Обзор
Извлечение HTML-таблиц в Excel является частым требованием для аналитиков данных, исследователей, разработчиков и бизнес-профессионалов, которые часто работают со структурированными веб-данными. HTML-таблицы часто содержат ценную информацию, такую как финансовые отчеты, каталоги продуктов, результаты исследований или статистику производительности. Однако перенос этих данных в Excel в чистом и удобном для использования формате может быть сложной задачей, особенно при работе со сложными таблицами, которые включают объединенные ячейки (rowspan, colspan), вложенные заголовки или большие наборы данных.
К счастью, существует несколько подходов к преобразованию HTML-таблиц в файлы Excel. Эти методы варьируются от быстрых ручных действий копирования-вставки, подходящих для небольших задач, до полностью автоматизированных скриптов с использованием VBA или Python для крупномасштабных или повторяющихся задач.
В этой статье мы рассмотрим четыре эффективных метода извлечения HTML-таблиц в Excel:
- Ручное копирование и вставка (самый простой метод)
- Встроенная функция Excel «Из Интернета»
- Макрос VBA (автоматизация Excel)
- Python (BeautifulSoup + Spire.XLS)
Наконец, мы сравним эти подходы в сводной таблице, чтобы помочь вам выбрать лучший метод в зависимости от вашего варианта использования.
Ручное копирование и вставка (самый простой метод)
Для небольших, одноразовых извлечений самым простым вариантом является использование копирования и вставки непосредственно из браузера в Excel.

Шаги:
- Откройте HTML-страницу в браузере (например, Chrome, Edge или Firefox).
- Выделите таблицу, которую хотите извлечь.
- Скопируйте ее с помощью Ctrl+C (или щелкните правой кнопкой мыши → Копировать).
- Откройте Excel и вставьте с помощью Ctrl+V.
Плюсы:
- Чрезвычайно просто — не требуется настройка или программирование.
- Мгновенно работает для небольших, чистых таблиц.
Минусы:
- Ручной процесс — утомительный и неэффективный для частых или больших наборов данных.
- Не всегда сохраняет объединенные ячейки или форматирование.
- Не может надежно обрабатывать динамические (отрисованные с помощью JavaScript) таблицы.
Когда использовать: лучше всего подходит для небольших таблиц, сбора данных по запросу или быстрого тестирования.
Встроенная функция Excel «Из Интернета»
Excel включает мощный инструмент «Получить и преобразовать данные» (ранее Power Query), который позволяет пользователям извлекать таблицы непосредственно с веб-страницы.
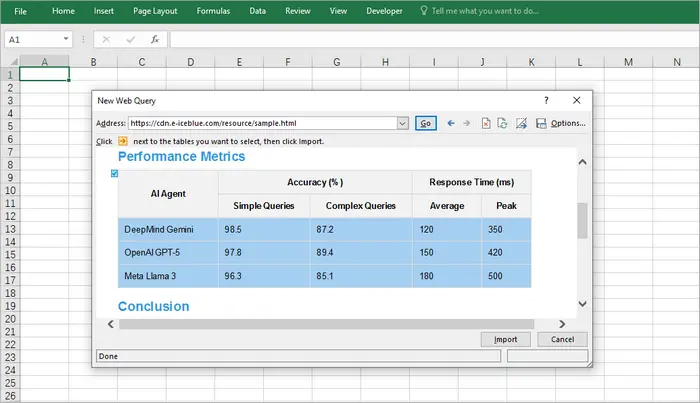
Шаги:
- Откройте Excel.
- Перейдите в Данные → Из Интернета.
- Введите URL-адрес веб-страницы, содержащей таблицу.
- Excel отобразит обнаруженные таблицы; выберите ту, которая вам нужна.
- Загрузите данные на свой рабочий лист.
Плюсы:
- Прямая интеграция в Excel — не требуются внешние инструменты.
- Хорошо работает со структурированными HTML-таблицами.
- Поддерживает обновление — может повторно извлекать обновленные данные из того же источника.
