Tabla de contenidos
Instalar con Maven
<dependency>
<groupId>e-iceblue</groupId>
<artifactId>spire.pdf</artifactId>
<version>11.8.3</version>
</dependency>
Enlaces relacionados

Al trabajar con archivos PDF en Java, a menudo es necesario convertir entre datos binarios y formatos basados en texto. La codificación Base64 permite representar el contenido de un PDF como texto sin formato, lo cual es útil al transmitir documentos en JSON, enviarlos a través de envíos de formularios o almacenarlos en sistemas basados en texto. La biblioteca estándar de Java proporciona java.util.Base64, lo que facilita la implementación de conversiones de Base64 a PDF y de PDF a Base64 sin dependencias adicionales.
En este tutorial, exploraremos cómo manejar estas conversiones utilizando únicamente el JDK, así como cómo trabajar con imágenes en Base64 e incrustarlas en archivos PDF. Para operaciones más avanzadas, como editar un PDF recibido como Base64 y exportarlo de nuevo, demostraremos el uso de Free Spire.PDF for Java.
Tabla de contenidos
- Convertir Base64 a PDF en Java (solo JDK)
- Convertir PDF a Base64 en Java (solo JDK)
- Consejos de validación y seguridad
- Guardar imágenes Base64 como PDF en Java
- Cargar PDF en Base64, modificar y guardar de nuevo como Base64
- Consideraciones de rendimiento y memoria
- FAQ
Convertir Base64 a PDF en Java (solo JDK)
El enfoque más sencillo es leer una cadena Base64 en la memoria, eliminar cualquier prefijo opcional (como data:application/pdf;base64,) y luego decodificarla en un PDF. Esto funciona bien para archivos de tamaño pequeño a mediano.
import java.nio.file.*;
import java.nio.charset.StandardCharsets;
import java.util.Base64;
public class Base64ToPdf {
public static void main(String[] args) throws Exception {
// Leer texto Base64 de un archivo (o cualquier otra fuente)
String base64 = Files.readString(Paths.get("sample.pdf.b64"), StandardCharsets.UTF_8);
// Eliminar prefijos comunes de URI de datos si están presentes
base64 = stripDataPrefix(base64);
// Decodificar Base64 en bytes de PDF sin procesar
// El decodificador MIME tolera saltos de línea y texto ajustado
byte[] pdfBytes = Base64.getMimeDecoder().decode(base64);
// Escribir los bytes decodificados en un archivo PDF
Files.write(Paths.get("output.pdf"), pdfBytes);
}
/** Utilidad para eliminar el prefijo "data:application/pdf;base64,", si está incluido */
private static String stripDataPrefix(String src) {
String s = src.trim();
int comma = s.indexOf(',');
if (comma > 0 && s.substring(0, comma).toLowerCase().contains("base64")) {
return s.substring(comma + 1).trim();
}
return s;
}
}
Explicación Este ejemplo es sencillo y fiable para contenido Base64 que cabe cómodamente en la memoria. Se elige Base64.getMimeDecoder() porque maneja con elegancia los saltos de línea, que son comunes en el texto Base64 exportado desde sistemas de correo electrónico o API. Si sabe que su cadena Base64 no contiene saltos de línea, también podría usar Base64.getDecoder().
Asegúrese de eliminar cualquier prefijo de URI de datos (data:application/pdf;base64,) antes de decodificar, ya que no forma parte de la carga útil de Base64. El método de ayuda stripDataPrefix() lo hace automáticamente.
Variante de transmisión (sin la cadena completa en memoria)
Para archivos PDF grandes, es mejor procesar Base64 en modo de transmisión. Esto evita cargar toda la cadena Base64 en la memoria de una vez.
import java.io.*;
import java.nio.file.*;
import java.util.Base64;
public class Base64ToPdfStreamed {
public static void main(String[] args) throws Exception {
// Entrada: archivo de texto que contiene PDF codificado en Base64
Path in = Paths.get("sample.pdf.b64");
// Salida: archivo PDF decodificado
Path out = Paths.get("output.pdf");
// Envolver el decodificador Base64 alrededor del flujo de entrada
try (InputStream b64In = Base64.getMimeDecoder().wrap(Files.newInputStream(in));
OutputStream pdfOut = Files.newOutputStream(out)) {
// Transmitir los bytes decodificados directamente a la salida PDF
b64In.transferTo(pdfOut);
}
}
}
Explicación Este enfoque basado en la transmisión es más eficiente en cuanto a memoria, ya que decodifica los datos sobre la marcha en lugar de almacenar en búfer toda la cadena. Es el método recomendado para archivos grandes o flujos continuos (por ejemplo, sockets de red).
