
In modernen Anwendungen ist JSON eines der gebräuchlichsten Datenformate für APIs, Konfigurationsdateien und den Datenaustausch. Obwohl JSON ideal für Maschinen ist, ist es nicht immer für Menschen lesbar. Der Export von JSON in eine PDF-Tabelle kann helfen, strukturierte Informationen in Berichten, Dashboards oder interner Dokumentation klar darzustellen.
In diesem Tutorial erfahren Sie, wie Sie mit Python und Spire.XLS JSON in eine gut formatierte PDF-Tabelle konvertieren, einschließlich:
- Automatisches Erkennen von Datensätzen für den Tabellenexport
- Abflachen verschachtelter JSON-Felder
- Erstellen professionell aussehender PDFs
Wir werden auch die manuelle Datensatzextraktion für tief verschachtelte Strukturen behandeln, die Ihnen die volle Kontrolle über komplexe JSON-Dateien gibt.
Warum die Konvertierung von JSON in PDF nicht immer einfach ist
JSON gibt es in allen Formen und Größen:
- Flache Arrays: einfach direkt in Zeilen zu konvertieren
- Verschachtelte Objekte: z. B. ein Spezifikationswörterbuch in jedem Produkt
- Arrays in Arrays: z. B. eine Liste von Produkten innerhalb einer Abteilung
- Inkonsistente Schlüssel: Einige Objekte haben zusätzliche oder fehlende Felder
Betrachten Sie zum Beispiel diese Struktur für das Inventar eines Geschäfts:
{
"store": {
"departments": [
{
"name": "Computers",
"products": [{"id": 1, "name": "Laptop", "specs": {"CPU": "i7"}}]
},
{
"name": "Accessories",
"products": [{"id": 101, "name": "Mouse", "colors": ["Black", "White"]}]
}
]
}
}
Dies in eine Tabelle abzuflachen ist nicht trivial, da verschachtelte Felder in Spalten umgewandelt und Arrays möglicherweise erweitert oder zu Zeichenfolgen zusammengefügt werden müssen. Unsere Lösung bietet eine robuste Handhabung für die meisten JSON-Strukturen und bietet gleichzeitig eine Option zur manuellen Extraktion für ungewöhnlich komplexe Fälle.
Für eine schnelle Auffrischung der JSON-Syntax und -Struktur siehe: Einführung in JSON
Schritt 1 — JSON-Daten laden
Laden Sie vor der Verarbeitung Ihre JSON-Datei in Python. Die Verwendung des integrierten json-Moduls stellt sicher, dass der Inhalt in native Python-Wörterbücher und -Listen geparst wird:
import json
file_path = r"C:\Users\Administrator\Desktop\Products.json"
with open(file_path, "r", encoding="utf-8") as f:
data = json.load(f)
Was dieser Schritt bewirkt:
- Liest eine JSON-Datei von der Festplatte
- Konvertiert sie zur weiteren Verarbeitung in Python-Objekte (dict und list)
Tipp: Geben Sie immer encoding="utf-8" an, um Probleme mit Nicht-ASCII-Zeichen zu vermeiden.
Schritt 2 — Den zu exportierenden Datensatz automatisch erkennen
Viele JSON-Dateien enthalten mehrere verschachtelte Listen. Oft benötigen wir die Liste der Objekte, die die „Haupttabelle“ darstellt – normalerweise die größte Liste von Wörterbüchern. Die folgende Funktion sucht automatisch nach dem tabellenähnlichsten Datensatz:
def find_dataset(obj):
"""Durchsuchen Sie JSON rekursiv und geben Sie den tabellenähnlichsten Datensatz zurück."""
candidates = []
def search(node):
if isinstance(node, list):
if node and all(isinstance(i, dict) for i in node):
keys = set()
for item in node:
keys.update(item.keys())
score = len(keys) * len(node)
candidates.append((score, node))
for item in node:
search(item)
elif isinstance(node, dict):
for value in node.values():
search(value)
search(obj)
if not candidates:
raise ValueError("Kein passender Datensatz gefunden.")
candidates.sort(key=lambda x: x[0], reverse=True)
return candidates[0][1]
# Usage
dataset = find_dataset(data)
Wie es funktioniert:
- Durchläuft rekursiv die JSON-Struktur
- Bewertet Kandidatenlisten basierend auf der Anzahl der Schlüssel × der Anzahl der Elemente
- Wählt den reichhaltigsten Datensatz als Haupttabelle aus
Einschränkungen:
- Verschmilzt nicht automatisch tief verschachtelte Listen (z. B. Produkte mehrerer Abteilungen)
- Einige Felder erfordern möglicherweise eine manuelle Extraktion für volle Sichtbarkeit
Optional — Manuelle Datensatzextraktion
Extrahieren Sie für tief verschachtelte oder benutzerdefinierte Datensätze die Daten manuell:
dataset = []
for dept in data["store"]["departments"]:
for prod in dept["products"]:
prod["department"] = dept["name"]
dataset.append(prod)
Dieser Ansatz garantiert, dass Sie genau die Felder erfassen, die Sie benötigen, einschließlich des Hinzufügens von Kontext wie der Abteilung für jedes Produkt.
