XML is a widely used format for storing structured data, but it’s not ideal for analysis or tabular tools like Excel. Converting XML to CSV allows you to work with the data in a simpler, flat format that’s compatible with spreadsheets and data analysis libraries. By converting XML to CSV, you can easily import data into Excel, perform calculations, or feed it into Python data analysis tools like Pandas.
This approach also helps standardize complex hierarchical data into a format that is easier to read, manipulate, and share across different applications. In this tutorial, we’ll explore how to efficiently transform XML files into CSV using Spire.XLS for Python.
Table of Contents:
- Setting Up Spire.XLS for Python
- Understanding XML Data Structures
- How XML Data Is Extracted and Converted
- Basic Example: Convert XML to CSV with Python
- Advanced Techniques
- Troubleshooting and Common Issues
- Conclusion
- FAQs
Setting Up Spire.XLS for Python
Before we can start, we need to install the Spire.XLS library. The package is available on PyPI , so installation is straightforward. Run the following command:
pip install spire.xls
Once installed, you can import the required classes:
from spire.xls import *
from spire.xls.common import *
Spire.XLS provides the Workbook and Worksheet objects for managing Excel-like files. You’ll use them to create new CSV files and populate them with your XML data.
Understanding XML Data Structures
XML files are organized in a tree-like hierarchy, where elements (or nodes) are enclosed in tags. Each element can contain text, attributes, or even other child elements.
For example, consider this Books.xml:
<catalog>
<book isbn="9780451524935">
<title>The Catcher in the Rye</title>
<author>J.D. Salinger</author>
<genre>Fiction</genre>
<reviews>
<review>Excellent coming-of-age story</review>
<review>A true classic</review>
</reviews>
</book>
<book isbn="9780439023528">
<title>The Hunger Games</title>
<author>Suzanne Collins</author>
<genre>Adventure</genre>
</book>
</catalog>
- Root node : <catalog> is the top-level container.
- Child nodes : Each <book> is a child of <catalog>.
- Elements : <title>, <author>, and <genre> are elements inside each <book>.
- Attributes : The isbn in <book isbn="..."> is an attribute attached to the book element.
- Nested elements : The <reviews> node contains multiple <review> sub-nodes.
Challenges when converting XML to CSV:
- Hierarchical data – XML allows nesting (e.g., <reviews> inside <book>), while CSV is flat.
- Attributes vs. elements – Data may be stored as an attribute (isbn) or as a tag (title).
- Optional fields – Not all <book> elements may contain the same tags, which can lead to missing values in the CSV.
A robust converter must be able to handle these differences and map hierarchical XML into a flat, tabular CSV format.
How XML Data Is Extracted and Converted
To load and parse an XML file in Python, you can use the built-in xml.etree.ElementTree library. This library lets you navigate the XML tree, retrieve elements, and access attributes. For example:
import xml.etree.ElementTree as ET
# Load the XML file
tree = ET.parse("Books.xml")
root = tree.getroot()
# Iterate through elements
for book in root.findall("book"):
title = book.findtext("title", "")
author = book.findtext("author", "")
isbn = book.attrib.get("isbn", "")
After extracting the XML data, the next step is to map it to a tabular structure . Using Spire.XLS for Python , you can create a workbook, write the extracted values into worksheet cells, and finally export the worksheet as a CSV file for easy analysis.
General Steps to Convert XML to CSV in Python
- Use xml.etree.ElementTree to load and retrieve data from the XML file.
- Create a Workbook object using Spire.XLS.
- Add a worksheet with Workbook.Worksheets.Add() .
- Write extracted XML data into the worksheet using Worksheet.SetValue() .
- Save the worksheet to a CSV file using Worksheet.SaveToFile() .
Basic Example: Convert XML to CSV with Python
Let’s start with a basic XML-to-CSV conversion. This example automatically generates headers by inspecting the first <book> element and then exports all child nodes into CSV.
