PDF-Dateien sind eine beliebte Wahl zum Teilen und Verteilen von Dokumenten, es kann jedoch eine große Herausforderung sein, PDF-Inhalte zu extrahieren und wiederzuverwenden. Glücklicherweise, Konvertieren von PDF-Dateien in HTML mit Python bietet eine hervorragende Lösung zum Abrufen und Wiederverwenden von PDF-Informationen, die die Zugänglichkeit, Durchsuchbarkeit und Anpassungsfähigkeit verbessert. Darüber hinaus ermöglicht das HTML-Format Suchmaschinen, den Inhalt zu indizieren, wodurch die Wahrscheinlichkeit steigt, dass er im Web gefunden wird. Darüber hinaus können sowohl Anfänger als auch erfahrene Entwickler die Flexibilität und Benutzerfreundlichkeit von Python nutzen Python zum Konvertieren von PDF in HTML einfach und effizient.

Dieser Artikel konzentriert sich auf die Konvertierung von PDF in HTML in Python-Programmen. Es umfasst hauptsächlich die folgenden Themen:
- Überblick über die Konvertierung von PDF in HTML mit Python
- Konvertieren Sie PDF mit Python-Code in eine einzelne HTML-Datei
- Konvertieren Sie PDF in HTML mit getrennten Bildern mit Python
- Konvertieren Sie PDF mit Python in mehrere HTML-Dateien
- Kostenlose Lizenz und technischer Support
Überblick über die Konvertierung von PDF in HTML mit Python
Die umfangreichen APIs von Python bieten Komfort für verschiedene Verarbeitungsvorgänge von PDF-Dokumenten. Spire.PDF for Python ist eine der leistungsstarken APIs, die verschiedene Vorgänge an PDF-Dokumenten ausführen kann, einschließlich Konvertieren, Bearbeiten usw Zusammenführen von PDF-Dokumenten. Und die Konvertierung von PDF in HTML mit Python kann mit dieser API mühelos implementiert werden.
In Spire.PDF for Python repräsentiert die PdfDocument-Klasse ein PDF-Dokument. Wir können eine PDF-Datei mit der LoadFromFile()-Methode dieser Klasse laden und das Dokument in anderen Formaten wie HTML speichern, um eine einfache Konvertierung von PDF in HTML zu erreichen.
Darüber hinaus stellt diese API auch die Methode SetConvertHtmlOptions() unter der Eigenschaft PdfDocument.ConversionOptions bereit, um die Bildeinbettungsoptionen während der Konvertierung festzulegen. Nachfolgend sind die Parameter aufgeführt, die an diese Methode übergeben werden können, um die maximale Seitenzahl, die SVG-Einbettungsoption, die Bildeinbettungsoption und die SVG-Qualitätsoption festzulegen:
- useEmbeddedSvg (bool): Wenn es auf True gesetzt ist, ermöglicht es das Einbetten von SVG in die konvertierte HTML-Datei. Die resultierende HTML-Datei enthält alle Elemente des PDF-Dokuments, einschließlich Bilder, in einer einzigen HTML-Datei.
- useEmbeddedImg (bool): Wenn es auf True gesetzt ist, ermöglicht es das Einbetten von Bildern in die konvertierte HTML-Datei. Dieser Parameter funktioniert nur, wenn useEmbeddedSvg auf False gesetzt ist.
- maxPageOneFile (int): Legt die maximale Anzahl von Seiten fest, die in eine einzelne HTML-Datei aufgenommen werden sollen. Wenn die PDF-Datei mehr Seiten als die angegebene Anzahl umfasst, werden mehrere HTML-Dateien generiert, die jeweils eine Teilmenge der Seiten enthalten.
- useHighQualityEmbeddedSvg (bool): Wenn auf True gesetzt, wird die Verwendung hochwertiger Versionen eingebetteter SVG-Bilder im HTML-Konvertierungsprozess sichergestellt.
