
보관하고 싶은 웹페이지를 발견했지만 직접 복사하거나 저장하는 것이 허용되지 않는 경우가 있습니다. 이러한 경우 웹페이지를 PDF로 저장하는 것이 좋은 해결책입니다. 언제든지 오프라인으로 페이지에 액세스하고 나중에 콘텐츠를 편집하거나 강조 표시할 수도 있습니다. 이 가이드에서는 내장된 브라우저 기능, 온라인 도구 및 코드 기반 방법을 사용하여 웹페이지를 PDF로 다운로드하는 세 가지 쉬운 방법을 살펴봅니다.
기본 제공 기능으로 웹페이지를 PDF로 다운로드
웹페이지를 PDF로 저장해야 할 때 대부분의 사람들은 가장 먼저 브라우저의 내장 다운로드 기능을 사용합니다. 이것이 작업을 완료하는 가장 빠르고 편리한 방법입니다. 그러나 운영 체제에 따라 단계가 약간 다를 수 있습니다. 가장 일반적인 두 플랫폼인 Windows와 macOS에서 웹페이지를 PDF로 다운로드하는 방법을 살펴보겠습니다.
Windows에서 웹페이지를 PDF로 다운로드
- Ctrl + P를 눌러 인쇄 대화상자를 엽니다.
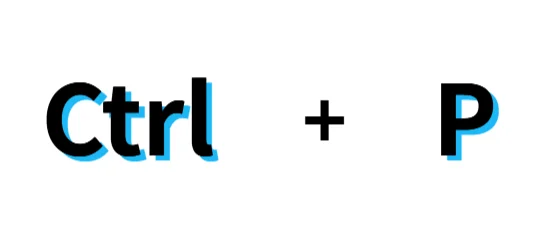
- 프린터 드롭다운 목록에서 Microsoft Print to PDF 또는 PDF로 저장을 선택합니다(이름은 브라우저에 따라 다를 수 있음).
- 인쇄를 클릭하여 계속합니다.
- 파일 대화상자가 나타나면 대상 폴더를 선택하고 저장을 클릭합니다.
- Windows 버전에 Microsoft Print to PDF가 포함되어 있지 않은 경우에도 Chrome의 내장 PDF로 저장 옵션을 사용하여 웹페이지를 PDF로 다운로드할 수 있습니다.
macOS에서 웹페이지를 PDF로 다운로드
- Command + P를 눌러 인쇄 창을 엽니다.

- 왼쪽 하단에서 PDF 드롭다운 메뉴를 클릭하고 PDF로 저장을 선택합니다.
- Chrome에서는 저장하기 전에 미리보기에서 PDF 열기를 선택하여 볼 수도 있습니다.
- 메시지가 표시되면 파일을 저장할 위치를 선택하고 확인합니다.
온라인 도구를 사용하여 웹페이지를 PDF로 다운로드하는 방법
컴퓨터의 내장 단축키 외에도 온라인 도구를 사용하여 웹페이지를 PDF로 저장할 수도 있습니다. 이러한 도구는 설치가 필요 없고 모든 장치(컴퓨터, 노트북, 휴대폰)에서 작동하며 다양한 유형의 웹 콘텐츠를 빠르게 처리할 수 있어 편리합니다. 단계는 간단합니다. 브라우저에서 "HTML to PDF" 또는 "웹페이지를 PDF로 다운로드"를 검색하기만 하면 됩니다. 아래 예에서는 이 목적을 위해 가장 널리 사용되는 도구 중 하나인 iLovePDF를 사용하겠습니다.
- iLovePDF 공식 웹사이트로 이동하여 HTML to PDF 도구를 찾으십시오.
-
HTML 추가 버튼을 클릭한 다음 팝업 창에 저장하려는 웹페이지의 URL을 입력합니다. 모든 것이 올바른지 확인한 후 오른쪽 하단의 빨간색 추가 버튼을 클릭합니다.
- 다음으로, 필요에 따라 오른쪽 패널에서 설정을 조정한 다음 PDF로 변환을 클릭합니다. 변환이 완료되면 PDF 파일을 컴퓨터에 다운로드할 수 있습니다.
