Mucha gente abre Adobe Acrobat solo para descubrir que extraer páginas de un PDF es una función de pago. La buena noticia es que no tienes que pagar por ello. Ya sea que necesites conservar páginas clave de un contrato o extraer una sección de un informe, esta guía te mostrará tres formas fáciles y gratuitas de extraer páginas de un PDF en solo unos pocos clics.
- Extraer Páginas de PDF con Google Chrome
- Guardar una Página de un PDF Rápidamente con Herramientas en Línea
- Extraer Páginas de un PDF Gratis Usando Python
- La Conclusión
Cómo Extraer Páginas de PDF con Google Chrome
No necesitas ningún software adicional: solo Google Chrome puede extraer páginas específicas de un PDF en línea. Usando su función de Impresión incorporada, puedes elegir guardar todas las páginas, solo las páginas impares o pares, o cualquier rango de páginas personalizado que desees. Simplemente selecciona las páginas que deseas conservar y guárdalas como un nuevo archivo PDF. A continuación, te explicamos cómo extraer páginas de un PDF usando Google Chrome:
- Localiza el archivo PDF del que deseas extraer páginas y haz clic derecho para abrirlo en Google Chrome.
- Haz clic en el botón Imprimir en la esquina superior derecha y cambia la impresora de destino a Guardar como PDF.
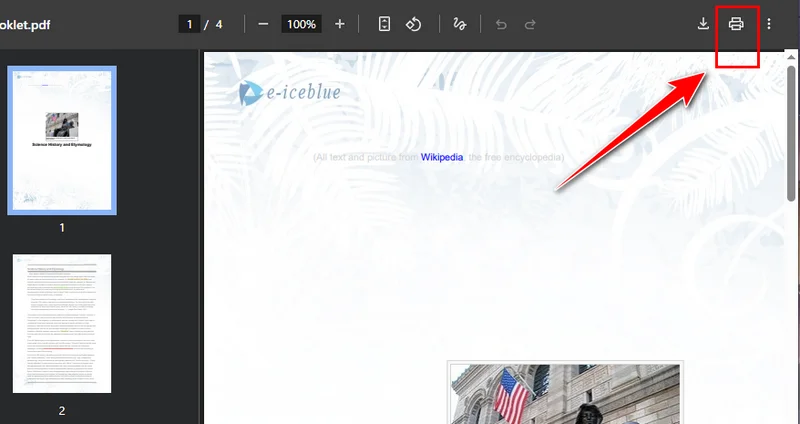
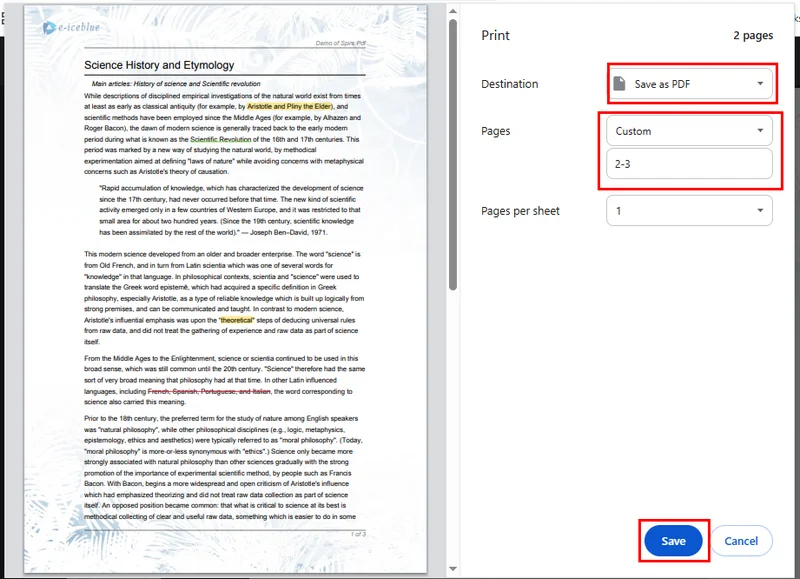
- Selecciona las páginas que deseas conservar, luego haz clic en Guardar. Chrome descargará automáticamente el nuevo PDF a tu dispositivo.
Pros
- No es necesario instalar ningún software de terceros.
- Ideal para extraer rápidamente 1–2 páginas.
- Experiencia fluida y ampliamente accesible (casi todos los usuarios tienen Chrome).
Contras
- No es adecuado para extraer una gran cantidad de páginas no consecutivas.
- Las opciones de salida son bastante básicas.
Cómo Guardar una Página de un PDF Rápidamente con Herramientas en Línea
Hay muchas formas de extraer páginas de un PDF. Además de usar la función incorporada de Chrome, también puedes usar herramientas en línea para dividir documentos PDF y guardar las páginas que necesitas. Como estas herramientas están basadas en la web, funcionan tanto en computadoras como en dispositivos móviles, y no necesitas descargar nada ni registrarte. Simplemente busca "cómo extraer páginas de un PDF" en tu navegador y encontrarás muchas opciones. En esta guía, demostraremos el proceso usando Smallpdf, pero no te preocupes, la mayoría de las herramientas en línea funcionan de manera muy similar.
- Ve a la página Extraer Páginas PDF en Smallpdf.
- Arrastra tu archivo PDF a la herramienta, que lo procesará automáticamente y mostrará todas las páginas.
- Selecciona las páginas que deseas extraer, luego haz clic en Finalizar. Puedes elegir exportar las páginas como un solo PDF o como archivos PDF separados.
