많은 사람들이 PDF에서 페이지를 추출하는 기능이 유료라는 사실을 알게 되기 위해 Adobe Acrobat을 엽니다. 좋은 소식은 비용을 지불할 필요가 없다는 것입니다. 계약서에서 주요 페이지를 보관해야 하거나 보고서에서 섹션을 추출해야 하는 경우, 이 가이드는 단 몇 번의 클릭만으로 PDF에서 페이지를 추출하는 세 가지 무료하고 쉬운 방법을 보여줍니다.
Google Chrome으로 PDF에서 페이지 추출하는 방법
추가 소프트웨어가 필요 없습니다. Google Chrome만으로도 온라인에서 PDF의 특정 페이지를 추출할 수 있습니다. 내장된 인쇄 기능을 사용하여 모든 페이지, 홀수 또는 짝수 페이지만 저장하거나 원하는 사용자 지정 페이지 범위를 선택할 수 있습니다. 보관하려는 페이지를 선택하고 새 PDF 파일로 저장하기만 하면 됩니다. Google Chrome을 사용하여 PDF에서 페이지를 추출하는 방법은 다음과 같습니다.
- 페이지를 추출하려는 PDF 파일을 찾아 마우스 오른쪽 버튼을 클릭하여 Google Chrome에서 엽니다.
- 오른쪽 상단의 인쇄 버튼을 클릭하고 대상 프린터를 PDF로 저장으로 변경합니다.
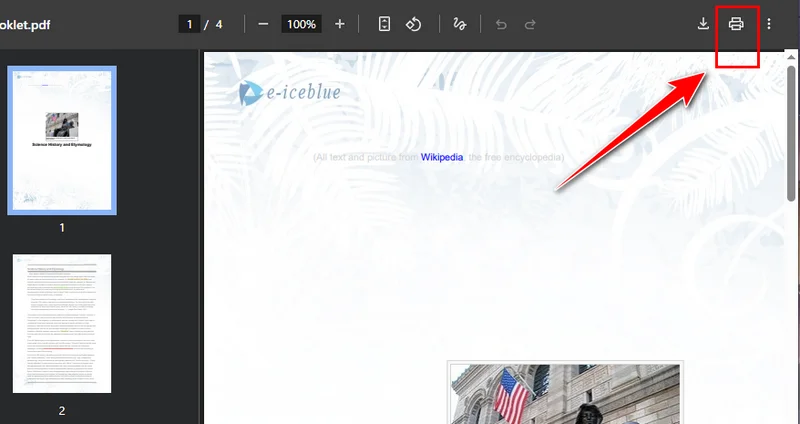
- 보관할 페이지를 선택한 다음 저장을 클릭합니다. Chrome이 새 PDF를 장치에 자동으로 다운로드합니다.
장점
- 타사 소프트웨어를 설치할 필요가 없습니다.
- 1-2 페이지를 빠르게 추출하는 데 이상적입니다.
- 부드러운 경험과 폭넓은 접근성 (거의 모든 사용자가 Chrome을 사용함).
단점
- 연속되지 않은 많은 수의 페이지를 추출하는 데 적합하지 않습니다.
- 출력 옵션이 매우 기본적입니다.
온라인 도구로 PDF의 한 페이지를 빠르게 저장하는 방법
PDF에서 페이지를 추출하는 방법은 여러 가지가 있습니다. Chrome의 내장 기능을 사용하는 것 외에도 온라인 도구를 사용하여 PDF 문서를 분할하고 필요한 페이지를 저장할 수도 있습니다. 이러한 도구는 웹 기반이므로 컴퓨터와 모바일 장치 모두에서 작동하며 아무것도 다운로드하거나 가입할 필요가 없습니다. 브라우저에서 "PDF에서 페이지를 추출하는 방법"을 검색하기만 하면 다양한 옵션을 찾을 수 있습니다. 이 가이드에서는 Smallpdf를 사용하여 프로세스를 시연하지만 걱정하지 마십시오. 대부분의 온라인 도구는 매우 유사한 방식으로 작동합니다.
- Smallpdf의 PDF 페이지 추출 페이지로 이동합니다.
- PDF 파일을 도구로 끌어다 놓으면 자동으로 처리되어 모든 페이지가 표시됩니다.
- 추출할 페이지를 선택한 다음 마침을 클릭합니다. 페이지를 단일 PDF 또는 별도의 PDF 파일로 내보내도록 선택할 수 있습니다.
- 추출이 완료되면 다운로드 버튼을 클릭하여 결과 PDF를 장치에 저장합니다.
장점
- 다운로드나 설치 없이 브라우저에서 직접 사용할 수 있습니다.
- 단일 페이지, 연속 페이지 또는 비연속 페이지 추출을 지원합니다.
- 직관적인 인터페이스 — 끌어다 놓기만 하면 되므로 초보자도 쉽게 사용할 수 있습니다.
- 브라우저와 인터넷 연결이 있는 모든 장치에서 작동하며 호환성이 높습니다.
단점
- 인터넷 연결이 필요하며 오프라인에서는 사용할 수 없습니다.
