
Trabajar con datos tabulares es una tarea común para los desarrolladores de Python, y Pandas es la biblioteca de referencia para la manipulación y el análisis de datos. A menudo, los desarrolladores necesitan exportar DataFrames de Pandas a Excel para informes, colaboración en equipo o análisis de datos adicionales. Aunque Pandas proporciona la función to_excel para exportaciones básicas, crear informes de Excel profesionales con encabezados formateados, celdas con estilo, múltiples hojas y gráficos puede ser un desafío.
Este tutorial demuestra cómo escribir un único DataFrame o múltiples DataFrames en Excel usando Spire.XLS for Python, una biblioteca de Excel multifuncional que permite la personalización completa de archivos de Excel directamente desde Python, sin necesidad de tener Microsoft Excel instalado.
Tabla de Contenidos
- Por qué usar Spire.XLS para exportar DataFrame de Pandas a Excel
- Requisitos previos para exportar DataFrame de Pandas a Excel
- Exportar un único DataFrame de Pandas a Excel con formato
- Convertir múltiples DataFrames de Pandas a un solo archivo de Excel
- Escribir DataFrames de Pandas en un archivo de Excel existente
- Personalización avanzada para exportar DataFrames de Pandas a Excel
- Conclusión
- Preguntas frecuentes
Por qué usar Spire.XLS para exportar DataFrame de Pandas a Excel
Aunque Pandas proporciona una funcionalidad básica de exportación a Excel, Spire.XLS la amplía al dar un control total sobre la creación de archivos de Excel. En lugar de simplemente escribir datos sin procesar, los desarrolladores pueden:
- Organizar múltiples DataFrames en hojas separadas dentro de un solo libro de trabajo.
- Personalizar encabezados, fuentes, colores y formato de celdas para producir diseños profesionales.
- Autoajustar columnas y ajustar la altura de las filas para mejorar la legibilidad.
- Añadir gráficos, fórmulas y otras características de Excel directamente desde Python
Requisitos previos para exportar DataFrame de Pandas a Excel
Antes de exportar un DataFrame de Pandas a Excel, asegúrese de tener instaladas las siguientes bibliotecas requeridas. Puede hacerlo ejecutando el siguiente comando en la terminal de su proyecto:
pip install pandas spire.xls
Estas bibliotecas le permiten escribir DataFrames en Excel con múltiples hojas, formato personalizado, gráficos atractivos y diseños estructurados.
Exportar un único DataFrame de Pandas a Excel con formato
Exportar un único DataFrame a un archivo de Excel es el escenario más común. Usando Spire.XLS, no solo puede exportar su DataFrame, sino también formatear encabezados, aplicar estilo a las celdas y agregar gráficos para que su informe se vea profesional.
Repasemos este proceso paso a paso.
Paso 1: Crear un DataFrame de muestra
Primero, necesitamos crear un DataFrame. Aquí, tenemos nombres de empleados, departamentos y salarios. Por supuesto, puede reemplazar esto con su propio conjunto de datos.
import pandas as pd
from spire.xls import *
# Crear un DataFrame simple
df = pd.DataFrame({
'Employee': ['Alice', 'Bob', 'Charlie'],
'Department': ['HR', 'Finance', 'IT'],
'Salary': [5000, 6000, 7000]
})
Paso 2: Crear un libro de trabajo y acceder a la primera hoja
Ahora crearemos un nuevo libro de trabajo de Excel y prepararemos la primera hoja de cálculo. Démosle un nombre significativo para que sea fácil de entender.
# Crear un nuevo libro de trabajo
workbook = Workbook()
sheet = workbook.Worksheets[0]
sheet.Name = "Datos de Empleados"
Paso 3: Escribir los encabezados de las columnas
Escribiremos los encabezados en la primera fila, los pondremos en negrita y agregaremos un fondo gris claro para que todo se vea ordenado.
# Escribir encabezados de columna
for colIndex, colName in enumerate(df.columns, start=1):
cell = sheet.Range[1, colIndex]
cell.Text = colName
cell.Style.Font.IsBold = True # Poner encabezados en negrita
cell.Style.Color = Color.get_LightGray() # Fondo gris claro
Paso 4: Escribir las filas de datos
A continuación, escribimos cada fila del DataFrame. Para los números, usamos la propiedad NumberValue para que Excel pueda reconocerlos para cálculos y gráficos.
# Escribir filas de datos
for rowIndex, row in enumerate(df.values, start=2):
for colIndex, value in enumerate(row, start=1):
cell = sheet.Range[rowIndex, colIndex]
if isinstance(value, (int, float)):
cell.NumberValue = value
else:
cell.Text = str(value)
Paso 5: Aplicar bordes y autoajustar columnas
Para darle a su hoja de Excel una apariencia pulida y similar a una tabla, agreguemos bordes y ajustemos automáticamente el ancho de las columnas.
