
Lavorare con dati tabulari è un compito comune per gli sviluppatori Python e Pandas è la libreria di riferimento per la manipolazione e l'analisi dei dati. Spesso, gli sviluppatori devono esportare i DataFrame di Pandas in Excel per la reportistica, la collaborazione in team o ulteriori analisi dei dati. Sebbene Pandas fornisca la funzione to_excel per esportazioni di base, la creazione di report Excel professionali con intestazioni formattate, celle stilizzate, fogli multipli e grafici può essere impegnativa.
Questo tutorial dimostra come scrivere un singolo DataFrame o più DataFrame in Excel utilizzando Spire.XLS per Python, una libreria Excel multifunzionale che consente la personalizzazione completa dei file Excel direttamente da Python, senza la necessità di installare Microsoft Excel.
Indice
- Perché usare Spire.XLS per convertire DataFrame Pandas in Excel
- Prerequisiti per convertire DataFrame Pandas in Excel
- Esportare un singolo DataFrame Pandas in Excel con formattazione
- Convertire più DataFrame Pandas in un unico file Excel
- Scrivere DataFrame Pandas in un file Excel esistente
- Personalizzazione avanzata per l'esportazione di DataFrame Pandas in Excel
- Conclusione
- Domande frequenti
Perché usare Spire.XLS per convertire DataFrame Pandas in Excel
Mentre Pandas fornisce funzionalità di esportazione Excel di base, Spire.XLS le estende offrendo il pieno controllo sulla creazione di file Excel. Invece di scrivere semplicemente dati grezzi, gli sviluppatori possono:
- Organizzare più DataFrame in fogli separati all'interno di un'unica cartella di lavoro.
- Personalizzare intestazioni, caratteri, colori e formattazione delle celle per produrre layout professionali.
- Adattare automaticamente le colonne e regolare l'altezza delle righe per una migliore leggibilità.
- Aggiungere grafici, formule e altre funzionalità di Excel direttamente da Python
Prerequisiti per convertire DataFrame Pandas in Excel
Prima di esportare un DataFrame Pandas in Excel, assicurati di aver installato le seguenti librerie richieste. Puoi farlo eseguendo il seguente comando nel terminale del tuo progetto:
pip install pandas spire.xls
Queste librerie ti consentono di scrivere DataFrame in Excel con fogli multipli, formattazione personalizzata, grafici accattivanti e layout strutturati.
Esportare un singolo DataFrame Pandas in Excel con formattazione
L'esportazione di un singolo DataFrame in un file Excel è lo scenario più comune. Utilizzando Spire.XLS, non solo puoi esportare il tuo DataFrame, ma anche formattare le intestazioni, stilizzare le celle e aggiungere grafici per rendere il tuo report professionale.
Vediamo questo processo passo dopo passo.
Passaggio 1: creare un DataFrame di esempio
Per prima cosa, dobbiamo creare un DataFrame. Qui abbiamo nomi di dipendenti, reparti e stipendi. Ovviamente, puoi sostituirlo con il tuo set di dati.
import pandas as pd
from spire.xls import *
# Create a simple DataFrame
df = pd.DataFrame({
'Employee': ['Alice', 'Bob', 'Charlie'],
'Department': ['HR', 'Finance', 'IT'],
'Salary': [5000, 6000, 7000]
})
Passaggio 2: creare una cartella di lavoro e accedere al primo foglio
Ora creeremo una nuova cartella di lavoro Excel e prepareremo il primo foglio di lavoro. Diamo un nome significativo in modo che sia facile da capire.
# Create a new workbook
workbook = Workbook()
sheet = workbook.Worksheets[0]
sheet.Name = "Employee Data"
Passaggio 3: scrivere le intestazioni delle colonne
Scriveremo le intestazioni nella prima riga, le metteremo in grassetto e aggiungeremo uno sfondo grigio chiaro, in modo che tutto appaia ordinato.
# Write column headers
for colIndex, colName in enumerate(df.columns, start=1):
cell = sheet.Range[1, colIndex]
cell.Text = colName
cell.Style.Font.IsBold = True # Make headers bold
cell.Style.Color = Color.get_LightGray() # Light gray background
Passaggio 4: scrivere le righe di dati
Successivamente, scriviamo ogni riga dal DataFrame. Per i numeri, utilizziamo la proprietà NumberValue in modo che Excel possa riconoscerli per calcoli e grafici.
