PDF parsing in Java is commonly required when applications need to extract usable information from PDF files, rather than simply render them for display. Typical use cases include document indexing, automated report processing, invoice analysis, and data ingestion pipelines.
Unlike structured formats such as JSON or XML, PDFs are designed for visual fidelity. Text, tables, images, and other elements are stored as positioned drawing instructions instead of logical data structures. As a result, effective PDF parsing in Java depends on understanding how content is represented internally and how Java-based libraries expose that content through their APIs.
This article focuses on practical PDF parsing operations in real Java applications using Spire.PDF for Java, with each section covering a specific extraction task—text, tables, images, or metadata—rather than presenting PDF parsing as a single linear workflow.
Table of Contents
- Understanding PDF Parsing from an Implementation Perspective
- A Practical PDF Parsing Workflow in Java
- Loading and Validating PDF Documents in Java
- Parsing Text from PDF Pages Using Java
- Parsing Tables from PDF Pages Using Java
- Parsing Images from PDF Pages Using Java
- Parsing PDF Metadata Using Java
- Implementation Considerations for PDF Parsing in Java
- Frequently Asked Questions
Understanding PDF Parsing from an Implementation Perspective
From an implementation perspective, PDF parsing in Java is not a single operation, but a set of extraction tasks applied to the same document, depending on the type of data the application needs to obtain.
In real systems, PDF parsing is typically used to retrieve:
- Plain text content for indexing, search, or analysis
- Structured data such as tables for further processing or storage
- Embedded resources such as images for archiving or downstream processing
- Document metadata for classification, auditing, or version tracking
The complexity of PDF parsing comes from the way PDF files store content. Unlike structured document formats, PDFs do not preserve logical elements such as paragraphs, rows, or tables. Instead, most content is represented as:
- Page-level content streams
- Text fragments positioned using coordinates
- Graphical elements (images, lines, spacing, borders) that visually imply structure
As a result, Java-based PDF parsing focuses on reconstructing meaning from layout information, rather than reading predefined data structures. This is why practical Java implementations rely on a dedicated PDF parsing library that exposes low-level page content while also providing higher-level utilities—such as text extraction and table detection—to reduce the amount of custom logic required.
A Practical PDF Parsing Workflow in Java
In production environments, PDF parsing is best designed as a set of independent parsing operations that can be applied selectively, rather than as a strict step-by-step pipeline. This design improves fault isolation and allows applications to apply only the parsing logic they actually need.
At this stage, we will use Spire.PDF for Java, a Java PDF library that provides APIs for text extraction, table detection, image exporting, metadata access, and more. It is suitable for backend services, batch processing jobs, and document automation systems.
Installing Spire.PDF for Java
You can download the library from the Spire.PDF for Java download page and manually include it in your project dependencies. If you are using Maven, you can also install it by adding the following dependency to your project:
<repositories>
<repository>
<id>com.e-iceblue</id>
<name>e-iceblue</name>
<url>https://repo.e-iceblue.com/nexus/content/groups/public/</url>
</repository>
</repositories>
<dependencies>
<dependency>
<groupId>e-iceblue</groupId>
<artifactId>spire.doc</artifactId>
<version>13.12.2</version>
</dependency>
</dependencies>
After installation, you can load and analyze PDF documents using Java code without relying on external tools.
Loading and Validating PDF Documents in Java
Before performing any parsing operation, the PDF document should be loaded and validated. This step is best treated as a standalone operation that confirms the document can be safely processed by downstream parsing logic.
