This article demonstrates how to extract OLE objects from an Excel document using Spire.XLS for Java.
import com.spire.xls.*;
import com.spire.xls.core.IOleObject;
import java.io.*;
public class ExtractOLEObjects {
public static void main(String[] args){
//Create a Workbook instance
Workbook workbook = new Workbook();
//Load the Excel document
workbook.loadFromFile("OLEObjectsExample.xlsx");
//Get the first worksheet
Worksheet sheet = workbook.getWorksheets().get(0);
//Extract ole objects
if (sheet.hasOleObjects()) {
for (int i = 0; i < sheet.getOleObjects().size(); i++) {
IOleObject object = sheet.getOleObjects().get(i);
OleObjectType type = sheet.getOleObjects().get(i).getObjectType();
switch (type) {
//Word document
case WordDocument:
byteArrayToFile(object.getOleData(), "output/extractOLE.docx");
break;
//PowerPoint document
case PowerPointSlide:
byteArrayToFile(object.getOleData(), "output/extractOLE.pptx");
break;
//PDF document
case AdobeAcrobatDocument:
byteArrayToFile(object.getOleData(), "output/extractOLE.pdf");
break;
//Excel document
case ExcelWorksheet:
byteArrayToFile(object.getOleData(), "output/extractOLE.xlsx");
break;
}
}
}
}
public static void byteArrayToFile(byte[] datas, String destPath) {
File dest = new File(destPath);
try (InputStream is = new ByteArrayInputStream(datas);
OutputStream os = new BufferedOutputStream(new FileOutputStream(dest, false));) {
byte[] flush = new byte[1024];
int len = -1;
while ((len = is.read(flush)) != -1) {
os.write(flush, 0, len);
}
os.flush();
} catch (IOException e) {
e.printStackTrace();
}
}
}
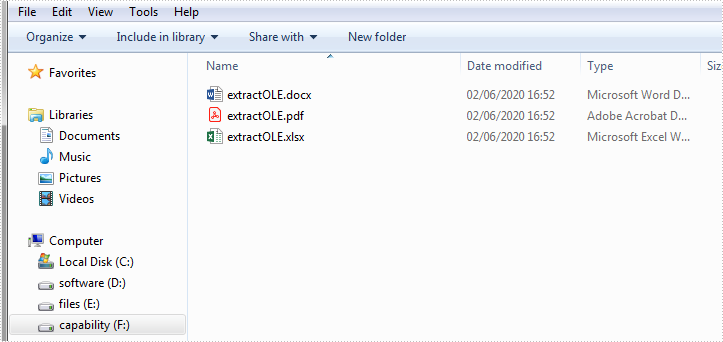
The following screenshot shows the extracted OLE documents: