PDF-файлы — популярный выбор для совместного использования и распространения документов, но извлечение и повторное использование PDF-содержимого может оказаться довольно сложной задачей. К счастью, преобразование PDF-файлов в HTML с помощью Python предлагает отличное решение для поиска и повторного использования информации в формате PDF, которое повышает доступность, возможность поиска и адаптируемость. Кроме того, формат HTML позволяет поисковым системам индексировать контент, повышая вероятность его обнаружения в Интернете. Более того, благодаря гибкости и простоте использования Python, его могут использовать как новички, так и опытные разработчики. Python для преобразования PDF в HTML легко и эффективно.

Эта статья посвящена тому, как конвертировать PDF в HTML в программах Python. В основном он включает в себя следующие темы:
- Обзор преобразования PDF в HTML с помощью Python
- Преобразование PDF в один HTML-файл с помощью кода Python
- Преобразование PDF в HTML с разделением изображений с помощью Python
- Преобразование PDF в несколько файлов HTML с помощью Python
- Бесплатная лицензия и техническая поддержка
Обзор преобразования PDF в HTML с помощью Python
Обширные API-интерфейсы Python обеспечивают удобство выполнения различных операций обработки PDF-документов. Spire.PDF for Python — это один из мощных API, который может выполнять различные операции с документами PDF, включая преобразование, редактирование и объединение PDF-документов. Преобразование PDF в HTML с помощью Python можно легко реализовать с помощью этого API.
В Spire.PDF for Python класс PdfDocument представляет документ PDF. Мы можем загрузить PDF-файл с помощью метода LoadFromFile() в этом классе и сохранить документ в других форматах, например HTML, чтобы добиться простого преобразования PDF в HTML.
Кроме того, этот API также предоставляет метод SetConvertHtmlOptions() в свойстве PdfDocument.ConversionOptions для установки параметров внедрения изображения во время преобразования. Ниже приведены параметры, которые можно передать этому методу, чтобы установить максимальное количество страниц, параметр внедрения SVG, параметр внедрения изображения и параметр качества SVG:
- useEmbeddedSvg (bool): если установлено значение True, разрешено встраивание SVG в преобразованный HTML-файл. Результирующий HTML-файл будет включать все элементы PDF-документа, включая изображения, в один HTML-файл.
- useEmbeddedImg (bool): если установлено значение True, разрешено встраивание изображений в преобразованный HTML-файл. Этот параметр работает только в том случае, если для параметра useEmbeddedSvg установлено значение False.
- maxPageOneFile (int): устанавливает максимальное количество страниц, включаемых в один HTML-файл. Если в PDF-файле больше страниц, чем указано, будет создано несколько файлов HTML, каждый из которых содержит подмножество страниц.
- useHighQualityEmbeddedSvg (bool): если установлено значение True, гарантирует использование высококачественных версий встроенных изображений SVG в процессе преобразования HTML.
Типичный рабочий процесс преобразования PDF в HTML в Python с использованием Spire.PDF for Python:
- Создайте объект класса PdfDocument и загрузите PDF-документ с помощью метода PdfDocument.LoadFromFile(string fileName).
- Установите параметры преобразования, используя метод PdfDocument.ConversionOptions.SetConvertHtmlOptions().
- Преобразуйте документ в формат HTML и сохраните его с помощью метода PdfDocument.SaveToFile(string fileName, FileFormat.HTML).
Пользователи могут загрузите Spire.PDF for Python и импортируйте его в свои проекты или установите с помощью PyPI:
pip install Spire.PDF
Преобразование PDF в один HTML-файл с помощью кода Python
В этом примере кода показано, как преобразовать PDF в HTML с помощью Python напрямую, без установки каких-либо параметров преобразования. В этом случае нам нужно только загрузить PDF-файл с помощью метода LoadFromFile и сохранить его как HTML-файл с помощью метода SaveToFile. Преобразованный HTML-файл будет представлять собой один HTML-файл со встроенными в него изображениями и другими элементами.