# Aplicar bordes y autoajustar columnas
usedRange = sheet.AllocatedRange
usedRange.BorderAround(LineStyleType.Thin, Color.get_Black()) # Bordes exteriores
usedRange.BorderInside(LineStyleType.Thin, Color.get_Black()) # Bordes interiores
usedRange.AutoFitColumns()
Paso 6: Agregar un gráfico para visualizar datos
Los gráficos le ayudan a comprender rápidamente las tendencias. Aquí, crearemos un gráfico de columnas para comparar los salarios.
# Agregar un gráfico
chart = sheet.Charts.Add()
chart.ChartType = ExcelChartType.ColumnClustered
chart.DataRange = sheet.Range["A1:C4"] # Rango de datos para el gráfico
chart.SeriesDataFromRange = False
chart.LeftColumn = 5 # Posición del gráfico
chart.TopRow = 1
chart.RightColumn = 10
chart.BottomRow = 16
chart.ChartTitle = "Comparación de salarios de empleados"
chart.ChartTitleArea.Font.Size = 12
chart.ChartTitleArea.Font.IsBold = True
Paso 7: Guardar el libro de trabajo
Finalmente, guarde el libro de trabajo en la ubicación deseada.
# Guardar el archivo de Excel
workbook.SaveToFile("DataFrameWithChart.xlsx", ExcelVersion.Version2016)
workbook.Dispose()
Resultado:
El archivo XLSX de Excel generado a partir del DataFrame de Pandas se ve así:
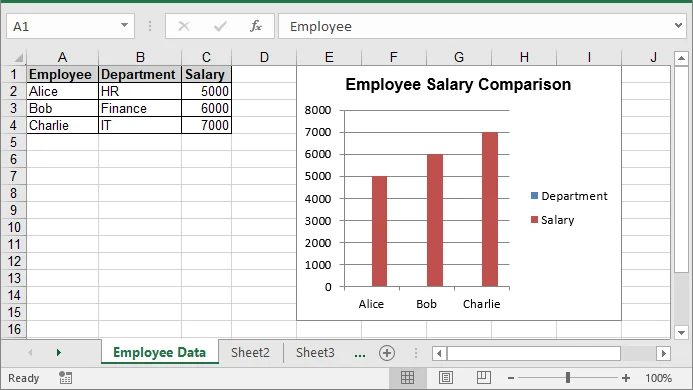
Una vez que se genera el archivo de Excel, se puede procesar más, como convertirlo a PDF para compartirlo fácilmente:
workbook.SaveToFile("ToPdf.pdf", FileFormat.PDF)
Para más detalles, consulte la guía sobre convertir Excel a PDF en Python.
Convertir múltiples DataFrames de Pandas a un solo archivo de Excel
Al crear informes de Excel, a menudo es necesario colocar múltiples conjuntos de datos en hojas separadas. Usando Spire.XLS, cada DataFrame de Pandas se puede escribir en su propia hoja de trabajo, asegurando que los datos relacionados estén organizados de forma clara y sean fáciles de analizar. Los siguientes pasos demuestran este flujo de trabajo.
Paso 1: Crear múltiples DataFrames de muestra
Antes de exportar, creamos dos DataFrames separados: uno para la información de los empleados y otro para los productos. Cada DataFrame irá a su propia hoja de Excel.
import pandas as pd
from spire.xls import *
# DataFrames de muestra
df1 = pd.DataFrame({'Name': ['Alice', 'Bob'], 'Age': [25, 30]})
df2 = pd.DataFrame({'Product': ['Laptop', 'Phone'], 'Price': [1000, 500]})
# Lista de DataFrames con los nombres de hoja correspondientes
dataframes = [
(df1, "Empleados"),
(df2, "Productos")
]
Aquí, dataframes es una lista de tuplas que empareja cada DataFrame con el nombre de la hoja en la que debe aparecer.
Paso 2: Crear un nuevo libro de trabajo
A continuación, creamos un nuevo libro de trabajo de Excel para almacenar todos los DataFrames.
# Crear un nuevo libro de trabajo
workbook = Workbook()
Esto inicializa un libro de trabajo en blanco con tres hojas predeterminadas. Las renombraremos y poblaremos en el siguiente paso.
