Im heutigen digitalen Zeitalter ist die Fähigkeit, Informationen aus PDF-Dokumenten schnell und effizient zu extrahieren, für verschiedene Branchen und Fachleute von entscheidender Bedeutung. Unabhängig davon, ob Sie ein Forscher oder Datenanalyst sind oder einfach mit einer großen Menge an PDF-Dateien arbeiten, können Sie durch die Konvertierung von PDFs in ein bearbeitbares Textformat wertvolle Zeit und Mühe sparen. Hier kommt Python, eine vielseitige und leistungsstarke Programmiersprache, mit ihren umfangreichen Konvertierungsfunktionen zum Einsatz PDF in Text in Python umwandeln.

In diesem Artikel erfahren Sie, wie Sie es verwenden Python für PDF in Text Konvertierung und entfesselt die Leistungsfähigkeit von Python bei der PDF-Dateiverarbeitung. Dieser Artikel umfasst die folgenden Themen:
- Python-API für die Konvertierung von PDF in Text
- Anleitung zum Konvertieren von PDF in Text in Python
- Python zum Konvertieren von PDF in Text, ohne das Layout beizubehalten
- Python zum Konvertieren von PDF in Text und Beibehalten des Layouts
- Python zum Konvertieren eines bestimmten PDF-Seitenbereichs in Text
- Holen Sie sich eine kostenlose Lizenz für die API zum Konvertieren von PDF in Text in Python
- Erfahren Sie mehr über die PDF-Verarbeitung mit Python
Python-API für die Konvertierung von PDF in Text
Um Python für die Konvertierung von PDF in Text zu verwenden, ist eine PDF-Verarbeitungs-API – Spire.PDF for Python – erforderlich. Diese Python-Bibliothek wurde für die Bearbeitung von PDF-Dokumenten in Python-Programmen entwickelt, wodurch Python-Programme mit verschiedenen PDF-Verarbeitungsfähigkeiten ausgestattet werden.
Wir können Laden Sie Spire.PDF for Python herunter und fügen Sie es unserem Projekt hinzu oder installieren Sie es einfach über PyPI mit dem folgenden Code:
pip install Spire.PDF
Anleitung zum Konvertieren von PDF in Text in Python
Bevor wir mit der Konvertierung von PDF in Text mit Python fortfahren, werfen wir einen Blick auf die wichtigsten Vorteile, die es uns bieten kann:
- Bearbeitbarkeit: Durch das Konvertieren von PDF in Text können Sie das Dokument einfacher bearbeiten, da Textdateien auf den meisten Geräten geöffnet und bearbeitet werden können.
- Barrierefreiheit: Textdateien sind im Allgemeinen besser zugänglich als PDFs. Ganz gleich, ob es sich um einen Desktop oder ein Mobiltelefon handelt, Textdateien können problemlos auf Geräten angezeigt werden.
- Integration mit anderen Anwendungen: Textdateien können nahtlos in verschiedene Anwendungen und Arbeitsabläufe integriert werden.
Schritte zum Konvertieren von PDF-Dokumenten in Textdateien in Python:
- Installieren Spire.PDF for Python.
- Module importieren.
- Erstellen Sie ein Objekt der Klasse PdfDocument und laden Sie eine PDF-Datei mit der Methode LoadFromFile().
- Erstellen Sie ein Objekt der PdfTextExtractOptions-Klasse und legen Sie die Textextraktionsoptionen fest, einschließlich der Extraktion des gesamten Textes, der Anzeige ausgeblendeten Textes, der Extraktion nur des Texts in einem bestimmten Bereich und der einfachen Extraktion.
- Rufen Sie mit der Methode PdfDocument.Pages.get_Item() eine Seite im Dokument ab und erstellen Sie PdfTextExtractor-Objekte basierend auf jeder Seite, um den Text mit der Methode Extract() mit angegebenen Optionen aus der Seite zu extrahieren.
- Speichern Sie den extrahierten Text als Textdatei und schließen Sie das PdfDocument-Objekt.