- Una vez que se complete la extracción, haz clic en el botón Descargar para guardar el PDF resultante en tu dispositivo.
Pros
- Se puede usar directamente en tu navegador, sin descargas ni instalaciones.
- Admite la extracción de páginas individuales, páginas consecutivas o páginas no consecutivas.
- Interfaz intuitiva: solo arrastrar y soltar, fácil incluso para principiantes.
- Funciona en cualquier dispositivo con navegador y conexión a internet, alta compatibilidad.
Contras
- Requiere conexión a internet; no se puede usar sin conexión.
- Algunas herramientas limitan el tamaño del archivo para los usuarios gratuitos.
- Los archivos se suben al servidor, así que ten cuidado con el contenido sensible.
- Las funciones avanzadas, como el procesamiento por lotes o las descargas sin marcas de agua, pueden requerir pago.
Cómo Extraer Páginas de un PDF Gratis Usando Python
Al trabajar con archivos PDF, tanto Chrome como las herramientas en línea comparten una limitación: solo pueden procesar un archivo a la vez. Si manejas múltiples archivos PDF, existe una solución más rápida y profesional: Free Spire.PDF for Python.
Esta potente biblioteca ofrece una amplia gama de funciones para PDF, incluyendo la extracción de páginas, la conversión de formatos y la edición de contenido. Con Free Spire.PDF, puedes extraer fácilmente páginas específicas agregándolas desde el PDF de origen a un nuevo documento usando el método PdfDocument.InsertPage().
El código de muestra a continuación demuestra cómo extraer la 2ª y 4ª página de un PDF y combinarlas en un nuevo archivo.
from spire.pdf import PdfDocument
# Load a PDF file
source_pdf = PdfDocument()
source_pdf.LoadFromFile("/input/Booklet.pdf")
# Create a new PdfDocument instance
new_pdf = PdfDocument()
# Extract page 2 and page 4
new_pdf.InsertPage(source_pdf, 1)
new_pdf.InsertPage(source_pdf, 3)
# Save the extracted pages
new_pdf.SaveToFile("/output/extracted_pages.pdf")
new_pdf.Close()
Aquí está la vista previa del archivo resultante: 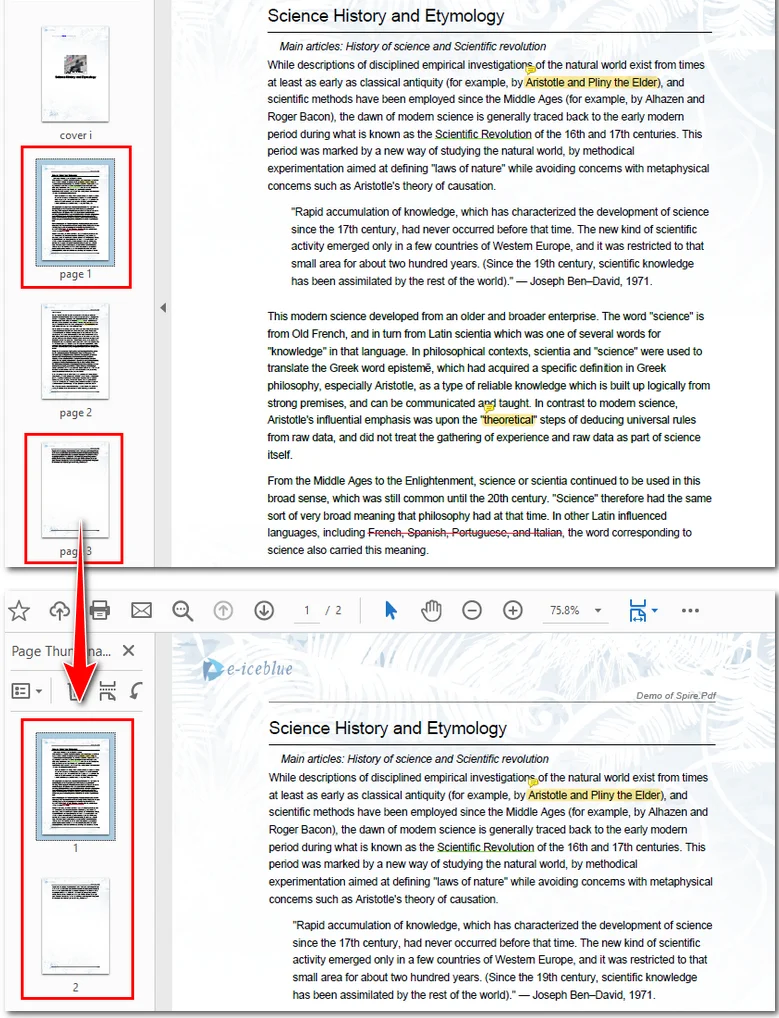
Si necesitas extraer una gran cantidad de páginas, otra opción es eliminar las páginas innecesarias en su lugar. Este enfoque puede ser igual de efectivo al trabajar con archivos PDF en Python.
La Conclusión
Ya sea que estés extrayendo una sola página o gestionando múltiples archivos PDF, elegir la herramienta adecuada puede ahorrarte mucho tiempo. Si prefieres una solución más flexible y basada en código, Free Spire.PDF for Python ofrece una forma fiable de extraer, editar u organizar archivos PDF de manera eficiente. Puedes descargarlo gratis y explorar más funciones en el sitio web oficial.
TAMBIÉN LEER