Минусы:
- Ограниченная поддержка динамического или отрисованного с помощью JavaScript контента.
- Иногда не удается обнаружить сложные таблицы.
- Требуется доступ в Интернет и действительный URL-адрес (не для локальных HTML-файлов, если они не импортированы вручную).
Когда использовать: лучше всего для аналитиков, извлекающих живые, структурированные данные с веб-сайтов, которые регулярно обновляются.
Макрос VBA (автоматизация Excel)
Для пользователей, которые часто извлекают HTML-таблицы и хотят большего контроля, VBA (Visual Basic for Applications) предоставляет отличное решение. VBA позволяет извлекать таблицы с URL-адреса и правильно обрабатывать объединенные ячейки, с чем не справляется простое копирование-вставка.
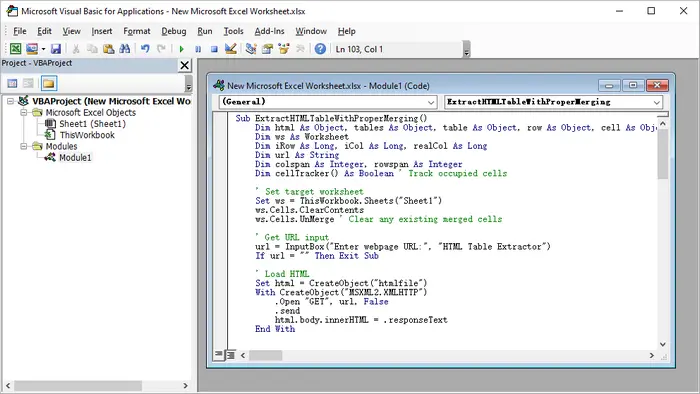
Шаги:
- Запустите Microsoft Excel.
- Нажмите Alt + F11, чтобы открыть редактор VBA.
- Щелкните правой кнопкой мыши в проводнике проекта → Вставить → Модуль.
- Вставьте предоставленный код VBA.
- Закройте редактор VBA.
- Нажмите Alt + F8, выберите имя макроса и нажмите Выполнить.
Пример кода VBA:
Sub ExtractHTMLTableWithProperMerging()
Dim html As Object, tables As Object, table As Object, row As Object, cell As Object
Dim ws As Worksheet
Dim iRow As Long, iCol As Long, realCol As Long
Dim url As String
Dim colspan As Integer, rowspan As Integer
Dim cellTracker() As Boolean ' Отслеживание занятых ячеек
' Установить целевой рабочий лист
Set ws = ThisWorkbook.Sheets("Sheet1")
ws.Cells.ClearContents
ws.Cells.UnMerge ' Очистить все существующие объединенные ячейки
' Получить ввод URL
url = InputBox("Введите URL веб-страницы:", "Извлечение HTML-таблицы")
If url = "" Then Exit Sub
' Загрузить HTML
Set html = CreateObject("htmlfile")
With CreateObject("MSXML2.XMLHTTP")
.Open "GET", url, False
.send
html.body.innerHTML = .responseText
End With
' Получить первую таблицу (измените индекс при необходимости)
Set tables = html.getElementsByTagName("table")
If tables.Length = 0 Then
MsgBox "Таблицы не найдены!", vbExclamation
Exit Sub
End If
Set table = tables(0)
' Инициализировать массив отслеживания ячеек
Dim maxRows As Long, maxCols As Long
maxRows = table.Rows.Length
maxCols = 0
For Each row In table.Rows
If row.Cells.Length > maxCols Then maxCols = row.Cells.Length
Next
ReDim cellTracker(1 To maxRows, 1 To maxCols)
' Обработать таблицу
iRow = 1
For Each row In table.Rows
realCol = 1 ' Отслеживать фактическую позицию столбца с учетом rowspan
' Найти первый доступный столбец в этой строке
While realCol <= maxCols And cellTracker(iRow, realCol)
realCol = realCol + 1
Wend
iCol = 1 ' Отслеживать логическую позицию столбца
For Each cell In row.Cells
' Получить атрибуты объединения
colspan = 1
rowspan = 1
On Error Resume Next ' В случае, если атрибуты не существуют
colspan = cell.colspan
rowspan = cell.rowspan
On Error GoTo 0
' Пропустить уже занятые ячейки (из rowspan выше)
While realCol <= maxCols And cellTracker(iRow, realCol)
realCol = realCol + 1
Wend
If realCol > maxCols Then Exit For
' Записать значение
ws.Cells(iRow, realCol).Value = cell.innerText
' Отметить все ячейки, которые будут заняты этой ячейкой
Dim r As Long, c As Long
For r = iRow To iRow + rowspan - 1
For c = realCol To realCol + colspan - 1
If r <= maxRows And c <= maxCols Then
cellTracker(r, c) = True
End If
Next c
Next r
' Объединить ячейки при необходимости