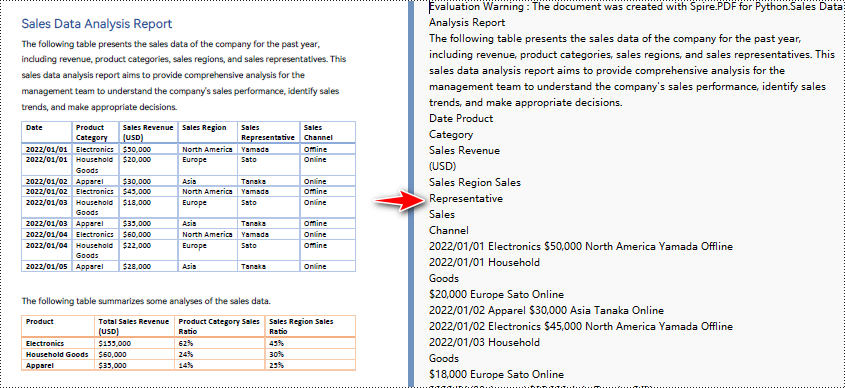
Python zum Konvertieren von PDF in Text ohne Beibehaltung des Layouts
Wenn Sie die einfache Extraktionsmethode zum Extrahieren von Text aus PDF verwenden, behält das Programm die leeren Bereiche nicht bei und verfolgt nicht die aktuelle Y-Position jeder Zeichenfolge und fügt einen Zeilenumbruch in die Ausgabe ein, wenn sich die Y-Position geändert hat.
- Python
from spire.pdf import PdfDocument
from spire.pdf import PdfTextExtractOptions
from spire.pdf import PdfTextExtractor
# Create an object of PdfDocument class and load a PDF file
pdf = PdfDocument()
pdf.LoadFromFile("Sample.pdf")
# Create a string object to store the text
extracted_text = ""
# Create an object of PdfExtractor
extract_options = PdfTextExtractOptions()
# Set to use simple extraction method
extract_options.IsSimpleExtraction = True
# Loop through the pages in the document
for i in range(pdf.Pages.Count):
# Get a page
page = pdf.Pages.get_Item(i)
# Create an object of PdfTextExtractor passing the page as paramter
text_extractor = PdfTextExtractor(page)
# Extract the text from the page
text = text_extractor.ExtractText(extract_options)
# Add the extracted text to the string object
extracted_text += text
# Write the extracted text to a text file
with open("output/ExtractedText.txt", "w") as file:
file.write(extracted_text)
pdf.Close()
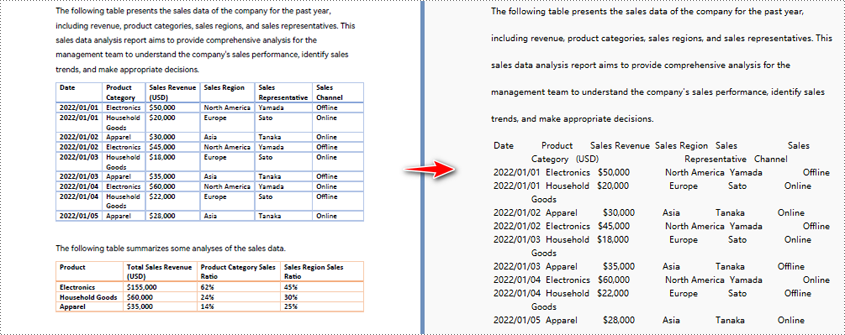
Python zum Konvertieren von PDF in Text und Beibehalten des Layouts
Wenn Sie die Standardextraktionsmethode zum Extrahieren von Text aus PDF verwenden, extrahiert das Programm den Text Zeile für Zeile, einschließlich Leerzeichen.
