De nombreuses personnes ouvrent Adobe Acrobat pour découvrir que l'extraction de pages d'un PDF est une fonctionnalité payante. La bonne nouvelle, c'est que vous n'avez pas à payer pour cela. Que vous ayez besoin de conserver les pages clés d'un contrat ou d'extraire une section d'un rapport, ce guide vous montrera trois façons simples et gratuites d'extraire des pages d'un PDF en quelques clics.
- Extraire des pages d'un PDF avec Google Chrome
- Enregistrer rapidement une page d'un PDF avec des outils en ligne
- Extraire gratuitement des pages d'un PDF en utilisant Python
- La conclusion
Comment extraire des pages d'un PDF avec Google Chrome
Vous n'avez besoin d'aucun logiciel supplémentaire — Google Chrome peut à lui seul extraire des pages spécifiques d'un PDF en ligne. Grâce à sa fonction d'impression intégrée, vous pouvez choisir d'enregistrer toutes les pages, uniquement les pages paires ou impaires, ou toute plage de pages personnalisée de votre choix. Il vous suffit de sélectionner les pages que vous souhaitez conserver et de les enregistrer dans un nouveau fichier PDF. Voici comment extraire des pages d'un PDF à l'aide de Google Chrome :
- Localisez le fichier PDF dont vous souhaitez extraire les pages et faites un clic droit pour l'ouvrir dans Google Chrome.
- Cliquez sur le bouton Imprimer dans le coin supérieur droit et changez l'imprimante de destination en Enregistrer au format PDF.
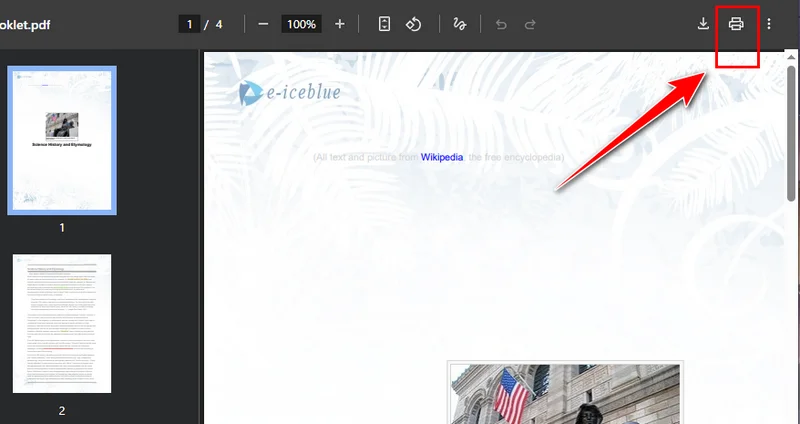
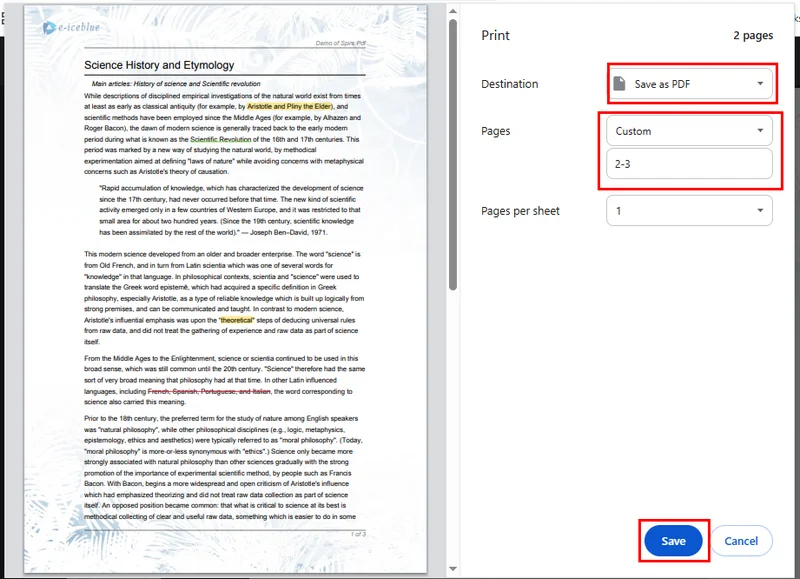
- Sélectionnez les pages que vous souhaitez conserver, puis cliquez sur Enregistrer. Chrome téléchargera automatiquement le nouveau PDF sur votre appareil.