- Se utiliza Base64.getMimeDecoder() para tolerar los saltos de línea en la entrada.
- El método transferTo() copia eficientemente los bytes decodificados de la entrada a la salida sin manejo manual de búfer.
- En el uso en el mundo real, considere agregar manejo de excepciones para gestionar errores de acceso a archivos o escrituras parciales.
Convertir PDF a Base64 en Java (solo JDK)
Codificar un PDF en Base64 es igual de simple. Para archivos más pequeños, leer todo el PDF en la memoria está bien:
import java.nio.file.*;
import java.util.Base64;
public class PdfToBase64 {
public static void main(String[] args) throws Exception {
// Leer el archivo PDF en un arreglo de bytes
byte[] pdfBytes = Files.readAllBytes(Paths.get("input.pdf"));
// Codificar los bytes del PDF como una cadena Base64
String base64 = Base64.getEncoder().encodeToString(pdfBytes);
// Escribir la cadena Base64 en un archivo de texto
Files.writeString(Paths.get("output.pdf.b64"), base64);
}
}
Explicación Este enfoque es simple y funciona bien para archivos de tamaño pequeño o mediano. Todo el archivo PDF se lee en un arreglo de bytes y se codifica como una única cadena Base64. Esta cadena se puede almacenar, transmitir en JSON o incrustar en una URI de datos.
Codificador de transmisión (maneja archivos grandes de manera eficiente)
Para archivos PDF grandes, puede evitar la sobrecarga de memoria codificando directamente como un flujo:
import java.io.*;
import java.nio.file.*;
import java.util.Base64;
public class PdfToBase64Streamed {
public static void main(String[] args) throws Exception {
// Entrada: archivo PDF binario
try (InputStream pdfIn = Files.newInputStream(Paths.get("input.pdf"));
// Flujo de salida sin procesar para el archivo de texto Base64
OutputStream rawOut = Files.newOutputStream(Paths.get("output.pdf.b64"));
// Envolver el flujo de salida con el codificador Base64
OutputStream b64Out = Base64.getEncoder().wrap(rawOut)) {
// Transmitir los bytes del PDF directamente a la salida codificada en Base64
pdfIn.transferTo(b64Out);
}
}
}
Explicación El codificador de transmisión maneja eficientemente archivos grandes codificando datos de forma incremental en lugar de cargar todo en la memoria. El método Base64.getEncoder().wrap() convierte un flujo de salida regular en uno que escribe texto Base64 automáticamente.
Este diseño se escala mejor para archivos PDF grandes, flujos de red o servicios que deben manejar muchos documentos simultáneamente sin sufrir problemas de memoria.
Consejos de validación y seguridad
- Detectar URIs de datos: los usuarios pueden enviar prefijos data:application/pdf;base64,. Elimínelos antes de decodificar.
- Saltos de línea: al decodificar texto que puede contener líneas ajustadas (correos electrónicos, registros), use Base64.getMimeDecoder().
- Verificación rápida de cordura: después de la decodificación, los primeros bytes de un PDF válido generalmente comienzan con %PDF-. Puede afirmar esto para la detección temprana de fallas.
- Codificación de caracteres: trate el texto Base64 como UTF-8 (o US-ASCII) al leer/escribir archivos .b64.
- Manejo de errores: envuelva la decodificación/codificación en bloques try/catch y muestre mensajes procesables (por ejemplo, tamaño, discrepancia de encabezado).
Guardar imágenes Base64 como PDF en Java
A veces recibe imágenes (por ejemplo, PNG o JPEG) como cadenas Base64 y necesita envolverlas en un PDF. Si bien la biblioteca estándar de Java no tiene API de PDF, Free Spire.PDF for Java lo hace sencillo.
Puede descargar Free Spire.PDF for Java y agregarlo a su proyecto o instalar Free Spire.PDF for Java desde el repositorio de Maven.
Conceptos clave de Spire.PDF
- PdfDocument — el contenedor para una o más páginas PDF.