Schritt 3 — JSON abflachen und normalisieren
Um JSON in eine Tabelle zu konvertieren, müssen verschachtelte Strukturen abgeflacht werden:
def flatten_json(obj, parent_key="", sep="_"):
items = {}
if isinstance(obj, dict):
for key, value in obj.items():
new_key = f"{parent_key}{sep}{key}" if parent_key else key
if isinstance(value, dict):
items.update(flatten_json(value, new_key, sep))
elif isinstance(value, list):
if not value:
items[new_key] = ""
elif all(not isinstance(i, (dict, list)) for i in value):
items[new_key] = ", ".join(map(str, value))
else:
for index, item in enumerate(value):
indexed_key = f"{new_key}{sep}{index}"
items.update(flatten_json(item, indexed_key, sep))
else:
items[new_key] = value
elif isinstance(obj, list):
for index, item in enumerate(obj):
indexed_key = f"{parent_key}{sep}{index}" if parent_key else str(index)
items.update(flatten_json(item, indexed_key, sep))
else:
items[parent_key] = obj
return items
def normalize_json(data):
flattened_rows = [flatten_json(item) for item in data]
all_keys_ordered, seen_keys = [], set()
for row in flattened_rows:
for key in row.keys():
if key not in seen_keys:
seen_keys.add(key)
all_keys_ordered.append(key)
aligned_rows = [{key: str(row.get(key, "")) for key in all_keys_ordered} for row in flattened_rows]
return aligned_rows, all_keys_ordered
rows, headers = normalize_json(dataset)
Was dieser Schritt bewirkt:
- Konvertiert verschachtelte Wörterbücher in Spaltennamen wie specs_CPU, specs_RAM
- Konvertiert Listen von Primitiven in durch Kommas getrennte Zeichenfolgen
- Behält den zuerst gesehenen Schlüssel als erste Spalte bei
Schritt 4 — Über Excel in PDF exportieren
Sobald die Daten abgeflacht sind, exportieren Sie sie als PDF mit Spire.XLS for Python. Anstatt PDF direkt zu rendern, verwenden wir Excel als zwischengeschaltete Layout-Ebene. Dieser Ansatz bietet die volle Kontrolle über Tabellenstruktur, Formatierung, Ränder und Skalierung vor dem Export in PDF.
Abhängigkeit installieren:
pip install spire.xls
JSON mit Spire.XLS in PDF exportieren:
from spire.xls import Workbook
import os
def export_to_pdf(data_rows, headers, output_path):
workbook = Workbook()
sheet = workbook.Worksheets[0]
# Write headers
for col, header in enumerate(headers):
sheet.Range[1, col + 1].Text = header
# Write data rows
for row_idx, row in enumerate(data_rows, start=2):
for col_idx, header in enumerate(headers):
sheet.Range[row_idx, col_idx + 1].Text = row[header]
# Formatting
workbook.ConverterSetting.SheetFitToPageRetainPaperSize = True
workbook.ConverterSetting.SheetFitToWidth = True
for i in range(1, sheet.Range.ColumnCount + 1):
sheet.AutoFitColumn(i)
sheet.PageSetup.LeftMargin = 0.3
sheet.PageSetup.RightMargin = 0.3
sheet.PageSetup.TopMargin = 0.5
sheet.PageSetup.BottomMargin = 0.5
sheet.PageSetup.IsPrintGridlines = True
sheet.DefaultRowHeight = 18
os.makedirs(os.path.dirname(output_path), exist_ok=True)
sheet.SaveToPdf(output_path)
workbook.Dispose()
print(f"PDF gespeichert: {output_path}")
Tipps zur PDF-Formatierung:
- Spalten automatisch an den Inhalt anpassen
- Ränder für die Lesbarkeit festlegen
- Gitternetzlinien für eine bessere Tabellenvisualisierung aktivieren
Das könnte Ihnen auch gefallen: Excel in Python in PDF konvertieren
Schritt 5 — Beispiel: Produkte aus einer komplexen JSON-Datei exportieren
Kombinieren Sie die vorherigen Schritte:
file_path = r"C:\Users\Administrator\Desktop\Products.json"