Avantages
- Aucune installation de logiciel tiers n'est nécessaire.
- Idéal pour extraire rapidement 1 à 2 pages.
- Expérience fluide et largement accessible (presque tous les utilisateurs ont Chrome).
Inconvénients
- Ne convient pas à l'extraction d'un grand nombre de pages non consécutives.
- Les options de sortie sont assez basiques.
Comment enregistrer rapidement une page d'un PDF avec des outils en ligne
Il existe de nombreuses façons d'extraire des pages d'un PDF. Outre l'utilisation de la fonctionnalité intégrée de Chrome, vous pouvez également utiliser des outils en ligne pour diviser des documents PDF et enregistrer les pages dont vous avez besoin. Comme ces outils sont basés sur le Web, ils fonctionnent aussi bien sur les ordinateurs que sur les appareils mobiles, et vous n'avez rien à télécharger ni à vous inscrire. Il vous suffit de rechercher « comment extraire des pages d'un PDF » dans votre navigateur pour trouver de nombreuses options. Dans ce guide, nous allons vous montrer le processus en utilisant Smallpdf, mais ne vous inquiétez pas, la plupart des outils en ligne fonctionnent de manière très similaire.
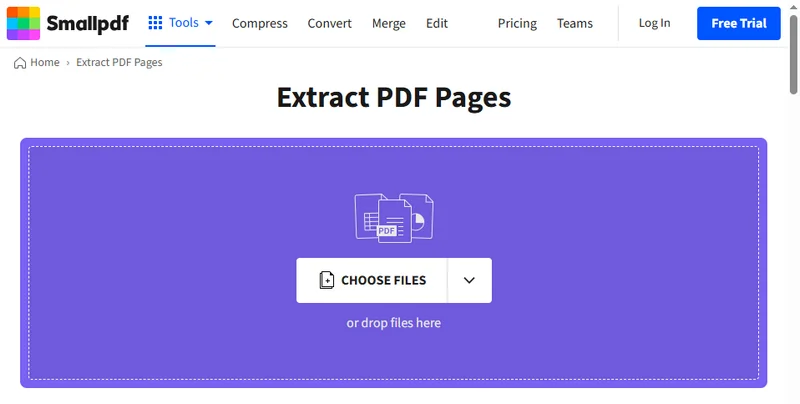
- Allez à la page Extraire des pages PDF sur Smallpdf.
- Faites glisser votre fichier PDF dans l'outil, qui le traitera automatiquement et affichera toutes les pages.
- Sélectionnez les pages que vous souhaitez extraire, puis cliquez sur Terminer. Vous pouvez choisir d'exporter les pages sous forme d'un seul PDF ou de fichiers PDF distincts.
- Une fois l'extraction terminée, cliquez sur le bouton Télécharger pour enregistrer le PDF résultant sur votre appareil.
Avantages
- Peut être utilisé directement dans votre navigateur, sans aucun téléchargement ni installation.
- Prend en charge l'extraction de pages uniques, de pages consécutives ou de pages non consécutives.
- Interface intuitive — il suffit de glisser-déposer, facile même pour les débutants.
- Fonctionne sur n'importe quel appareil doté d'un navigateur et d'une connexion Internet, hautement compatible.
Inconvénients
- Nécessite une connexion Internet ; ne peut pas être utilisé hors ligne.
- Certains outils limitent la taille des fichiers pour les utilisateurs gratuits.
- Les fichiers sont téléchargés sur le serveur, soyez donc prudent avec le contenu sensible.
- Les fonctionnalités avancées, telles que le traitement par lots ou les téléchargements sans filigrane, peuvent nécessiter un paiement.
Comment extraire gratuitement des pages d'un PDF en utilisant Python
Lorsqu'il s'agit de PDF, Chrome et les outils en ligne partagent une limitation : ils ne peuvent traiter qu'un seul fichier à la fois. Si vous manipulez plusieurs PDF, il existe une solution plus rapide et plus professionnelle : Free Spire.PDF for Python.