Пример кода:
- Python
from spire.pdf.common import *
from spire.pdf import *
# Craete an object of PdfDocument class
doc = PdfDocument()
# Load a PDF document
doc.LoadFromFile("G:/Documents/ARCHITECTURE.pdf")
# Convert the document to HTML
doc.SaveToFile("output/HTML/PDFToHTML.html", FileFormat.HTML)
doc.Close()
Результат преобразования:
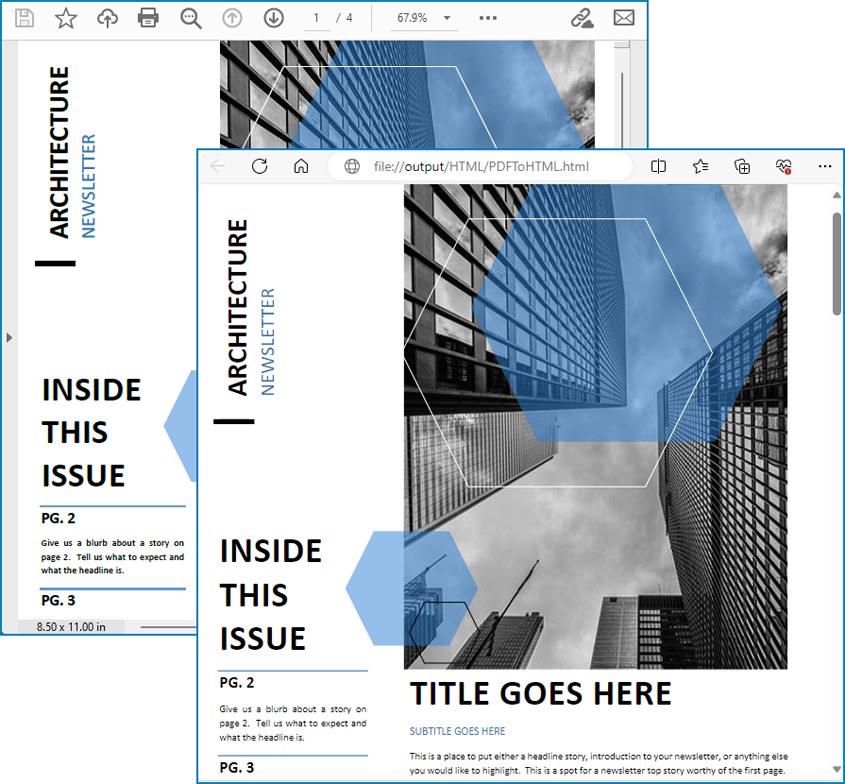
Преобразование PDF в HTML с разделением изображений с помощью Python
Установив для параметра useEmbeddedSvg значение False, мы можем преобразовать документ PDF в файл HTML с изображениями и файлами CSS, отделенными от него и сохраненными в папке. Это делает удобным дальнейшее редактирование преобразованного HTML-файла и выполнение дополнительных операций над изображениями.
Пример кода:
- Python
from spire.pdf.common import *
from spire.pdf import *
# Craete an object of PdfDocument class
doc = PdfDocument()
# Load a PDF document
doc.LoadFromFile("ARCHITECTURE.pdf")
# Disable embedding SVG
doc.ConvertOptions.SetPdfToHtmlOptions(False)
# Convert the document to HTML
doc.SaveToFile("output/HTML/PDFToHTMLWithoutEmbeddingSVG.html", FileFormat.HTML)
doc.Close()
Результат преобразования:
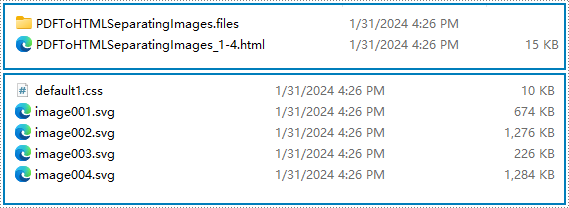
Преобразование PDF в несколько файлов HTML с помощью Python
При условии, что для параметра useEmbeddedSvg установлено значение False, метод SetPdfToHtmlOptions позволяет использовать параметр maxPageOneFile (int) для определения максимального количества страниц, включенных в каждый преобразованный HTML-файл. Эта функция позволяет Разделение PDF-документа в процессе конверсии. Например, установка для параметра значения 1 приведет к преобразованию каждой страницы в отдельный HTML-файл.
Пример кода:
- Python
from spire.pdf.common import *
from spire.pdf import *
# Craete an object of PdfDocument class
doc = PdfDocument()
# Load a PDF document
doc.LoadFromFile("ARCHITECTURE.pdf")
# Disable embedding SVG
doc.ConvertOptions.SetPdfToHtmlOptions(False, False, 1, False)
# Convert the document to HTML
doc.SaveToFile("output/HTML/PDFToHTMLLimitingPage.html", FileFormat.HTML)
doc.Close()
Результат преобразования:
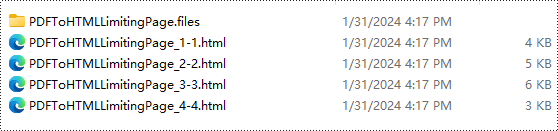
Бесплатная лицензия и техническая поддержка
Spire.PDF for Python предлагает пользователям бесплатную пробную лицензию для всех пользователей, включая корпоративных и индивидуальных пользователей. Подать заявку на временную лицензию использовать этот API Python для преобразования документов PDF в файлы HTML, удаляя любые ограничения использования или водяные знаки.
По любым проблемам, возникающим во время преобразования PDF в HTML с помощью этого API, пользователи могут обратиться за технической поддержкой на форум Spire.PDF.
Заключение
В этой статье показано, как конвертировать PDF в HTML с помощью Python, и представлены различные варианты преобразования, такие как преобразование в один файл HTML, отделение файлов HTML от изображений и разделение PDF-документа во время преобразования. Благодаря Spire.PDF for Python пользователи получают доступ к простому и эффективному методу преобразования Python в PDF в HTML, поддерживающему гибкие возможности настройки.