Viele Leute öffnen Adobe Acrobat nur um festzustellen, dass das Extrahieren von Seiten aus einem PDF eine kostenpflichtige Funktion ist. Die gute Nachricht ist – Sie müssen nicht dafür bezahlen. Egal, ob Sie wichtige Seiten aus einem Vertrag behalten oder einen Abschnitt aus einem Bericht extrahieren müssen, dieser Leitfaden zeigt Ihnen drei kostenlose und einfache Möglichkeiten, Seiten aus einem PDF mit nur wenigen Klicks zu extrahieren.
- Seiten aus PDF mit Google Chrome extrahieren
- Eine Seite eines PDFs schnell mit Online-Tools speichern
- Seiten aus einem PDF kostenlos mit Python extrahieren
- Das Fazit
Wie man Seiten aus einem PDF mit Google Chrome extrahiert
Sie benötigen keine zusätzliche Software – Google Chrome allein kann bestimmte Seiten aus einem PDF online extrahieren. Mit der integrierten Druckfunktion können Sie alle Seiten, nur ungerade oder gerade Seiten oder einen beliebigen benutzerdefinierten Seitenbereich speichern. Wählen Sie einfach die Seiten aus, die Sie behalten möchten, und speichern Sie sie als neue PDF-Datei. So extrahieren Sie Seiten aus einem PDF mit Google Chrome:
- Suchen Sie die PDF-Datei, aus der Sie Seiten extrahieren möchten, und klicken Sie mit der rechten Maustaste, um sie in Google Chrome zu öffnen.
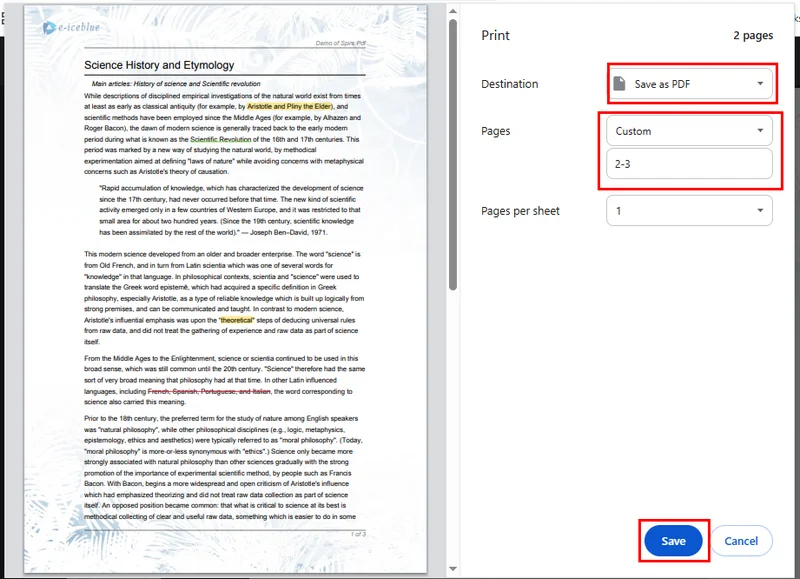
- Klicken Sie auf die Schaltfläche Drucken in der oberen rechten Ecke und ändern Sie den Zieldrucker auf Als PDF speichern.
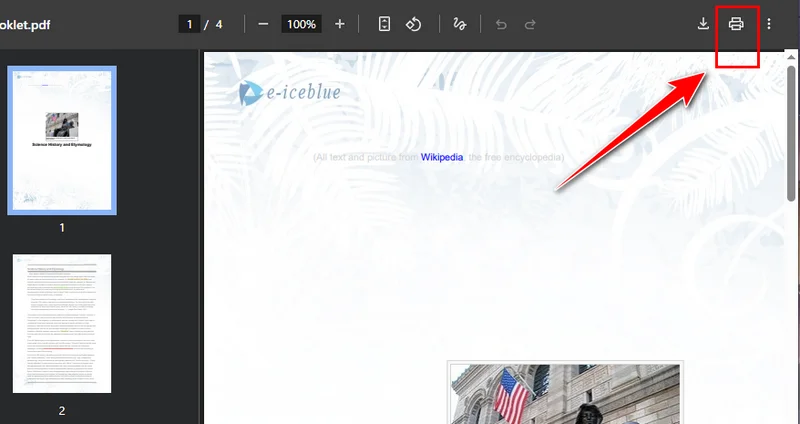
- Wählen Sie die Seiten aus, die Sie behalten möchten, und klicken Sie dann auf Speichern. Chrome lädt die neue PDF-Datei automatisch auf Ihr Gerät herunter.