If colspan > 1 Or rowspan > 1 Then
With ws.Range(ws.Cells(iRow, realCol), ws.Cells(iRow + rowspan - 1, realCol + colspan - 1))
.Merge
.HorizontalAlignment = xlCenter
.VerticalAlignment = xlCenter
End With
End If
realCol = realCol + colspan
iCol = iCol + 1
Next cell
iRow = iRow + 1
Next row
' Форматирование
ws.UsedRange.Columns.AutoFit
ws.UsedRange.Borders.Weight = xlThin
MsgBox "Таблица извлечена с правильным объединением!", vbInformation
End Sub
Плюсы:
- Работает полностью в Excel — не требуются внешние инструменты.
- Обрабатывает сложные таблицы с объединенными ячейками.
- Может быть настроен для нескольких таблиц или запланированного выполнения.
Минусы:
- Настройка требует знания VBA.
- Не может обрабатывать данные, отрисованные с помощью JavaScript, без дополнительных шагов.
- Работает только в настольной версии Excel (не в Excel Online).
Когда использовать: идеально подходит для пользователей, которые регулярно извлекают похожие таблицы и хотят получить решение в один клик.
Python (BeautifulSoup и Spire.XLS)
Для разработчиков или опытных пользователей Python предоставляет наиболее гибкое, масштабируемое и автоматизированное решение. С помощью таких библиотек, как BeautifulSoup для парсинга HTML и Spire.XLS for Python для работы с Excel, вы можете программно извлекать, очищать и экспортировать таблицы с полным контролем.
Шаги:
- Установите Python (рекомендуется 3.8+).
- Создайте новый проект в вашей IDE (например, VS Code, PyCharm).
- Установите зависимости:
pip install requests beautifulsoup4 spire.xls
- Скопируйте и запустите следующий скрипт.
Код на Python:
import requests
from bs4 import BeautifulSoup
from spire.xls import Workbook, ExcelVersion
# Получить строку HTML с URL-адреса
response = requests.get("https://cdn.e-iceblue.com/resource/sample.html")
html = response.text
# Разобрать HTML
soup = BeautifulSoup(html, "html.parser")
table = soup.find("table") # Получить первую таблицу
# Инициализировать Excel
workbook = Workbook()
sheet = workbook.Worksheets[0]
# Отслеживать объединенные ячейки, чтобы пропустить их позже
skip_cells = set()
# Перебрать строки и ячейки HTML
for row_idx, row in enumerate(table.find_all("tr")):
col_idx = 1 # Столбцы Excel начинаются с 1
for cell in row.find_all(["th", "td"]):
# Пропустить уже объединенные ячейки
while (row_idx + 1, col_idx) in skip_cells:
col_idx += 1
# Получить значения colspan/rowspan (по умолчанию 1, если отсутствуют)
colspan = int(cell.get("colspan", 1))
rowspan = int(cell.get("rowspan", 1))
# Записать значение ячейки в Excel
sheet.Range[row_idx + 1, col_idx].Text = cell.get_text(strip=True)
# Объединить ячейки, если colspan/rowspan > 1
if colspan > 1 or rowspan > 1:
end_row = row_idx + rowspan
end_col = col_idx + colspan - 1
sheet.Range[row_idx + 1, col_idx, end_row, end_col].Merge()
# Отметить объединенные ячейки для пропуска
for r in range(row_idx + 1, end_row + 1):
for c in range(col_idx, end_col + 1):
if r != row_idx + 1 or c != col_idx: # Пропустить основную ячейку
skip_cells.add((r, c))
col_idx += colspan
# Автоматически подогнать ширину столбцов во всем используемом диапазоне
sheet.AllocatedRange.AutoFitColumns()
# Сохранить в Excel
workbook.SaveToFile("TableToExcel.xlsx", ExcelVersion.Version2016)
workbook.Dispose()
Плюсы:
- Полный контроль — можно анализировать, очищать и преобразовывать данные.
