
Преобразование таблицы PDF в Word звучит просто, но любой, кто пробовал это сделать, знает, что процесс может быть на удивление нестабильным. Файлы PDF предназначены в первую очередь для отображения, а не для структурированного редактирования, что часто приводит к повреждению макетов таблиц при конвертации или копировании. Пользователи часто сталкиваются с разорванными строками, объединенными столбцами, потерянными границами, непоследовательными интервалами между ячейками или экспортом таблиц в виде изображений, а не редактируемых таблиц Word.
Это полное руководство объясняет надежные методы преобразования таблиц PDF в таблицы Word. Вы узнаете об онлайн-инструментах, ручных подходах и высокоточных программных решениях. Если вам нужно преобразовать таблицы PDF в Word, извлечь структурированные данные из PDF или создать полностью редактируемые таблицы Word для профессиональных или автоматизированных рабочих процессов, эта статья предоставит вам необходимые практические знания и технические сведения.
1. Почему преобразование таблиц PDF в Word является сложной задачей
Прежде чем изучать методы преобразования, важно понять, почему таблицы в PDF-файлах трудно интерпретировать. Это поможет вам выбрать правильный инструмент в зависимости от сложности макета.
1.1 PDF-файлы не содержат настоящих таблиц
В отличие от Word или HTML, файлы PDF не хранят структуру таблиц. Вместо этого они хранят:
- текст с использованием абсолютных позиций
- линии и границы как пути рисования
- строки/столбцы только как визуальное выравнивание, а не структурированные данные сетки
В результате:
- Строки и столбцы не распознаются как ячейки
- Элементы линий могут не соответствовать фактическим границам таблицы
- Выбор текста или копирование часто нарушает макет
Вот почему простое копирование и вставка почти всегда не удается.
1.2 Word требует структурированных элементов таблицы
Microsoft Word ожидает:
- определенный элемент
<table> - постоянное количество строк/столбцов
- истинные границы ячеек
- регулируемую ширину столбцов
Если содержимое PDF не может быть интерпретировано в эту структуру, Word создает непредсказуемые результаты или экспортирует таблицу как изображение.
Понимание этих ограничений объясняет, почему надежное извлечение таблиц из PDF требует интеллектуального анализа, выходящего за рамки простого визуального обнаружения.
2. Обзор надежных методов
Это руководство охватывает три практических способа преобразования таблиц PDF в таблицы Word:
- Онлайн-конвертеры PDF в Word – самый быстрый, минимальный контроль
- Настольное программное обеспечение – более стабильное, лучшая точность
- Программное извлечение и восстановление таблиц – высочайшая точность и полностью редактируемые результаты
Совет: Большинство непрограммных решений преобразуют весь PDF-файл в файл Word. Если вам нужны только таблицы, возможно, вам придется вручную удалить окружающее содержимое после этого.
Самый точный метод — это программное извлечение данных таблицы и восстановление таблицы Word — это позволяет избежать потерь форматирования и обеспечивает полностью редактируемый, чистый вывод таблицы.
3. Метод 1: Преобразование таблицы PDF в Word с помощью онлайн-инструментов (самый быстрый и простой)
Онлайн-конвертеры PDF в Word удобны для быстрых преобразований. Эти инструменты пытаются автоматически определять структуру таблиц и экспортировать их в документ Word.
Типичный рабочий процесс
-
Откройте онлайн-конвертер (например, Free PDF Converter).
-
Загрузите ваш PDF.
-
Дождитесь автоматического преобразования.
-
Скачайте файл Word.
-
При необходимости вручную настройте форматирование таблицы.
Плюсы
- Не требует установки
- Работает на любом устройстве
- Очень быстро
Минусы
- Низкая точность для сложных таблиц
- Проблемы с конфиденциальностью (загрузка в облако)
- Может выводить таблицы в виде изображений
- Ограниченная настройка
Онлайн-инструменты лучше всего подходят для простых, одноразовых преобразований.
4. Метод 2: Преобразование таблиц PDF с помощью настольного программного обеспечения (более стабильно и безопасно)
Настольные приложения обрабатывают файлы локально, обеспечивая лучшую точность и конфиденциальность. Microsoft Word, Acrobat и специализированное программное обеспечение для PDF часто обеспечивают приемлемое извлечение таблиц для стандартных макетов.
Общий рабочий процесс
-
Установите программное обеспечение (например, Microsoft Word).
-
Откройте PDF-файл в приложении.
-
Подтвердите преобразование, нажав .
-
Дождитесь обработки.
-
Отредактируйте и сохраните результат как файл .docx.