- 일부 도구는 무료 사용자의 파일 크기를 제한합니다.
- 파일이 서버에 업로드되므로 민감한 콘텐츠에 주의하십시오.
- 일괄 처리나 워터마크 없는 다운로드와 같은 고급 기능은 유료일 수 있습니다.
Python을 사용하여 PDF에서 무료로 페이지를 추출하는 방법
PDF를 다룰 때 Chrome과 온라인 도구 모두 한 번에 하나의 파일만 처리할 수 있다는 한 가지 제한 사항을 공유합니다. 여러 PDF를 처리하는 경우 더 빠르고 전문적인 솔루션이 있습니다. 바로 Free Spire.PDF for Python입니다.
이 강력한 라이브러리는 페이지 추출, 형식 변환, 콘텐츠 편집 등 다양한 PDF 기능을 제공합니다. Free Spire.PDF를 사용하면 PdfDocument.InsertPage() 메서드를 사용하여 원본 PDF에서 새 문서로 페이지를 추가하여 특정 페이지를 쉽게 추출할 수 있습니다.
아래 샘플 코드는 PDF에서 2번째와 4번째 페이지를 추출하여 새 파일로 병합하는 방법을 보여줍니다.
from spire.pdf import PdfDocument
# Load a PDF file
source_pdf = PdfDocument()
source_pdf.LoadFromFile("/input/Booklet.pdf")
# Create a new PdfDocument instance
new_pdf = PdfDocument()
# Extract page 2 and page 4
new_pdf.InsertPage(source_pdf, 1)
new_pdf.InsertPage(source_pdf, 3)
# Save the extracted pages
new_pdf.SaveToFile("/output/extracted_pages.pdf")
new_pdf.Close()
결과 파일의 미리보기는 다음과 같습니다. 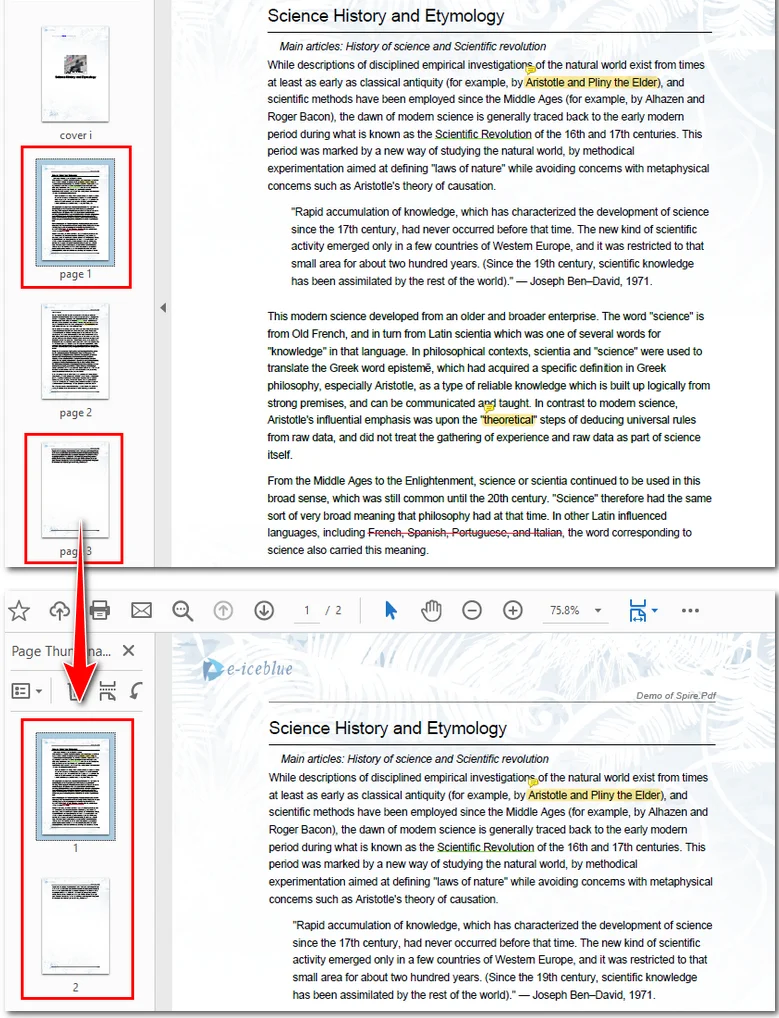
많은 수의 페이지를 추출해야 하는 경우 다른 옵션은 대신 불필요한 페이지를 삭제하는 것입니다. 이 접근 방식은 Python에서 PDF로 작업할 때 똑같이 효과적일 수 있습니다.
결론
단일 페이지를 추출하든 여러 PDF를 관리하든 올바른 도구를 선택하면 많은 시간을 절약할 수 있습니다. 보다 유연하고 코드 기반 솔루션을 선호하는 경우 Free Spire.PDF for Python은 PDF 파일을 효율적으로 추출, 편집 또는 구성할 수 있는 안정적인 방법을 제공합니다. 무료로 다운로드하고 공식 웹사이트에서 더 많은 기능을 탐색할 수 있습니다.
함께 읽기