# Write data rows
for rowIndex, row in enumerate(df.values, start=2):
for colIndex, value in enumerate(row, start=1):
cell = sheet.Range[rowIndex, colIndex]
if isinstance(value, (int, float)):
cell.NumberValue = value
else:
cell.Text = str(value)
Passaggio 5: applicare i bordi e adattare automaticamente le colonne
Per dare al tuo foglio Excel un aspetto curato e simile a una tabella, aggiungiamo i bordi e regoliamo automaticamente la larghezza delle colonne.
# Apply borders and auto-fit columns
usedRange = sheet.AllocatedRange
usedRange.BorderAround(LineStyleType.Thin, Color.get_Black()) # Outside borders
usedRange.BorderInside(LineStyleType.Thin, Color.get_Black()) # Inside borders
usedRange.AutoFitColumns()
Passaggio 6: aggiungere un grafico per visualizzare i dati
I grafici ti aiutano a comprendere rapidamente le tendenze. Qui, creeremo un istogramma che confronta gli stipendi.
# Add a chart
chart = sheet.Charts.Add()
chart.ChartType = ExcelChartType.ColumnClustered
chart.DataRange = sheet.Range["A1:C4"] # Data range for chart
chart.SeriesDataFromRange = False
chart.LeftColumn = 5 # Chart position
chart.TopRow = 1
chart.RightColumn = 10
chart.BottomRow = 16
chart.ChartTitle = "Employee Salary Comparison"
chart.ChartTitleArea.Font.Size = 12
chart.ChartTitleArea.Font.IsBold = True
Passaggio 7: salvare la cartella di lavoro
Infine, salva la cartella di lavoro nella posizione desiderata.
# Save the Excel file
workbook.SaveToFile("DataFrameWithChart.xlsx", ExcelVersion.Version2016)
workbook.Dispose()
Risultato:
Il file Excel XLSX generato dal DataFrame di Pandas ha questo aspetto:
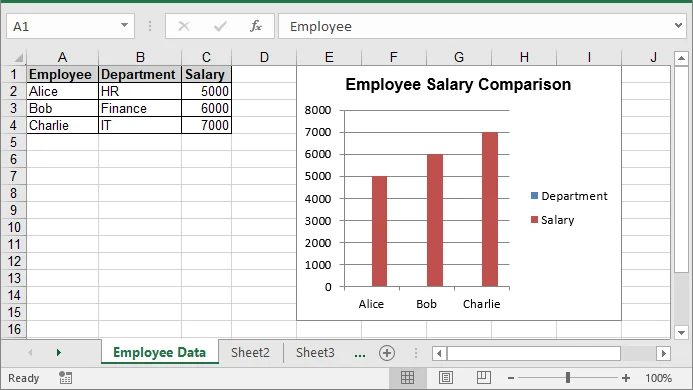
Una volta generato il file Excel, può essere ulteriormente elaborato, ad esempio convertito in PDF per una facile condivisione:
workbook.SaveToFile("ToPdf.pdf", FileFormat.PDF)
Per maggiori dettagli, consulta la guida sulla conversione di Excel in PDF in Python.
Convertire più DataFrame Pandas in un unico file Excel
Quando si creano report in Excel, spesso è necessario inserire più set di dati in fogli separati. Utilizzando Spire.XLS, ogni DataFrame di Pandas può essere scritto nel proprio foglio di lavoro, garantendo che i dati correlati siano organizzati in modo chiaro e facili da analizzare. I seguenti passaggi dimostrano questo flusso di lavoro.
Passaggio 1: creare più DataFrame di esempio
Prima di esportare, creiamo due DataFrame separati: uno per le informazioni sui dipendenti e un altro per i prodotti. Ogni DataFrame andrà nel proprio foglio Excel.
import pandas as pd
from spire.xls import *
# Sample DataFrames
df1 = pd.DataFrame({'Name': ['Alice', 'Bob'], 'Age': [25, 30]})
df2 = pd.DataFrame({'Product': ['Laptop', 'Phone'], 'Price': [1000, 500]})
# List of DataFrames with corresponding sheet names
dataframes = [
(df1, "Employees"),
(df2, "Products")
]
Qui, dataframes è un elenco di tuple che associa ogni DataFrame al nome del foglio in cui dovrebbe apparire.
Passaggio 2: creare una nuova cartella di lavoro
Successivamente, creiamo una nuova cartella di lavoro Excel per memorizzare tutti i DataFrame.
# Create a new workbook
workbook = Workbook()
Questo inizializza una cartella di lavoro vuota con tre fogli predefiniti. Li rinomineremo e popoleremo nel passaggio successivo.