import com.spire.pdf.PdfDocument;
public class loadPDF {
public static void main(String[] args) {
// Create a PdfDocument instance
PdfDocument pdf = new PdfDocument();
// Load the PDF document
pdf.loadFromFile("sample.pdf");
// Get the total number of pages
int pageCount = pdf.getPages().getCount();
System.out.println("Total pages: " + pageCount);
}
}
Console Output Preview
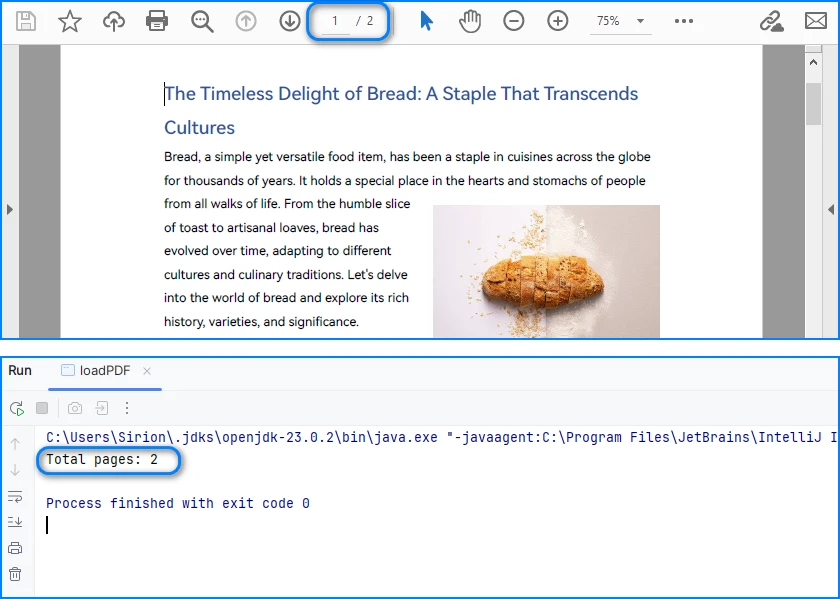
From an implementation perspective, successful loading and page access already verify several critical conditions:
- The file conforms to a supported PDF format
- The document structure can be parsed without fatal errors
- The page tree is present and accessible
In production systems, this validation step is often used as a gatekeeper. Documents that fail to load or expose a valid page collection can be rejected early.
Real world applications often need developers to parse PDFs in other formats, like bytes or streams. You can refer to How to Load PDF Documents from Bytes Using Java for details.
Separating document validation from extraction logic helps prevent cascading failures, especially in batch or automated parsing workflows.
Parsing Text from PDF Pages Using Java
Text parsing is one of the most common PDF processing tasks in Java and typically involves extracting and reconstructing readable text from PDF pages. When working with Spire.PDF for Java, text extraction should be implemented using the PdfTextExtractor class together with configurable extraction options, rather than relying on a single high-level API call.
Treating text parsing as an independent operation allows developers to extract and process textual content flexibly whenever it is required, such as indexing, analysis, or content migration.
How Text Parsing and Extraction Work in Java
In a typical Java implementation, text parsing is performed through a small set of clearly defined operations, each of which is reflected directly in the code:
- Load the PDF document into a PdfDocument instance
- Configure text parsing behavior using PdfTextExtractOptions
- Create a PdfTextExtractor for each page
- Parse and collect page-level text results
This page-based design maps cleanly to the underlying PDF structure and provides better control when processing multi-page documents.
Java Example: Extracting Text from PDF
The following example demonstrates how to extract text from a PDF file using PdfTextExtractor and PdfTextExtractOptions in Spire.PDF for Java.
