Многие открывают Adobe Acrobat и обнаруживают, что извлечение страниц из PDF — платная функция. Хорошая новость в том, что вам не нужно за это платить. Если вам нужно сохранить ключевые страницы из контракта или извлечь раздел из отчета, это руководство покажет вам три бесплатных и простых способа извлечь страницы из PDF всего за несколько кликов.
- Извлечение страниц из PDF с помощью Google Chrome
- Быстрое сохранение одной страницы PDF с помощью онлайн-инструментов
- Бесплатное извлечение страниц из PDF с помощью Python
- Заключение
Как извлечь страницы из PDF с помощью Google Chrome
Вам не нужно никакого дополнительного программного обеспечения — один только Google Chrome может извлекать определенные страницы из PDF онлайн. Используя встроенную функцию «Печать», вы можете выбрать сохранение всех страниц, только нечетных или четных страниц, или любой другой диапазон страниц по вашему выбору. Просто выберите страницы, которые вы хотите сохранить, и сохраните их как новый PDF-файл. Вот как извлечь страницы из PDF с помощью Google Chrome:
- Найдите PDF-файл, из которого вы хотите извлечь страницы, и щелкните правой кнопкой мыши, чтобы открыть его в Google Chrome.
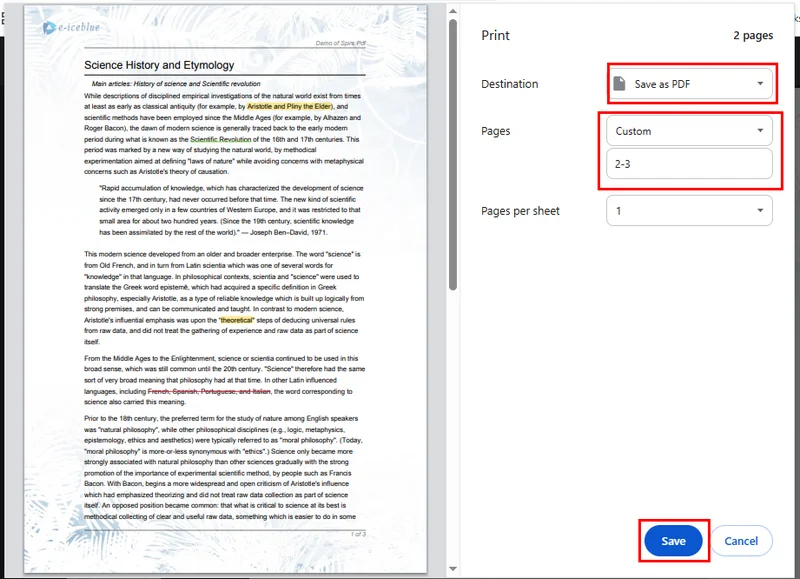
- Нажмите кнопку Печать в правом верхнем углу и измените принтер назначения на Сохранить как PDF.
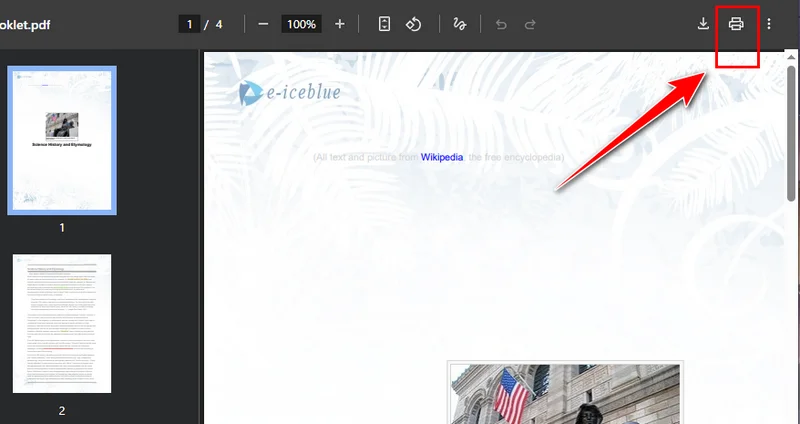
- Выберите страницы, которые хотите сохранить, затем нажмите Сохранить. Chrome автоматически загрузит новый PDF-файл на ваше устройство.