Passaggio 3: scorrere ogni DataFrame e scrivere nel proprio foglio
Invece di scrivere ogni DataFrame individualmente, possiamo scorrere il nostro elenco ed elaborarli allo stesso modo. Ciò riduce il codice duplicato e semplifica la gestione di più set di dati.
for i, (df, sheet_name) in enumerate(dataframes):
# Get or create a sheet
if i < workbook.Worksheets.Count:
sheet = workbook.Worksheets[i]
else:
sheet = workbook.Worksheets.Add()
sheet.Name = sheet_name
# Write headers with bold font and background color
for colIndex, colName in enumerate(df.columns, start=1):
cell = sheet.Range[1, colIndex]
cell.Text = colName
cell.Style.Font.IsBold = True
cell.Style.Color = Color.get_LightGray()
sheet.Columns[colIndex - 1].ColumnWidth = 15 # Set fixed column width
# Write rows of data
for rowIndex, row in enumerate(df.values, start=2):
for colIndex, value in enumerate(row, start=1):
cell = sheet.Range[rowIndex, colIndex]
if isinstance(value, (int, float)):
cell.NumberValue = value
else:
cell.Text = str(value)
# Apply thin borders around the used range
usedRange = sheet.AllocatedRange
usedRange.BorderAround(LineStyleType.Thin, Color.get_Black()) # Outside borders
usedRange.BorderInside(LineStyleType.Thin, Color.get_Black()) # Inside borders
Utilizzando questo ciclo, possiamo facilmente aggiungere più DataFrame in futuro senza riscrivere lo stesso codice.
Passaggio 4: salvare la cartella di lavoro
Infine, salviamo il file Excel. Entrambi i set di dati sono ora ordinatamente organizzati in un unico file con fogli separati, intestazioni formattate e bordi appropriati.
# Save the workbook
workbook.SaveToFile("MultipleDataFrames.xlsx", ExcelVersion.Version2016)
workbook.Dispose()
Ora il tuo file Excel è pronto per essere condiviso o analizzato ulteriormente.
Risultato:

Il file MultipleDataFrames.xlsx contiene due fogli:
- Dipendenti (con nomi ed età)
- Prodotti (con dettagli e prezzi dei prodotti)
Questa organizzazione rende i file Excel multi-report puliti e facili da navigare.
Scrivere DataFrame Pandas in un file Excel esistente
In alcuni casi, invece di creare un nuovo file Excel, potrebbe essere necessario scrivere i DataFrame in una cartella di lavoro esistente. Ciò può essere facilmente ottenuto caricando la cartella di lavoro esistente, aggiungendo un nuovo foglio o accedendo al foglio desiderato e scrivendo i dati del DataFrame utilizzando la stessa logica.
Il codice seguente mostra come scrivere un DataFrame Pandas in un file Excel esistente:
import pandas as pd
from spire.xls import *
# Load an existing Excel file
workbook = Workbook()
workbook.LoadFromFile("MultipleDataFrames.xlsx")
# Create a new DataFrame to add
new_df = pd.DataFrame({
'Region': ['North', 'South', 'East', 'West'],
'Sales': [12000, 15000, 13000, 11000]
})
# Add a new worksheet for the new DataFrame
new_sheet = workbook.Worksheets.Add("Regional Sales")
# Write headers
for colIndex, colName in enumerate(new_df.columns, start=1):
cell = new_sheet.Range[1, colIndex]
cell.Text = colName
cell.Style.Font.IsBold = True
cell.Style.Color = Color.get_LightGray()
new_sheet.Columns[colIndex - 1].ColumnWidth = 15
# Write data rows
for rowIndex, row in enumerate(new_df.values, start=2):
for colIndex, value in enumerate(row, start=1):
cell = new_sheet.Range[rowIndex, colIndex]
if isinstance(value, (int, float)):
cell.NumberValue = value
else:
cell.Text = str(value)
# Save the changes
workbook.SaveToFile("DataFrameToExistingWorkbook.xlsx", ExcelVersion.Version2016)
workbook.Dispose()
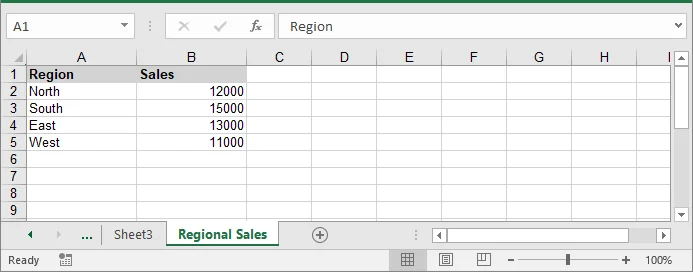
Personalizzazione avanzata per l'esportazione di DataFrame Pandas in Excel
Oltre alle esportazioni di base, i DataFrame di Pandas possono essere personalizzati in Excel per soddisfare requisiti di reporting specifici. Opzioni avanzate, come la selezione di colonne specifiche e l'inclusione o l'esclusione dell'indice, consentono di creare file Excel più puliti, leggibili e professionali. Gli esempi seguenti dimostrano come applicare queste personalizzazioni.
