
Moderne Anwendungen sind stark auf APIs angewiesen, die strukturierte JSON-Daten zurückgeben. Während diese Daten ideal für Softwaresysteme sind, benötigen Stakeholder und Geschäftsteams Informationen oft in einem lesbaren, gemeinsam nutzbaren Format – und PDF-Berichte bleiben einer der am weitesten verbreiteten Standards für Dokumentation, Prüfung und Verteilung.
Anstatt JSON-Dateien manuell mit Online-Tools zu konvertieren, können Entwickler den gesamten Arbeitsablauf automatisieren – vom Abrufen von Live-API-Daten bis zur Erstellung strukturierter PDF-Berichte.
In diesem Tutorial erfahren Sie, wie Sie eine End-to-End-Automatisierungspipeline mit Python erstellen:
- JSON-Daten von einer API abrufen
- Die Antwort parsen und strukturieren
- Die Daten in ein Excel-Arbeitsblatt laden
- Das Arbeitsblatt als gut formatierten PDF-Bericht exportieren
Dieser Ansatz ist ideal für geplante Berichterstattung, SaaS-Dashboards, Analyseexporte und Backend-Automatisierungssysteme.
Warum Online-JSON-zu-PDF-Konverter nicht ausreichen
Online-Konverter können für schnelle, einmalige Aufgaben nützlich sein. Sie stoßen jedoch oft an ihre Grenzen, wenn sie mit Live-APIs oder automatisierten Arbeitsabläufen arbeiten.
Häufige Einschränkungen sind:
- Keine Möglichkeit, Daten direkt von APIs abzurufen
- Fehlende Automatisierungs- oder Planungsunterstützung
- Begrenzte Formatierungs- und Berichtslayout-Kontrolle
- Schwierigkeiten bei der Handhabung verschachtelter JSON-Strukturen
- Datenschutzbedenken beim Hochladen sensibler Daten
- Keine Integration mit Backend-Pipelines oder CI/CD-Systemen
Für Entwickler, die automatisierte Berichtssysteme erstellen, bietet ein programmatischer Arbeitsablauf weitaus mehr Flexibilität, Skalierbarkeit und Kontrolle. Mit Python und Spire.XLS können Sie strukturierte Berichte direkt aus API-Antworten erstellen, ohne manuellen Eingriff.
Voraussetzungen & Architekturübersicht: JSON-API → Excel → PDF-Pipeline
Bevor Sie den Automatisierungsworkflow erstellen, stellen Sie sicher, dass Ihre Umgebung vorbereitet ist:
pip install spire.xls requests
Warum Excel als Zwischenschicht verwenden?
Anstatt JSON direkt in PDF zu konvertieren, verwendet dieses Tutorial Excel als strukturierte Berichtsebene. Dieser Ansatz bietet mehrere Vorteile:
- Konvertiert unstrukturiertes JSON in saubere tabellarische Layouts
- Ermöglicht einfache Formatierung und Spaltensteuerung
- Sorgt für eine konsistente PDF-Ausgabe
- Unterstützt zukünftige Erweiterungen wie Diagramme und Zusammenfassungen
Pipeline-Architektur
Der Automatisierungsprozess folgt einer strukturierten Transformationspipeline:
- API-Schicht: Ruft Live-JSON-Daten von Backend-Diensten ab
- Datenverarbeitungsschicht: Normalisiert und glättet JSON-Strukturen
- Berichtslayout-Schicht (Excel): Organisiert Daten in lesbaren Tabellen
- Exportschicht (PDF): Erstellt einen gemeinsam nutzbaren Abschlussbericht
Dieser mehrschichtige Ansatz verbessert die Skalierbarkeit und hält die Berichtslogik für zukünftige Automatisierungsszenarien flexibel.