- Правильно обрабатывает объединенные ячейки.
- Легко масштабируется на несколько таблиц или веб-сайтов.
- Автоматизируется для запланированных задач или пакетных заданий.
Минусы:
- Требуется установка Python и базовые знания программирования.
- Больше настроек, чем у встроенных решений Excel.
- Внешние зависимости (BeautifulSoup, Spire.XLS).
Когда использовать: лучше всего для разработчиков или продвинутых пользователей, регулярно извлекающих большие или сложные таблицы.
Вывод:
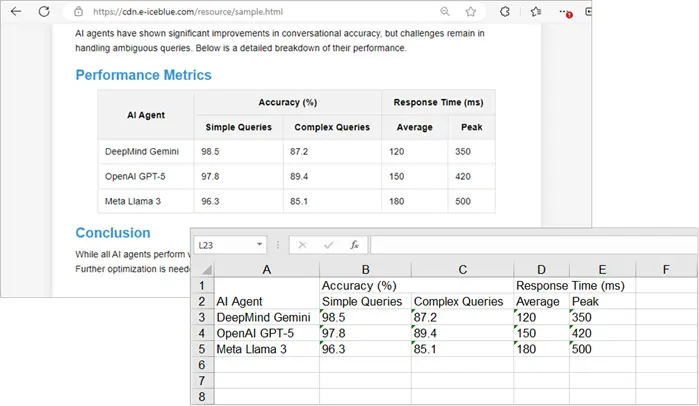
Чтобы улучшить визуальную привлекательность созданного листа Excel на Python, вы можете применять стили к ячейкам или рабочим листам в Excel.
Сводная таблица: лучший метод в зависимости от варианта использования
| Метод | Лучше всего подходит для | Плюсы | Минусы | Автоматизация? |
|---|---|---|---|---|
| Ручное копирование и вставка | Быстрое, одноразовое использование | Быстро, без настроек | Нет автоматизации, проблемы с форматированием | ❌Нет |
| Excel из Интернета | Живые структурированные данные | Интегрировано, поддерживает обновление | Ограничено для динамических таблиц | ❌Нет |
| Макрос VBA | Повторяющиеся задачи в Excel | Автоматизирует извлечение, обрабатывает объединения | Требует знания VBA | ✅Да |
| Python (BeautifulSoup + Spire.XLS) | Разработчики, большие/сложные таблицы | Полный контроль, масштабируемость, автоматизация | Требует программирования и зависимостей | ✅Да |
Заключительные мысли
Метод, который вы выберете, во многом зависит от вашего варианта использования:
- Если вам нужно лишь изредка скопировать небольшую таблицу, ручное копирование и вставка — самый быстрый способ.
- Если вы хотите извлекать структурированные данные с веб-страницы, которая часто обновляется, удобен Excel из Интернета.
- Для бизнес-пользователей, которые ежедневно работают в Excel и хотят автоматизации, идеальным является макрос VBA.
- Для разработчиков, работающих с несколькими наборами данных или сложными структурами HTML, Python с BeautifulSoup и Spire.XLS обеспечивает наибольшую гибкость и масштабируемость.
Комбинируя эти методы с вашим рабочим процессом, вы можете сэкономить часы ручной работы и обеспечить более чистое и надежное извлечение данных в Excel.