코드를 사용하여 웹페이지를 PDF로 다운로드하는 방법
위에서 언급한 두 가지 일반적인 방법 외에도 코드를 사용하여 이 작업을 수행할 수도 있습니다. 이는 개발자를 위해 설계된 보다 유연한 옵션입니다. 이 접근 방식은 일괄 다운로드, 전체 오프라인 작업, 대규모 작업을 위한 더 나은 자동화와 같이 이전 방법에서는 제공하지 않았던 몇 가지 이점을 제공합니다.
이 튜토리얼에서는 Spire.Doc for Python을 사용하여 웹페이지를 PDF로 다운로드하는 방법을 보여줍니다. 전문적인 Python 라이브러리로서 개발자는 간단한 문서 형식 변환부터 내용 편집 및 암호화와 같은 고급 작업까지 모든 것을 처리할 수 있습니다.
Python에서 전체 웹페이지를 PDF로 다운로드하는 단계:
-
pip install spire.doc명령을 사용하여 Spire.Doc을 설치합니다. 웹페이지 콘텐츠를 가져오는 데 사용되는 라이브러리인 requests도 설치해야 합니다. -
필요한 모듈 가져오기:
from spire.doc import *
from spire.doc.common import *
import requests
- 웹페이지 URL을 지정하고 HTML에서 콘텐츠 가져오기:
# 웹페이지에서 HTML 콘텐츠 가져오기
url = "/Tutorials/Python/Spire.Doc-for-Python/Program-Guide/Conversion/Python-Convert-HTML-to-PDF.html"
html = requests.get(url).text
- HTML 콘텐츠를 Word 문서에 쓰기:
# HTML을 Word 문서에 쓰기
doc = Document()
section = doc.AddSection()
paragraph = section.AddParagraph()
paragraph.AppendHTML(html)
- 마지막으로 문서를 PDF 파일로 저장합니다:
# 문서를 PDF로 저장
doc.SaveToFile("E:/Administrator/Python1/webpage_to_pdf11.pdf", FileFormat.PDF)
다음은 전체 코드 예제입니다:
from spire.doc import *
from spire.doc.common import *
import requests
# 웹에서 HTML 가져오기
url = "/Tutorials/Python/Spire.Doc-for-Python/Program-Guide/Conversion/Python-Convert-HTML-to-PDF.html"
html = requests.get(url).text
# 문서를 HTML로 쓰기
doc = Document()
section = doc.AddSection()
paragraph = section.AddParagraph()
paragraph.AppendHTML(html)
# 문서를 PDF 파일로 저장
doc.SaveToFile("E:/Administrator/Python1/webpage_to_pdf11.pdf", FileFormat.PDF)
doc.Close()
다음은 결과 PDF 파일의 미리보기입니다: 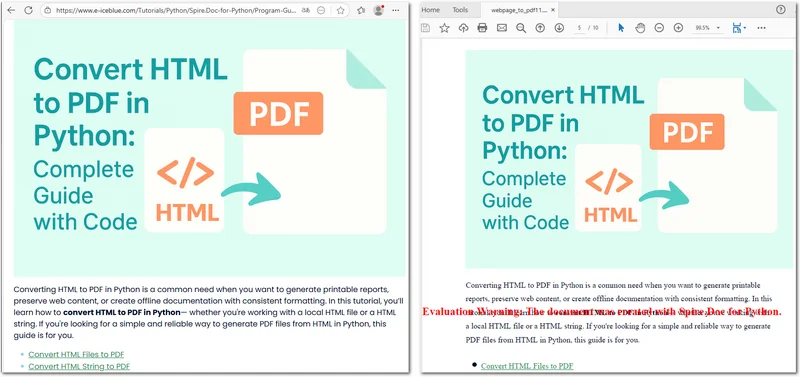
웹페이지를 HTML 형식으로 저장하는 경우 Spire.Doc은 Document.SaveToFile() 메서드를 사용하여 쉽게 PDF로 변환할 수도 있습니다.
결론
이 기사에서는 웹페이지를 PDF로 다운로드하는 세 가지 다른 방법을 소개했습니다. 필요에 따라 내장 기능, 온라인 도구 또는 Spire.Doc Python 라이브러리 사용 등 자신에게 가장 적합한 방법을 선택할 수 있습니다. 더 많은 고급 PDF 기능을 탐색하고 싶다면 Spire.Doc의 30일 무료 라이선스를 사용하여 잠재력을 최대한 경험해 보십시오.
함께 읽기