Schritt 1 – JSON-Daten von einer API abrufen
Die meisten automatisierten Berichtsworkflows beginnen mit dem Sammeln von Live-Daten von einer API. Anstatt Dateien manuell zu exportieren, ruft Ihr Skript die neuesten Datensätze direkt von Backend-Diensten, Analyseplattformen oder SaaS-Anwendungen ab. Dies stellt sicher:
- Berichte enthalten immer aktuelle Daten
- Keine manuellen Download- oder Konvertierungsschritte
- Einfache Integration in geplante Automatisierungspipelines
Unten sehen Sie ein Beispiel, das zeigt, wie man JSON-Daten mit Python abruft:
import requests
# Example API endpoint
url = "https://api.example.com/employees"
headers = {
"Authorization": "Bearer YOUR_API_TOKEN"
}
response = requests.get(url, headers=headers, timeout=30)
if response.status_code != 200:
raise Exception(f"API request failed: {response.status_code}")
api_data = response.json()
print("Records retrieved:", len(api_data))
Wichtige Praktiken:
- Überprüfen Sie immer den HTTP-Statuscode
- Fügen Sie bei Bedarf Authentifizierungs-Header hinzu
- Behandeln Sie Ratenbegrenzungen und API-Drosselung
- Bereiten Sie sich auf die Paginierung bei großen Datensätzen vor
Die Beispiele in diesem Tutorial verwenden die beliebte Python-Bibliothek requests zur Handhabung der HTTP-Kommunikation; konsultieren Sie die offizielle Requests-Dokumentation für fortgeschrittene Authentifizierungs- und Sitzungsverwaltungsmuster.
Schritt 2 – Die JSON-Antwort parsen und strukturieren
Nicht alle JSON-Dateien haben die gleiche Struktur. Einige APIs geben eine einfache Liste von Datensätzen zurück, während andere Daten in Objekte verpacken oder verschachtelte Arrays und Unterfelder enthalten. Das direkte Schreiben von komplexem JSON in Excel führt oft zu Fehlern oder unlesbaren Berichten.
Unterschiedliche JSON-Strukturen verstehen
| JSON-Typ | Beispielstruktur | Direkter Excel-Export |
|---|---|---|
| Einfache Liste | [ {…}, {…} ] | Funktioniert direkt |
| Verpackte Liste | { "employees": [ {…} ] } | ⚠ Zuerst Liste extrahieren |
| Verschachtelte Objekte | { "address": { "city": "NY" } } | ⚠ Felder abflachen |
| Verschachtelte Arrays | { "skills": ["Python", "SQL"] } | ⚠ In Zeichenfolge konvertieren |
Eine normalisierte Struktur sollte so aussehen:
[
{"id":1,"name":"Alice","city":"NY","skills":"Python, SQL"}
]
Dieses Format kann direkt in Excel-Zeilen geschrieben werden. Wenn Sie nicht vertraut sind, wie verschachtelte Objekte und Arrays strukturiert sind, kann die Überprüfung der offiziellen JSON-Datenformatspezifikation helfen zu klären, wie komplexe API-Antworten organisiert sind.
JSON vor der Berichterstellung normalisieren
Anstatt JSON für jede API manuell zu ändern, können Sie automatisch:
- Verpackte Listen erkennen
- Verschachtelte Objekte abflachen
- Arrays in lesbare Zeichenfolgen umwandeln
- Daten für die Berichterstattung standardisieren
Unten finden Sie einen wiederverwendbaren Normalisierungshelfer:
def normalize_json(input_json):
# Step 1: detect wrapped list
if isinstance(input_json, dict):
for value in input_json.values():
if isinstance(value, list):
input_json = value
break
normalized = []
for item in input_json:
flat_item = {}
for key, value in item.items():
# flatten nested dict
if isinstance(value, dict):
for sub_key, sub_val in value.items():
flat_item[f"{key}_{sub_key}"] = str(sub_val)
# convert lists to string
elif isinstance(value, list):
flat_item[key] = ", ".join(map(str, value))
else:
flat_item[key] = str(value)
normalized.append(flat_item)
return normalized
Hinweis: Tief verschachtelte mehrstufige JSON-Strukturen können je nach API-Komplexität eine zusätzliche rekursive Abflachung erfordern.
Anwendungsbeispiel:
with open("data.json", "r", encoding="utf-8") as f:
raw_data = json.load(f)
structured_data = normalize_json(raw_data)
Dies stellt sicher, dass der Datensatz unabhängig von der JSON-Komplexität für den Excel-Export sicher ist.