import com.spire.pdf.PdfDocument;
import com.spire.pdf.texts.PdfTextExtractOptions;
import com.spire.pdf.texts.PdfTextExtractor;
public class extractPdfText {
public static void main(String[] args) {
// Create and load the PDF document
PdfDocument pdf = new PdfDocument();
pdf.loadFromFile("sample.pdf");
// Use StringBuilder to efficiently accumulate extracted text
StringBuilder extractedText = new StringBuilder();
// Configure text extraction options
PdfTextExtractOptions options = new PdfTextExtractOptions();
// Enable simple extraction mode for more readable text output
options.setSimpleExtraction(true);
// Iterate through each page in the PDF
for (int i = 0; i < pdf.getPages().getCount(); i++) {
// Create a PdfTextExtractor for the current page
PdfTextExtractor extractor =
new PdfTextExtractor(pdf.getPages().get(i));
// Extract text content from the current page using the options
String pageText = extractor.extract(options);
// Append the extracted page text to the result buffer
extractedText.append(pageText).append("\n");
}
// At this point, extractedText contains the full textual content
// and can be stored, indexed, or further processed
System.out.println(extractedText.toString());
}
}
Console Output Preview
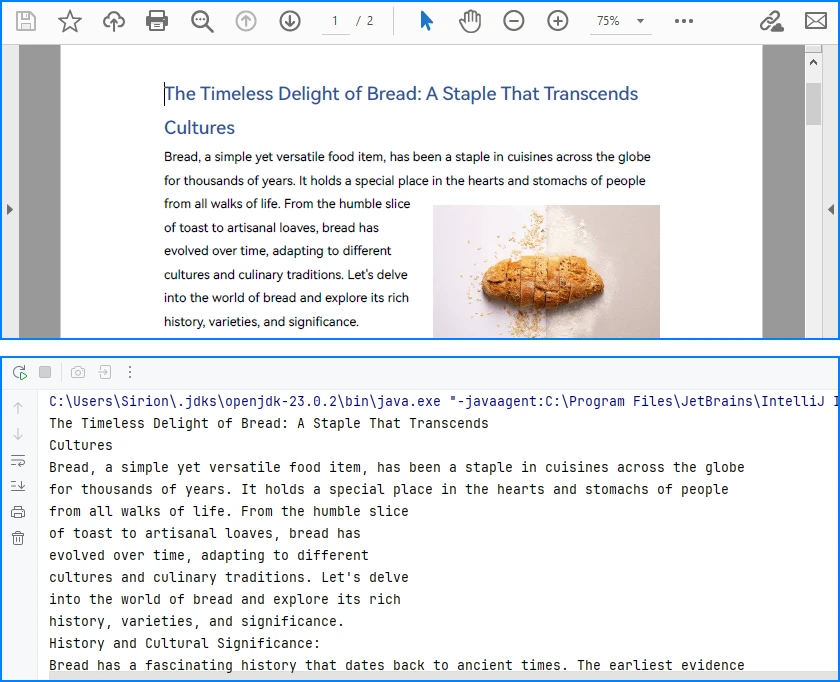
Explanation of Key Points in PDF Text Parsing
-
PdfTextExtractor: Operates at the page level and provides finer control over how text is reconstructed.
-
PdfTextExtractOptions: Allows you to control extraction behavior. Enabling
setSimpleExtraction(true)helps produce cleaner, more readable text by simplifying layout reconstruction. -
Page-by-page processing: Improves scalability and makes it easier to handle large PDF files or isolate problematic pages.
Technical Considerations
- Text is reconstructed from positioned glyphs rather than stored as paragraphs
- Extraction behavior can be tuned using PdfTextExtractOptions
- Page-level extraction improves fault tolerance and flexibility
- Extracted text often requires additional normalization for downstream systems
This method works well for reports, contracts, and other text-centric documents with relatively consistent layouts and is the recommended approach for parsing text from PDF pages in Java using Spire.PDF for Java. You can check out How to Extract Text from PDF Pages Using Java for more text extraction examples.
Parsing Tables from PDF Pages Using Java
Table parsing is an advanced PDF parsing operation that focuses on identifying tabular structures within PDF pages and reconstructing them into structured rows and columns. Compared to plain text parsing, table parsing preserves semantic relationships between data cells and is commonly used in scenarios such as invoices, financial statements, and operational reports.
When performing PDF parsing in Java, table parsing allows applications to transform visually aligned content into structured data that can be programmatically processed, stored, or exported.
How Table Parsing Works in Java Practice
When parsing tables, the implementation shifts from plain text extraction to structure inference based on visual alignment and layout consistency.
- Load the PDF document into a PdfDocument instance
- Create a PdfTableExtractor bound to the document
- Parse table structures from a specific page
- Reconstruct rows and columns from the parsed table model
- Validate and normalize parsed cell data for downstream use
Unlike plain text parsing, table parsing infers structure from visual alignment and layout consistency, allowing row-and-column access to data that is otherwise represented as positioned text.