from spire.xls import *
from spire.xls.common import *
import xml.etree.ElementTree as ET
# Create a Workbook object
workbook = Workbook()
# Remove default worksheets
workbook.Worksheets.Clear()
# Add a worksheet and name it
worksheet = workbook.Worksheets.Add("Books")
# Load an XML file
xml_tree = ET.parse("C:\\Users\\Administrator\\Desktop\\Books.xml")
# Get the root element of the XML tree
xml_root = xml_tree.getroot()
# Get the first the "book" element
first_book = xml_root.find("book")
# Extract header information and convert it into a list
header = list(first_book.iter())[1:]
# Write header to Excel
for col_index, header_node in enumerate(header, start=1):
header_text = header_node.tag
worksheet.SetValue(1, col_index, header_text)
# Write other data to Excel by iterating over each book element and each data node within it
row_index = 2
for book in xml_root.iter("book"):
for col_index, data_node in enumerate(list(book.iter())[1:], start=1):
value = data_node.text
header_text = list(header[col_index - 1].iter())[0].tag
worksheet.SetValue(row_index, col_index, value)
row_index += 1
# Save the document to an Excel file
worksheet.SaveToFile("output/XmlToCsv.csv", ",", Encoding.get_UTF8())
# Dispose resources
workbook.Dispose()
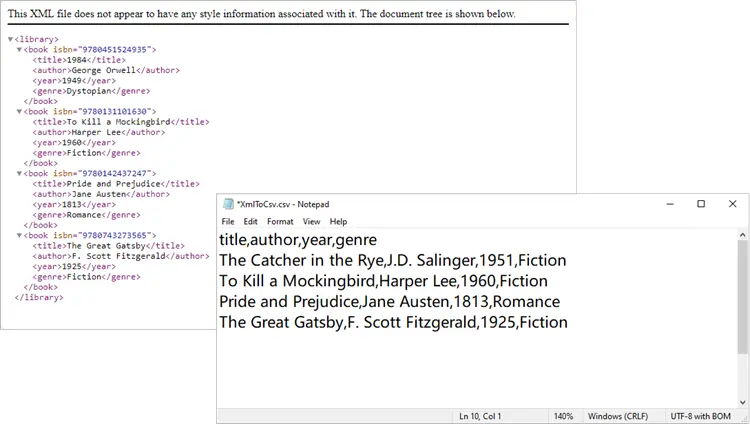
This script works well for simple, flat XML structures. It automatically generates headers (title, author, genre, price) and fills each row with corresponding values.
Output:
You might also be interested in: Convert XML to Excel and PDF in Python
Advanced Techniques
The basic script works in many cases, but XML often isn’t so simple. Let’s go through some advanced techniques to handle real-world scenarios.
Exporting Only Specific Elements
Sometimes your XML has more data than you need. Maybe you only want to export title and author, ignoring everything else.
from spire.xls import *
from spire.xls.common import *
import xml.etree.ElementTree as ET
# Create a Workbook object
workbook = Workbook()
# Remove default worksheets
workbook.Worksheets.Clear()
# Add a worksheet and name it
worksheet = workbook.Worksheets.Add("Books")
# Load the XML file
xml_tree = ET.parse(r"C:\Users\Administrator\Desktop\Books.xml")
xml_root = xml_tree.getroot()
# Define the elements you want to export
selected_elements = ["title", "author"]
# Write header
for col_index, tag in enumerate(selected_elements, start=1):
worksheet.SetValue(1, col_index, tag)
# Write data
row_index = 2
for book in xml_root.iter("book"):
for col_index, tag in enumerate(selected_elements, start=1):
# Use findtext to handle missing values safely
worksheet.SetValue(row_index, col_index, book.findtext(tag, ""))
row_index += 1
# Save the document to a CSV file
worksheet.SaveToFile("output/XmlToCsv_Selected.csv", ",", Encoding.get_UTF8())
# Dispose resources
workbook.Dispose()
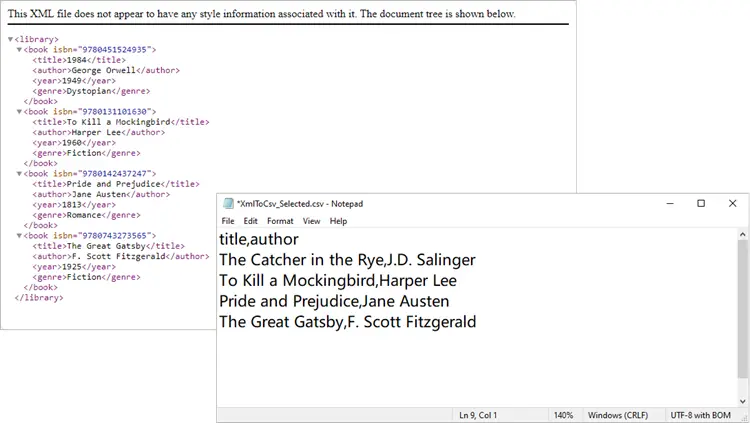
This approach ensures your CSV only contains the columns you care about.