- Python
from spire.pdf import PdfDocument
from spire.pdf import PdfTextExtractOptions
from spire.pdf import PdfTextExtractor
# Create an object of PdfDocument class and load a PDF file
pdf = PdfDocument()
pdf.LoadFromFile("Sample.pdf")
# Create a string object to store the text
extracted_text = ""
# Create an object of PdfExtractor
extract_options = PdfTextExtractOptions()
# Loop through the pages in the document
for i in range(pdf.Pages.Count):
# Get a page
page = pdf.Pages.get_Item(i)
# Create an object of PdfTextExtractor passing the page as paramter
text_extractor = PdfTextExtractor(page)
# Extract the text from the page
text = text_extractor.ExtractText(extract_options)
# Add the extracted text to the string object
extracted_text += text
# Write the extracted text to a text file
with open("output/ExtractedText.txt", "w") as file:
file.write(extracted_text)
pdf.Close()
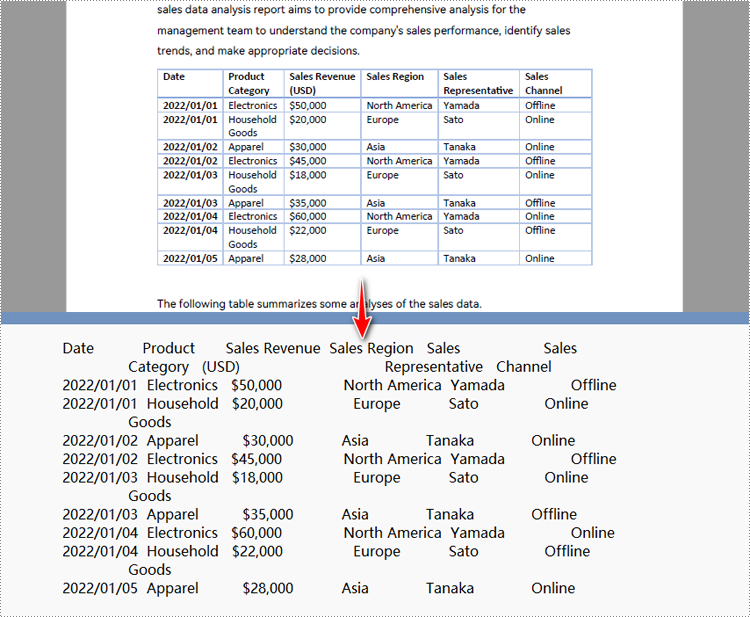
Python zum Konvertieren eines bestimmten PDF-Seitenbereichs in Text
- Python
from spire.pdf import PdfDocument
from spire.pdf import PdfTextExtractOptions
from spire.pdf import PdfTextExtractor
from spire.pdf import RectangleF
# Create an object of PdfDocument class and load a PDF file
pdf = PdfDocument()
pdf.LoadFromFile("Sample.pdf")
# Create an object of PdfExtractor
extract_options = PdfTextExtractOptions()
# Set to extract specific page area
extract_options.ExtractArea = RectangleF(50.0, 220.0, 700.0, 230.0)
# Get a page
page = pdf.Pages.get_Item(0)
# Create an object of PdfTextExtractor passing the page as paramter
text_extractor = PdfTextExtractor(page)
# Extract the text from the page
extracted_text = text_extractor.ExtractText(extract_options)
# Write the extracted text to a text file
with open("output/ExtractedText.txt", "w") as file:
file.write(extracted_text)
pdf.Close()
Holen Sie sich eine kostenlose Lizenz für die API zum Konvertieren von PDF in Text in Python
Benutzer können Beantragen Sie eine kostenlose temporäre Lizenz um Spire.PDF für Python auszuprobieren und die Python-PDF-zu-Text-Konvertierungsfunktionen ohne Einschränkungen zu testen.
Erfahren Sie mehr über die PDF-Verarbeitung mit Python
Neben der Konvertierung von PDF in Text mit Python können wir über die folgenden Quellen auch weitere PDF-Verarbeitungsfunktionen dieser API erkunden:
- So extrahieren Sie Text aus PDF-Dokumenten mit Python
- Tutorials zur PDF-Verarbeitung mit Python
- Konvertieren bildbasierter PDF-Dokumente in Text (OCR)
Abschluss
In diesem Blogbeitrag haben wir es untersucht Python in PDF-zu-Text-Konvertierung. Indem wir die Betriebsschritte befolgen und auf die Codebeispiele im Artikel verweisen, können wir schnell etwas erreichen PDF-zu-Text-Konvertierung in Python Programme. Darüber hinaus bietet der Artikel Einblicke in die Vorteile der Konvertierung von PDF-Dokumenten in Textdateien. Noch wichtiger ist, dass wir aus den Referenzen im Artikel weitere Kenntnisse über den Umgang mit PDF-Dokumenten mit Python und Methoden zur Konvertierung bildbasierter PDF-Dokumente in Text mithilfe von OCR-Tools gewinnen können. Sollten bei der Nutzung von Spire.PDF for Python Probleme auftreten, können Sie technischen Support erhalten, indem Sie sich über das Spire.PDF-Forum oder per E-Mail an unser Team wenden.