Плюсы
- Не нужно устанавливать стороннее программное обеспечение.
- Идеально для быстрого извлечения 1–2 страниц.
- Плавная работа и широкая доступность (почти у всех пользователей есть Chrome).
Минусы
- Не подходит для извлечения большого количества непоследовательных страниц.
- Возможности вывода довольно ограничены.
Как быстро сохранить одну страницу PDF с помощью онлайн-инструментов
Существует много способов извлечь страницы из PDF. Помимо использования встроенной функции Chrome, вы также можете использовать онлайн-инструменты для разделения PDF-документов и сохранения нужных страниц. Поскольку эти инструменты работают через веб, они доступны как на компьютерах, так и на мобильных устройствах, и вам не нужно ничего скачивать или регистрироваться. Просто введите в поиске «как извлечь страницы из PDF», и вы найдете множество вариантов. В этом руководстве мы продемонстрируем процесс на примере Smallpdf, но не волнуйтесь — большинство онлайн-инструментов работают очень похоже.
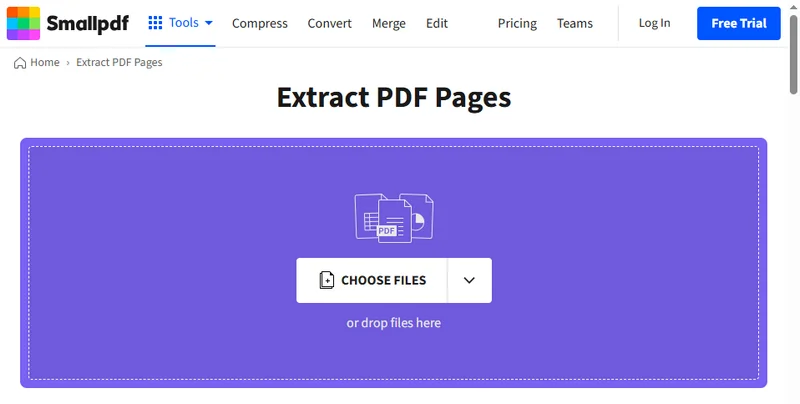
- Перейдите на страницу извлечения PDF на Smallpdf.
- Перетащите ваш PDF-файл в инструмент, который автоматически обработает его и отобразит все страницы.
- Выберите страницы, которые хотите извлечь, затем нажмите Готово. Вы можете экспортировать страницы как один PDF-файл или как отдельные PDF-файлы.
- После завершения извлечения нажмите кнопку Скачать, чтобы сохранить полученный PDF-файл на ваше устройство.
Плюсы
- Можно использовать прямо в браузере, без скачиваний и установок.
- Поддерживает извлечение отдельных, последовательных или непоследовательных страниц.
- Интуитивно понятный интерфейс — просто перетащите, легко даже для новичков.
- Работает на любом устройстве с браузером и подключением к интернету, высокая совместимость.
Минусы
- Требуется подключение к интернету; нельзя использовать офлайн.
- Некоторые инструменты ограничивают размер файла для бесплатных пользователей.
- Файлы загружаются на сервер, поэтому будьте осторожны с конфиденциальным содержимым.
- Расширенные функции, такие как пакетная обработка или загрузка без водяных знаков, могут требовать оплаты.
Как бесплатно извлечь страницы из PDF с помощью Python
При работе с PDF и Chrome, и онлайн-инструменты имеют одно ограничение — они могут обрабатывать только один файл за раз. Если вы работаете с несколькими PDF-файлами, есть более быстрое и профессиональное решение: Free Spire.PDF for Python.
Эта мощная библиотека предоставляет широкий спектр функций для работы с PDF, включая извлечение страниц, преобразование форматов и редактирование содержимого. С помощью Free Spire.PDF вы можете легко извлекать определенные страницы, добавляя их из исходного PDF в новый документ с помощью метода PdfDocument.InsertPage().