- PdfPageBase — representa una página en la que puede dibujar.
- PdfImage.fromImage() — carga una BufferedImage o un flujo en una imagen PDF dibujable.
- drawImage() — coloca la imagen en las coordenadas y el tamaño especificados.
- Sistema de coordenadas — Spire.PDF utiliza un sistema de coordenadas donde (0,0) es la esquina superior izquierda.
Ejemplo: Convertir una imagen Base64 a PDF usando Java
import com.spire.pdf.PdfDocument;
import com.spire.pdf.PdfPageBase;
import com.spire.pdf.graphics.PdfImage;
import java.io.*;
import java.nio.charset.StandardCharsets;
import java.nio.file.*;
import java.util.Base64;
public class Base64ImageToPdf {
public static void main(String[] args) throws Exception {
// 1) Leer el archivo Base64 y decodificar (eliminar el prefijo de URI de datos si existe)
String base64Image = Files.readString(Paths.get("G:/Document/image.b64"), StandardCharsets.UTF_8).trim();
int comma = base64Image.indexOf(',');
if (comma > 0 && base64Image.substring(0, comma).toLowerCase().contains("base64")) {
base64Image = base64Image.substring(comma + 1).trim();
}
byte[] imageBytes = Base64.getMimeDecoder().decode(base64Image);
// 2) Crear PDF e insertar la imagen
PdfDocument pdf = new PdfDocument();
try (ByteArrayInputStream in = new ByteArrayInputStream(imageBytes)) {
PdfImage img = PdfImage.fromStream(in);
pdf.getPageSettings().setWidth(img.getWidth());
pdf.getPageSettings().setHeight(img.getHeight());
pdf.getPageSettings().setMargins(0, 0, 0, 0);
PdfPageBase page = pdf.getPages().add();
page.getCanvas().drawImage(img, 0, 0);
}
// 3) Guardar el archivo PDF
pdf.saveToFile("output/image.pdf");
}
}
El siguiente ejemplo decodifica una imagen Base64 y la incrusta en una página PDF. La salida se ve así:
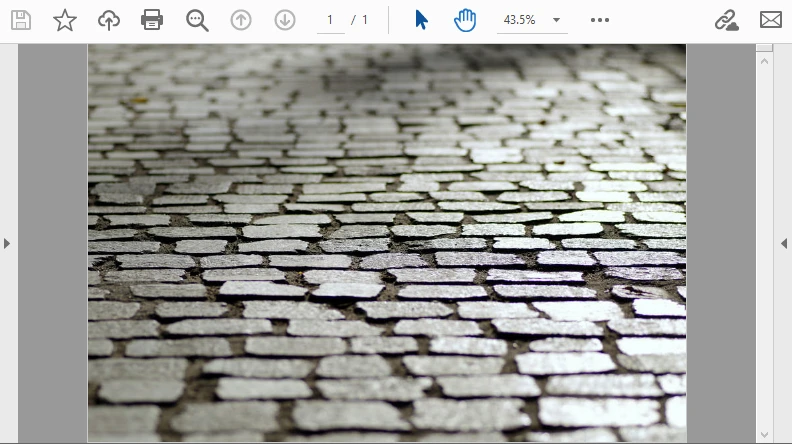
Este flujo de trabajo es ideal para incrustar documentos escaneados o firmas que llegan como Base64.
Para gráficos vectoriales, también puede consultar nuestra guía sobre Convertir SVG a PDF en Java.
Cargar PDF en Base64, modificar y guardar de nuevo como Base64
En muchas API, un PDF llega como Base64. Con Spire.PDF puede cargarlo, dibujar en las páginas (texto/marcas de agua) y devolver Base64 nuevamente, ideal para funciones sin servidor o microservicios.
Conceptos clave de Spire.PDF utilizados aquí
- PdfDocument.loadFromBytes(byte[]) — construye un documento directamente a partir de bytes decodificados.
- PdfPageBase#getCanvas() — obtiene una superficie de dibujo para colocar texto, formas o imágenes.
- Fuentes y pinceles — por ejemplo, PdfTrueTypeFont o fuentes integradas a través de PdfFont, con PdfSolidBrush para colorear.
- Guardar en memoria — pdf.saveToStream(ByteArrayOutputStream) produce bytes sin procesar, que puede volver a codificar con Base64.