Paso 3: Recorrer cada DataFrame y escribirlo en su propia hoja
En lugar de escribir cada DataFrame individualmente, podemos recorrer nuestra lista y procesarlos de la misma manera. Esto reduce el código duplicado y facilita el manejo de más conjuntos de datos.
for i, (df, sheet_name) in enumerate(dataframes):
# Obtener o crear una hoja
if i < workbook.Worksheets.Count:
sheet = workbook.Worksheets[i]
else:
sheet = workbook.Worksheets.Add()
sheet.Name = sheet_name
# Escribir encabezados con fuente en negrita y color de fondo
for colIndex, colName in enumerate(df.columns, start=1):
cell = sheet.Range[1, colIndex]
cell.Text = colName
cell.Style.Font.IsBold = True
cell.Style.Color = Color.get_LightGray()
sheet.Columns[colIndex - 1].ColumnWidth = 15 # Establecer ancho de columna fijo
# Escribir filas de datos
for rowIndex, row in enumerate(df.values, start=2):
for colIndex, value in enumerate(row, start=1):
cell = sheet.Range[rowIndex, colIndex]
if isinstance(value, (int, float)):
cell.NumberValue = value
else:
cell.Text = str(value)
# Aplicar bordes delgados alrededor del rango usado
usedRange = sheet.AllocatedRange
usedRange.BorderAround(LineStyleType.Thin, Color.get_Black()) # Bordes exteriores
usedRange.BorderInside(LineStyleType.Thin, Color.get_Black()) # Bordes interiores
Usando este bucle, podemos agregar fácilmente más DataFrames en el futuro sin reescribir el mismo código.
Paso 4: Guardar el libro de trabajo
Finalmente, guardamos el archivo de Excel. Ambos conjuntos de datos ahora están organizados de forma ordenada en un solo archivo con hojas separadas, encabezados formateados y bordes adecuados.
# Guardar el libro de trabajo
workbook.SaveToFile("MultipleDataFrames.xlsx", ExcelVersion.Version2016)
workbook.Dispose()
Ahora su archivo de Excel está listo para ser compartido o analizado más a fondo.
Resultado:

El archivo MultipleDataFrames.xlsx contiene dos hojas:
- Empleados (con nombres y edades)
- Productos (con detalles de productos y precios)
Esta organización hace que los archivos de Excel con múltiples informes sean limpios y fáciles de navegar.
Escribir DataFrames de Pandas en un archivo de Excel existente
En algunos casos, en lugar de crear un nuevo archivo de Excel, es posible que necesite escribir DataFrames en un libro de trabajo existente. Esto se puede lograr fácilmente cargando el libro de trabajo existente, agregando una nueva hoja o accediendo a la hoja deseada y escribiendo los datos del DataFrame con la misma lógica.
El siguiente código muestra cómo escribir un DataFrame de Pandas en un archivo de Excel existente:
import pandas as pd
from spire.xls import *
# Cargar un archivo de Excel existente
workbook = Workbook()
workbook.LoadFromFile("MultipleDataFrames.xlsx")
# Crear un nuevo DataFrame para agregar
new_df = pd.DataFrame({
'Region': ['North', 'South', 'East', 'West'],
'Sales': [12000, 15000, 13000, 11000]
})
# Agregar una nueva hoja de trabajo para el nuevo DataFrame
new_sheet = workbook.Worksheets.Add("Ventas Regionales")
# Escribir encabezados
for colIndex, colName in enumerate(new_df.columns, start=1):
cell = new_sheet.Range[1, colIndex]
cell.Text = colName
cell.Style.Font.IsBold = True
cell.Style.Color = Color.get_LightGray()
new_sheet.Columns[colIndex - 1].ColumnWidth = 15
# Escribir filas de datos
for rowIndex, row in enumerate(new_df.values, start=2):
for colIndex, value in enumerate(row, start=1):
cell = new_sheet.Range[rowIndex, colIndex]
if isinstance(value, (int, float)):
cell.NumberValue = value
else:
cell.Text = str(value)
# Guardar los cambios
workbook.SaveToFile("DataFrameToExistingWorkbook.xlsx", ExcelVersion.Version2016)
workbook.Dispose()
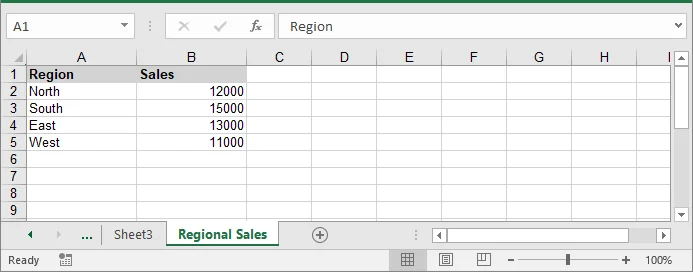
Personalización avanzada para exportar DataFrames de Pandas a Excel
Más allá de las exportaciones básicas, los DataFrames de Pandas se pueden personalizar en Excel para cumplir con requisitos específicos de informes. Las opciones avanzadas, como seleccionar columnas específicas e incluir o excluir el índice, le permiten crear archivos de Excel más limpios, legibles y profesionales. Los siguientes ejemplos demuestran cómo aplicar estas personalizaciones.