Output:
Including XML Attributes in CSV
What if your XML contains important data stored as attributes, such as isbn? You can easily include them:
from spire.xls import *
from spire.xls.common import *
import xml.etree.ElementTree as ET
# Create a Workbook object
workbook = Workbook()
# Remove default worksheets
workbook.Worksheets.Clear()
# Add a worksheet and name it
worksheet = workbook.Worksheets.Add("Books")
# Load an XML file
xml_tree = ET.parse(r"C:\Users\Administrator\Desktop\Books.xml")
# Get the root element of the XML tree
xml_root = xml_tree.getroot()
# Get the first the "book" element
first_book = xml_root.find("book")
# Extract header information (child nodes)
header = list(first_book.iter())[1:]
# Write header to Excel
worksheet.SetValue(1, 1, "isbn") # <-- Add ISBN column first
for col_index, header_node in enumerate(header, start=2): # start at 2 now
header_text = header_node.tag
worksheet.SetValue(1, col_index, header_text)
# Write data
row_index = 2
for book in xml_root.iter("book"):
# Write isbn as text
isbn_value = book.attrib.get("isbn", "")
worksheet.Range[row_index, 1].Text = isbn_value
# Then write other fields
for col_index, data_node in enumerate(list(book.iter())[1:], start=2):
value = data_node.text
worksheet.SetValue(row_index, col_index, value)
row_index += 1
# Format the whole ISBN column as text to prevent scientific notation
last_row = row_index - 1
isbn_range = f"A2:A{last_row}"
worksheet.Range[isbn_range].NumberFormat = "@"
# Save the document to an Excel file (CSV format)
worksheet.SaveToFile("output/XmlToCsv_WithAttributes.csv", ",", Encoding.get_UTF8())
# Dispose resources
workbook.Dispose()
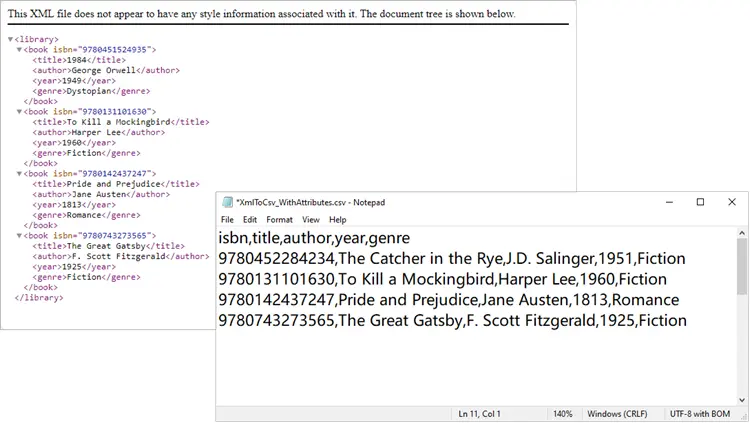
Here we explicitly create an ISBN column, extract it from each <book>’s attributes, and format it as text to prevent Excel from displaying it in scientific notation.