Приведенный ниже пример кода демонстрирует, как извлечь 2-ю и 4-ю страницы из PDF и объединить их в новый файл.
from spire.pdf import PdfDocument
# Load a PDF file
source_pdf = PdfDocument()
source_pdf.LoadFromFile("/input/Booklet.pdf")
# Create a new PdfDocument instance
new_pdf = PdfDocument()
# Extract page 2 and page 4
new_pdf.InsertPage(source_pdf, 1)
new_pdf.InsertPage(source_pdf, 3)
# Save the extracted pages
new_pdf.SaveToFile("/output/extracted_pages.pdf")
new_pdf.Close()
Вот предварительный просмотр полученного файла: 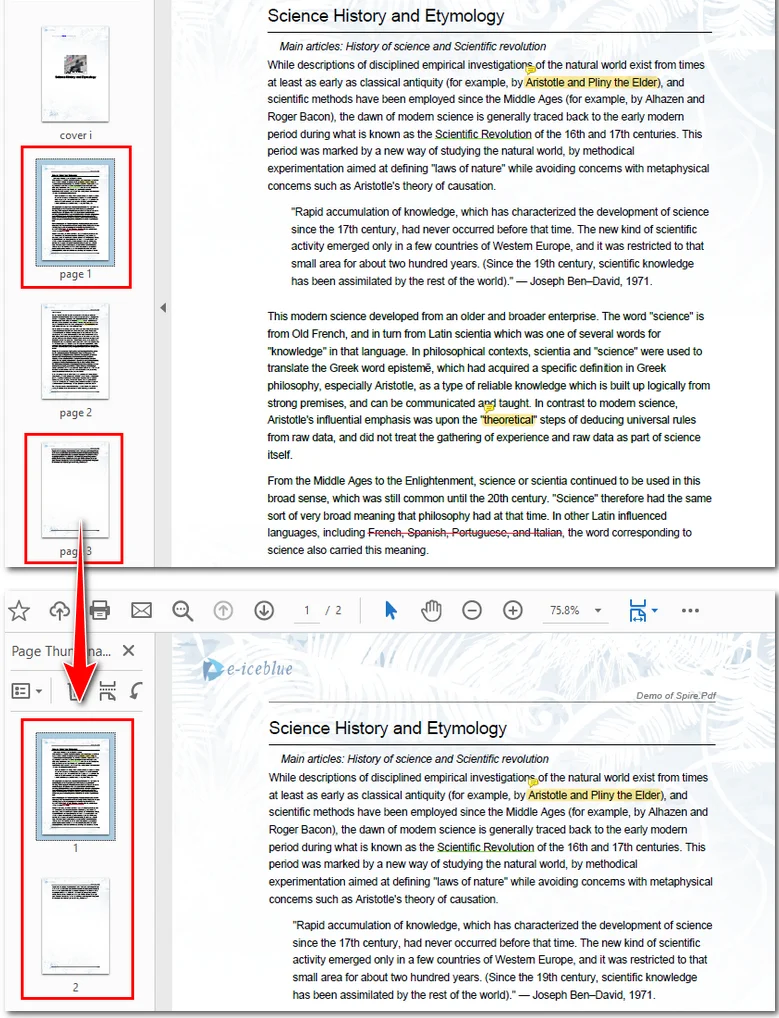
Если вам нужно извлечь большое количество страниц, другой вариант — удалить ненужные страницы. Этот подход может быть столь же эффективным при работе с PDF в Python.
Заключение
Независимо от того, извлекаете ли вы одну страницу или управляете несколькими PDF-файлами, выбор правильного инструмента может сэкономить вам много времени. Если вы предпочитаете более гибкое и основанное на коде решение, Free Spire.PDF for Python предлагает надежный способ эффективного извлечения, редактирования или организации PDF-файлов. Вы можете скачать его бесплатно и изучить больше функций на официальном сайте.
ЧИТАЙТЕ ТАКЖЕ