Schritt 3 – Strukturierte JSON-Daten in ein Excel-Arbeitsblatt laden
Excel fungiert nach der JSON-Normalisierung als strukturierte Berichtsebene. Sobald komplexe JSON-Strukturen in eine einfache Liste von Wörterbüchern abgeflacht wurden, können die Daten direkt in Zeilen und Spalten für die weitere Formatierung und den PDF-Export geschrieben werden.
Mit Spire.XLS für Python können Entwickler Excel-Berichte vollständig per Code erstellen, ändern und formatieren – ohne Microsoft Excel zu benötigen – was die Integration fortgeschrittener Tabellenkalkulationsoperationen in automatisierte Berichtsworkflows erleichtert.
Arbeitsmappe und Arbeitsblatt erstellen
from spire.xls import Workbook
workbook = Workbook()
sheet = workbook.Worksheets[0]
So funktioniert es:
- Initialisiert eine neue Excel-Datei im Speicher.
- Greift auf das erste Arbeitsblatt zu.
- Bereitet eine Leinwand zum Schreiben strukturierter Daten vor.
Kopfzeilen und Datenzeilen schreiben
headers = list(structured_data[0].keys())
for col, header in enumerate(headers):
sheet.Range[1, col + 1].Text = header
for row_idx, row in enumerate(structured_data, start=2):
for col_idx, key in enumerate(headers):
sheet.Range[row_idx, col_idx + 1].Text = str(row.get(key, ""))
So funktioniert es:
- Extrahiert Spaltenüberschriften aus strukturierten Daten.
- Schreibt zuerst die Kopfzeile.
- Iteriert durch Datensätze und füllt Zeilen nacheinander.
- Konvertiert Werte in Zeichenfolgen, um eine konsistente Ausgabe zu gewährleisten.
Formatierung vor dem Export vorbereiten
# Auto-fit columns
for i in range(1, sheet.Range.ColumnCount + 1):
sheet.AutoFitColumn(i)
# Set a default row height for all rows
sheet.DefaultRowHeight = 18
# Set uniform margins for the sheet
sheet.PageSetup.LeftMargin = 0.2
sheet.PageSetup.RightMargin = 0.2
sheet.PageSetup.TopMargin = 0.2
sheet.PageSetup.BottomMargin = 0.2
# Enable printing of gridlines
sheet.PageSetup.IsPrintGridlines = True
Da das Arbeitsblatt bereits Layout und Formatierung definiert, behält der PDF-Export die visuelle Struktur ohne zusätzliche Renderlogik bei.
Schritt 4 – Das Arbeitsblatt als PDF-Bericht exportieren
Sobald die Daten in Excel strukturiert und formatiert sind, erstellt der Export nach PDF einen portablen, professionellen Bericht, der geeignet ist für:
- Verteilung an Stakeholder
- Compliance-Dokumentation
- Automatisierte Berichtspipelines
- Archivspeicherung
Excel-Arbeitsblatt als PDF-Bericht speichern
sheet.SaveToPdf("output.pdf")
Ihr strukturierter PDF-Bericht wird nun automatisch aus API-Daten generiert.
