개요
HTML 표를 Excel로 추출하는 것은 구조화된 웹 데이터를 자주 다루는 데이터 분석가, 연구원, 개발자 및 비즈니스 전문가에게 일반적인 요구 사항입니다. HTML 표에는 재무 보고서, 제품 카탈로그, 연구 결과 또는 성과 통계와 같은 귀중한 정보가 포함되어 있는 경우가 많습니다. 그러나 해당 데이터를 깨끗하고 사용 가능한 형식으로 Excel로 전송하는 것은 까다로울 수 있으며, 특히 병합된 셀(rowspan, colspan), 중첩된 헤더 또는 대규모 데이터 세트가 포함된 복잡한 표를 처리할 때 그렇습니다.
다행히도 HTML 표를 Excel 파일로 변환하는 여러 가지 방법이 있습니다. 이러한 방법은 작은 작업에 적합한 빠른 수동 복사-붙여넣기 작업부터 대규모 또는 반복적인 작업을 위한 VBA 또는 Python을 사용한 완전 자동화된 스크립트에 이르기까지 다양합니다.
이 기사에서는 HTML 표를 Excel로 추출하는 네 가지 효과적인 방법을 살펴보겠습니다.
마지막으로, 사용 사례에 따라 최상의 방법을 선택하는 데 도움이 되도록 이러한 접근 방식을 요약 표에서 비교할 것입니다.
수동 복사-붙여넣기 (가장 간단한 방법)
작고 일회성인 추출의 경우 가장 간단한 옵션은 브라우저에서 Excel로 직접 복사하여 붙여넣는 것입니다.

단계:
- 브라우저(예: Chrome, Edge 또는 Firefox)에서 HTML 페이지를 엽니다.
- 추출하려는 표를 강조 표시합니다.
- Ctrl+C(또는 마우스 오른쪽 버튼 클릭 → 복사)로 복사합니다.
- Excel을 열고 Ctrl+V로 붙여넣습니다.
장점:
- 매우 간단함—설정이나 코딩이 필요 없음.
- 작고 깔끔한 표에 즉시 작동함.
단점:
- 수동 프로세스—잦거나 큰 데이터 세트에는 지루하고 비효율적임.
- 병합된 셀이나 서식을 항상 유지하지는 않음.
- 동적(JavaScript 렌더링) 표를 안정적으로 처리할 수 없음.
사용 시기: 작은 표, 임시 데이터 수집 또는 빠른 테스트에 가장 적합합니다.
Excel의 내장된 "웹에서" 기능
Excel에는 사용자가 웹 페이지에서 직접 표를 가져올 수 있는 강력한 "데이터 가져오기 및 변환" 도구(이전의 파워 쿼리)가 포함되어 있습니다.
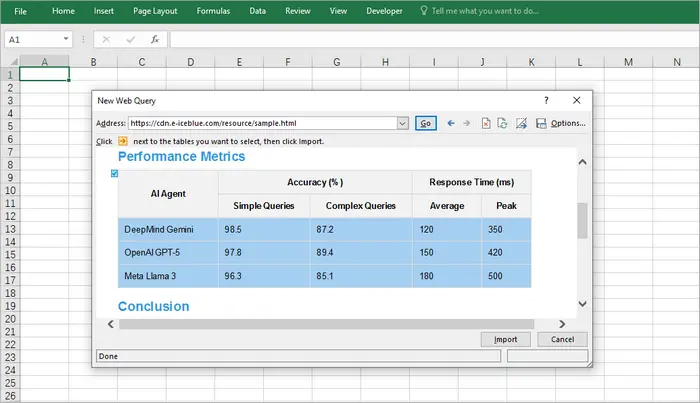
단계:
- Excel을 엽니다.
- 데이터 → 웹에서로 이동합니다.
- 표가 포함된 웹 페이지의 URL을 입력합니다.
- Excel이 감지된 표를 표시합니다. 원하는 표를 선택합니다.
- 워크시트에 데이터를 로드합니다.
장점:
- Excel에 직접 통합—외부 도구 필요 없음.
- 구조화된 HTML 표에 잘 작동함.
- 새로 고침 지원—동일한 소스에서 업데이트된 데이터를 다시 가져올 수 있음.
