
PDF-Dateien sind für den Dokumentenaustausch weit verbreitet, aber nicht alle PDFs verhalten sich wie gescannte Dokumente. Viele PDFs enthalten bearbeitbare Textebenen, Vektorgrafiken und auswählbare Inhalte, was sie leicht zu ändern, zu kopieren oder wiederzuverwenden macht.
In realen Szenarien – wie Archivierung, öffentliche Verteilung oder Dokumentenfinalisierung – möchten Sie vielleicht, dass ein PDF wie eine gescannte Datei aussieht und sich so verhält. Das Umwandeln eines PDFs in ein gescanntes PDF entfernt seine bearbeitbare Struktur und wandelt jede Seite in eine bildbasierte Darstellung um.
Dieser Leitfaden erklärt, was ein gescanntes PDF ist, warum Sie eines benötigen könnten und wie Sie ein PDF mit Online-Tools oder Python-Automatisierung in ein gescanntes Dokument umwandeln.
Schnellnavigation
- Was ist ein gescanntes PDF?
- Warum PDF in gescanntes PDF umwandeln?
- Methode 1: PDF mit einem Online-Tool in ein gescanntes PDF umwandeln
- Methode 2: PDF mit Python in ein gescanntes PDF umwandeln
- PDF vs. gescanntes PDF: Hauptunterschiede
- Können gescannte PDFs noch bearbeitet werden?
- Häufig gestellte Fragen
Was ist ein gescanntes PDF?
Ein gescanntes PDF ist ein PDF-Dokument, in dem jede Seite als Bild gespeichert ist, anstatt als bearbeitbarer Text oder Vektorobjekte. Es ähnelt stark einem Dokument, das durch das Scannen von Papier mit einem physischen Scanner erstellt wurde.
Hauptmerkmale von gescannten PDFs sind:
- Text ist nicht auswählbar oder bearbeitbar
- Seiten sind bildbasiert
- Layout und Erscheinungsbild sind visuell festgelegt
- Die Dateigröße ist normalerweise größer als bei textbasierten PDFs
- Textsuche ist nicht verfügbar, es sei denn, OCR wird angewendet
Wenn Sie ein PDF in ein gescanntes PDF umwandeln, flachen Sie im Wesentlichen seinen Inhalt ab und entfernen seine interne Struktur.
Warum PDF in gescanntes PDF umwandeln?
Ein PDF in ein gescanntes Dokument umzuwandeln ist in vielen Situationen nützlich:
- Verhindern Sie gelegentliches Bearbeiten oder die Wiederverwendung von Inhalten
- Dokumente für die Archivierung vorbereiten
- Endgültige Berichte oder Mitteilungen verteilen
- Papierbasierte Arbeitsabläufe simulieren
- Dokumentenerscheinungsbild plattformübergreifend standardisieren
Im Vergleich zum schutzbasierten Schutz basieren gescannte PDFs auf struktureller Konvertierung anstatt auf vom Betrachter durchgesetzten Regeln, was sie widerstandsfähiger gegen gelegentliche Änderungen macht.
Methode 1: PDF mit einem Online-Tool in ein gescanntes PDF umwandeln
Online-PDF-Konverter eignen sich für schnelle, einmalige Konvertierungen von nicht sensiblen Dokumenten.
Schritte:
-
Öffnen Sie eine vertrauenswürdige Website zum Konvertieren von PDF in gescannte PDF (zum Beispiel, SafePDFKit).
-
Laden Sie die PDF-Datei hoch, die Sie konvertieren möchten.
