Nell'era digitale di oggi, estrarre testo da immagini o PDF scansionati è un requisito comune per varie applicazioni. Il riconoscimento ottico dei caratteri (OCR) è una tecnologia che consente ai computer di riconoscere ed estrarre testo da tali documenti. Con esso, possiamo convertire facilmente immagini e PDF scansionati in formati modificabili e ricercabili, semplificando l'elaborazione e l'analisi del contenuto testuale. In questo blog esploreremo come farlo estrai testo da immagini e PDF scansionati con OCR in C#.
- Estrai testo da immagini in C#
- Estrai testo da immagini con coordinate in C#
- Estrai testo da PDF scansionati in C#
Librerie C# per l'estrazione di testo da immagini e PDF scansionati
Per estrarre il testo dalle immagini, utilizzeremo Spire.OCR for .NET biblioteca. Spire.OCR for .NET è una potente libreria progettata specificamente per estrarre testo da immagini nelle applicazioni .NET. Supporta vari formati di immagine come BMP, JPG, PNG, TIFF e GIF.
Ecco i passaggi per installare Spire.OCR for .NET:
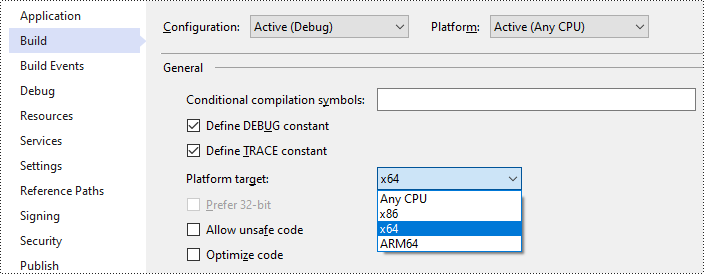
- Modifica la piattaforma di destinazione della tua soluzione in x64.
- Installa Spire.OCR da NuGet eseguendo il comando seguente nella console di gestione pacchetti NuGet:
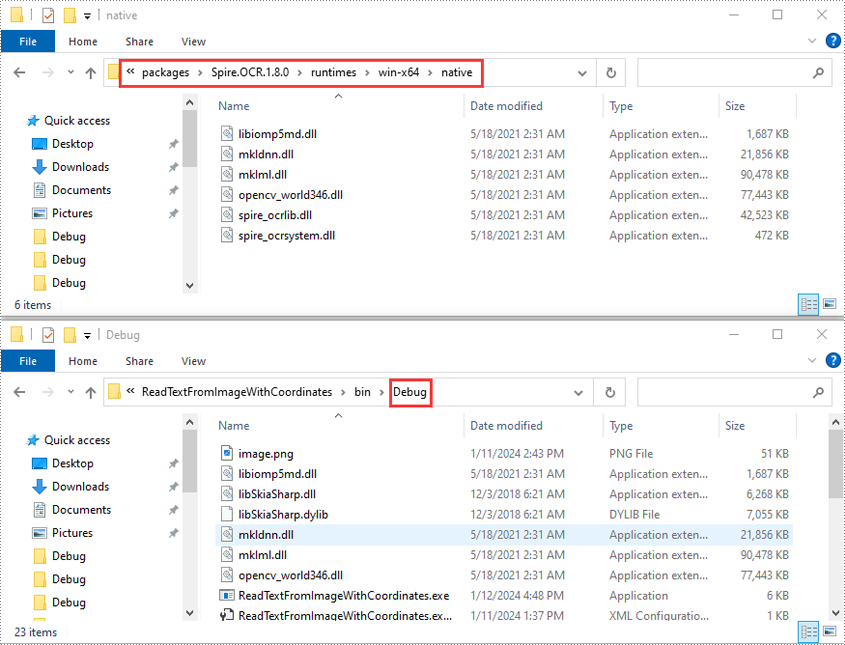
- Apri la cartella della soluzione e vai alla directory "packages\Spire.OCR.1.8.0\runtimes\win-x64\native". Copia i file DLL da questa directory e incollali nella cartella "Debug" della tua soluzione.
Install-Package Spire.OCR
Per estrarre il testo dai PDF scansionati, dobbiamo prima convertire il documento PDF in immagini. Per questa attività utilizzeremo la libreria Spire.PDF for .NET Una volta completata la conversione, possiamo utilizzare Spire.OCR per estrarre il testo dalle immagini risultanti.
