
Bei der Arbeit mit PDF-Dateien in Java ist es oft notwendig, zwischen Binärdaten und textbasierten Formaten zu konvertieren. Die Base64-Kodierung ermöglicht es, PDF-Inhalte als reinen Text darzustellen, was nützlich ist, wenn Dokumente in JSON übertragen, über Formulare gesendet oder in textbasierten Systemen gespeichert werden. Die Standardbibliothek von Java bietet java.util.Base64, was die Implementierung von Konvertierungen von Base64 in PDF und von PDF in Base64 ohne zusätzliche Abhängigkeiten unkompliziert macht.
In diesem Tutorial werden wir untersuchen, wie diese Konvertierungen nur mit dem JDK gehandhabt werden, sowie wie man mit Base64-Bildern arbeitet und sie in PDFs einbettet. Für fortgeschrittenere Operationen, wie das Bearbeiten eines als Base64 empfangenen PDFs und das erneute Exportieren, werden wir die Verwendung von Free Spire.PDF for Java demonstrieren.
Inhaltsverzeichnis
- Base64 in PDF in Java konvertieren (nur JDK)
- PDF in Base64 in Java konvertieren (nur JDK)
- Validierungs- und Sicherheitstipps
- Base64-Bilder als PDF in Java speichern
- Base64-PDF laden, ändern und wieder als Base64 speichern
- Leistungs- und Speicherüberlegungen
- FAQ
Base64 in PDF in Java konvertieren (nur JDK)
Der einfachste Ansatz besteht darin, eine Base64-Zeichenfolge in den Speicher zu lesen, optionale Präfixe (wie data:application/pdf;base64,) zu entfernen und sie dann in ein PDF zu dekodieren. Dies funktioniert gut für kleine bis mittelgroße Dateien.
import java.nio.file.*;
import java.nio.charset.StandardCharsets;
import java.util.Base64;
public class Base64ToPdf {
public static void main(String[] args) throws Exception {
// Base64-Text aus einer Datei (oder einer anderen Quelle) lesen
String base64 = Files.readString(Paths.get("sample.pdf.b64"), StandardCharsets.UTF_8);
// Gängige Daten-URI-Präfixe entfernen, falls vorhanden
base64 = stripDataPrefix(base64);
// Base64 in rohe PDF-Bytes dekodieren
// Der MIME-Dekodierer toleriert Zeilenumbrüche und umgebrochenen Text
byte[] pdfBytes = Base64.getMimeDecoder().decode(base64);
// Dekodierte Bytes in eine PDF-Datei schreiben
Files.write(Paths.get("output.pdf"), pdfBytes);
}
/** Hilfsprogramm zum Entfernen von "data:application/pdf;base64,", falls enthalten */
private static String stripDataPrefix(String src) {
String s = src.trim();
int comma = s.indexOf(',');
if (comma > 0 && s.substring(0, comma).toLowerCase().contains("base64")) {
return s.substring(comma + 1).trim();
}
return s;
}
}
Erklärung Dieses Beispiel ist unkompliziert und zuverlässig für Base64-Inhalte, die bequem in den Speicher passen. Der Base64.getMimeDecoder() wird gewählt, weil er Zeilenumbrüche problemlos handhabt, die in aus E-Mail-Systemen oder APIs exportiertem Base64-Text üblich sind. Wenn Sie wissen, dass Ihre Base64-Zeichenfolge keine Zeilenumbrüche enthält, können Sie auch Base64.getDecoder() verwenden.
Stellen Sie sicher, dass Sie vor dem Dekodieren alle Daten-URI-Präfixe (data:application/pdf;base64,) entfernen, da sie nicht Teil der Base64-Nutzlast sind. Die Hilfsmethode stripDataPrefix() erledigt dies automatisch.
Streaming-Variante (keine vollständige Zeichenfolge im Speicher)
Für große PDFs ist es besser, Base64 im Streaming-Verfahren zu verarbeiten. Dies vermeidet das Laden der gesamten Base64-Zeichenfolge auf einmal in den Speicher.
import java.io.*;
import java.nio.file.*;
import java.util.Base64;
public class Base64ToPdfStreamed {
public static void main(String[] args) throws Exception {
// Eingabe: Textdatei mit Base64-kodiertem PDF
Path in = Paths.get("sample.pdf.b64");
// Ausgabe: dekodierte PDF-Datei
Path out = Paths.get("output.pdf");
// Den Base64-Dekodierer um den Eingabestream wickeln
try (InputStream b64In = Base64.getMimeDecoder().wrap(Files.newInputStream(in));
OutputStream pdfOut = Files.newOutputStream(out)) {
// Dekodierte Bytes direkt in die PDF-Ausgabe streamen
b64In.transferTo(pdfOut);
}
}
}
Erklärung Dieser streamingbasierte Ansatz ist speichereffizienter, da er Daten on-the-fly dekodiert, anstatt die gesamte Zeichenfolge zu puffern. Es ist die empfohlene Methode für große Dateien oder kontinuierliche Streams (z. B. Netzwerk-Sockets).