Плюсы
- Более высокая точность обнаружения
- Поддерживает большие и многостраничные файлы
- Нет рисков, связанных с загрузкой
Минусы
- Некоторое программное обеспечение платное
- Все еще ненадежно для нестандартных таблиц
- Функции различаются в разных инструментах
Настольные инструменты хорошо работают для средней сложности, но не для структурированных данных, которые должны оставаться идеально редактируемыми.
5. Метод 3: Программное извлечение и преобразование таблиц PDF (самый точный метод)
Для пользователей, нуждающихся в постоянном, автоматизированном и высококачественном восстановлении таблиц, программный подход является наиболее надежным. Он позволяет:
- точное извлечение содержимого таблицы
- полный контроль над созданием таблицы Word
- пакетная обработка
- постоянное форматирование
Этот метод может успешно преобразовывать даже сложные или нестандартные таблицы PDF в идеально редактируемые таблицы Word.
5.1 Вариант А: Автоматическое преобразование всего PDF в Word
Используя Free Spire.PDF for Python, вы можете напрямую преобразовать PDF в документ Word. Библиотека пытается определить структуру таблиц, анализируя элементы линий, позиционирование текста и выравнивание столбцов.
Установите Free Spire.PDF for Python с помощью pip:
pip install spire.pdf.free
Пример кода Python для преобразования PDF в Word
from spire.pdf import PdfDocument, FileFormat
input_pdf = "sample.pdf"
output_docx = "output/pdf_to_docx.docx"
# Открыть документ PDF
pdf = PdfDocument()
pdf.LoadFromFile(input_pdf)
# Сохранить PDF в документ Word
pdf.SaveToFile(output_docx, FileFormat.DOCX)
Ниже приведен предварительный просмотр результата преобразования PDF в Word:
Когда использовать
- Таблицы с четкими линиями сетки
- Простые и умеренно сложные макеты
- Когда точность таблицы не должна быть 100% идеальной
Ограничения
- Сложные или объединенные ячейки могут отображаться неточно
- Таблицы без границ могут быть неверно истолкованы
- Для более продвинутых вариантов преобразования, пожалуйста, обратитесь к Как преобразовать PDF в Doc/Docx с помощью Python.
5.2 Вариант Б: Извлечение данных таблицы и ручное восстановление таблиц Word (наилучшая точность)
Вы также можете извлекать данные таблиц из PDF с помощью Free Spire.PDF for Python и создавать таблицы Word с помощью Free Spire.Doc for Python. Этот метод является самым надежным и точным для преобразования таблиц PDF в документы Word. Он обеспечивает:
- Полную редактируемость таблицы
- Предсказуемую структуру
- Полный контроль над форматированием
- Надежную автоматизацию
Установите Free Spire.Doc for Python:
pip install spire.doc.free
Рабочий процесс:
- Извлечь данные таблицы из PDF
- Создать документ Word программно
- Вставить таблицу, используя извлеченные данные
- Применить форматирование
Пример кода Python для извлечения таблиц PDF и создания таблиц Word
from spire.pdf import PdfDocument, PdfTableExtractor
from spire.doc import Document, FileFormat, DefaultTableStyle, AutoFitBehaviorType, BreakType
input_pdf = "sample.pdf"
output_docx = "output/pdf_table_to_docx.docx"
# Открыть документ PDF
pdf = PdfDocument()
pdf.LoadFromFile(input_pdf)
# Создать документ Word
doc = Document()
section = doc.AddSection()
# Извлечь данные таблицы из PDF
table_extractor = PdfTableExtractor(pdf)
for i in range(pdf.Pages.Count):
tables = table_extractor.ExtractTable(i)
if tables is not None and len(tables) > 0:
for i in range(len(tables)):
table = tables[i]
# Создать таблицу в документе Word
word_table = section.AddTable()
word_table.ApplyStyle(DefaultTableStyle.ColorfulGridAccent4)
word_table.ResetCells(table.GetRowCount(), table.GetColumnCount())
for j in range(table.GetRowCount()):
for k in range(table.GetColumnCount()):
cell_text = table.GetText(j, k).replace("\n", " ")
# Записать текст ячейки в соответствующую ячейку таблицы Word
tr = word_table.Rows[j].Cells[k].AddParagraph().AppendText(cell_text)