Java Example: Parsing Tables from a PDF Page
The following example demonstrates how to parse tables from a PDF page using PdfTableExtractor in Spire.PDF for Java. The extracted tables are converted into structured row-and-column data that can be further processed or exported.
import com.spire.pdf.PdfDocument;
import com.spire.pdf.utilities.PdfTable;
import com.spire.pdf.utilities.PdfTableExtractor;
public class extractPdfTable {
public static void main(String[] args) {
// Load the PDF document
PdfDocument pdf = new PdfDocument();
pdf.loadFromFile("sample1.pdf");
// Create a table extractor bound to the document
PdfTableExtractor extractor = new PdfTableExtractor(pdf);
// Parse tables from the first page (page index starts at 0)
PdfTable[] tables = extractor.extractTable(0);
if (tables != null) {
for (PdfTable table : tables) {
// Retrieve parsed table structure
int rowCount = table.getRowCount();
int columnCount = table.getColumnCount();
System.out.println("Rows: " + rowCount +
", Columns: " + columnCount);
// Reconstruct table cell data row by row
StringBuilder tableData = new StringBuilder();
for (int i = 0; i < rowCount; i++) {
for (int j = 0; j < columnCount; j++) {
// Retrieve text from each parsed table cell
tableData.append(table.getText(i, j));
if (j < columnCount - 1) {
tableData.append("\t");
}
}
if (i < rowCount - 1) {
tableData.append("\n");
}
}
// Parsed table data is now available for export or storage
System.out.println(tableData.toString());
}
}
}
}
Console Output Preview
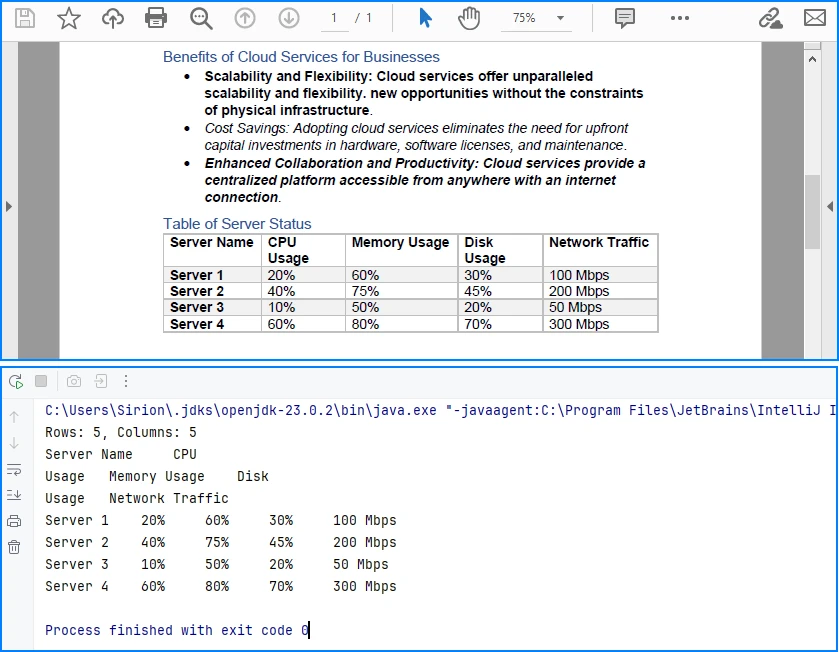
Explanation of Key Implementation Details
-
PdfTableExtractor: Analyzes page-level content and detects tabular regions based on visual alignment and layout features.
-
Structure reconstruction: Rows and columns are inferred from the relative positioning of text elements, allowing cell-level access through row and column indices.
-
Page-scoped parsing: Tables are parsed on a per-page basis, which improves accuracy and makes it easier to handle layout variations across pages.
Practical Considerations When Parsing PDF Tables
- Table boundaries are inferred from visual layout, not from an explicit schema
- Header rows may require additional detection or handling logic
- Parsed cell content often needs normalization before storage or export
- Complex or inconsistent layouts may affect parsing accuracy
Despite these limitations, table parsing remains one of the most valuable PDF parsing capabilities in Java, especially for automating data extraction from structured business documents.
After parsing table structures from PDF pages, the extracted data is often exported to structured formats such as CSV for further use, as shown in Convert PDF Tables to CSV in Java.
Parsing Images from PDF Pages Using Java
Image parsing is a specialized PDF parsing capability that focuses on extracting embedded image resources from PDF pages. Unlike text or table parsing, which operates on content streams or layout inference, image parsing works by analyzing page-level resources and identifying image objects embedded within each page.