단점:
- 동적 또는 JavaScript 렌더링 콘텐츠에 대한 지원 제한.
- 때때로 복잡한 표를 감지하지 못함.
- 인터넷 액세스 및 유효한 URL 필요(수동으로 가져오지 않는 한 로컬 HTML 파일에는 해당되지 않음).
사용 시기: 정기적으로 업데이트되는 웹사이트에서 실시간 구조화된 데이터를 가져오는 분석가에게 가장 적합합니다.
VBA 매크로 (Excel 자동화)
HTML 표를 자주 추출하고 더 많은 제어를 원하는 사용자에게 VBA(Visual Basic for Applications)는 훌륭한 솔루션을 제공합니다. VBA를 사용하면 URL에서 표를 가져와 병합된 셀을 올바르게 처리할 수 있으며, 이는 기본 복사-붙여넣기로는 처리할 수 없습니다.
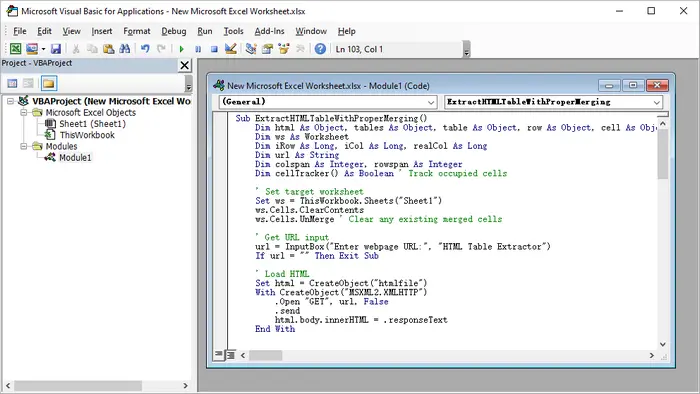
단계:
- Microsoft Excel을 시작합니다.
- Alt + F11을 눌러 VBA 편집기를 엽니다.
- 프로젝트 탐색기에서 마우스 오른쪽 버튼 클릭 → 삽입 → 모듈.
- 제공된 VBA 코드를 붙여넣습니다.
- VBA 편집기를 닫습니다.
- Alt + F8을 누르고 매크로 이름을 선택한 다음 실행을 클릭합니다.
샘플 VBA 코드:
Sub ExtractHTMLTableWithProperMerging()
Dim html As Object, tables As Object, table As Object, row As Object, cell As Object
Dim ws As Worksheet
Dim iRow As Long, iCol As Long, realCol As Long
Dim url As String
Dim colspan As Integer, rowspan As Integer
Dim cellTracker() As Boolean ' 차지된 셀 추적
' 대상 워크시트 설정
Set ws = ThisWorkbook.Sheets("Sheet1")
ws.Cells.ClearContents
ws.Cells.UnMerge ' 기존 병합된 셀 모두 지우기
' URL 입력 받기
url = InputBox("웹 페이지 URL 입력:", "HTML 표 추출기")
If url = "" Then Exit Sub
' HTML 로드
Set html = CreateObject("htmlfile")
With CreateObject("MSXML2.XMLHTTP")
.Open "GET", url, False
.send
html.body.innerHTML = .responseText
End With
' 첫 번째 표 가져오기 (필요시 인덱스 변경)
Set tables = html.getElementsByTagName("table")
If tables.Length = 0 Then
MsgBox "표를 찾을 수 없습니다!", vbExclamation
Exit Sub
End If
Set table = tables(0)
' 셀 추적기 배열 초기화
Dim maxRows As Long, maxCols As Long
maxRows = table.Rows.Length
maxCols = 0
For Each row In table.Rows
If row.Cells.Length > maxCols Then maxCols = row.Cells.Length
Next
ReDim cellTracker(1 To maxRows, 1 To maxCols)
' 표 처리
iRow = 1
For Each row In table.Rows
realCol = 1 ' rowspan을 고려한 실제 열 위치 추적
' 이 행에서 첫 번째 사용 가능한 열 찾기
While realCol <= maxCols And cellTracker(iRow, realCol)
realCol = realCol + 1
Wend
iCol = 1 ' 논리적 열 위치 추적
For Each cell In row.Cells
' 병합 속성 가져오기
colspan = 1
rowspan = 1
On Error Resume Next ' 속성이 없는 경우 대비
colspan = cell.colspan
rowspan = cell.rowspan
On Error GoTo 0
' 이미 차지된 셀 건너뛰기 (위의 rowspan으로 인해)
While realCol <= maxCols And cellTracker(iRow, realCol)
realCol = realCol + 1
Wend
If realCol > maxCols Then Exit For
' 값 쓰기
ws.Cells(iRow, realCol).Value = cell.innerText
' 이 셀이 차지할 모든 셀 표시
Dim r As Long, c As Long
For r = iRow To iRow + rowspan - 1
For c = realCol To realCol + colspan - 1
If r <= maxRows And c <= maxCols Then
cellTracker(r, c) = True
End If
Next c