Vorteile
- Keine Notwendigkeit, Software von Drittanbietern zu installieren.
- Ideal zum schnellen Extrahieren von 1–2 Seiten.
- Reibungslose Erfahrung und weithin zugänglich (fast alle Benutzer haben Chrome).
Nachteile
- Nicht geeignet zum Extrahieren einer großen Anzahl nicht aufeinanderfolgender Seiten.
- Die Ausgabeoptionen sind ziemlich einfach.
Wie man eine Seite eines PDFs schnell mit Online-Tools speichert
Es gibt viele Möglichkeiten, Seiten aus einem PDF zu extrahieren. Neben der integrierten Funktion von Chrome können Sie auch Online-Tools verwenden, um PDF-Dokumente aufzuteilen und die benötigten Seiten zu speichern. Da diese Tools webbasiert sind, funktionieren sie sowohl auf Computern als auch auf mobilen Geräten, und Sie müssen nichts herunterladen oder sich anmelden. Suchen Sie einfach in Ihrem Browser nach „Wie man Seiten aus einem PDF extrahiert“, und Sie werden viele Optionen finden. In diesem Leitfaden demonstrieren wir den Prozess mit Smallpdf, aber keine Sorge – die meisten Online-Tools funktionieren auf sehr ähnliche Weise.
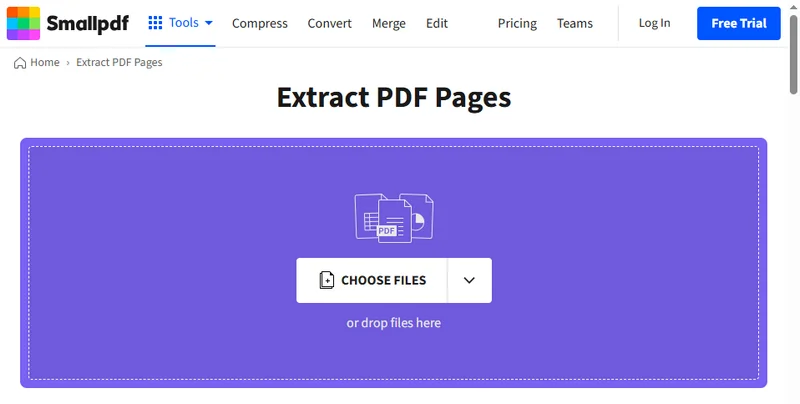
- Gehen Sie zur Seite PDF Extrahieren auf Smallpdf.
- Ziehen Sie Ihre PDF-Datei in das Tool, das sie automatisch verarbeitet und alle Seiten anzeigt.
- Wählen Sie die Seiten aus, die Sie extrahieren möchten, und klicken Sie dann auf Fertigstellen. Sie können wählen, ob Sie die Seiten als einzelne PDF-Datei oder als separate PDF-Dateien exportieren möchten.
- Sobald die Extraktion abgeschlossen ist, klicken Sie auf die Schaltfläche Herunterladen, um die resultierende PDF-Datei auf Ihrem Gerät zu speichern.
Vorteile
- Kann direkt in Ihrem Browser verwendet werden, ohne Downloads oder Installationen.
- Unterstützt das Extrahieren einzelner Seiten, aufeinanderfolgender Seiten oder nicht aufeinanderfolgender Seiten.
- Intuitive Benutzeroberfläche – einfach per Drag & Drop, auch für Anfänger einfach.
- Funktioniert auf jedem Gerät mit Browser und Internetverbindung, hochkompatibel.
Nachteile
- Erfordert eine Internetverbindung; kann nicht offline verwendet werden.
- Einige Tools begrenzen die Dateigröße für kostenlose Benutzer.
- Dateien werden auf den Server hochgeladen, seien Sie also vorsichtig mit sensiblen Inhalten.
- Erweiterte Funktionen wie Stapelverarbeitung oder wasserzeichenfreie Downloads können kostenpflichtig sein.
Wie man Seiten aus einem PDF kostenlos mit Python extrahiert
Beim Umgang mit PDFs haben sowohl Chrome als auch Online-Tools eine Einschränkung – sie können nur eine Datei gleichzeitig verarbeiten. Wenn Sie mehrere PDFs bearbeiten, gibt es eine schnellere und professionellere Lösung: Free Spire.PDF for Python.
