I documenti PDF hanno un layout fisso e non consentono agli utenti di apportare modifiche al loro interno. Per rendere nuovamente modificabile il contenuto del PDF, puoi farlo convertire PDF in Word o estrarre testo da PDF. In questo articolo imparerai come farlo estrarre il testo da una pagina PDF specifica, come estrarre il testo da una particolare area rettangolare, e come farlo estrarre testo con SimpleTextExtractionStrategy in C# e VB.NET utilizzando Spire.PDF for .NET.
- Estrai testo da una pagina specificata
- Estrai testo da un rettangolo
- Estrai testo utilizzando SimpleTextExtractionStrategy
Installa Spire.PDF for .NET
Per cominciare, devi aggiungere i file DLL inclusi nel pacchetto Spire.PDF for.NET come riferimenti nel tuo progetto .NET. I file DLL possono essere scaricati da questo link o installato tramite NuGet.
PM> Install-Package Spire.PDF
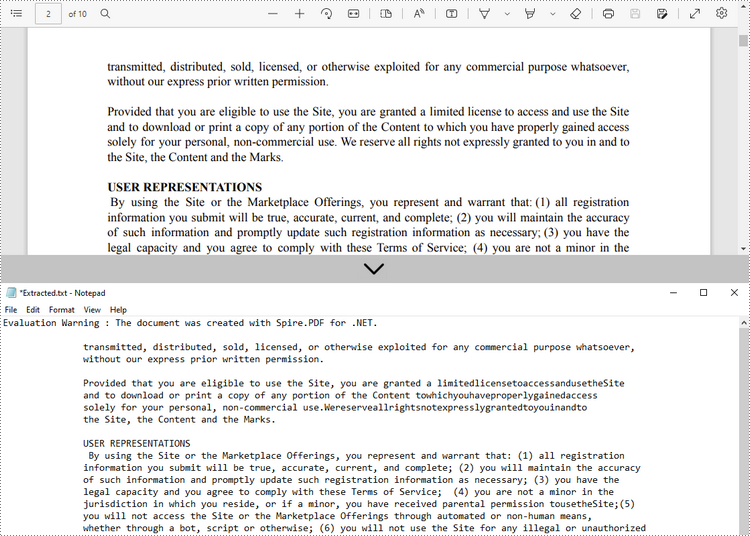
Estrai testo da una pagina specificata
Di seguito sono riportati i passaggi per estrarre il testo da una determinata pagina di un documento PDF utilizzando Spire.PDF for .NET.
- Crea un oggetto PdfDocument.
- Carica un file PDF utilizzando il metodo PdfDocument.LoadFromFile().
- Ottieni la pagina specifica tramite la proprietà PdfDocument.Pages[index].
- Crea un oggetto PdfTextExtractor.
- Crea un oggetto PdfTextExtractOptions e imposta la proprietà IsExtractAllText su true.
- Estrai il testo dalla pagina selezionata utilizzando il metodo PdfTextExtractor.ExtractText().
- Scrivi il testo estratto in un file TXT.
- C#
- VB.NET
using System;
using System.IO;
using Spire.Pdf;
using Spire.Pdf.Texts;
namespace ExtractTextFromPage
{
class Program
{
static void Main(string[] args)
{
//Create a PdfDocument object
PdfDocument doc = new PdfDocument();
//Load a PDF file
doc.LoadFromFile(@"C:\Users\Administrator\Desktop\Terms of Service.pdf");
//Get the second page
PdfPageBase page = doc.Pages[1];
//Create a PdfTextExtractot object
PdfTextExtractor textExtractor = new PdfTextExtractor(page);
//Create a PdfTextExtractOptions object
PdfTextExtractOptions extractOptions = new PdfTextExtractOptions();
//Set isExtractAllText to true
extractOptions.IsExtractAllText = true;
//Extract text from the page
string text = textExtractor.ExtractText(extractOptions);
//Write to a txt file
File.WriteAllText("Extracted.txt", text);
}
}
}
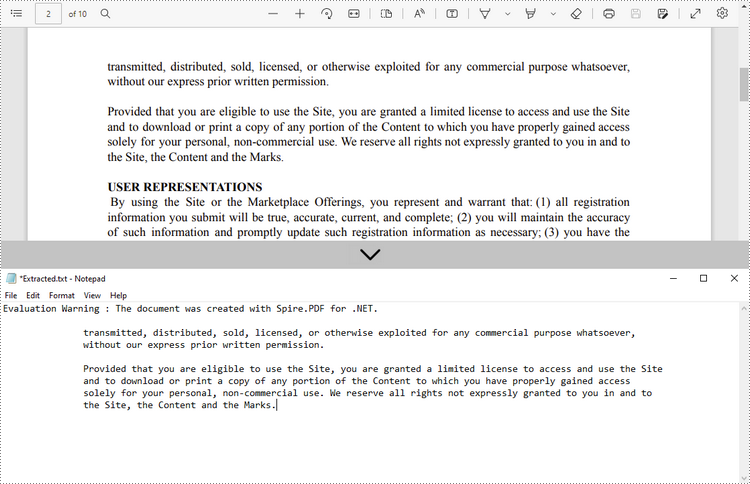
Estrai testo da un rettangolo
Di seguito sono riportati i passaggi per estrarre il testo da un'area rettangolare di una pagina utilizzando Spire.PDF for .NET.
- Crea un oggetto PdfDocument.
- Carica un file PDF utilizzando il metodo PdfDocument.LoadFromFile().
- Ottieni la pagina specifica tramite la proprietà PdfDocument.Pages[index].
- Crea un oggetto PdfTextExtractor.
- Crea un oggetto PdfTextExtractOptions e specifica l'area del rettangolo tramite la sua proprietà ExtractArea.
- Estrai il testo dal rettangolo utilizzando il metodo PdfTextExtractor.ExtractText().
- Scrivi il testo estratto in un file TXT.
- C#
- VB.NET
using Spire.Pdf;
using Spire.Pdf.Texts;
using System.IO;
using System.Drawing;
namespace ExtractTextFromRectangleArea
{
class Program
{
static void Main(string[] args)
{
//Create a PdfDocument object
PdfDocument doc = new PdfDocument();
//Load a PDF file
doc.LoadFromFile(@"C:\Users\Administrator\Desktop\Terms of Service.pdf");
//Get the second page
PdfPageBase page = doc.Pages[1];
//Create a PdfTextExtractot object
PdfTextExtractor textExtractor = new PdfTextExtractor(page);
//Create a PdfTextExtractOptions object
PdfTextExtractOptions extractOptions = new PdfTextExtractOptions();
//Set the rectangle area
extractOptions.ExtractArea = new RectangleF(0, 0, 890, 170);
//Extract text from the rectangle
string text = textExtractor.ExtractText(extractOptions);
//Write to a txt file
File.WriteAllText("Extracted.txt", text);
}
}
}
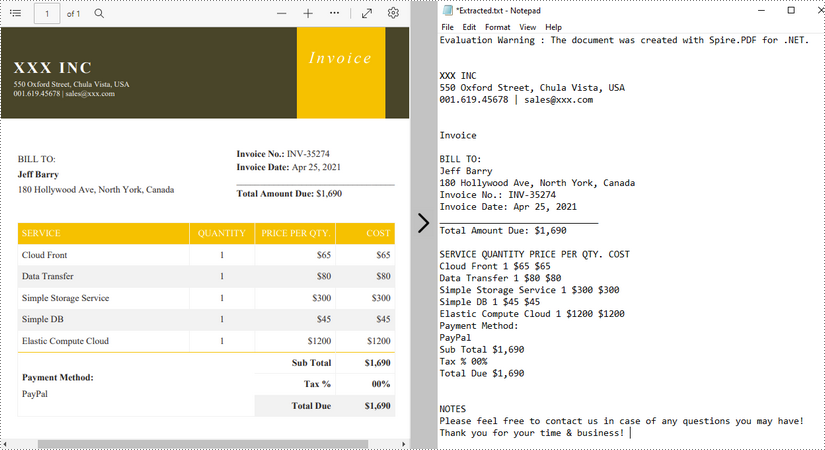
Estrai testo utilizzando SimpleTextExtractionStrategy
I metodi precedenti estraggono il testo riga per riga. Quando si estrae il testo utilizzando SimpleTextExtractionStrategy, tiene traccia della posizione Y corrente di ciascuna stringa e inserisce un'interruzione di riga nell'output se la posizione Y è cambiata. Di seguito sono riportati i passaggi dettagliati.
- Crea un oggetto PdfDocument.
- Carica un file PDF utilizzando il metodo PdfDocument.LoadFromFile().
- Ottieni la pagina specifica tramite la proprietà PdfDocument.Pages[index].
- Crea un oggetto PdfTextExtractor.
- Crea un oggetto PdfTextExtractOptions e imposta la proprietà IsSimpleExtraction su true.
- Estrai il testo dalla pagina selezionata utilizzando il metodo PdfTextExtractor.ExtractText().
- Scrivi il testo estratto in un file TXT.
- C#
- VB.NET
using System.IO;
using Spire.Pdf;
using Spire.Pdf.Texts;
namespace SimpleExtraction
{
class Program
{
static void Main(string[] args)
{
//Create a PdfDocument object
PdfDocument doc = new PdfDocument();
//Load a PDF file
doc.LoadFromFile(@"C:\Users\Administrator\Desktop\Invoice.pdf");
//Get the first page
PdfPageBase page = doc.Pages[0];
//Create a PdfTextExtractor object
PdfTextExtractor textExtractor = new PdfTextExtractor(page);
//Create a PdfTextExtractOptions object
PdfTextExtractOptions extractOptions = new PdfTextExtractOptions();
//Set IsSimpleExtraction to true
extractOptions.IsSimpleExtraction = true;
//Extract text from the selected page
string text = textExtractor.ExtractText(extractOptions);
//Write to a txt file
File.WriteAllText("Extracted.txt", text);
}
}
}
Richiedi una licenza temporanea
Se desideri rimuovere il messaggio di valutazione dai documenti generati o eliminare le limitazioni della funzione, per favore richiedere una licenza di prova di 30 giorni per te.