Ejemplo: Cargar, modificar y guardar PDF en Base64 en Java
import com.spire.pdf.*;
import com.spire.pdf.graphics.*;
import java.awt.*;
import java.io.*;
import java.util.Base64;
public class EditBase64Pdf {
public static void main(String[] args) throws Exception {
String base64Pdf = "..."; // cadena de PDF en Base64 entrante
// Decodificar a bytes
byte[] pdfBytes = Base64.getDecoder().decode(base64Pdf);
// Cargar PDF
PdfDocument pdf = new PdfDocument();
pdf.loadFromBytes(pdfBytes);
// Agregar sello en cada página
for (PdfPageBase page : (Iterable) pdf.getPages()) {
PdfTrueTypeFont font = new PdfTrueTypeFont(new Font("Arial", Font.BOLD, 36));
PdfSolidBrush brush = new PdfSolidBrush(new PdfRGBColor(Color.BLUE));
page.getCanvas().drawString("Processed", font, brush, 100, 100);
}
// Guardar en memoria y volver a codificar en Base64
ByteArrayOutputStream output = new ByteArrayOutputStream();
pdf.saveToStream(output);
pdf.close();
String resultBase64 = Base64.getEncoder().encodeToString(output.toByteArray());
System.out.println(resultBase64);
}
}
En este ejemplo, se agrega una marca de agua azul "Procesado" a cada página del PDF antes de volver a codificarlo en Base64. El resultado se ve así:
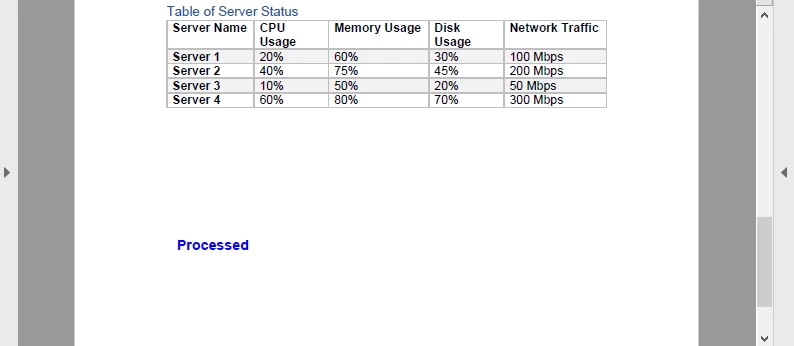
Este viaje de ida y vuelta (Base64 → PDF → Base64) es útil para pipelines de documentos, como estampar facturas o agregar firmas dinámicas en un servicio en la nube.
Tutoriales relacionados:
Extraer texto de PDF en Java | Crear documentos PDF en Java
Consideraciones de rendimiento y memoria
- Transmisión vs. E/S de archivos — cuando se trata de Base64, prefiera ByteArrayInputStream y ByteArrayOutputStream para evitar archivos temporales innecesarios.
- PDF con muchas imágenes — la decodificación de imágenes Base64 puede aumentar el uso de la memoria; considere escalar o comprimir antes de incrustar.
- PDF grandes — Spire.PDF maneja PDF de varios MB, pero para documentos muy grandes considere el procesamiento página por página.
- Funciones sin servidor — los flujos de trabajo de Base64 encajan bien porque se evita la dependencia del sistema de archivos y se devuelven los resultados directamente a través de las respuestas de la API.
FAQ
P: ¿Puedo convertir Base64 a PDF usando solo el JDK?
Sí. Java SE proporciona utilidades de Base64 y E/S de archivos, por lo que puede manejar la conversión sin bibliotecas adicionales.
P: ¿Puedo editar PDF con la biblioteca estándar de Java?
No. Java SE no admite el análisis de la estructura ni la representación de PDF. Para editar, use una biblioteca dedicada como Spire.PDF for Java.
P: ¿Es suficiente Free Spire.PDF for Java?
Sí. La edición gratuita de Spire.PDF for Java tiene un tamaño de documento limitado, pero es suficiente para pruebas o proyectos a pequeña escala.
P: ¿Necesito guardar los PDF en el disco?
No siempre. La conversión también se puede ejecutar en memoria usando flujos, lo que a menudo se prefiere para API y aplicaciones en la nube.