Muitos relatórios financeiros, documentos de pesquisa, documentos legais ou faturas são frequentemente distribuídos em formato PDF. A leitura de arquivos PDF permite extrair informações, analisar conteúdo e executar tarefas de processamento de dados, como extração de texto, pesquisa por palavras-chave, classificação de documentos e mineração de dados.
Ao usar C# para ler PDF, você pode automatizar a tarefa repetitiva para realizar a recuperação eficiente de informações específicas de uma grande coleção de arquivos PDF. Isso é valioso para aplicações que exigem pesquisas em arquivos extensos, bibliotecas digitais ou repositórios de documentos. Este artigo fornecerá os seguintes exemplos para mostrar como leia o arquivo PDF em C#.
- Ler texto de uma página PDF em C#
- Ler texto de uma área de página PDF em C#
- Leia PDF sem preservar o layout do texto em C#
- Extraia imagens e tabelas em PDF em C#
Biblioteca de leitor de PDF C#
A biblioteca Spire.PDF for .NET pode servir como uma biblioteca de leitura de PDF que permite aos desenvolvedores integrar recursos de leitura de PDF em seus aplicativos. Ele fornece funções e APIs para análise, renderização e processamento de arquivos PDF em aplicativos .NET.
Você também pode baixe o leitor de PDF C# para adicionar manualmente os arquivos DLL como referências em seu projeto .NET ou instalá-los diretamente por meio do NuGet.
PM> Install-Package Spire.PDF
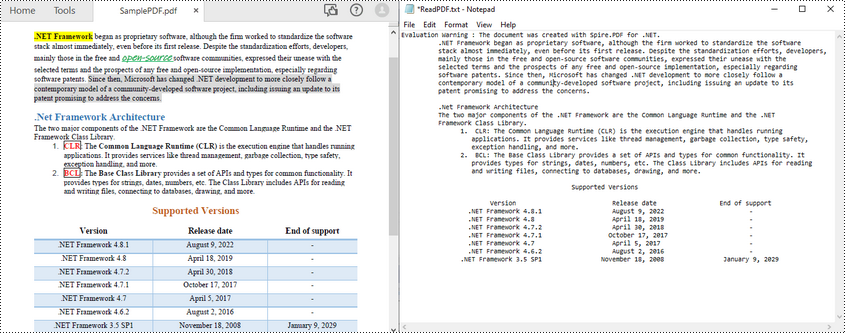
Ler texto de uma página PDF em C#
O Spire.PDF for .NET facilita a leitura de texto PDF em C# por meio da classe PdfTextExtractor. A seguir estão as etapas para ler todo o texto de uma página PDF específica.
- Crie um objeto PdfDocument.
- Carregue um arquivo PDF usando o método PdfDocument.LoadFromFile().
- Obtenha a página específica através da propriedade PdfDocument.Pages[index].
- Crie um objeto PdfTextExtractor.
- Crie um objeto PdfTextExtractOptions e defina a propriedade IsExtractAllText como true.
- Extraia o texto da página selecionada usando o método PdfTextExtractor.ExtractText().
- Escreva o texto extraído em um arquivo TXT.
O exemplo de código a seguir mostra como usar C# para ler texto PDF de uma página especificada.
- C#
using System;
using System.IO;
using Spire.Pdf;
using Spire.Pdf.Texts;
namespace ExtractTextFromPage
{
class Program
{
static void Main(string[] args)
{
//Create a PdfDocument object
PdfDocument doc = new PdfDocument();
//Load a PDF file
doc.LoadFromFile("TestPDF.pdf");
//Get the first page
PdfPageBase page = doc.Pages[0];
//Create a PdfTextExtractot object
PdfTextExtractor textExtractor = new PdfTextExtractor(page);
//Create a PdfTextExtractOptions object
PdfTextExtractOptions extractOptions = new PdfTextExtractOptions();
//Set isExtractAllText to true
extractOptions.IsExtractAllText = true;
//Read text from the PDF page
string text = textExtractor.ExtractText(extractOptions);
//Write to a txt file
File.WriteAllText("ReadPDF.txt", text);
}
}
}
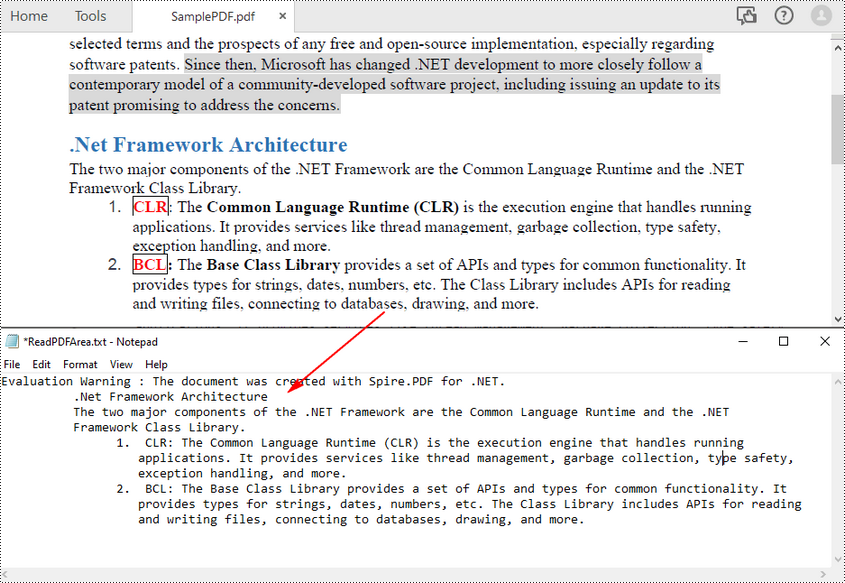
Ler texto de uma área de página PDF em C#
Para ler texto PDF de uma área de página especificada em PDF, você pode primeiro definir uma área retangular e depois chamar o método setExtractArea() da classe PdfTextExtractOptions para extrair o texto dela. A seguir estão as etapas para extrair texto PDF de uma área retangular de uma página.