Diese leistungsstarke Bibliothek bietet eine breite Palette von PDF-Funktionen, einschließlich dem Extrahieren von Seiten, dem Konvertieren von Formaten und dem Bearbeiten von Inhalten. Mit Free Spire.PDF können Sie ganz einfach bestimmte Seiten extrahieren, indem Sie sie aus dem Quell-PDF mit der Methode PdfDocument.InsertPage() in ein neues Dokument einfügen.
Der folgende Beispielcode zeigt, wie die 2. und 4. Seite aus einem PDF extrahiert und in einer neuen Datei zusammengeführt werden.
from spire.pdf import PdfDocument
# Load a PDF file
source_pdf = PdfDocument()
source_pdf.LoadFromFile("/input/Booklet.pdf")
# Create a new PdfDocument instance
new_pdf = PdfDocument()
# Extract page 2 and page 4
new_pdf.InsertPage(source_pdf, 1)
new_pdf.InsertPage(source_pdf, 3)
# Save the extracted pages
new_pdf.SaveToFile("/output/extracted_pages.pdf")
new_pdf.Close()
Hier ist die Vorschau der resultierenden Datei: 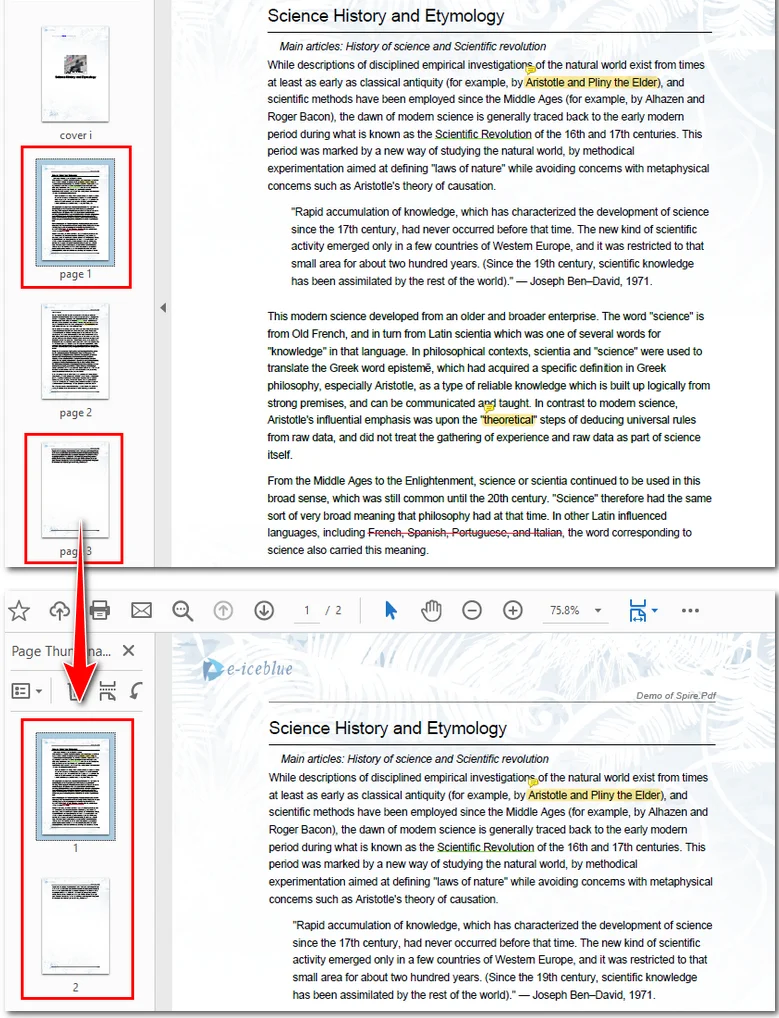
Wenn Sie eine große Anzahl von Seiten extrahieren müssen, besteht eine weitere Möglichkeit darin, stattdessen die nicht benötigten Seiten zu löschen. Dieser Ansatz kann bei der Arbeit mit PDFs in Python genauso effektiv sein.
Das Fazit
Egal, ob Sie eine einzelne Seite extrahieren oder mehrere PDFs verwalten, die Wahl des richtigen Tools kann Ihnen viel Zeit sparen. Wenn Sie eine flexiblere und codebasierte Lösung bevorzugen, bietet Free Spire.PDF for Python eine zuverlässige Möglichkeit, PDF-Dateien effizient zu extrahieren, zu bearbeiten oder zu organisieren. Sie können es kostenlos herunterladen und weitere Funktionen auf der offiziellen Website erkunden.
LESEN SIE AUCH