1. Seleziona colonne specifiche
A volte potresti non aver bisogno di esportare tutte le colonne da un DataFrame. Selezionando solo le colonne pertinenti, puoi mantenere i tuoi report Excel concisi e mirati. Il codice seguente dimostra come scorrere le colonne scelte durante la scrittura di intestazioni e righe:
import pandas as pd
from spire.xls import *
# Create a DataFrame
df = pd.DataFrame({
'Employee': ['Alice', 'Bob', 'Charlie'],
'Department': ['HR', 'Finance', 'IT'],
'Salary': [5000, 6000, 7000]
})
# Set the columns to export
columns_to_export = ['Employee', 'Department']
# Create a new workbook and access the first sheet
workbook = Workbook()
sheet = workbook.Worksheets[0]
# Write headers
for colIndex, colName in enumerate(columns_to_export, start=1):
sheet.Range[1, colIndex].Text = colName
# Write rows
for rowIndex, row in enumerate(df[columns_to_export].values, start=2):
for colIndex, value in enumerate(row, start=1):
sheet.Range[rowIndex, colIndex].Text = value
# Save the Excel file
workbook.SaveToFile("select_columns.xlsx")
workbook.Dispose()
2. Includi o escludi indice
Per impostazione predefinita, l'indice del DataFrame non è incluso nell'esportazione. Se il tuo report richiede identificatori di riga o indici numerici, puoi aggiungerli manualmente. Questo frammento di codice mostra come includere l'indice insieme alle colonne selezionate:
# Write header for index
sheet.Range[1, 1].Text = "Index"
# Write index values (numeric)
for rowIndex, idx in enumerate(df.index, start=2):
sheet.Range[rowIndex, 1].NumberValue = idx # Use NumberValue for numeric
# Write headers for other columns
for colIndex, colName in enumerate(columns_to_export, start=2):
sheet.Range[1, colIndex].Text = colName
# Write the data rows
for rowIndex, row in enumerate(df[columns_to_export].values, start=2):
for colIndex, value in enumerate(row, start=2):
if isinstance(value, (int, float)):
sheet.Range[rowIndex, colIndex].NumberValue = value
else:
sheet.Range[rowIndex, colIndex].Text = str(value)
# Save the workbook
workbook.SaveToFile("include_index.xlsx", ExcelVersion.Version2016)
workbook.Dispose()
Conclusione
Esportare un DataFrame Pandas in Excel è semplice, ma la produzione di report professionali e ben formattati richiede un controllo aggiuntivo. Utilizzando Pandas per la preparazione dei dati e Spire.XLS per Python per creare e formattare file Excel, è possibile generare cartelle di lavoro strutturate, leggibili e visivamente organizzate. Questo approccio funziona sia per singoli DataFrame che per più set di dati, rendendo facile la creazione di report Excel pronti per l'analisi, la condivisione o ulteriori manipolazioni.
Domande frequenti
D1: Come posso esportare un DataFrame Pandas in Excel in Python?
R1: Puoi usare librerie come Spire.XLS per scrivere un DataFrame in un file Excel. Ciò ti consente di trasferire dati tabulari da Python a Excel mantenendo il controllo sulla formattazione e sul layout.
D2: Posso esportare più di un DataFrame in un singolo file Excel?
R2: Sì. È possibile scrivere più DataFrame in fogli separati all'interno della stessa cartella di lavoro. Ciò aiuta a mantenere i set di dati correlati organizzati in un unico file.
D3: Come aggiungo intestazioni e formatto le celle in Excel da un DataFrame?
R3: Le intestazioni possono essere rese in grassetto, colorate o avere larghezze fisse. I valori numerici possono essere memorizzati come numeri e il testo come stringhe. La formattazione migliora la leggibilità dei report.
D4: È possibile includere grafici nel file Excel esportato?
R4: Sì. Grafici come istogrammi o grafici a linee possono essere aggiunti in base ai dati del tuo DataFrame per aiutare a visualizzare tendenze o confronti.
D5: Ho bisogno di Microsoft Excel installato per esportare i DataFrame?
R5: Non necessariamente. Alcune librerie, tra cui Spire.XLS, possono creare e formattare file Excel interamente in Python senza fare affidamento sull'installazione di Excel.