tr.CharacterFormat.FontName = "Arial"
tr.CharacterFormat.FontSize = 11
# Автоподбор ширины таблицы
word_table.AutoFit(AutoFitBehaviorType.AutoFitToContents)
section.AddParagraph().AppendBreak(BreakType.LineBreak)
# Сохранить документ Word
doc.SaveToFile(output_docx, FileFormat.Docx)
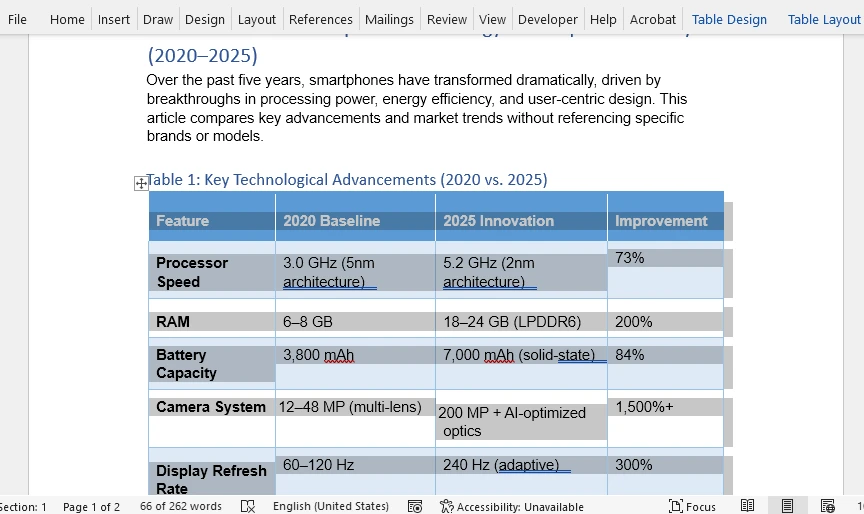
Ниже приведен предварительный просмотр восстановленных таблиц Word:

Почему этот метод превосходит другие
- Выходные таблицы всегда редактируемы
- Идеально подходит для автоматизации и пакетной обработки
- Работает даже без видимых линий таблицы
- Позволяет настраивать форматирование, шрифты, границы и стили
Это рекомендуемое решение для профессионального использования.
Если вам нужно экспортировать таблицы PDF в другие форматы, ознакомьтесь с Как извлечь таблицы из PDF с помощью Python.
6. Сравнение точности всех методов
| Метод | Точность | Редактируемый | Контроль форматирования | Лучше всего для |
|---|---|---|---|---|
| Онлайн-конвертеры | ★★★★☆ | Да | Низкий | Быстрое одноразовое использование |
| Настольное ПО | ★★★★☆ | Да | Средний | Стандартные профессиональные документы |
| Программное извлечение + восстановление | ★★★★★ | Да | Полный | Автоматизация, бизнес-процессы |
| Полное преобразование PDF → Word (авто) | ★★★★☆ | Да | Средний | Чистые, хорошо структурированные PDF |
7. Лучшие практики для высококачественного преобразования
Чтобы обеспечить наилучшие результаты, следуйте этим лучшим практикам:
Подготовка файла
- Предпочитайте оригинальные текстовые PDF (не отсканированные)
- Запустите OCR перед извлечением таблицы, если PDF отсканирован
Советы по дизайну таблиц
- Сохраняйте постоянное выравнивание столбцов
- Избегайте ненужных объединенных ячеек
- Поддерживайте четкое расстояние между столбцами
Технические рекомендации
- Используйте программное извлечение для пакетных рабочих процессов
- Восстанавливайте таблицы Word для точного форматирования
- Всегда проверяйте извлеченные данные на точность
8. Часто задаваемые вопросы
1. Как преобразовать таблицу PDF в редактируемую таблицу Word без потери форматирования?
Используйте либо высококачественные настольные конвертеры, либо программную библиотеку, такую как Spire.PDF + Spire.Doc. Программное извлечение обеспечивает наиболее стабильные результаты.
2. Могу ли я извлечь только таблицу (а не весь PDF) в Word?
Да. Извлеките только данные таблицы и восстановите таблицу программно. Это создает полностью редактируемые таблицы Word.
3. Почему моя таблица PDF появилась как изображение в Word?
Конвертер не смог интерпретировать структуру и экспортировал содержимое как изображение. Используйте инструмент, который поддерживает восстановление таблиц.
4. Какой метод является наиболее точным для сложных или нестандартных таблиц?
Программное извлечение в сочетании с ручным созданием таблицы в Word.
9. Заключение
Преобразование таблиц PDF в таблицы Word варьируется от простого до очень сложного в зависимости от структуры исходного PDF. Быстрые онлайн-инструменты и настольные приложения хорошо работают для простых макетов, но они часто испытывают трудности с объединенными ячейками, нестандартными интервалами или многострочными структурами.
Для пользователей, которым требуется точный, редактируемый и надежный вывод, особенно в автоматизации бизнеса и крупномасштабной обработке документов, программный подход обеспечивает непревзойденную точность. Он позволяет истинное восстановление таблиц в Word с полным контролем над форматированием, стилем и структурой ячеек.
Независимо от того, нужна ли вам быстрая онлайн-конвертация или глубоко точный автоматизированный конвейер, методы, описанные в этом руководстве, гарантируют, что вы сможете надежно преобразовывать таблицы PDF в полностью редактируемые таблицы Word на всех уровнях сложности.