-
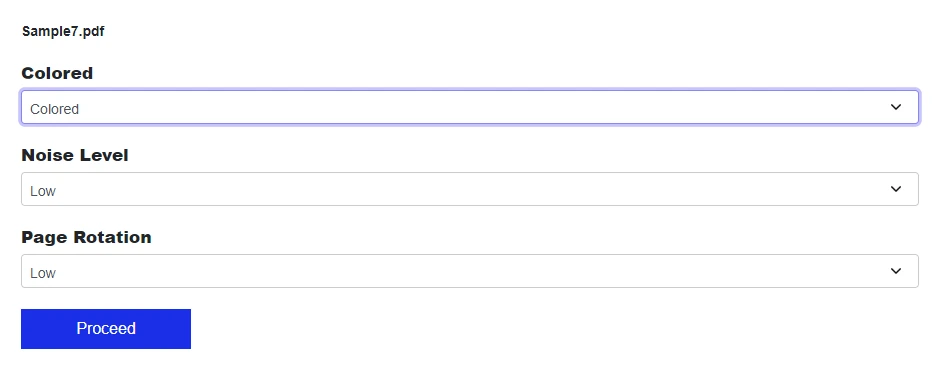
Konfigurieren Sie die Einstellungen wie Farbmodus, Rauschpegel und Seitendrehung.
-
Konvertieren und laden Sie das gescannte PDF herunter.
Am besten für:
- Gelegentliche Konvertierungen
- Öffentliche oder risikoarme Dokumente
- Benutzer, die browserbasierte Tools bevorzugen
Hinweis: Vermeiden Sie das Hochladen vertraulicher Dateien, es sei denn, der Dienst erklärt klar, wie hochgeladene Dokumente gehandhabt und gelöscht werden.
Wenn Sie das Bearbeiten, Kopieren oder Drucken per Passwortschutz einschränken möchten, können Sie sich in wie man PDFs verschlüsselt eine detaillierte Anleitung ansehen.
Methode 2: PDF mit Python in ein gescanntes PDF umwandeln
Für die Stapelverarbeitung oder automatisierte Arbeitsabläufe bietet Python eine zuverlässige Möglichkeit, PDFs in gescannte, bildbasierte Dokumente umzuwandeln.
Bibliotheken wie Spire.PDF für Python ermöglichen es Ihnen, jede PDF-Seite als Bild zu rendern und aus diesen Bildern ein neues PDF zu erstellen.
Schritt 1: Installieren Sie die Bibliothek
pip install spire.pdf
Sie können auch Spire.PDF für Python herunterladen und es manuell zu Ihrem Projekt hinzufügen.
Schritt 2: PDF-Seiten in Bilder umwandeln und das PDF neu erstellen
from spire.pdf import *
# Load the original PDF
pdf = PdfDocument()
pdf.LoadFromFile("Sample.pdf")
# Create a new PDF for the scanned output
scanned_pdf = PdfDocument()
# Convert each page to an image
for i in range(pdf.Pages.Count):
image_stream = pdf.SaveAsImage(i)
image = PdfImage.FromStream(image_stream)
page = scanned_pdf.Pages.Add(
SizeF(float(image.Width), float(image.Height)),
PdfMargins(0.0, 0.0)
)
page.Canvas.DrawImage(
image,
RectangleF.FromLTRB(0.0, 0.0, float(image.Width), float(image.Height))
)
# Save the scanned PDF
scanned_pdf.SaveToFile("ScannedPDF.pdf")
pdf.Dispose()
scanned_pdf.Dispose()
Vorschau des konvertierten gescannten PDFs:
In diesem gescannten PDF wird jede Seite als ganzseitiges Bild gerendert und eingebettet. Diese Konvertierung entfernt die ursprüngliche Textebene und die Dokumentenstruktur, wodurch der Inhalt nicht bearbeitbar und nicht auswählbar wird.
Vorteile der programmatischen Konvertierung:
- Konsistente Ausgabequalität
- Unterstützung für Stapelverarbeitung
- Keine manuelle Intervention
- Einfache Integration in Dokumenten-Pipelines
Für flexiblere Stapelverarbeitungs-Workflows unterstützt Python auch das direkte Umwandeln von PDFs in Bilder oder das Verschlüsseln von PDFs, um das Risiko der Bearbeitung und Wiederverwendung von Inhalten weiter zu reduzieren.
