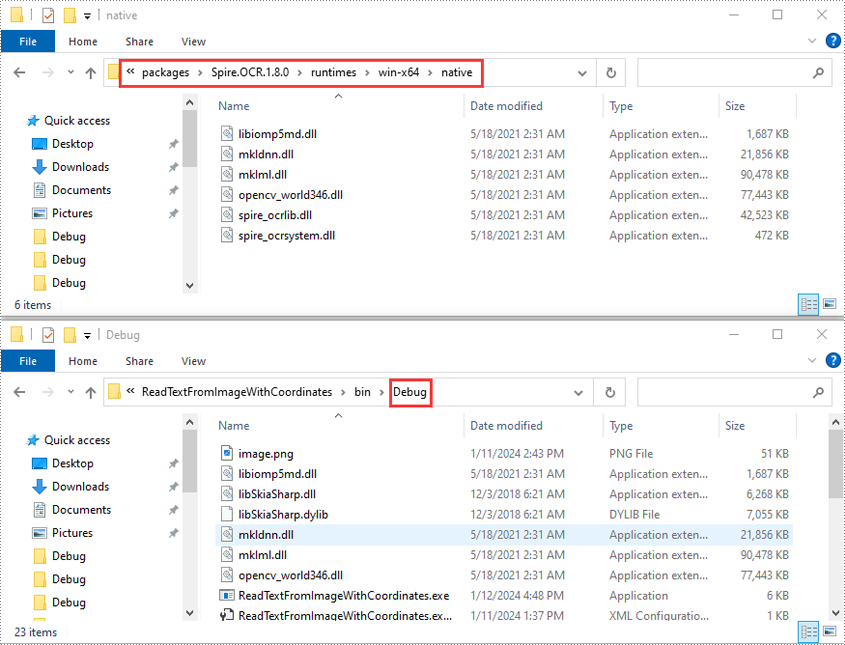
- Öffnen Sie Ihren Lösungsordner und navigieren Sie zum Verzeichnis „packages\Spire.OCR.1.8.0\runtimes\win-x64\native“. Kopieren Sie die DLL-Dateien aus diesem Verzeichnis und fügen Sie sie in den Ordner „Debug“ Ihrer Lösung ein.
Install-Package Spire.OCR
Um Text aus gescannten PDFs zu extrahieren, müssen wir zunächst das PDF-Dokument in Bilder konvertieren. Für diese Aufgabe verwenden wir die Spire.PDF for .NET Bibliothek. Sobald die Konvertierung abgeschlossen ist, können wir Spire.OCR verwenden, um Text aus den resultierenden Bildern zu extrahieren.
Sie können Spire.PDF for .NET von NuGet installieren, indem Sie den folgenden Befehl in der NuGet Package Manager-Konsole ausführen:
Install-Package Spire.PDF
Text aus Bildern in C# extrahieren
Spire.OCR bietet die Methode OcrScanner.Scan() zum Erkennen von Text aus einem Bild. Nach der Erkennung können Sie den erkannten Text mithilfe der Eigenschaft OcrScanner.Text abrufen.
Hier sind die wichtigsten Schritte zum Erkennen von Text aus einem Bild mit Spire.OCR:
- Erstellen Sie eine Instanz der OcrScanner-Klasse.
- Erkennen Sie Text aus einem Bild mit der Methode OcrScanner.Scan().
- Rufen Sie den erkannten Text mithilfe der OcrScanner.Text-Eigenschaft aus dem OcrScanner-Objekt ab.
- Speichern Sie den Text in einer Textdatei.
Hier ist ein Codebeispiel, das zeigt, wie man Text aus einem Bild erkennt und das Ergebnis in einer Textdatei speichert:
- C#
using Spire.OCR;
using System.IO;
namespace ReadTextFromImage
{
internal class Program
{
static void Main(string[] args)
{
//Specify the path of the input image file
string imageFilePath = "Image.png";
//Specify the path of the output text file
string outputFilePath = "ScanImage.txt";
//Call the ScanTextFromImage method to scan text from an image
string scannedText = ScanTextFromImage(imageFilePath);
//Write the text to the specified file
File.WriteAllText(outputFilePath, scannedText);
}
public static string ScanTextFromImage(string imageFilePath)
{
//Instantiate an OcrScanner object
using (OcrScanner ocrScanner = new OcrScanner())
{
//Scan text from the image
ocrScanner.Scan(imageFilePath);
//Get the recognized text from the OcrScanner object
IOCRText text = ocrScanner.Text;
//Return the text
return text.ToString();
}
}
}
}
Extrahieren Sie Text aus Bildern mit Koordinaten in C#
Das Extrahieren von Koordinaten ist nützlich, wenn Sie die genaue Position bestimmter Textelemente in Ihrem Bild ermitteln müssen. Mit Spire.OCR können Sie den erkannten Text in Blöcken oder Zeilen abrufen. Für jeden Block können Sie detaillierte Standortinformationen abrufen, einschließlich der X- und Y-Koordinaten sowie seiner Breite und Höhe.
Hier sind die wichtigsten Schritte zum Extrahieren von Text zusammen mit seinen Standortinformationen aus einem Bild mit Spire.OCR:
- Erstellen Sie eine Instanz der OcrScanner-Klasse.
- Erkennen Sie Text aus einem Bild mit der Methode OcrScanner.Scan().
- Rufen Sie den erkannten Text mithilfe der OcrScanner.Text-Eigenschaft aus dem OcrScanner-Objekt ab.
- Durchlaufen Sie die Textblöcke des erkannten Textes.
- Rufen Sie für jeden Block seine Text- und Standortinformationen mithilfe der Eigenschaften IOCRTextBlock.Text und IOCRTextBlock.Box ab und hängen Sie das Ergebnis dann an eine Zeichenfolgenliste an.