- Base64.getMimeDecoder() wird verwendet, um Zeilenumbrüche in der Eingabe zu tolerieren.
- Die Methode transferTo() kopiert dekodierte Bytes effizient vom Eingang zum Ausgang ohne manuelle Pufferbehandlung.
- Im realen Einsatz sollten Sie eine Ausnahmebehandlung hinzufügen, um Dateizugriffsfehler или Teil-Schreibvorgänge zu verwalten.
PDF in Base64 in Java konvertieren (nur JDK)
Das Kodieren eines PDFs in Base64 ist genauso einfach. Für kleinere Dateien ist es in Ordnung, das gesamte PDF in den Speicher zu lesen:
import java.nio.file.*;
import java.util.Base64;
public class PdfToBase64 {
public static void main(String[] args) throws Exception {
// Die PDF-Datei in ein Byte-Array lesen
byte[] pdfBytes = Files.readAllBytes(Paths.get("input.pdf"));
// Die PDF-Bytes als Base64-Zeichenfolge kodieren
String base64 = Base64.getEncoder().encodeToString(pdfBytes);
// Die Base64-Zeichenfolge in eine Textdatei schreiben
Files.writeString(Paths.get("output.pdf.b64"), base64);
}
}
Erklärung Dieser Ansatz ist einfach und funktioniert gut für kleine oder mittelgroße Dateien. Das gesamte PDF wird in ein Byte-Array eingelesen und als einzelne Base64-Zeichenfolge kodiert. Diese Zeichenfolge kann gespeichert, in JSON übertragen oder in eine Daten-URI eingebettet werden.
Streaming-Encoder (behandelt große Dateien effizient)
Für große PDFs können Sie den Speicher-Overhead vermeiden, indem Sie direkt als Stream kodieren:
import java.io.*;
import java.nio.file.*;
import java.util.Base64;
public class PdfToBase64Streamed {
public static void main(String[] args) throws Exception {
// Eingabe: binäre PDF-Datei
try (InputStream pdfIn = Files.newInputStream(Paths.get("input.pdf"));
// Roher Ausgabestream für die Base64-Textdatei
OutputStream rawOut = Files.newOutputStream(Paths.get("output.pdf.b64"));
// Ausgabestream mit Base64-Encoder umwickeln
OutputStream b64Out = Base64.getEncoder().wrap(rawOut)) {
// PDF-Bytes direkt in die Base64-kodierte Ausgabe streamen
pdfIn.transferTo(b64Out);
}
}
}
Erklärung Der Streaming-Encoder behandelt große Dateien effizient, indem er Daten inkrementell kodiert, anstatt alles in den Speicher zu laden. Die Methode Base64.getEncoder().wrap() verwandelt einen regulären Ausgabestream in einen, der automatisch Base64-Text schreibt.
Dieses Design skaliert besser für große PDFs, Netzwerk-Streams oder Dienste, die viele Dokumente gleichzeitig ohne Speicherprobleme verarbeiten müssen.
Validierungs- und Sicherheitstipps
- Daten-URIs erkennen: Benutzer könnten Präfixe wie data:application/pdf;base64, senden. Entfernen Sie diese vor dem Dekodieren.
- Zeilenumbrüche: Beim Dekodieren von Text, der umgebrochene Zeilen enthalten könnte (E-Mails, Protokolle), verwenden Sie Base64.getMimeDecoder().
- Schnelle Plausibilitätsprüfung: Nach dem Dekodieren beginnen die ersten Bytes eines gültigen PDFs normalerweise mit %PDF-. Sie können dies zur frühzeitigen Fehlererkennung überprüfen.
- Zeichenkodierung: Behandeln Sie Base64-Text als UTF-8 (oder US-ASCII), wenn Sie .b64-Dateien lesen/schreiben.
- Fehlerbehandlung: Umschließen Sie Dekodierung/Kodierung mit try/catch und geben Sie aussagekräftige Meldungen aus (z. B. Größe, Header-Fehlanpassung).
Base64-Bilder als PDF in Java speichern
Manchmal erhalten Sie Bilder (z. B. PNG oder JPEG) als Base64-Zeichenfolgen und müssen sie in ein PDF einbetten. Während die Standardbibliothek von Java keine PDF-APIs hat, macht Free Spire.PDF for Java dies unkompliziert.
Sie können Free Spire.PDF for Java herunterladen und zu Ihrem Projekt hinzufügen oder Free Spire.PDF for Java aus dem Maven-Repository installieren.