In Java-based PDF processing systems, parsing images is commonly used for archiving visual content, auditing document composition, or passing image data to downstream processing pipelines.
How Image Parsing Works in Java
At the implementation level, image parsing operates on page-level resources rather than text content streams.
- Load the PDF document into a PdfDocument instance
- Initialize a PdfImageHelper utility
- Iterate through pages and retrieve image resource information
- Parse each embedded image and export it as a standard image format
Because images are stored as independent page resources, this parsing operation does not depend on text flow, layout reconstruction, or table detection logic.
Java Example: Parsing Images from PDF Pages
The following example demonstrates how to parse images embedded in PDF pages using PdfImageHelper and PdfImageInfo in Spire.PDF for Java. Each detected image is extracted and saved as a PNG file.
import com.spire.pdf.PdfDocument;
import com.spire.pdf.utilities.PdfImageHelper;
import com.spire.pdf.utilities.PdfImageInfo;
import javax.imageio.ImageIO;
import java.awt.image.BufferedImage;
import java.io.File;
import java.io.IOException;
public class ExtractPdfImages {
public static void main(String[] args) throws IOException {
// Load the PDF document
PdfDocument pdf = new PdfDocument();
pdf.loadFromFile("sample.pdf");
// Create a PdfImageHelper instance
PdfImageHelper imageHelper = new PdfImageHelper();
// Iterate through each page in the document
for (int i = 0; i < pdf.getPages().getCount(); i++) {
// Retrieve information of all images in the current page
PdfImageInfo[] imageInfos = imageHelper.getImagesInfo(pdf.getPages().get(i));
if (imageInfos != null) {
for (int j = 0; j < imageInfos.length; j++) {
// Retrieve image data as BufferedImage
BufferedImage image = imageInfos[j].getImage();
// Save the parsed image to a file
File output = new File(
"output/images/page_" + i + "_image_" + j + ".png"
);
ImageIO.write(image, "PNG", output);
}
}
}
}
}
Extracted Images Preview
Explanation of Key Details in PDF Image Parsing
-
PdfImageHelper & PdfImageInfo: These classes analyze page-level resources and provide access to embedded images as BufferedImage objects.
-
Page-scoped parsing: Images are parsed on a per-page basis, ensuring accurate extraction even for multi-page PDFs with repeated or reused images.
-
Independent of layout: Parsing does not rely on text flow or table alignment, making it suitable for any visual resources embedded in the document.
Practical Considerations When Parsing PDF Images
- Parsed images may include decorative or background elements
- Image resolution, color space, and format may vary by document
- Large PDFs can contain many images, so memory and storage should be managed
- Image parsing complements text, table, and metadata parsing, completing the PDF parsing workflow in Java
Besides extracting and saving individual images, PDF pages can also be converted directly to images; see Convert PDF Pages to Images in Java for more details.
Parsing PDF Metadata Using Java
Metadata parsing is a foundational PDF parsing capability that focuses on reading document-level information stored separately from visual content. Unlike text or table parsing, metadata parsing does not depend on page layout and can be applied reliably to almost any PDF file.
In Java-based PDF processing systems, parsing metadata is often used as an initial analysis step to support document classification, routing, and indexing decisions.
How Metadata Parsing works with Java
Unlike page-level parsing tasks, metadata parsing is implemented as a document-level operation that accesses information stored outside the rendering content.
- Load the PDF document into a PdfDocument instance
- Access the document information dictionary
- Parse available metadata fields
- Use parsed metadata to support classification, routing, or indexing logic
Since metadata is stored independently of page layout and rendering instructions, this parsing operation is lightweight, fast, and highly consistent across PDF files.