Output:
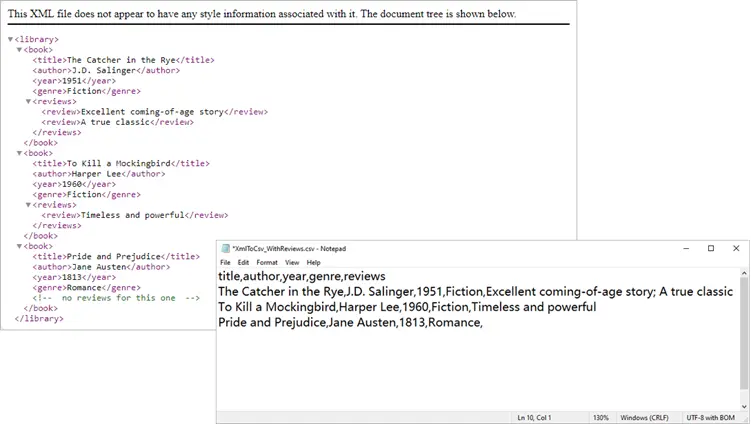
Handling Nested XML Structures
Nested nodes are common. Suppose your XML looks like this:
<catalog>
<book>
<title>1984</title>
<author>George Orwell</author>
<reviews>
<review>Excellent read!</review>
<review>Still relevant today.</review>
</reviews>
</book>
</catalog>
Here’s how to collapse multiple <review> entries into a single CSV column:
from spire.xls import *
from spire.xls.common import *
import xml.etree.ElementTree as ET
# Create a Workbook object
workbook = Workbook()
# Remove default worksheets
workbook.Worksheets.Clear()
# Add a worksheet and name it
worksheet = workbook.Worksheets.Add("Books")
# Load an XML file
xml_tree = ET.parse(r"C:\Users\Administrator\Desktop\Nested.xml")
xml_root = xml_tree.getroot()
# Get the first <book> element
first_book = xml_root.find("book")
# Collect headers (auto-detected)
header = []
for child in first_book:
if child.tag == "reviews":
header.append("reviews") # collapse nested <review> into one column
else:
header.append(child.tag)
# Write header row
for col_index, header_text in enumerate(header, start=1):
worksheet.SetValue(1, col_index, header_text)
# Write data rows
row_index = 2
for book in xml_root.iter("book"):
col_index = 1
for child in book:
if child.tag == "reviews":
# Join all <review> texts into a single cell
reviews = [r.text for r in child.findall("review") if r.text]
worksheet.SetValue(row_index, col_index, "; ".join(reviews))
else:
worksheet.SetValue(row_index, col_index, child.text if child.text else "")
col_index += 1
row_index += 1
# Save to CSV
worksheet.SaveToFile("output/XmlToCsv_WithReviews.csv", ",", Encoding.get_UTF8())
# Dispose resources
workbook.Dispose()
Output:
Spire.XLS not only supports importing data from standard XML files into Excel or CSV, but also allows converting OpenXML (Microsoft's XML-based file format) to Excel. If you're interested, check out this tutorial: How to Convert Excel to OpenXML and OpenXML to Excel in Python.
Troubleshooting and Common Issues
Even with a well-structured script, you may encounter some common issues when converting XML to CSV:
- Scientific notation in Excel
- Problem: Long numeric strings like ISBNs may appear as 9.78045E+12 instead of the full number.
- Solution: Format the column as text before saving, for example:
worksheet.Range["A2:A{last_row}"].NumberFormat = "@" -
Missing values causing errors
- Problem: Some <book> elements may lack optional fields (e.g., <genre>). Attempting to access .text directly can cause errors.
- Solution: Use findtext(tag, "") to safely provide a default empty string.
-
Incomplete or unexpected headers
- Problem: If you generate headers from only the first <book>, you might miss fields that appear later in the XML.
- Solution: Scan multiple elements (or the entire dataset) to build a complete header list before writing data.
-
Encoding issues
- Problem: Special characters (such as accents or symbols) may not display correctly in the CSV.
- Solution: Always save with UTF-8 encoding:
worksheet.SaveToFile("output.csv",",", Encoding.get_UTF8())
Conclusion
Converting XML to CSV in Python doesn’t have to be painful. With Spire.XLS for Python, you can automate much of the process, including header generation, handling attributes, and flattening nested nodes. Whether you’re exporting only a few fields, working with complex hierarchies, or cleaning up messy XML, Spire.XLS gives you the flexibility to handle it.
By integrating these approaches into your workflow, you can turn structured XML datasets into clean, analysis-ready CSV files in just a few lines of code.
FAQs
Q1: Can I export directly to Excel (.xlsx) instead of CSV?
Yes. Simply use workbook.SaveToFile("output.xlsx", ExcelVersion.Version2016).
Q2: How do I handle very large XML files?
Use Python’s iterparse() from xml.etree.ElementTree to stream large files instead of loading them fully into memory.
Q3: What if some <book> elements contain additional tags?
You can enhance the header-building step to scan all <book> nodes and collect unique tags dynamically.
Q4: Can I customize the CSV delimiter (e.g., use ; instead of ,)?
Yes. When calling SaveToFile(), replace the delimiter argument:
worksheet.SaveToFile("output.csv", ";", Encoding.get_UTF8())
Q5: How do I export nested XML structures (e.g., multiple <review> nodes)?
Flatten them into a single cell by joining values. For example:
reviews = [r.text for r in book.find("reviews").findall("review")]
worksheet.SetValue(row_index, col_index, "; ".join(reviews))
Get a Free License
To fully experience the capabilities of Spire.XLS for Python without any evaluation limitations, you can request a free 30-day trial license.