Wichtige Spire.PDF-Konzepte
- PdfDocument — der Container für eine oder mehrere PDF-Seiten.
- PdfPageBase — repräsentiert eine Seite, auf der Sie zeichnen können.
- PdfImage.fromImage() — lädt ein BufferedImage oder einen Stream in ein zeichenbares PDF-Bild.
- drawImage() — platziert das Bild an den angegebenen Koordinaten und in der angegebenen Größe.
- Koordinatensystem — Spire.PDF verwendet ein Koordinatensystem, bei dem (0,0) die obere linke Ecke ist.
Beispiel: Base64-Bild in PDF konvertieren mit Java
import com.spire.pdf.PdfDocument;
import com.spire.pdf.PdfPageBase;
import com.spire.pdf.graphics.PdfImage;
import java.io.*;
import java.nio.charset.StandardCharsets;
import java.nio.file.*;
import java.util.Base64;
public class Base64ImageToPdf {
public static void main(String[] args) throws Exception {
// 1) Base64-Datei lesen und dekodieren (Daten-URI-Präfix entfernen, falls vorhanden)
String base64Image = Files.readString(Paths.get("G:/Document/image.b64"), StandardCharsets.UTF_8).trim();
int comma = base64Image.indexOf(',');
if (comma > 0 && base64Image.substring(0, comma).toLowerCase().contains("base64")) {
base64Image = base64Image.substring(comma + 1).trim();
}
byte[] imageBytes = Base64.getMimeDecoder().decode(base64Image);
// 2) PDF erstellen und das Bild einfügen
PdfDocument pdf = new PdfDocument();
try (ByteArrayInputStream in = new ByteArrayInputStream(imageBytes)) {
PdfImage img = PdfImage.fromStream(in);
pdf.getPageSettings().setWidth(img.getWidth());
pdf.getPageSettings().setHeight(img.getHeight());
pdf.getPageSettings().setMargins(0, 0, 0, 0);
PdfPageBase page = pdf.getPages().add();
page.getCanvas().drawImage(img, 0, 0);
}
// 3) PDF-Datei speichern
pdf.saveToFile("output/image.pdf");
}
}
Das folgende Beispiel dekodiert ein Base64-Bild und bettet es in eine PDF-Seite ein. Die Ausgabe sieht so aus:
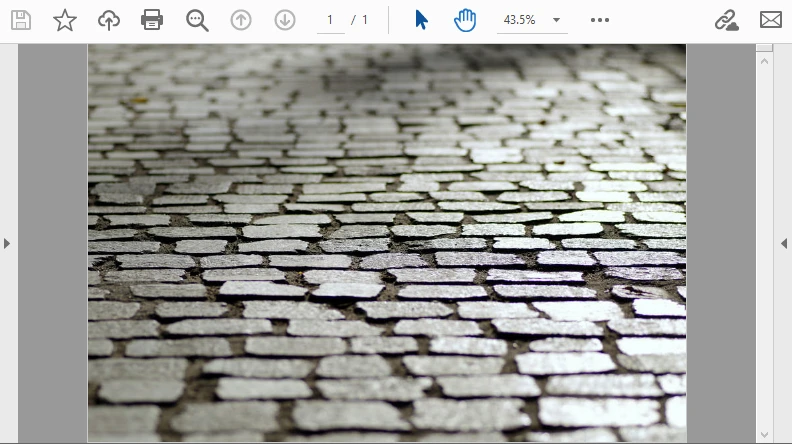
Dieser Workflow ist ideal zum Einbetten von gescannten Dokumenten oder Signaturen, die als Base64 ankommen.
Für Vektorgrafiken können Sie auch unsere Anleitung zum Konvertieren von SVG in PDF in Java einsehen.
Base64-PDF laden, ändern und wieder als Base64 speichern
In vielen APIs kommt ein PDF als Base64 an. Mit Spire.PDF können Sie es laden, auf Seiten zeichnen (Text/Wasserzeichen) und wieder Base64 zurückgeben – ideal für serverlose Funktionen oder Microservices.
Hier verwendete wichtige Spire.PDF-Konzepte
- PdfDocument.loadFromBytes(byte[]) — erstellt ein Dokument direkt aus dekodierten Bytes.
- PdfPageBase#getCanvas() — erhält eine Zeichenfläche zum Platzieren von Text, Formen oder Bildern.
- Schriftarten und Pinsel — z.B. PdfTrueTypeFont oder integrierte Schriftarten über PdfFont, mit PdfSolidBrush zum Färben.
- Speichern im Speicher — pdf.saveToStream(ByteArrayOutputStream) liefert rohe Bytes, die Sie mit Base64 erneut kodieren können.