Next r
' 필요시 셀 병합
If colspan > 1 Or rowspan > 1 Then
With ws.Range(ws.Cells(iRow, realCol), ws.Cells(iRow + rowspan - 1, realCol + colspan - 1))
.Merge
.HorizontalAlignment = xlCenter
.VerticalAlignment = xlCenter
End With
End If
realCol = realCol + colspan
iCol = iCol + 1
Next cell
iRow = iRow + 1
Next row
' 서식 지정
ws.UsedRange.Columns.AutoFit
ws.UsedRange.Borders.Weight = xlThin
MsgBox "표가 올바른 병합으로 추출되었습니다!", vbInformation
End Sub
장점:
- 전적으로 Excel 내에서 실행—외부 도구 필요 없음.
- 병합된 셀이 있는 복잡한 표 처리.
- 여러 표 또는 예약된 실행에 맞게 사용자 지정 가능.
단점:
- 설정에 VBA 지식 필요.
- 추가 단계 없이 JavaScript 렌더링 데이터 처리 불가.
- Excel 데스크톱에서만 작동(Excel 온라인에서는 작동 안 함).
사용 시기: 유사한 표를 정기적으로 추출하고 원클릭 솔루션을 원하는 사용자에게 적합합니다.
Python (BeautifulSoup & Spire.XLS)
개발자나 고급 사용자에게 Python은 가장 유연하고 확장 가능하며 자동화된 솔루션을 제공합니다. HTML 파싱을 위한 BeautifulSoup 및 Excel 조작을 위한 Spire.XLS for Python과 같은 라이브러리를 사용하여 프로그래밍 방식으로 표를 가져오고, 정리하고, 완전한 제어로 내보낼 수 있습니다.
단계:
- Python 설치(3.8+ 권장).
- IDE(예: VS Code, PyCharm)에서 새 프로젝트 생성.
- 의존성 설치:
pip install requests beautifulsoup4 spire.xls
- 다음 스크립트를 복사하여 실행합니다.
Python 코드:
import requests
from bs4 import BeautifulSoup
from spire.xls import Workbook, ExcelVersion
# URL에서 HTML 문자열 가져오기
response = requests.get("https://cdn.e-iceblue.com/resource/sample.html")
html = response.text
# HTML 파싱
soup = BeautifulSoup(html, "html.parser")
table = soup.find("table") # 첫 번째 표 가져오기
# Excel 초기화
workbook = Workbook()
sheet = workbook.Worksheets[0]
# 나중에 건너뛸 병합된 셀 추적
skip_cells = set()
# HTML 행 및 셀 반복
for row_idx, row in enumerate(table.find_all("tr")):
col_idx = 1 # Excel 열은 1부터 시작
for cell in row.find_all(["th", "td"]):
# 이미 병합된 셀 건너뛰기
while (row_idx + 1, col_idx) in skip_cells:
col_idx += 1
# colspan/rowspan 값 가져오기 (없는 경우 기본값 1)
colspan = int(cell.get("colspan", 1))
rowspan = int(cell.get("rowspan", 1))
# Excel에 셀 값 쓰기
sheet.Range[row_idx + 1, col_idx].Text = cell.get_text(strip=True)
# colspan/rowspan > 1인 경우 셀 병합
if colspan > 1 or rowspan > 1:
end_row = row_idx + rowspan
end_col = col_idx + colspan - 1
sheet.Range[row_idx + 1, col_idx, end_row, end_col].Merge()
# 건너뛸 병합된 셀 표시
for r in range(row_idx + 1, end_row + 1):
for c in range(col_idx, end_col + 1):
if r != row_idx + 1 or c != col_idx: # 주 셀 건너뛰기
skip_cells.add((r, c))
col_idx += colspan
# 사용된 모든 범위의 열 너비 자동 맞춤
sheet.AllocatedRange.AutoFitColumns()
# Excel에 저장
workbook.SaveToFile("TableToExcel.xlsx", ExcelVersion.Version2016)
workbook.Dispose()
장점:
- 완전한 제어—데이터를 파싱, 정리 및 변환할 수 있음.