- Crie um objeto PdfDocument.
- Carregue um arquivo PDF usando o método PdfDocument.LoadFromFile().
- Obtenha a página específica através da propriedade PdfDocument.Pages[index].
- Crie um objeto PdfTextExtractor.
- Crie um objeto PdfTextExtractOptions e especifique a área do retângulo por meio da propriedade ExtractArea dele.
- Extraia o texto do retângulo usando o método PdfTextExtractor.ExtractText().
- Escreva o texto extraído em um arquivo TXT.
O exemplo de código a seguir mostra como usar C# para ler texto PDF de uma área de página especificada.
- C#
using Spire.Pdf;
using Spire.Pdf.Texts;
using System.IO;
using System.Drawing;
namespace ExtractTextFromRectangleArea
{
class Program
{
static void Main(string[] args)
{
//Create a PdfDocument object
PdfDocument doc = new PdfDocument();
//Load a PDF file
doc.LoadFromFile("TestPDF.pdf");
//Get the first page
PdfPageBase page = doc.Pages[0];
//Create a PdfTextExtractot object
PdfTextExtractor textExtractor = new PdfTextExtractor(page);
//Create a PdfTextExtractOptions object
PdfTextExtractOptions extractOptions = new PdfTextExtractOptions();
//Specify a rectangle area
extractOptions.ExtractArea = new RectangleF(0, 180, 800, 160);
//Read PDF text from the rectangle
string text = textExtractor.ExtractText(extractOptions);
//Write to a txt file
File.WriteAllText("ReadPDFArea.txt", text);
}
}
}
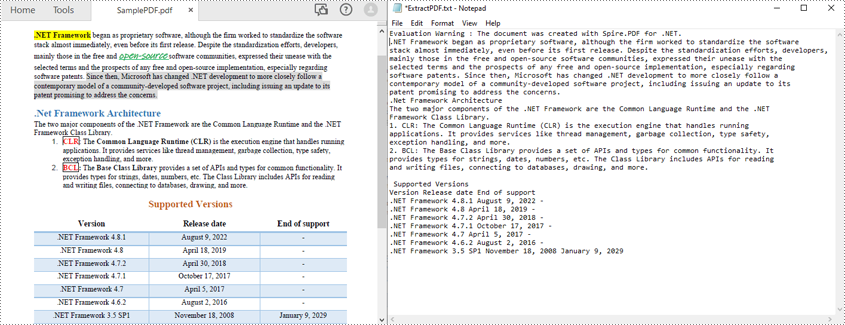
Leia PDF sem preservar o layout do texto em C#
Os métodos acima leem o texto do PDF linha por linha. Você também pode ler texto PDF de forma simples, sem manter seu layout, usando a estratégia SimpleExtraction. Ele rastreia a posição Y atual de cada string e insere uma quebra de linha na saída se a posição Y tiver mudado. A seguir estão as etapas para ler texto PDF de forma simples.
- Crie um objeto PdfDocument.
- Carregue um arquivo PDF usando o método PdfDocument.LoadFromFile().
- Obtenha a página específica através da propriedade PdfDocument.Pages[index].
- Crie um objeto PdfTextExtractor.
- Crie um objeto PdfTextExtractOptions e defina a propriedade IsSimpleExtraction como true.
- Extraia o texto da página selecionada usando o método PdfTextExtractor.ExtractText().
- Escreva o texto extraído em um arquivo TXT.
O exemplo de código a seguir mostra como usar C# para ler texto PDF sem preservar o layout do texto.
- C#
using System.IO;
using Spire.Pdf;
using Spire.Pdf.Texts;
namespace SimpleExtraction
{
class Program
{
static void Main(string[] args)
{
//Create a PdfDocument object
PdfDocument doc = new PdfDocument();
//Load a PDF file
doc.LoadFromFile("TestPDF.pdf");
//Get the first page
PdfPageBase page = doc.Pages[0];
//Create a PdfTextExtractor object
PdfTextExtractor textExtractor = new PdfTextExtractor(page);
//Create a PdfTextExtractOptions object
PdfTextExtractOptions extractOptions = new PdfTextExtractOptions();
//Set IsSimpleExtraction to true to
extractOptions.IsSimpleExtraction = true;
//Read text from the PDF page
string text = textExtractor.ExtractText(extractOptions);
//Write to a txt file
File.WriteAllText("ExtractPDF.txt", text);
}
}
}
Extraia imagens e tabelas em PDF em C#
Além de ler texto PDF em C#, a biblioteca Spire.PDF for .NET também permite extrair imagens de PDF ou ler apenas os dados da tabela em um arquivo PDF. Os links a seguir irão direcioná-lo para os tutoriais oficiais relevantes:
- Extraia imagens de PDF em C#
- Extraia dados de tabela de PDF em C#
- Extraia tabelas de PDF para Excel em C#
Conclusão
Este artigo apresentou várias maneiras de ler arquivos PDF em C#. Você pode aprender com os exemplos dados como ler texto PDF de uma página específica, de uma área retangular especificada ou ler arquivos PDF sem preservar o layout do texto. Além disso, a extração de imagens ou tabelas em um arquivo PDF também pode ser obtida com a biblioteca Spire.PDF for .NET.
Explore mais recursos de processamento e conversão de PDF da biblioteca .NET PDF usando a documentação. Se ocorrer algum problema durante o teste, sinta-se à vontade para entrar em contato com a equipe de suporte técnico por e-mail ou fórum.