PDF vs. gescanntes PDF: Hauptunterschiede
| Merkmal | Standard-PDF | Gescanntes PDF |
|---|---|---|
| Bearbeitbarer Text | Ja | Nein |
| Textauswahl | Ja | Nein |
| Durchsuchbarer Inhalt | Ja | Nein (ohne OCR) |
| Dateigröße | Kleiner | Größer |
| Bester Anwendungsfall | Bearbeitung & Wiederverwendung | Verteilung & Archivierung |
Schneller Tipp: Wenn Benutzer das Dokument nur ansehen – nicht wiederverwenden oder seinen Inhalt ändern – sollen, ist ein gescanntes PDF oft die bessere Wahl.
Können gescannte PDFs noch bearbeitet werden?
Gescannte PDFs sind deutlich schwieriger zu bearbeiten als Standard-PDFs, aber sie sind nicht absolut unbearbeitbar.
- Fortgeschrittene Editoren können Bilder ersetzen
- OCR-Tools können Text extrahieren
- Inhalt kann manuell neu abgetippt werden
Für die meisten Benutzer und alltäglichen Arbeitsabläufe schrecken gescannte PDFs jedoch effektiv von der Bearbeitung und Wiederverwendung von Inhalten ab.
Beste Vorgehensweise:
- Bewahren Sie original bearbeitbare PDFs sicher auf
- Verwenden Sie gescannte PDFs für die Verteilung oder Archivierung
- Kombinieren Sie nur dann mit OCR, wenn eine Textsuche erforderlich ist
Fazit
Das Umwandeln eines PDFs in ein gescanntes PDF ist eine praktische Möglichkeit, bearbeitbare Dokumente in visuell festgelegte, bildbasierte Dateien umzuwandeln. Durch das Entfernen der Textstruktur und das Abflachen jeder Seite zu einem Bild eignen sich gescannte PDFs besser zum Teilen von finalisierten Inhalten und zur Wahrung der Dokumentenintegrität.
Ob Sie einen Online-Konverter für PDF in gescannte PDF für schnelle Aufgaben oder Python-Automatisierung für groß angelegte Arbeitsabläufe verwenden, die Wahl des richtigen Ansatzes stellt sicher, dass Ihre Dokumente konsistent, professionell und widerstandsfähig gegen gelegentliche Änderungen bleiben.
FAQ
Entfernt das Umwandeln eines PDFs in ein gescanntes PDF den durchsuchbaren Text?
Ja. Wenn ein PDF in ein gescanntes PDF umgewandelt wird, wird jede Seite als Bild gespeichert, sodass die ursprüngliche Textebene entfernt wird. Folglich kann Text nicht durchsucht oder ausgewählt werden, es sei denn, es wird anschließend eine OCR-Erkennung angewendet.
Erhöht das Umwandeln eines PDFs in ein gescanntes Dokument die Dateigröße?
In den meisten Fällen, ja. Gescannte PDFs sind bildbasiert, und Bilddaten benötigen normalerweise mehr Speicherplatz als Text- und Vektorinhalte. Die endgültige Dateigröße hängt von Faktoren wie Bildauflösung und Komprimierungseinstellungen ab.
Was ist der Unterschied zwischen einem gescannten PDF und dem Exportieren eines PDFs als Bilder?
Das Exportieren eines PDFs als Bilder erzeugt separate Bilddateien, während ein gescanntes PDF diese Bilder wieder in ein einziges PDF-Dokument einbettet. Ein gescanntes PDF behält das PDF-Containerformat bei, was das Teilen, Anzeigen und Archivieren erleichtert.
Können gescannte PDFs das Bearbeiten oder Kopieren vollständig verhindern?
Gescannte PDFs reduzieren das gelegentliche Bearbeiten und Kopieren erheblich, da sie keinen bearbeitbaren Text enthalten. Fortgeschrittene Werkzeuge oder OCR-Software können jedoch immer noch Inhalte extrahieren, sodass gescannte PDFs eher als praktische Abschreckung denn als absoluter Schutz angesehen werden sollten.