with open(file_path, "r", encoding="utf-8") as f:
data = json.load(f)
# Option 1: Automatische Erkennung
dataset = find_dataset(data)
rows, headers = normalize_json(dataset)
# Option 2: Manuelle Extraktion für verschachtelte Strukturen
# dataset = []
# for dept in data["store"]["departments"]:
# for prod in dept["products"]:
# prod["department"] = dept["name"]
# dataset.append(prod)
# rows, headers = normalize_json(dataset)
export_to_pdf(rows, headers, "output/Products.pdf")
Wichtige Punkte:
- Die automatische Erkennung funktioniert für die meisten JSON-Arrays
- Die manuelle Extraktion gewährleistet die Kontrolle über verschachtelte und hierarchische Datensätze
Ausgabe:
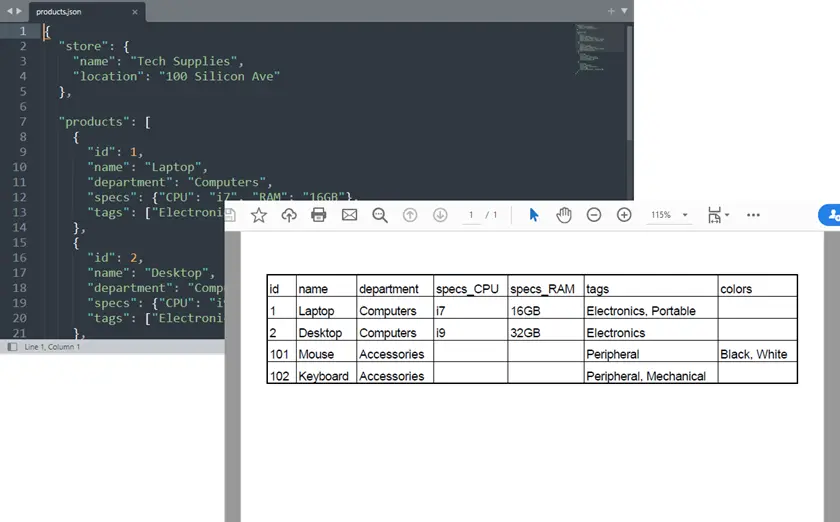
Vollständiges Python-Beispiel: JSON zu PDF
from spire.xls import Workbook
import json
import os
# ---------------------------
# Datensatz automatisch erkennen
# ---------------------------
def find_dataset(obj):
"""
Durchsuchen Sie JSON rekursiv und geben Sie den tabellenähnlichsten Datensatz zurück.
Strategie:
- Listen finden, die Wörterbücher enthalten
- Datensätze basierend auf der Anzahl der Felder bewerten
- Wählen Sie den Datensatz mit der reichhaltigsten Struktur
"""
candidates = []
def search(node):
if isinstance(node, list):
if node and all(isinstance(i, dict) for i in node):
# Eindeutige Schlüssel über Objekte hinweg zählen
keys = set()
for item in node:
keys.update(item.keys())
score = len(keys) * len(node)
candidates.append((score, node))
for item in node:
search(item)
elif isinstance(node, dict):
for value in node.values():
search(value)
search(obj)
if not candidates:
raise ValueError("Kein passender Datensatz gefunden.")
# bestbewerteten Datensatz auswählen
candidates.sort(key=lambda x: x[0], reverse=True)
return candidates[0][1]
# ---------------------------
# Robuster rekursiver JSON-Abflacher
# ---------------------------
def flatten_json(obj, parent_key="", sep="_"):
"""
Flacht verschachtelte Wörterbücher und Listen rekursiv ab.
Regeln:
- Verschachteltes dict → key_subkey
- Liste von Primitiven → durch Kommas getrennte Zeichenfolge
- Liste von dicts → indizierte Spalten (key_0_name, key_1_name)
- Gemischte Listen / Arrays-von-Arrays → rekursiv indiziert (key_0_0, key_0_1)
"""
items = {}
if isinstance(obj, dict):
for key, value in obj.items():
new_key = f"{parent_key}{sep}{key}" if parent_key else key
if isinstance(value, dict):
items.update(flatten_json(value, new_key, sep))
elif isinstance(value, list):
# Leere Liste
if not value:
items[new_key] = ""
# Liste von Primitiven
elif all(not isinstance(i, (dict, list)) for i in value):
items[new_key] = ", ".join(map(str, value))
# Gemischte oder verschachtelte Listen
else:
for index, item in enumerate(value):
indexed_key = f"{new_key}{sep}{index}"
items.update(flatten_json(item, indexed_key, sep))
else:
items[new_key] = value
# Listen der obersten Ebene
elif isinstance(obj, list):
for index, item in enumerate(obj):
indexed_key = f"{parent_key}{sep}{index}" if parent_key else str(index)
items.update(flatten_json(item, indexed_key, sep))
else:
items[parent_key] = obj
return items
# ---------------------------
# JSON-Daten normalisieren (Spaltenreihenfolge nach erstem Auftreten)
# ---------------------------
def normalize_json(data):
"""
JSON-Objekte abflachen und Kopfzeilen ausrichten, wobei die Reihenfolge des ersten Auftretens beibehalten wird.