Beispiel: Base64-PDF in Java laden, ändern und speichern
import com.spire.pdf.*;
import com.spire.pdf.graphics.*;
import java.awt.*;
import java.io.*;
import java.util.Base64;
public class EditBase64Pdf {
public static void main(String[] args) throws Exception {
String base64Pdf = "..."; // eingehende Base64-PDF-Zeichenfolge
// In Bytes dekodieren
byte[] pdfBytes = Base64.getDecoder().decode(base64Pdf);
// PDF laden
PdfDocument pdf = new PdfDocument();
pdf.loadFromBytes(pdfBytes);
// Stempel auf jede Seite hinzufügen
for (PdfPageBase page : (Iterable<PdfPageBase>) pdf.getPages()) {
PdfTrueTypeFont font = new PdfTrueTypeFont(new Font("Arial", Font.BOLD, 36));
PdfSolidBrush brush = new PdfSolidBrush(new PdfRGBColor(Color.BLUE));
page.getCanvas().drawString("Processed", font, brush, 100, 100);
}
// In den Speicher speichern und zurück in Base64 kodieren
ByteArrayOutputStream output = new ByteArrayOutputStream();
pdf.saveToStream(output);
pdf.close();
String resultBase64 = Base64.getEncoder().encodeToString(output.toByteArray());
System.out.println(resultBase64);
}
}
In diesem Beispiel wird jeder Seite des PDFs ein blauer „Processed“-Wasserzeichen hinzugefügt, bevor es wieder in Base64 kodiert wird. Das Ergebnis sieht so aus:
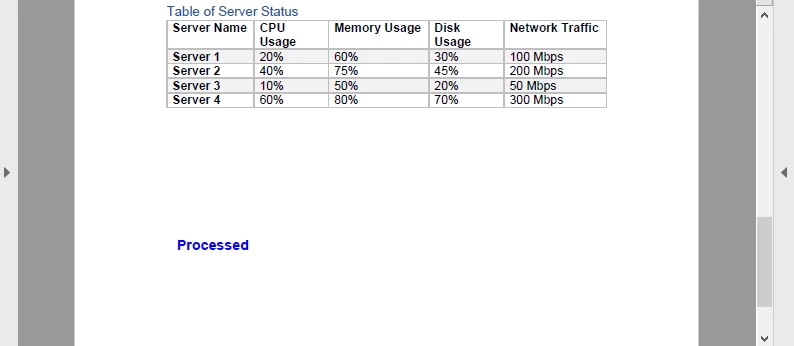
Dieser Round-Trip (Base64 → PDF → Base64) ist nützlich für Dokumenten-Pipelines, wie z.B. das Stempeln von Rechnungen oder das Hinzufügen dynamischer Signaturen in einem Cloud-Dienst.
Verwandte Tutorials:
Text aus PDF in Java extrahieren | PDF-Dokumente in Java erstellen
Leistungs- und Speicherüberlegungen
- Streaming vs. Datei-I/O — bei der Arbeit mit Base64 bevorzugen Sie ByteArrayInputStream und ByteArrayOutputStream, um unnötige temporäre Dateien zu vermeiden.
- Bildlastige PDFs — das Dekodieren von Base64-Bildern kann den Speicherverbrauch stark erhöhen; erwägen Sie eine Skalierung oder Komprimierung vor dem Einbetten.
- Große PDFs — Spire.PDF verarbeitet PDFs mit mehreren MB, aber für sehr große Dokumente sollten Sie eine seitenweise Verarbeitung in Betracht ziehen.
- Serverlose Funktionen — Base64-Workflows passen gut, da Sie die Abhängigkeit vom Dateisystem vermeiden und Ergebnisse direkt über API-Antworten zurückgeben.
FAQ
F: Kann ich Base64 nur mit dem JDK in PDF konvertieren?
Ja. Java SE bietet Dienstprogramme für Base64 und Datei-I/O, sodass Sie die Konvertierung ohne zusätzliche Bibliotheken durchführen können.
F: Kann ich PDF mit der Standard-Java-Bibliothek bearbeiten?
Nein. Java SE unterstützt weder das Parsen von PDF-Strukturen noch das Rendern. Verwenden Sie zum Bearbeiten eine dedizierte Bibliothek wie Spire.PDF for Java.
F: Ist Free Spire.PDF for Java ausreichend?
Ja. Die Free Spire.PDF for Java ist in der Dokumentengröße begrenzt, aber für Tests oder kleine Projekte ausreichend.
F: Muss ich PDFs auf der Festplatte speichern?
Nicht immer. Die Konvertierung kann auch im Speicher mit Streams ausgeführt werden, was oft für APIs und Cloud-Apps bevorzugt wird.