Typischer Arbeitsablauf zum Konvertieren von PDF in HTML in Python mit Spire.PDF for Python:
- Erstellen Sie ein Objekt der PdfDocument-Klasse und laden Sie ein PDF-Dokument mit der Methode PdfDocument.LoadFromFile(string fileName).
- Legen Sie die Konvertierungsoptionen mit der Methode PdfDocument.ConversionOptions.SetConvertHtmlOptions() fest.
- Konvertieren Sie das Dokument in das HTML-Format und speichern Sie es mit der Methode PdfDocument.SaveToFile(string fileName, FileFormat.HTML).
Benutzer können Laden Sie Spire.PDF for Python herunter und importieren Sie es in ihre Projekte oder installieren Sie es mit PyPI:
pip install Spire.PDF
Konvertieren Sie PDF mit Python-Code in eine einzelne HTML-Datei
Dieses Codebeispiel zeigt, wie Sie PDF mit Python direkt in HTML konvertieren, ohne Konvertierungsoptionen festzulegen. In diesem Fall müssen wir lediglich eine PDF-Datei mit der LoadFromFile-Methode laden und sie mit der SaveToFile-Methode als HTML-Datei speichern. Die konvertierte HTML-Datei ist eine einzelne HTML-Datei mit darin eingebetteten Bildern und anderen Elementen.
Codebeispiel:
- Python
from spire.pdf.common import *
from spire.pdf import *
# Craete an object of PdfDocument class
doc = PdfDocument()
# Load a PDF document
doc.LoadFromFile("G:/Documents/ARCHITECTURE.pdf")
# Convert the document to HTML
doc.SaveToFile("output/HTML/PDFToHTML.html", FileFormat.HTML)
doc.Close()
Konvertierungsergebnis:
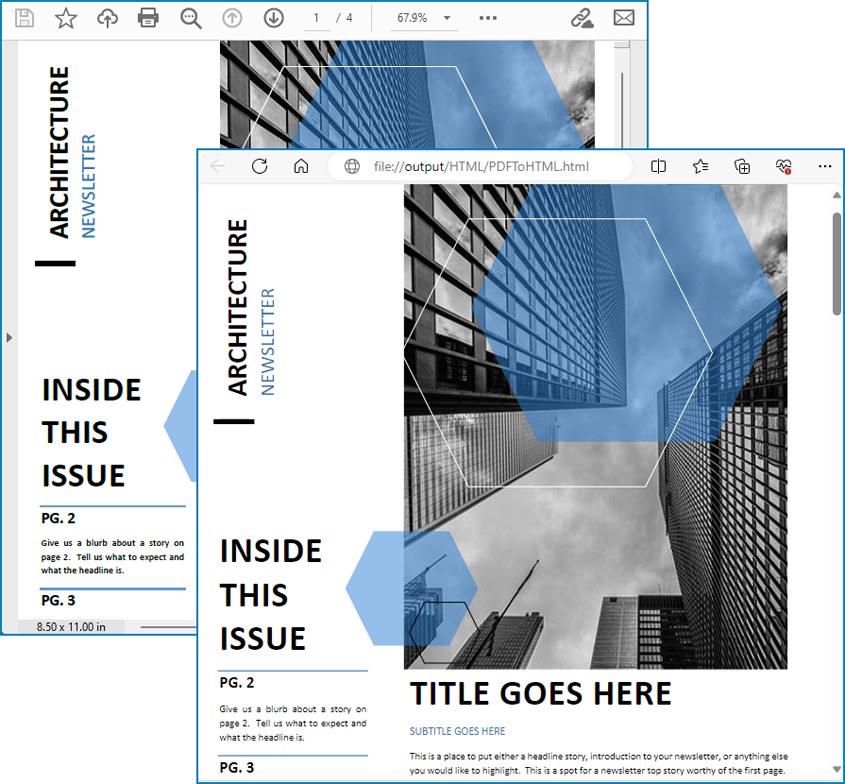
Konvertieren Sie PDF in HTML mit getrennten Bildern mit Python
Indem wir den Parameter „useEmbeddedSvg“ auf „False“ setzen, können wir das PDF-Dokument in eine HTML-Datei mit davon getrennten Bildern und CSS-Dateien konvertieren und in einem Ordner speichern. Dadurch ist es bequem, die konvertierte HTML-Datei weiter zu bearbeiten und zusätzliche Vorgänge an den Bildern durchzuführen.