- 병합된 셀을 올바르게 처리함.
- 여러 표나 웹사이트로 쉽게 확장 가능.
- 예약된 작업이나 일괄 작업에 대해 자동화 가능.
단점:
- Python 설치 및 기본 프로그래밍 지식 필요.
- 내장된 Excel 솔루션보다 설정이 더 많음.
- 외부 의존성(BeautifulSoup, Spire.XLS).
사용 시기: 크거나 복잡한 표를 정기적으로 추출하는 개발자나 고급 사용자에게 가장 적합합니다.
출력:
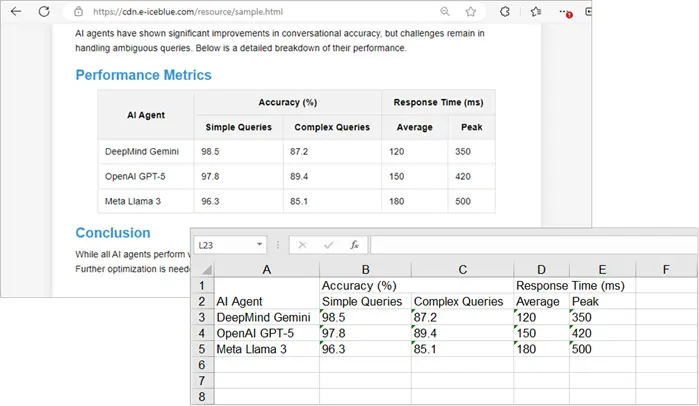
Python에서 생성된 Excel 워크시트의 시각적 매력을 향상시키려면 Excel의 셀 또는 워크시트에 스타일을 적용할 수 있습니다.
요약 표: 사용 사례별 최적의 방법
| 방법 | 가장 적합한 경우 | 장점 | 단점 | 자동화? |
|---|---|---|---|---|
| 수동 복사-붙여넣기 | 빠른, 일회성 사용 | 빠르고 설정 없음 | 자동화 불가, 서식 문제 | ❌아니요 |
| Excel 웹에서 | 실시간 구조화된 데이터 | 통합, 새로 고침 지원 | 동적 표에 제한적 | ❌아니요 |
| VBA 매크로 | Excel에서 반복 작업 | 추출 자동화, 병합 처리 | VBA 지식 필요 | ✅예 |
| Python (BeautifulSoup + Spire.XLS) | 개발자, 크거나 복잡한 표 | 완전한 제어, 확장 가능, 자동화 가능 | 코딩 및 의존성 필요 | ✅예 |
마지막 생각
선택하는 방법은 주로 사용 사례에 따라 다릅니다.
- 가끔 작은 표만 가져오면 되는 경우 수동 복사-붙여넣기가 가장 빠릅니다.
- 자주 업데이트되는 웹 페이지에서 구조화된 데이터를 가져오려면 Excel의 웹에서 기능이 편리합니다.
- 매일 Excel에서 작업하고 자동화를 원하는 비즈니스 사용자의 경우 VBA 매크로가 이상적입니다.
- 여러 데이터 세트나 복잡한 HTML 구조를 처리하는 개발자의 경우 BeautifulSoup와 Spire.XLS를 사용하는 Python이 가장 큰 유연성과 확장성을 제공합니다.
이러한 방법을 워크플로와 결합하면 수동 작업 시간을 절약하고 Excel로 더 깨끗하고 신뢰할 수 있는 데이터를 추출할 수 있습니다.