Der erste Schlüssel im ersten JSON-Objekt wird die erste Spalte sein.
"""
if not isinstance(data, list):
raise ValueError("Daten müssen eine Liste von Objekten sein.")
flattened_rows = [flatten_json(item) for item in data]
# Kopfzeilen in der Reihenfolge des ersten Auftretens verfolgen
all_keys_ordered = []
seen_keys = set()
for row in flattened_rows:
for key in row.keys():
if key not in seen_keys:
seen_keys.add(key)
all_keys_ordered.append(key)
# Alle Zeilen ausrichten, um alle Schlüssel einzuschließen
aligned_rows = [{key: str(row.get(key, "")) for key in all_keys_ordered} for row in flattened_rows]
return aligned_rows, all_keys_ordered
# ---------------------------
# Über Excel in PDF exportieren
# ---------------------------
def export_to_pdf(data_rows, headers, output_path):
workbook = Workbook()
sheet = workbook.Worksheets[0]
# Kopfzeile schreiben
for col, header in enumerate(headers):
sheet.Range[1, col + 1].Text = header
# Datenzeilen schreiben
for row_idx, row in enumerate(data_rows, start=2):
for col_idx, header in enumerate(headers):
sheet.Range[row_idx, col_idx + 1].Text = row[header]
# Formatierung
workbook.ConverterSetting.SheetFitToPageRetainPaperSize = True
workbook.ConverterSetting.SheetFitToWidth = True
for i in range(1, sheet.Range.ColumnCount + 1):
sheet.AutoFitColumn(i)
sheet.PageSetup.LeftMargin = 0.3
sheet.PageSetup.RightMargin = 0.3
sheet.PageSetup.TopMargin = 0.5
sheet.PageSetup.BottomMargin = 0.5
sheet.PageSetup.IsPrintGridlines = True
sheet.DefaultRowHeight = 18
os.makedirs(os.path.dirname(output_path), exist_ok=True)
sheet.SaveToPdf(output_path)
workbook.Dispose()
print(f"PDF gespeichert: {output_path}")
# ===========================
# Beispiel: Komplexer JSON-Datensatz
# ===========================
# JSON aus Datei laden
with open(r"C:\Users\Administrator\Desktop\Products.json", "r", encoding="utf-8") as f:
data = json.load(f)
# Option 1. Datensatz automatisch erkennen (funktioniert in den meisten Fällen)
dataset = find_dataset(data)
'''
# Option 2. Datensatz manuell extrahieren (funktioniert für komplexe ungewöhnliche Strukturen)
dataset = []
for dept in data["store"]["departments"]:
for prod in dept["products"]:
prod["department"] = dept["name"]
dataset.append(prod)
'''
# Normalisieren (der zuerst gesehene Schlüssel wird zur ersten Spalte)
rows, headers = normalize_json(dataset)
# In PDF exportieren
export_to_pdf(rows, headers, "output/Products.pdf")
Fazit
Die Konvertierung von JSON in eine PDF-Tabelle kann schwierig sein, insbesondere bei verschachtelten Strukturen oder inkonsistenten Schlüsseln. Mit Python und Spire.XLS können Sie JSON automatisch abflachen und eine logische Spaltenreihenfolge beibehalten, wodurch komplexe Datensätze in saubere, lesbare Tabellen umgewandelt werden, die für Berichte oder Dokumentationen geeignet sind.
Die automatische Datensatzerkennung verarbeitet die meisten JSON-Dateien, während die manuelle Extraktion bei Bedarf das Erfassen spezifischer verschachtelter Daten ermöglicht. Dieser Ansatz bietet eine flexible und zuverlässige Möglichkeit, JSON in professionelle PDF-Tabellen zu konvertieren, ohne Struktur oder Kontext zu verlieren.
Häufig gestellte Fragen
Kann dies jede JSON-Datei verarbeiten?
Die automatische Erkennung funktioniert für die meisten, aber für tief verschachtelte Daten kann eine manuelle Extraktion erforderlich sein.
Wie wird die Spaltenreihenfolge bestimmt?
Die Spalten erscheinen in der Reihenfolge ihres ersten Auftretens in den JSON-Objekten.
Können mehrere Datensätze zusammengeführt werden?
Ja, Sie können Datensätze vor dem Abflachen verketten.
Wie werden fehlende Felder behandelt?
Fehlende Werte werden automatisch als leere Zellen dargestellt.
Kann ich das PDF-Layout anpassen?
Ja, Ränder, Gitternetzlinien und Auto-Fit-Optionen sind über Spire.XLS vollständig konfigurierbar.