En la era digital actual, extraer texto de imágenes o archivos PDF escaneados es un requisito común para diversas aplicaciones. El reconocimiento óptico de caracteres (OCR) es una tecnología que permite a las computadoras reconocer y extraer texto de dichos documentos. Con él, podemos convertir sin esfuerzo imágenes y archivos PDF escaneados a formatos editables y con capacidad de búsqueda, lo que facilita el procesamiento y análisis del contenido textual. En este blog, exploraremos cómo extraer texto de imágenes y archivos PDF escaneados con OCR en C#.
- Extraer texto de imágenes en C#
- Extraer texto de imágenes con coordenadas en C#
- Extraiga texto de archivos PDF escaneados en C#
Bibliotecas C# para extraer texto de imágenes y archivos PDF escaneados
Para extraer texto de imágenes, utilizaremos Spire.OCR for .NET biblioteca. Spire.OCR for .NET es una poderosa biblioteca diseñada específicamente para extraer texto de imágenes en aplicaciones .NET. Admite varios formatos de imagen como BMP, JPG, PNG, TIFF y GIF.
Estos son los pasos para instalar Spire.OCR for .NET:
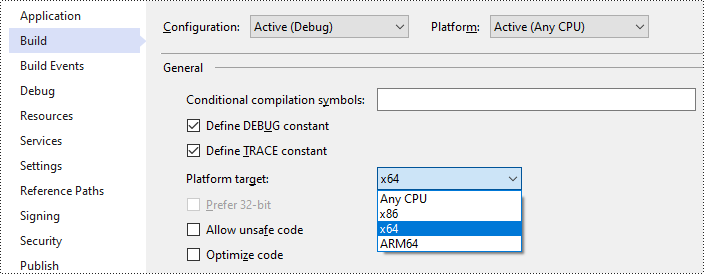
- Cambie la plataforma de destino de su solución a x64.
- Instale Spire.OCR desde NuGet ejecutando el siguiente comando en la consola del Administrador de paquetes NuGet:
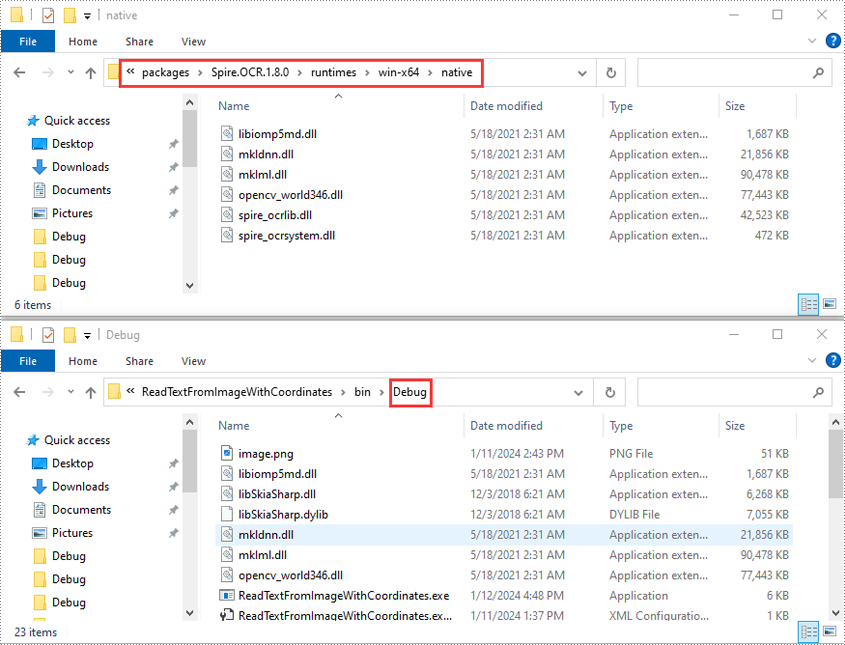
- Abra la carpeta de su solución y navegue hasta el directorio "packages\Spire.OCR.1.8.0\runtimes\win-x64\native". Copie los archivos DLL de este directorio y péguelos en la carpeta "Depurar" de su solución.
Install-Package Spire.OCR
Para extraer texto de archivos PDF escaneados, primero debemos convertir el documento PDF en imágenes. Para esta tarea, emplearemos la biblioteca Spire.PDF for .NET. Una vez completada la conversión, podemos utilizar Spire.OCR para extraer texto de las imágenes resultantes.