1. Seleccionar columnas específicas
A veces, es posible que no necesite exportar todas las columnas de un DataFrame. Al seleccionar solo las columnas relevantes, puede mantener sus informes de Excel concisos y enfocados. El siguiente código demuestra cómo recorrer las columnas elegidas al escribir encabezados y filas:
import pandas as pd
from spire.xls import *
# Crear un DataFrame
df = pd.DataFrame({
'Employee': ['Alice', 'Bob', 'Charlie'],
'Department': ['HR', 'Finance', 'IT'],
'Salary': [5000, 6000, 7000]
})
# Establecer las columnas a exportar
columns_to_export = ['Employee', 'Department']
# Crear un nuevo libro de trabajo y acceder a la primera hoja
workbook = Workbook()
sheet = workbook.Worksheets[0]
# Escribir encabezados
for colIndex, colName in enumerate(columns_to_export, start=1):
sheet.Range[1, colIndex].Text = colName
# Escribir filas
for rowIndex, row in enumerate(df[columns_to_export].values, start=2):
for colIndex, value in enumerate(row, start=1):
sheet.Range[rowIndex, colIndex].Text = value
# Guardar el archivo de Excel
workbook.SaveToFile("select_columns.xlsx")
workbook.Dispose()
2. Incluir o excluir el índice
Por defecto, el índice del DataFrame no se incluye en la exportación. Si su informe requiere identificadores de fila o índices numéricos, puede agregarlos manualmente. Este fragmento de código muestra cómo incluir el índice junto con las columnas seleccionadas:
# Escribir encabezado para el índice
sheet.Range[1, 1].Text = "Index"
# Escribir valores de índice (numéricos)
for rowIndex, idx in enumerate(df.index, start=2):
sheet.Range[rowIndex, 1].NumberValue = idx # Usar NumberValue para numéricos
# Escribir encabezados para otras columnas
for colIndex, colName in enumerate(columns_to_export, start=2):
sheet.Range[1, colIndex].Text = colName
# Escribir las filas de datos
for rowIndex, row in enumerate(df[columns_to_export].values, start=2):
for colIndex, value in enumerate(row, start=2):
if isinstance(value, (int, float)):
sheet.Range[rowIndex, colIndex].NumberValue = value
else:
sheet.Range[rowIndex, colIndex].Text = str(value)
# Guardar el libro de trabajo
workbook.SaveToFile("include_index.xlsx", ExcelVersion.Version2016)
workbook.Dispose()
Conclusión
Exportar un DataFrame de Pandas a Excel es simple, pero producir informes profesionales y bien formateados requiere un control adicional. Al usar Pandas para la preparación de datos y Spire.XLS for Python para crear y formatear archivos de Excel, puede generar libros de trabajo estructurados, legibles y visualmente organizados. Este enfoque funciona tanto para DataFrames individuales como para múltiples conjuntos de datos, lo que facilita la creación de informes de Excel que están listos para el análisis, el uso compartido o la manipulación posterior.
Preguntas frecuentes
P1: ¿Cómo puedo exportar un DataFrame de Pandas a Excel en Python?
R1: Puede usar bibliotecas como Spire.XLS para escribir un DataFrame en un archivo de Excel. Esto le permite transferir datos tabulares de Python a Excel manteniendo el control sobre el formato y el diseño.
P2: ¿Puedo exportar más de un DataFrame a un solo archivo de Excel?
R2: Sí. Se pueden escribir múltiples DataFrames en hojas separadas dentro del mismo libro de trabajo. Esto ayuda a mantener organizados los conjuntos de datos relacionados en un solo archivo.
P3: ¿Cómo agrego encabezados y formato a las celdas en Excel desde un DataFrame?
R3: Los encabezados se pueden poner en negrita, colorear o tener anchos fijos. Los valores numéricos se pueden almacenar como números y el texto como cadenas. El formato mejora la legibilidad de los informes.
P4: ¿Es posible incluir gráficos en el archivo de Excel exportado?
R4: Sí. Se pueden agregar gráficos como los de columnas o líneas basados en los datos de su DataFrame para ayudar a visualizar tendencias o comparaciones.
P5: ¿Necesito tener Microsoft Excel instalado para exportar DataFrames?
R5: No necesariamente. Algunas bibliotecas, incluido Spire.XLS, pueden crear y formatear archivos de Excel completamente en Python sin depender de que Excel esté instalado.