Ausgabe:
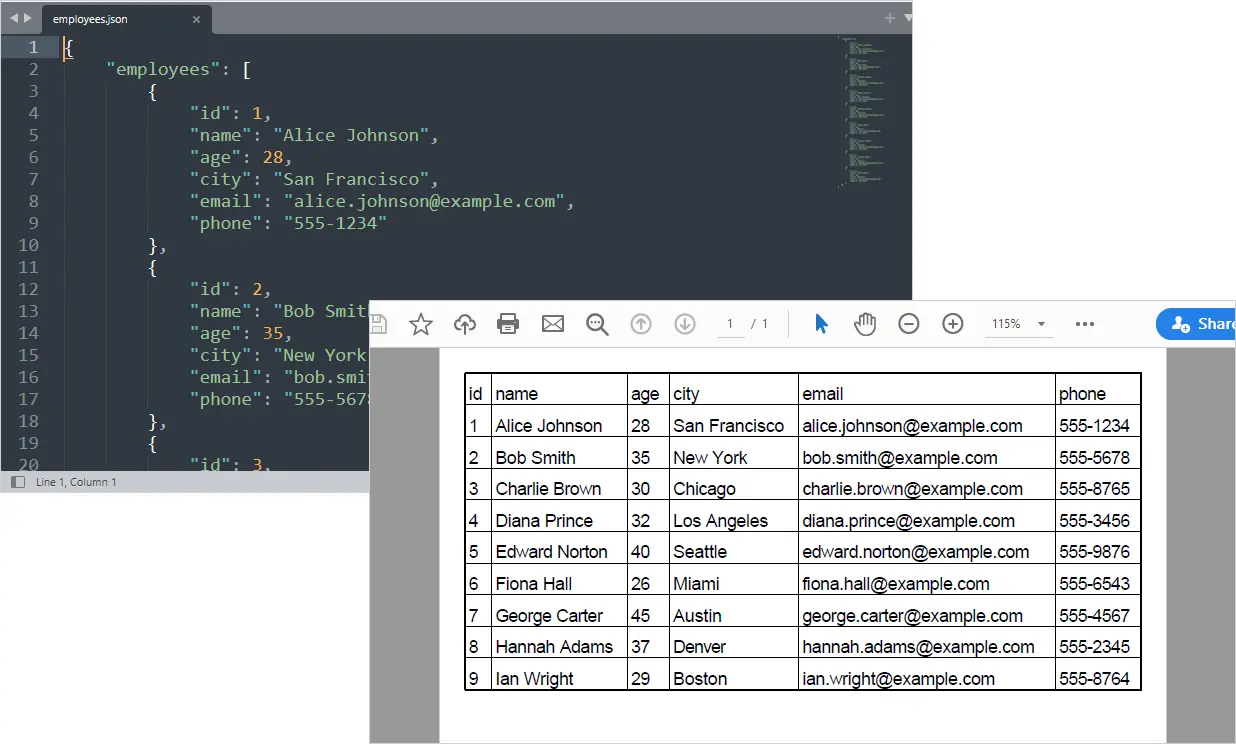
Das könnte Ihnen auch gefallen: Excel in PDF konvertieren in Python
Vollständiges Skript – Vom API-JSON zum strukturierten PDF-Bericht
from spire.xls import *
from spire.xls.common import *
import json
import requests
def normalize_json(input_json):
# Step 1: detect wrapped list
if isinstance(input_json, dict):
for value in input_json.values():
if isinstance(value, list):
input_json = value
break
normalized = []
for item in input_json:
flat_item = {}
for key, value in item.items():
# flatten nested dict
if isinstance(value, dict):
for sub_key, sub_val in value.items():
flat_item[f"{key}_{sub_key}"] = str(sub_val)
# convert lists to string
elif isinstance(value, list):
flat_item[key] = ", ".join(map(str, value))
else:
flat_item[key] = str(value)
normalized.append(flat_item)
return normalized
# =========================
# Step 1: Get JSON from API
# =========================
api_url = "https://api.example.com/employees"
response = requests.get(api_url)
if response.status_code != 200:
raise Exception(f"API request failed: {response.status_code}")
raw_data = response.json()
# =========================
# Step 2: Normalize JSON
# =========================
data = normalize_json(raw_data)
# =========================
# Step 3: Create Workbook
# =========================
workbook = Workbook()
sheet = workbook.Worksheets[0]
# Write headers
headers = list(data[0].keys())
for col, header in enumerate(headers):
sheet.Range[1, col + 1].Text = header
# Write rows
for row_idx, row in enumerate(data, start=2):
for col_idx, key in enumerate(headers):
sheet.Range[row_idx, col_idx + 1].Text = row.get(key, "")
# =========================
# Step 4: Format worksheet
# =========================
# Set conversion settings to adjust sheet layout
workbook.ConverterSetting.SheetFitToPageRetainPaperSize = True # Retain paper size during conversion
workbook.ConverterSetting.SheetFitToWidth = True # Fit sheet to width during conversion
# Auto-fit columns
for i in range(1, sheet.Range.ColumnCount + 1):
sheet.AutoFitColumn(i)
# Set uniform margins for the sheet
sheet.PageSetup.LeftMargin = 0.2
sheet.PageSetup.RightMargin = 0.2
sheet.PageSetup.TopMargin = 0.2
sheet.PageSetup.BottomMargin = 0.2
# Enable printing of gridlines
sheet.PageSetup.IsPrintGridlines = True
# Set a default row height for all rows
sheet.DefaultRowHeight = 18
# =========================
# Step 5: Export to PDF
# =========================
sheet.SaveToPdf("output.pdf")
workbook.Dispose()
Wenn Ihre Datenquelle eine lokale JSON-Datei anstelle einer Live-API ist, können Sie die Daten direkt von der Festplatte laden, bevor Sie den PDF-Bericht erstellen.