È possibile installare Spire.PDF for .NET da NuGet eseguendo il comando seguente nella console di gestione pacchetti NuGet:
Install-Package Spire.PDF
Estrai testo da immagini in C#
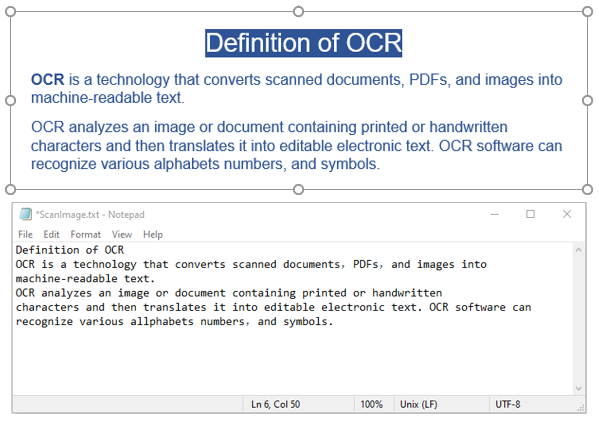
Spire.OCR fornisce il metodo OcrScanner.Scan() per riconoscere il testo da un'immagine. Dopo il riconoscimento è possibile ottenere il testo riconosciuto utilizzando la proprietà OcrScanner.Text.
Ecco i passaggi principali per riconoscere il testo da un'immagine utilizzando Spire.OCR:
- Crea un'istanza della classe OcrScanner.
- Riconoscere il testo da un'immagine utilizzando il metodo OcrScanner.Scan().
- Ottieni il testo riconosciuto dall'oggetto OcrScanner utilizzando la proprietà OcrScanner.Text.
- Salvare il testo in un file di testo.
Ecco un esempio di codice che mostra come riconoscere il testo da un'immagine e salvare il risultato in un file di testo:
- C#
using Spire.OCR;
using System.IO;
namespace ReadTextFromImage
{
internal class Program
{
static void Main(string[] args)
{
//Specify the path of the input image file
string imageFilePath = "Image.png";
//Specify the path of the output text file
string outputFilePath = "ScanImage.txt";
//Call the ScanTextFromImage method to scan text from an image
string scannedText = ScanTextFromImage(imageFilePath);
//Write the text to the specified file
File.WriteAllText(outputFilePath, scannedText);
}
public static string ScanTextFromImage(string imageFilePath)
{
//Instantiate an OcrScanner object
using (OcrScanner ocrScanner = new OcrScanner())
{
//Scan text from the image
ocrScanner.Scan(imageFilePath);
//Get the recognized text from the OcrScanner object
IOCRText text = ocrScanner.Text;
//Return the text
return text.ToString();
}
}
}
}
Estrai testo da immagini con coordinate in C#
L'estrazione delle coordinate è utile quando è necessario identificare la posizione esatta di elementi di testo specifici nell'immagine. Con Spire.OCR puoi recuperare il testo riconosciuto in blocchi o righe. Per ogni blocco, puoi ottenere informazioni dettagliate sulla posizione, comprese le coordinate xey, nonché la larghezza e l'altezza.
Ecco i passaggi principali per estrarre il testo insieme alle informazioni sulla posizione da un'immagine utilizzando Spire.OCR:
- Crea un'istanza della classe OcrScanner.
- Riconoscere il testo da un'immagine utilizzando il metodo OcrScanner.Scan().
- Ottieni il testo riconosciuto dall'oggetto OcrScanner utilizzando la proprietà OcrScanner.TextOcrScanner.Text.
- Scorrere i blocchi di testo del testo riconosciuto.
- Per ogni blocco, ottieni le informazioni sul testo e sulla posizione utilizzando le proprietà IOCRTextBlock.Text e IOCRTextBlock.Box, quindi aggiungi il risultato a un elenco di stringhe.
- Salva il contenuto dell'elenco in un file di testo.
