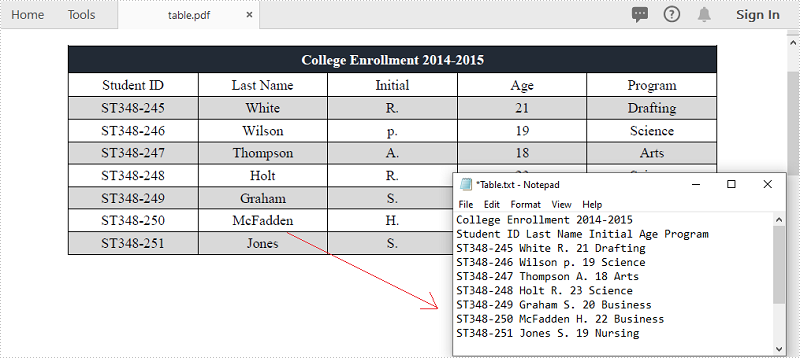
PDF is one of the most popular document formats for sharing and writing data. You may encounter the situation where you need to extract data from PDF documents, especially the data in tables. For example, there is useful information stored in the tables of your PDF invoices and you want to extract the data for further analysis or calculation. This article demonstrates how to extract data out of PDF tables and save it in a TXT file by using Spire.PDF for .NET.
Install Spire.PDF for .NET
To begin with, you need to add the DLL files included in the Spire.PDF for.NET package as references in your .NET project. The DLLs files can be either downloaded from this link or installed via NuGet.
- Package Manager
PM> Install-Package Spire.PDF
Extract Data from PDF Tables
The following are the main steps to extract tables from a PDF document.
- Create an instance of PdfDocument class.
- Load the sample PDF document using PdfDocument.LoadFromFile() method.
- Extract tables from a specific page using PdfTableExtractor.ExtractTable(int pageIndex) method.
- Get text of a certain table cell using PdfTable.GetText(int rowIndex, int columnIndex) method.
- Save the extracted data in a .txt file.
- C#
- VB.NET
using System.IO;
using System.Text;
using Spire.Pdf;
using Spire.Pdf.Utilities;
namespace ExtractPdfTable
{
class Program
{
static void Main(string[] args)
{
//Create a PdfDocument object
PdfDocument doc = new PdfDocument();
//Load the sample PDF file
doc.LoadFromFile(@"C:\Users\Administrator\Desktop\table.pdf");
//Create a StringBuilder object
StringBuilder builder = new StringBuilder();
//Initialize an instance of PdfTableExtractor class
PdfTableExtractor extractor = new PdfTableExtractor(doc);
//Declare a PdfTable array
PdfTable[] tableList = null;
//Loop through the pages
for (int pageIndex = 0; pageIndex < doc.Pages.Count; pageIndex++)
{
//Extract tables from a specific page
tableList = extractor.ExtractTable(pageIndex);
//Determine if the table list is null
if (tableList != null && tableList.Length > 0)
{
//Loop through the table in the list
foreach (PdfTable table in tableList)
{
//Get row number and column number of a certain table
int row = table.GetRowCount();
int column = table.GetColumnCount();
//Loop though the row and colunm
for (int i = 0; i < row; i++)
{
for (int j = 0; j < column; j++)
{
//Get text from the specific cell
string text = table.GetText(i, j);
//Add text to the string builder
builder.Append(text + " ");
}
builder.Append("\r\n");
}
}
}
}
//Write to a .txt file
File.WriteAllText("Table.txt", builder.ToString());
}
}
}
Imports System.IO
Imports System.Text
Imports Spire.Pdf
Imports Spire.Pdf.Utilities
Namespace ExtractPdfTable
Class Program
Shared Sub Main(ByVal args() As String)
'Create a PdfDocument object
Dim doc As PdfDocument = New PdfDocument()
'Load the sample PDF file
doc.LoadFromFile("C:\Users\Administrator\Desktop\table.pdf")
'Create a StringBuilder object
Dim builder As StringBuilder = New StringBuilder()
'Initialize an instance of PdfTableExtractor class
Dim extractor As PdfTableExtractor = New PdfTableExtractor(doc)
'Declare a PdfTable array
Dim tableList() As PdfTable = Nothing
'Loop through the pages
Dim pageIndex As Integer
For pageIndex = 0 To doc.Pages.Count- 1 Step pageIndex + 1
'Extract tables from a specific page
tableList = extractor.ExtractTable(pageIndex)
'Determine if the table list is null
If tableList <> Nothing And tableList.Length > 0 Then
'Loop through the table in the list
Dim table As PdfTable
For Each table In tableList
'Get row number and column number of a certain table
Dim row As Integer = table.GetRowCount()
Dim column As Integer = table.GetColumnCount()
'Loop though the row and colunm
Dim i As Integer
For i = 0 To row- 1 Step i + 1
Dim j As Integer
For j = 0 To column- 1 Step j + 1
'Get text from the specific cell
Dim text As String = table.GetText(i,j)
'Add text to the string builder
builder.Append(text + " ")
Next
builder.Append("\r\n")
Next
Next
End If
Next
'Write to a .txt file
File.WriteAllText("Table.txt", builder.ToString())
End Sub
End Class
End Namespace
Apply for a Temporary License
If you'd like to remove the evaluation message from the generated documents, or to get rid of the function limitations, please request a 30-day trial license for yourself.