with open("data.json", "r", encoding="utf-8") as f:
raw_data = json.load(f)
Praktische Anwendungsfälle
Dieser Automatisierungsworkflow kann in einer Vielzahl von datengesteuerten Berichtsszenarien angewendet werden:
- Automatisierte API-Berichtspipelines – Tägliche oder wöchentliche PDF-Berichte von Backend-Diensten ohne manuelle Exporte erstellen.
- SaaS-Nutzungs- und Aktivitätszusammenfassungen – Anwendungsanalyse-APIs in strukturierte Kunden- oder interne Berichte umwandeln.
- Finanz- und HR-Berichtsexporte – Strukturierte API-Daten in standardisierte PDF-Dokumente für die interne Verteilung umwandeln.
- Analyse-Dashboard-Snapshots – API-gesteuerte Metriken erfassen und in gemeinsam nutzbare Managementberichte umwandeln.
- Geplante Business-Intelligence-Berichte – Automatisch PDF-Zusammenfassungen aus Data-Warehouse- oder Analyse-APIs erstellen.
- Compliance- und Audit-Dokumentation – Konsistente, mit Zeitstempel versehene PDF-Datensätze aus strukturierten API-Datensätzen erstellen.
Abschließende Gedanken
Die Automatisierung der PDF-Berichterstellung aus JSON-API-Antworten ermöglicht es Entwicklern, skalierbare Berichtspipelines zu erstellen, die die manuelle Verarbeitung eliminieren. Durch die Kombination der API-Fähigkeiten von Python mit den Excel- und PDF-Exportfunktionen von Spire.XLS für Python können Sie strukturierte, professionelle Berichte direkt aus Live-Datenquellen erstellen.
Egal, ob Sie wöchentliche Geschäftsberichte, interne Dashboards oder Kundenlieferungen erstellen, dieser Arbeitsablauf bietet Flexibilität, Automatisierung und volle Kontrolle über den Berichterstellungsprozess.
JSON zu PDF: FAQs
Kann ich JSON direkt ohne Excel in PDF konvertieren?
Ja, aber die Verwendung von Excel als Zwischenschicht erleichtert die Strukturierung von Tabellen, die Steuerung von Layouts und die Erstellung konsistenter, professioneller Berichtsformate.
Wie gehe ich mit großen oder paginierten API-Antworten um?
Iterieren Sie durch die von der API bereitgestellten Seiten oder Token und führen Sie alle Ergebnisse in einem einzigen Datensatz zusammen, bevor Sie den PDF-Bericht erstellen.
Kann dieser Arbeitsablauf automatisch nach einem Zeitplan ausgeführt werden?
Ja. Sie können das Skript mit Cron-Jobs, dem Windows Task Scheduler, CI/CD-Pipelines oder Backend-Diensten automatisieren, um regelmäßig Berichte zu erstellen.
Wie passe ich das Layout des PDF-Berichts an?
Formatieren Sie das Excel-Arbeitsblatt vor dem Export – passen Sie Spaltenbreiten an, wenden Sie Stile an, frieren Sie Kopfzeilen ein oder fügen Sie Diagramme hinzu. Diese Einstellungen bleiben im PDF erhalten.
Was ist, wenn die API fehlende oder inkonsistente Felder zurückgibt?
Verwenden Sie sichere Extraktionsmethoden wie .get() mit Standardwerten beim Parsen von JSON, um Fehler zu vermeiden und konsistente Tabellenstrukturen beizubehalten.