Ecco un esempio di codice che mostra come riconoscere il testo insieme alle informazioni sulla posizione da un'immagine e salvare il risultato in un file di testo:
- C#
using Spire.OCR;
using System.Collections.Generic;
using System.IO;
namespace ReadTextFromImageWithCoordinates
{
internal class Program
{
static void Main(string[] args)
{
//Specify the path of the input image file
string imagePath = "Image.png";
//Specify the path of the output text file
string outputFile = "ScanImageWithCoordinates.txt";
//Call the ScanTextFromImageWithCoordinates method to extract text and its area information from the image
List<string> extractedText = ScanTextFromImageWithCoordinates(imagePath);
//Write the result to the specified file
File.WriteAllLines(outputFile, extractedText);
}
//Retrieve the text blocks along with their location information (x, y, width, height) from an image
public static List<string> ScanTextFromImageWithCoordinates(string imageFilePath)
{
//Create a list
List<string> extractedText = new List<string>();
//Instantiate an OcrScanner object
using (OcrScanner ocrScanner = new OcrScanner())
{
//Scan text from the image
ocrScanner.Scan(imageFilePath);
//Get the scanned text
IOCRText text = ocrScanner.Text;
//Iterate through each text block
foreach (IOCRTextBlock block in text.Blocks)
{
//Append the text of each block and its location information to the list
extractedText.Add($"Text: {block.Text}\nRectangular Area: {block.Box}");
}
}
return extractedText;
}
}
}
Estrai testo da PDF scansionati in C#
Per estrarre il testo dai PDF scansionati, dobbiamo seguire un processo in due passaggi. Innanzitutto, utilizziamo Spire.PDF per convertire i PDF scansionati in immagini. Quindi, utilizziamo Spire.OCR per estrarre il testo da quelle immagini.
Ecco i passaggi principali per riconoscere il testo da un PDF scansionato utilizzando Spire.PDF e Spire.OCR:
- Crea un'istanza della classe PdfDocument.
- Carica un documento PDF utilizzando il metodo PdfDocument.LoadFromFile().
- Scorri le pagine del documento PDF.
- Converti ogni pagina in un oggetto Immagine utilizzando il metodo PdfDocument.SaveAsImage().
- Salva l'oggetto Immagine in un flusso utilizzando il metodo Image.Save().
- Crea un'istanza della classe OcrScanner.
- Riconoscere il testo dal flusso utilizzando il metodo OcrScanner.Scan().
- Ottieni il testo riconosciuto utilizzando la proprietà IOCRText.Text e aggiungilo a un elenco di stringhe.
- Salva il contenuto dell'elenco in un file di testo.
Ecco un esempio di codice che mostra come riconoscere il testo da un PDF scansionato e salvare il risultato in un file di testo:
- C#
using Spire.OCR;
using Spire.Pdf;
using System.Collections.Generic;
using System.Drawing;
using System.Drawing.Imaging;
using System.IO;
namespace ReadTextFromScannedPDF
{
internal class Program
{
static void Main(string[] args)
{
//Specify the path of the scanned PDF file
string pdfFilePath = "Sample.pdf";
//Specify the path of the output text file
string outputFilePath = "ScanPDF.txt";
//Extract text from the scanned PDF
List<string> extractedText = ExtractTextFromScannedPDF(pdfFilePath);
//Write the text to the specified file
File.WriteAllLines(outputFilePath, extractedText);
}
//Extract text from a scanned PDF
public static List<string> ExtractTextFromScannedPDF(string pdfFilePath)
{
//Create a list to store the extracted text
List<string> extractedText = new List<string>();
//Create an instance of the PdfDocument class
using (PdfDocument document = new PdfDocument())
{
//Load the PDF document
document.LoadFromFile(pdfFilePath);
//Iterate through each page of the document
for (int pageIndex = 0; pageIndex < document.Pages.Count; pageIndex++)
{
//Convert the page to an image
using (Image image = document.SaveAsImage(pageIndex, 300, 300))
{
//Create a memory stream to hold the image data
using (MemoryStream stream = new MemoryStream())
{
//Save the image to the memory stream in PNG format
image.Save(stream, ImageFormat.Png);
stream.Position = 0;
//Scan the text from the image and add it to the list
string text = ScanTextFromImageStream(stream);
extractedText.Add(text);
}
}
}
}
//Return the list
return extractedText;
}
//Scan text from an image stream
public static string ScanTextFromImageStream(Stream stream)
{
//Create an instance of the OcrScanner class
using (OcrScanner ocrScanner = new OcrScanner())
{
//Scan the text from the image stream in PNG format
ocrScanner.Scan(stream, OCRImageFormat.Png);
IOCRText text = ocrScanner.Text;
//Return the text
return text.ToString();
}
}
}
}
Ottieni una licenza gratuita
Per sperimentare appieno le funzionalità di Spire.OCR for .NET o Spire.PDF for .NET senza limitazioni di valutazione, puoi richiedere una licenza di prova gratuita di 30 giorni.
Conclusione
Questo post del blog ha dimostrato come estrarre testo da immagini e documenti PDF scansionati in C#. In caso di domande, non esitate a pubblicarle sul nostro forum o inviarle al nostro team di supporto via e-mail.