Cette puissante bibliothèque offre un large éventail de fonctionnalités PDF, notamment l'extraction de pages, la conversion de formats et la modification de contenu. Avec Free Spire.PDF, vous pouvez facilement extraire des pages spécifiques en les ajoutant du PDF source dans un nouveau document à l'aide de la méthode PdfDocument.InsertPage().
L'exemple de code ci-dessous montre comment extraire les 2ème et 4ème pages d'un PDF et les fusionner dans un nouveau fichier.
from spire.pdf import PdfDocument
# Load a PDF file
source_pdf = PdfDocument()
source_pdf.LoadFromFile("/input/Booklet.pdf")
# Create a new PdfDocument instance
new_pdf = PdfDocument()
# Extract page 2 and page 4
new_pdf.InsertPage(source_pdf, 1)
new_pdf.InsertPage(source_pdf, 3)
# Save the extracted pages
new_pdf.SaveToFile("/output/extracted_pages.pdf")
new_pdf.Close()
Voici l'aperçu du fichier résultant : 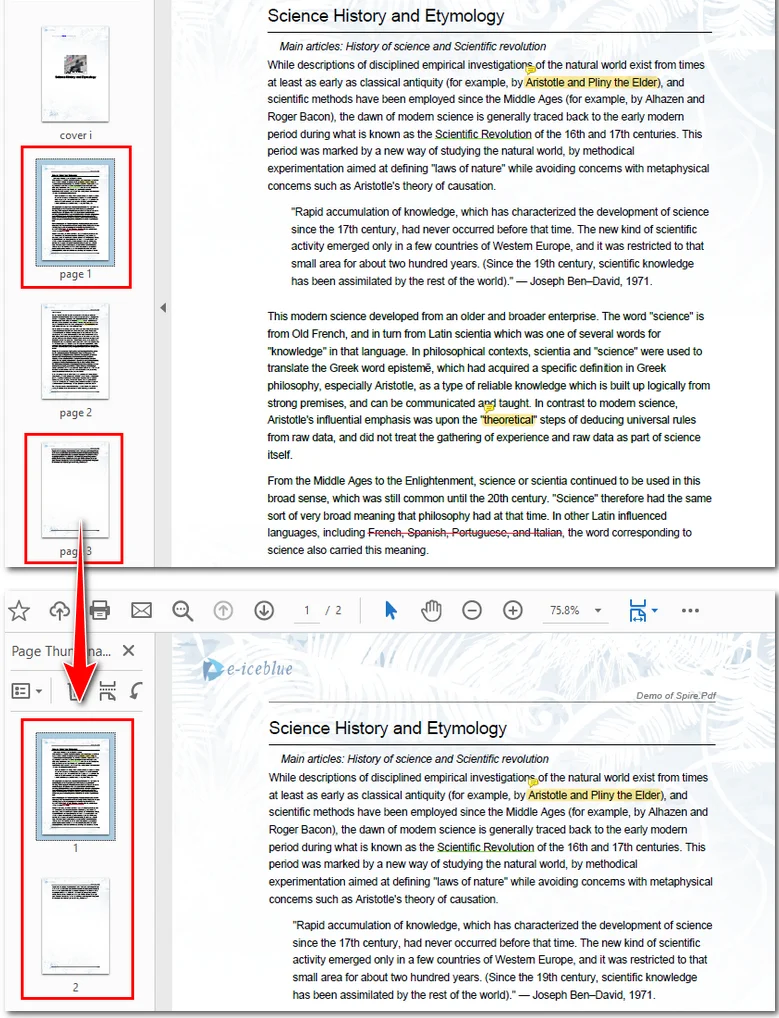
Si vous devez extraire un grand nombre de pages, une autre option consiste à supprimer les pages inutiles à la place. Cette approche peut être tout aussi efficace lorsque vous travaillez avec des PDF en Python.
La conclusion
Que vous extrayiez une seule page ou que vous gériez plusieurs PDF, choisir le bon outil peut vous faire gagner beaucoup de temps. Si vous préférez une solution plus flexible et basée sur le code, Free Spire.PDF for Python offre un moyen fiable d'extraire, de modifier ou d'organiser efficacement les fichiers PDF. Vous pouvez le télécharger gratuitement et explorer plus de fonctionnalités sur le site officiel.
LIRE AUSSI