- Speichern Sie den Inhalt der Liste in einer Textdatei.
Hier ist ein Codebeispiel, das zeigt, wie man Text zusammen mit seinen Standortinformationen aus einem Bild erkennt und das Ergebnis in einer Textdatei speichert:
- C#
using Spire.OCR;
using System.Collections.Generic;
using System.IO;
namespace ReadTextFromImageWithCoordinates
{
internal class Program
{
static void Main(string[] args)
{
//Specify the path of the input image file
string imagePath = "Image.png";
//Specify the path of the output text file
string outputFile = "ScanImageWithCoordinates.txt";
//Call the ScanTextFromImageWithCoordinates method to extract text and its area information from the image
List<string> extractedText = ScanTextFromImageWithCoordinates(imagePath);
//Write the result to the specified file
File.WriteAllLines(outputFile, extractedText);
}
//Retrieve the text blocks along with their location information (x, y, width, height) from an image
public static List<string> ScanTextFromImageWithCoordinates(string imageFilePath)
{
//Create a list
List<string> extractedText = new List<string>();
//Instantiate an OcrScanner object
using (OcrScanner ocrScanner = new OcrScanner())
{
//Scan text from the image
ocrScanner.Scan(imageFilePath);
//Get the scanned text
IOCRText text = ocrScanner.Text;
//Iterate through each text block
foreach (IOCRTextBlock block in text.Blocks)
{
//Append the text of each block and its location information to the list
extractedText.Add($"Text: {block.Text}\nRectangular Area: {block.Box}");
}
}
return extractedText;
}
}
}
Text aus gescannten PDFs in C# extrahieren
Um Text aus gescannten PDFs zu extrahieren, müssen wir einem zweistufigen Prozess folgen. Zunächst verwenden wir Spire.PDF, um die gescannten PDFs in Bilder umzuwandeln. Anschließend verwenden wir Spire.OCR, um den Text aus diesen Bildern zu extrahieren.
Hier sind die wichtigsten Schritte zum Erkennen von Text aus einem gescannten PDF mit Spire.PDF und Spire.OCR:
- Erstellen Sie eine Instanz der PdfDocument-Klasse.
- Laden Sie ein PDF-Dokument mit der Methode PdfDocument.LoadFromFile().
- Durchlaufen Sie die Seiten des PDF-Dokuments.
- Konvertieren Sie jede Seite mit der Methode PdfDocument.SaveAsImage() in ein Bildobjekt.
- Speichern Sie das Image-Objekt mit der Methode Image.Save() in einem Stream.
- Erstellen Sie eine Instanz der OcrScanner-Klasse.
- Erkennen Sie Text aus dem Stream mit der Methode OcrScanner.Scan().
- Rufen Sie den erkannten Text mithilfe der Eigenschaft IOCRText.Text ab und hängen Sie ihn an eine Zeichenfolgenliste an.
- Speichern Sie den Inhalt der Liste in einer Textdatei.
Hier ist ein Codebeispiel, das zeigt, wie man Text aus einer gescannten PDF-Datei erkennt und das Ergebnis in einer Textdatei speichert:
- C#
using Spire.OCR;
using Spire.Pdf;
using System.Collections.Generic;
using System.Drawing;
using System.Drawing.Imaging;
using System.IO;
namespace ReadTextFromScannedPDF
{
internal class Program
{
static void Main(string[] args)
{
//Specify the path of the scanned PDF file
string pdfFilePath = "Sample.pdf";
//Specify the path of the output text file
string outputFilePath = "ScanPDF.txt";
//Extract text from the scanned PDF
List<string> extractedText = ExtractTextFromScannedPDF(pdfFilePath);
//Write the text to the specified file
File.WriteAllLines(outputFilePath, extractedText);
}
//Extract text from a scanned PDF
public static List<string> ExtractTextFromScannedPDF(string pdfFilePath)
{
//Create a list to store the extracted text
List<string> extractedText = new List<string>();
//Create an instance of the PdfDocument class
using (PdfDocument document = new PdfDocument())
{
//Load the PDF document
document.LoadFromFile(pdfFilePath);
//Iterate through each page of the document
for (int pageIndex = 0; pageIndex < document.Pages.Count; pageIndex++)
{
//Convert the page to an image
using (Image image = document.SaveAsImage(pageIndex, 300, 300))
{
//Create a memory stream to hold the image data
using (MemoryStream stream = new MemoryStream())
{
//Save the image to the memory stream in PNG format
image.Save(stream, ImageFormat.Png);
stream.Position = 0;
//Scan the text from the image and add it to the list
string text = ScanTextFromImageStream(stream);
extractedText.Add(text);
}
}
}
}
//Return the list
return extractedText;
}
//Scan text from an image stream
public static string ScanTextFromImageStream(Stream stream)
{
//Create an instance of the OcrScanner class
using (OcrScanner ocrScanner = new OcrScanner())
{
//Scan the text from the image stream in PNG format
ocrScanner.Scan(stream, OCRImageFormat.Png);
IOCRText text = ocrScanner.Text;
//Return the text
return text.ToString();
}
}
}
}
Holen Sie sich eine kostenlose Lizenz
Um die Funktionen von Spire.OCR for .NET oder Spire.PDF for .NET ohne jegliche Evaluierungseinschränkungen voll auszuschöpfen, können Sie eine Anfrage stellen eine kostenlose 30-Tage-Testlizenz.
Abschluss
In diesem Blogbeitrag wurde gezeigt, wie man in C# Text aus Bildern und gescannten PDF-Dokumenten extrahiert. Wenn Sie Fragen haben, können Sie diese gerne in unserem Forum posten oder per email an unser Support-Team senden.