Java Example: Parsing PDF Document Metadata
The following example demonstrates how to parse common metadata fields from a PDF document using Spire.PDF for Java. These fields can be used for indexing, classification, or workflow routing.
import com.spire.pdf.PdfDocument;
public class ParsePdfMetadata {
public static void main(String[] args) {
// Load the PDF document
PdfDocument pdf = new PdfDocument();
pdf.loadFromFile("sample.pdf");
// Parse document-level metadata
String title = pdf.getDocumentInformation().getTitle();
String author = pdf.getDocumentInformation().getAuthor();
String subject = pdf.getDocumentInformation().getSubject();
String keywords = pdf.getDocumentInformation().getKeywords();
String creator = pdf.getDocumentInformation().getCreator();
String producer = pdf.getDocumentInformation().getProducer();
String creationDate = pdf.getDocumentInformation()
.getCreationDate().toString();
String modificationDate = pdf.getDocumentInformation()
.getModificationDate().toString();
// Parsed metadata can be stored, indexed, or used for routing logic
System.out.println(
"Title: " + title +
"\nAuthor: " + author +
"\nSubject: " + subject +
"\nKeywords: " + keywords +
"\nCreator: " + creator +
"\nProducer: " + producer +
"\nCreation Date: " + creationDate +
"\nModification Date: " + modificationDate
);
}
}
Console Output Preview

Explanation of Key Details in PDF Metadata Parsing
-
Document information dictionary: Metadata is parsed from a dedicated structure within the PDF file and is independent of page-level rendering content.
-
Field availability: Not all PDF files contain complete metadata. Parsed values may be empty or null and should be validated before use.
-
Low parsing overhead: Metadata parsing is fast and does not require page iteration, making it suitable as a preliminary parsing step.
For accessing custom PDF properties, see the PdfDocumentInformation API reference.
Common Use Cases for Metadata Parsing
- Document classification and tagging
- Search indexing and filtering
- Workflow routing and access control
- Version tracking and audit logging
Because metadata is parsed independently from visual layout and content streams, it is generally more stable and predictable than text or table parsing in complex PDF documents.
Implementation Considerations for PDF Parsing in Java
While individual parsing operations can be implemented independently, real-world Java applications often combine multiple PDF parsing capabilities within the same processing pipeline.
Combining Multiple Parsing Operations
Common implementation patterns include:
- Parsing text for indexing while parsing tables for structured storage
- Using parsed metadata to route documents to different processing workflows
- Executing parsing operations asynchronously or in scheduled batch jobs
Treating text, table, image, and metadata parsing as independent but composable operations makes PDF processing systems easier to extend, test, and maintain.
Practical Limitations and Constraints
Even with a capable Java PDF parser, certain limitations remain unavoidable:
- Scanned PDF files require OCR before any parsing can occur
- Highly complex or inconsistent layouts can reduce parsing accuracy
- Custom fonts or encodings may affect text reconstruction
Understanding these constraints helps align parsing strategies with realistic technical expectations and reduces error handling complexity in production systems.
Conclusion
PDF parsing in Java is most effective when treated as a collection of independent, purpose-driven extraction operations rather than a single linear workflow. By focusing on text extraction, table parsing, and metadata access as separate concerns, Java applications can reliably transform PDF documents into usable data.
With the help of a dedicated Java PDF parser such as Spire.PDF for Java, developers can build maintainable, production-ready PDF processing solutions that scale with real-world requirements.
To unlock the full potential of PDF parsing in Java using Spire.PDF for Java, you can request a free trial license.
Frequently Asked Questions for PDF Parsing in Java
Q1: How can I parse text from PDF pages in Java?
A1: You can use Spire.PDF for Java with the PdfTextExtractor class and PdfTextExtractOptions to extract page-level text efficiently. This approach allows flexible text parsing for indexing, analysis, or migration.
Q2: How do I extract tables from PDF files in Java?
A2: Use PdfTableExtractor to detect tabular regions and reconstruct rows and columns. Extracted tables can be further processed, exported, or stored as structured data.
Q3: Can I parse images from PDF pages in Java?
A3: Yes. With PdfImageHelper and PdfImageInfo, you can extract embedded images from each page and save them as files. You can also convert entire PDF pages directly to images if needed.
Q4: How do I read PDF metadata in Java?
A4: Access the PdfDocumentInformation object from your PDF document to retrieve standard fields like title, author, creation date, and keywords. This is fast and independent of page content.
Q5: Are there limitations to PDF parsing in Java?
A5: Complex layouts, scanned PDFs, and custom fonts can reduce parsing accuracy. Scanned documents require OCR before text or table extraction.