Codebeispiel:
- Python
from spire.pdf.common import *
from spire.pdf import *
# Craete an object of PdfDocument class
doc = PdfDocument()
# Load a PDF document
doc.LoadFromFile("ARCHITECTURE.pdf")
# Disable embedding SVG
doc.ConvertOptions.SetPdfToHtmlOptions(False)
# Convert the document to HTML
doc.SaveToFile("output/HTML/PDFToHTMLWithoutEmbeddingSVG.html", FileFormat.HTML)
doc.Close()
Konvertierungsergebnis:
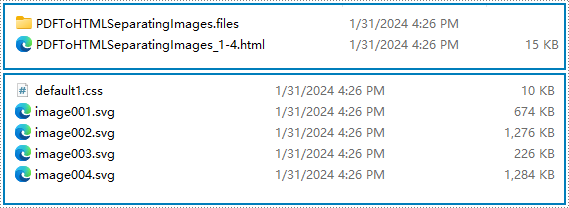
Konvertieren Sie PDF mit Python in mehrere HTML-Dateien
Unter der Voraussetzung, dass useEmbeddedSvg auf False gesetzt ist, ermöglicht die SetPdfToHtmlOptions-Methode die Verwendung des Parameters maxPageOneFile (int), um die maximale Anzahl von Seiten zu bestimmen, die in jeder konvertierten HTML-Datei enthalten sind. Diese Funktion ermöglicht Aufteilen von PDF-Dokumenten im Konvertierungsprozess. Wenn Sie den Parameter beispielsweise auf 1 setzen, wird jede Seite in eine separate HTML-Datei konvertiert.
Codebeispiel:
- Python
from spire.pdf.common import *
from spire.pdf import *
# Craete an object of PdfDocument class
doc = PdfDocument()
# Load a PDF document
doc.LoadFromFile("ARCHITECTURE.pdf")
# Disable embedding SVG
doc.ConvertOptions.SetPdfToHtmlOptions(False, False, 1, False)
# Convert the document to HTML
doc.SaveToFile("output/HTML/PDFToHTMLLimitingPage.html", FileFormat.HTML)
doc.Close()
Konvertierungsergebnis:
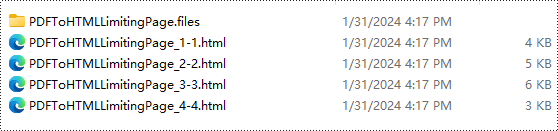
Kostenlose Lizenz und technischer Support
Spire.PDF for Python bietet Benutzern eine kostenlose Testlizenz für alle Benutzer, einschließlich Unternehmens- und Einzelbenutzern. Beantragen Sie eine temporäre Lizenz um diese Python-API zum Konvertieren von PDF-Dokumenten in HTML-Dateien zu verwenden und dabei jegliche Nutzungsbeschränkungen oder Wasserzeichen zu entfernen.
Bei Problemen, die bei der PDF-zu-HTML-Konvertierung mithilfe dieser API auftreten, können Benutzer technische Unterstützung im Spire.PDF-Forum suchen.
Abschluss
Dieser Artikel zeigt, wie Sie PDF mit Python in HTML konvertieren und bietet verschiedene Konvertierungsoptionen, z. B. die Konvertierung in eine einzelne HTML-Datei, das Trennen von HTML-Dateien von Bildern und das Aufteilen des PDF-Dokuments während der Konvertierung. Mit Spire.PDF for Python haben Benutzer Zugriff auf eine unkomplizierte und effiziente Methode für Python bei der PDF-zu-HTML-Konvertierung, die flexible Anpassungsoptionen unterstützt.