Puede instalar Spire.PDF for .NET desde NuGet ejecutando el siguiente comando en la consola del Administrador de paquetes NuGet:
Install-Package Spire.PDF
Extraer texto de imágenes en C#
Spire.OCR proporciona el método OcrScanner.Scan() para reconocer texto de una imagen. Después del reconocimiento, puede obtener el texto reconocido utilizando la propiedad OcrScanner.Text.
Estos son los pasos principales para reconocer texto de una imagen usando Spire.OCR:
- Cree una instancia de la clase OcrScanner.
- Reconocer texto de una imagen usando el método OcrScanner.Scan().
- Obtenga el texto reconocido del objeto OcrScanner usando la propiedad OcrScanner.Text.
- Guarde el texto en un archivo de texto.
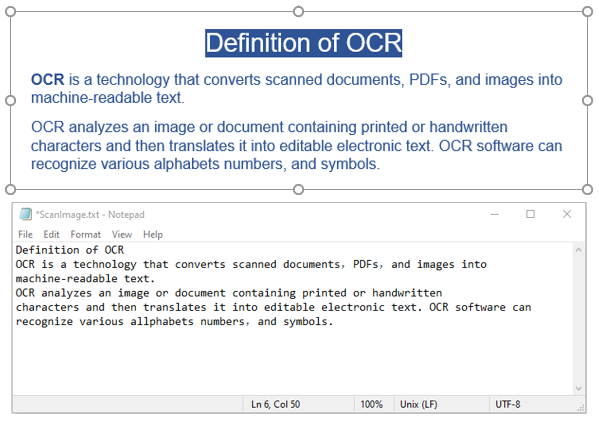
A continuación se muestra un ejemplo de código que muestra cómo reconocer texto de una imagen y guardar el resultado en un archivo de texto:
- C#
using Spire.OCR;
using System.IO;
namespace ReadTextFromImage
{
internal class Program
{
static void Main(string[] args)
{
//Specify the path of the input image file
string imageFilePath = "Image.png";
//Specify the path of the output text file
string outputFilePath = "ScanImage.txt";
//Call the ScanTextFromImage method to scan text from an image
string scannedText = ScanTextFromImage(imageFilePath);
//Write the text to the specified file
File.WriteAllText(outputFilePath, scannedText);
}
public static string ScanTextFromImage(string imageFilePath)
{
//Instantiate an OcrScanner object
using (OcrScanner ocrScanner = new OcrScanner())
{
//Scan text from the image
ocrScanner.Scan(imageFilePath);
//Get the recognized text from the OcrScanner object
IOCRText text = ocrScanner.Text;
//Return the text
return text.ToString();
}
}
}
}
Extraer texto de imágenes con coordenadas en C#
Extraer coordenadas es útil cuando necesita identificar la ubicación exacta de elementos de texto específicos en su imagen. Con Spire.OCR, puedes recuperar el texto reconocido en bloques o líneas. Para cada bloque, puede obtener información detallada de su ubicación, incluidas las coordenadas xey, así como su ancho y alto.
Estos son los pasos principales para extraer texto junto con su información de ubicación de una imagen usando Spire.OCR:
- Cree una instancia de la clase OcrScanner.
- Reconocer texto de una imagen usando el método OcrScanner.Scan().
- Obtenga el texto reconocido del objeto OcrScanner usando la propiedad OcrScanner.Text.
- Iterar a través de los bloques de texto del texto reconocido.
- Para cada bloque, obtenga su texto y su información de ubicación usando las propiedades IOCRTextBlock.Text y IOCRTextBlock.Box, luego agregue el resultado a una lista de cadenas.
- Guarde el contenido de la lista en un archivo de texto.
A continuación se muestra un ejemplo de código que muestra cómo reconocer texto junto con su información de ubicación de una imagen y guardar el resultado en un archivo de texto:
- C#
using Spire.OCR;
using System.Collections.Generic;
using System.IO;
namespace ReadTextFromImageWithCoordinates
{
internal class Program
{
static void Main(string[] args)
{
//Specify the path of the input image file
string imagePath = "Image.png";
//Specify the path of the output text file
string outputFile = "ScanImageWithCoordinates.txt";
//Call the ScanTextFromImageWithCoordinates method to extract text and its area information from the image
List<string> extractedText = ScanTextFromImageWithCoordinates(imagePath);
//Write the result to the specified file
File.WriteAllLines(outputFile, extractedText);
}
//Retrieve the text blocks along with their location information (x, y, width, height) from an image
public static List<string> ScanTextFromImageWithCoordinates(string imageFilePath)
{
//Create a list
List<string> extractedText = new List<string>();
//Instantiate an OcrScanner object
using (OcrScanner ocrScanner = new OcrScanner())
{
//Scan text from the image
ocrScanner.Scan(imageFilePath);
//Get the scanned text
IOCRText text = ocrScanner.Text;
//Iterate through each text block
foreach (IOCRTextBlock block in text.Blocks)
{
//Append the text of each block and its location information to the list
extractedText.Add($"Text: {block.Text}\nRectangular Area: {block.Box}");
}
}
return extractedText;
}
}
}
Extraiga texto de archivos PDF escaneados en C#
Para extraer texto de archivos PDF escaneados, debemos seguir un proceso de dos pasos. Primero, usamos Spire.PDF para convertir los archivos PDF escaneados en imágenes. Luego, utilizamos Spire.OCR para extraer el texto de esas imágenes.
Estos son los pasos principales para reconocer texto de un PDF escaneado usando Spire.PDF y Spire.OCR:
- Cree una instancia de la clase PdfDocument.
- Cargue un documento PDF utilizando el método PdfDocument.LoadFromFile().
- Iterar a través de las páginas del documento PDF.
- Convierta cada página en un objeto Imagen utilizando el método PdfDocument.SaveAsImage().
- Guarde el objeto Imagen en una secuencia usando el método Image.Save().
- Cree una instancia de la clase OcrScanner.
- Reconozca texto de la secuencia utilizando el método OcrScanner.Scan().
- Obtenga el texto reconocido utilizando la propiedad IOCRText.Text y agréguelo a una lista de cadenas.
- Guarde el contenido de la lista en un archivo de texto.
A continuación se muestra un ejemplo de código que muestra cómo reconocer texto de un PDF escaneado y guardar el resultado en un archivo de texto:
- C#
using Spire.OCR;
using Spire.Pdf;
using System.Collections.Generic;
using System.Drawing;
using System.Drawing.Imaging;
using System.IO;
namespace ReadTextFromScannedPDF
{
internal class Program
{
static void Main(string[] args)
{
//Specify the path of the scanned PDF file
string pdfFilePath = "Sample.pdf";
//Specify the path of the output text file
string outputFilePath = "ScanPDF.txt";
//Extract text from the scanned PDF
List<string> extractedText = ExtractTextFromScannedPDF(pdfFilePath);
//Write the text to the specified file
File.WriteAllLines(outputFilePath, extractedText);
}
//Extract text from a scanned PDF
public static List<string> ExtractTextFromScannedPDF(string pdfFilePath)
{
//Create a list to store the extracted text
List<string> extractedText = new List<string>();
//Create an instance of the PdfDocument class
using (PdfDocument document = new PdfDocument())
{
//Load the PDF document
document.LoadFromFile(pdfFilePath);
//Iterate through each page of the document
for (int pageIndex = 0; pageIndex < document.Pages.Count; pageIndex++)
{
//Convert the page to an image
using (Image image = document.SaveAsImage(pageIndex, 300, 300))
{
//Create a memory stream to hold the image data
using (MemoryStream stream = new MemoryStream())
{
//Save the image to the memory stream in PNG format
image.Save(stream, ImageFormat.Png);
stream.Position = 0;
//Scan the text from the image and add it to the list
string text = ScanTextFromImageStream(stream);
extractedText.Add(text);
}
}
}
}
//Return the list
return extractedText;
}
//Scan text from an image stream
public static string ScanTextFromImageStream(Stream stream)
{
//Create an instance of the OcrScanner class
using (OcrScanner ocrScanner = new OcrScanner())
{
//Scan the text from the image stream in PNG format
ocrScanner.Scan(stream, OCRImageFormat.Png);
IOCRText text = ocrScanner.Text;
//Return the text
return text.ToString();
}
}
}
}
Obtenga una licencia gratuita
Para experimentar plenamente las capacidades de Spire.OCR for .NET o Spire.PDF for .NET sin limitaciones de evaluación, puede solicitar una licencia de prueba gratuita de 30 días.
Conclusión
Esta publicación de blog demostró cómo extraer texto de imágenes y documentos PDF escaneados en C#. Si tiene alguna pregunta, no dude en publicarla en nuestro foro o enviarla a nuestro equipo de soporte por correo electrónico.